长期以来主流的代码修复评测基准SWE-bench面临数据过时、覆盖面窄、手动维护成本高等问题,严重制约了AI模型真实能力的展现。
微软发布全新代码修复评测基准SWE-bench-Live,不仅引入了来自GitHub最新的Issue,显著提升了对模型评估的实时性与准确性,还实现代码运行环境的全自动化构建与自动更新,打破了传统静态评测基准的局限。
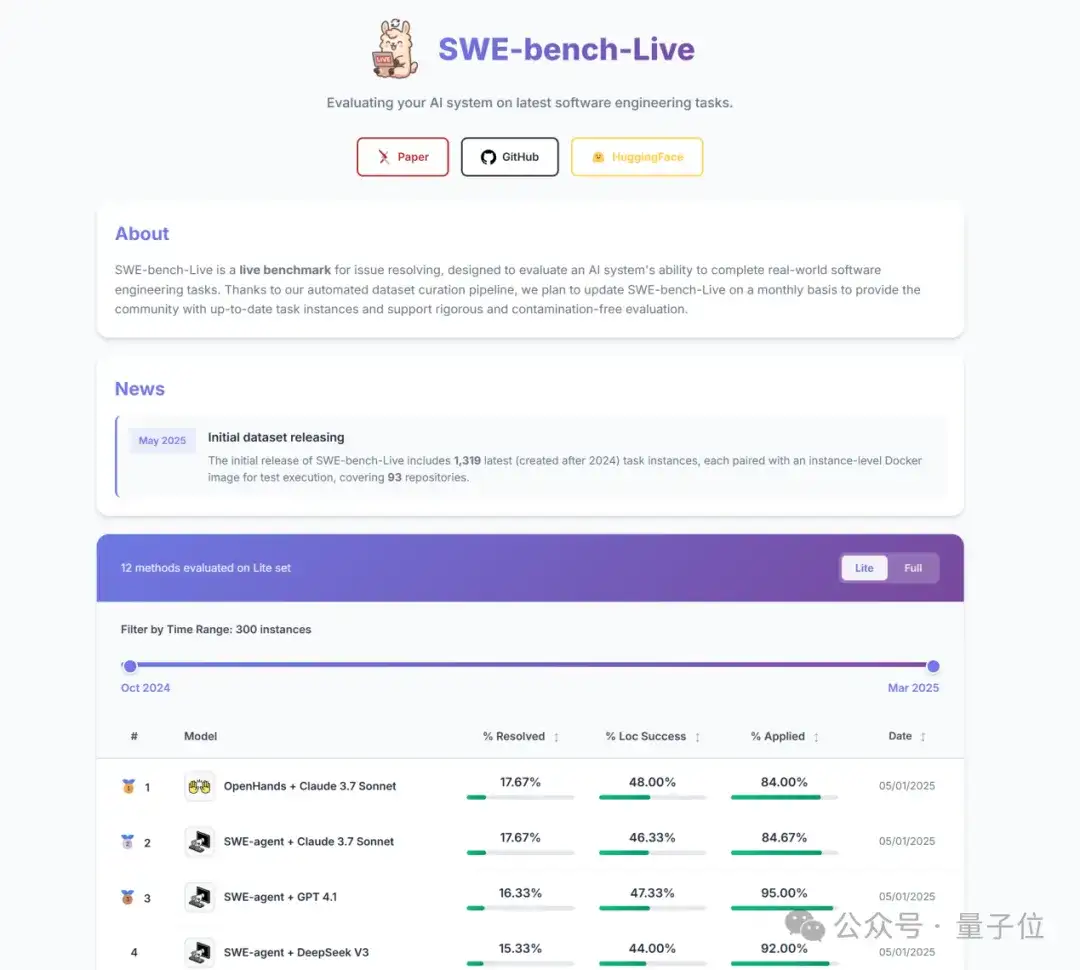
△图1: SWE-bench-Live leaderboard.
全自动化环境搭建
传统的代码修复评测基准需要人工构建代码运行环境,不仅成本高昂,且更新缓慢,难以跟上软件开发环境的快速变化。SWE-bench-Live开创性地采用了基于Agent的智能化框架REPOLAUNCH,彻底解决了这些问题。
REPOLAUNCH可以根据Github中真实的Issue,自动搭建其Docker环境并执行测试验证,整个流程完全无人干预,并且每月自动更新,持续提供最新鲜、最具代表性的评测数据。这种自动化的实时更新模式,消除了数据泄露与模型过拟合风险。

△图2: 自动化流水线流程图
REPOLAUNCH详细流程
REPOLAUNCH的核心原理是利用智能agent技术模仿人类开发者的环境构建过程。具体流程包括:
- 相关文件自动识别:智能地提取CI/CD配置、README文件等关键信息。
- Docker环境自动选择与搭建:自动识别项目依赖的基础镜像并快速构建容器。
- 智能Agent交互迭代调试:agent以ReAct模式(Reasoning+Action)进行持续迭代和环境调试,模拟开发者行为,快速定位并解决环境问题。
- 环境固化与验证:成功搭建的环境以Docker镜像形式固化,确保任何人都能轻松复现和使用。
不仅如此,REPOLAUNCH还具有广泛的应用潜力,能够支持更多下游任务。例如:
- 自动化新手环境配置:帮助缺乏经验的开发者快速搭建复杂的开发环境。
- 构建强化学习反馈环境:为强化学习模型提供自动化的代码交互反馈环境,加速模型的迭代与优化。
- 遗留项目环境重建:快速恢复历史或废弃代码项目的环境,解决依赖版本冲突等问题。
实验发现
首次基于SWE-bench-Live的全面评测结果显示,当前顶尖大模型和代码Agent的表现大幅下滑。
在完全相同的实验设置下,在传统评测基准SWE-bench Verified中达到43.2%准确率的OpenHands + Claude 3.7 Sonnet组合,转到SWE-bench-Live后仅达到了19.25%的准确率。这一明显差距揭示了传统静态基准中潜在的过拟合问题,表明实时、多样的数据环境对模型能力的客观评测至关重要。
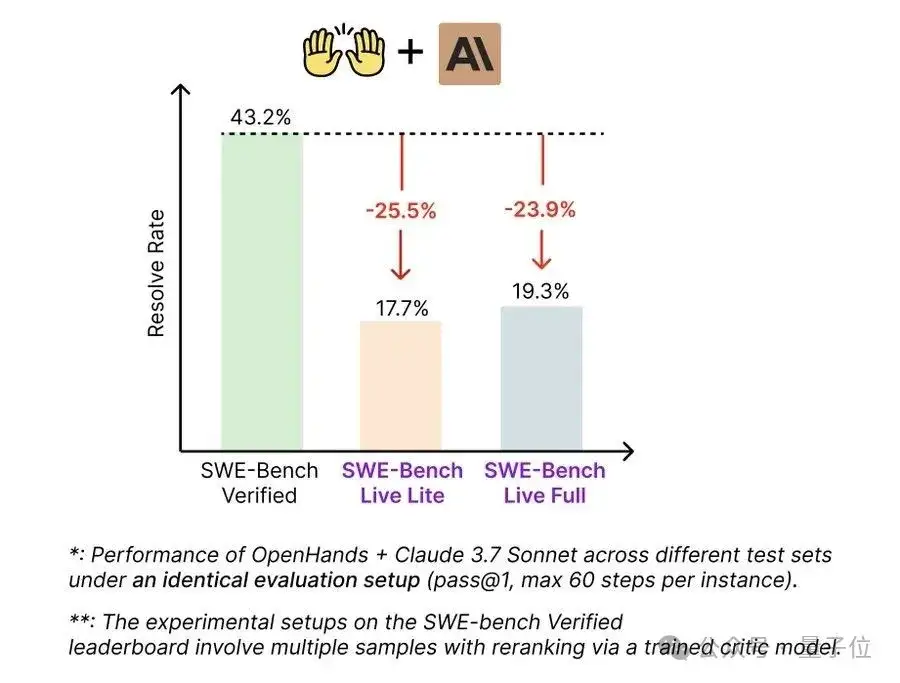
△图3:模型在不同基准上的表现对比图
如图进一步深入的实验分析显示,即使在SWE-bench-Live中,LLM在修复来自非原有SWE-bench仓库的新Issue时,其成功率也显著低于修复原有SWE-bench仓库的Issue。这一现象说明,现有大模型可能已在传统静态评测中形成了一定的过拟合,对于未见过的新仓库和新问题表现明显下降,进一步凸显了SWE-bench-Live实时、动态、多样性评测的重要性。
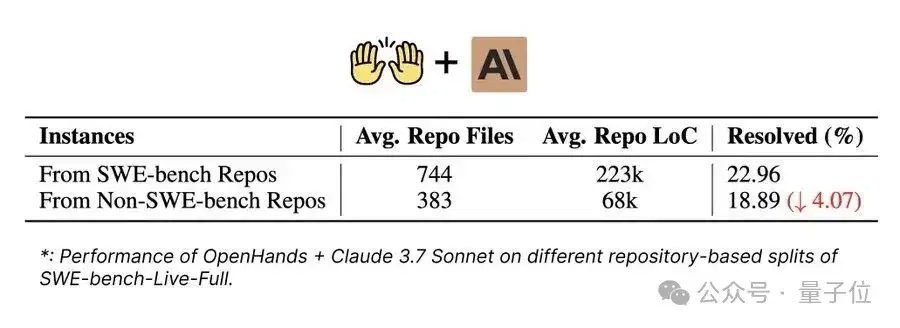
△图4:OpenHands+Claude 3.7 Sonnet在SWE-bench-Live不同仓库来源的性能对比
多领域覆盖与多样化挑战
SWE-bench-Live的首批任务涵盖了1319个真实Issue,涉及93个开源项目,领域包括AI/ML、DevOps、Web开发、数据库、科学计算等多个方向。这种多样性与高频实时更新使SWE-bench-Live的评估更加准确,更能反应模型能力的高低。
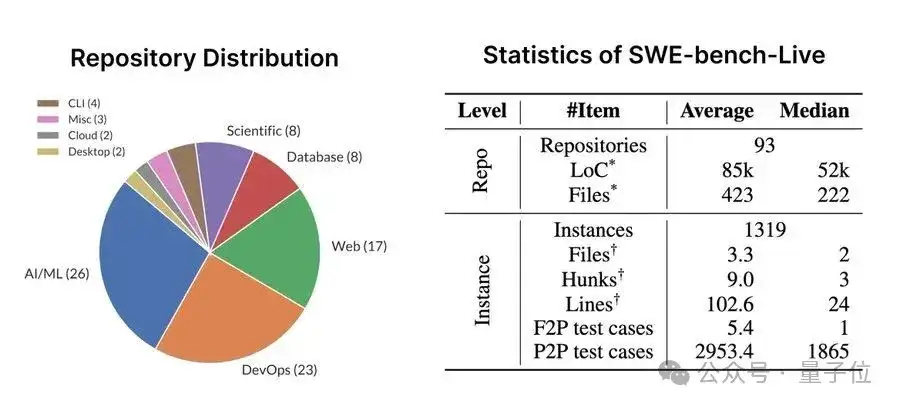
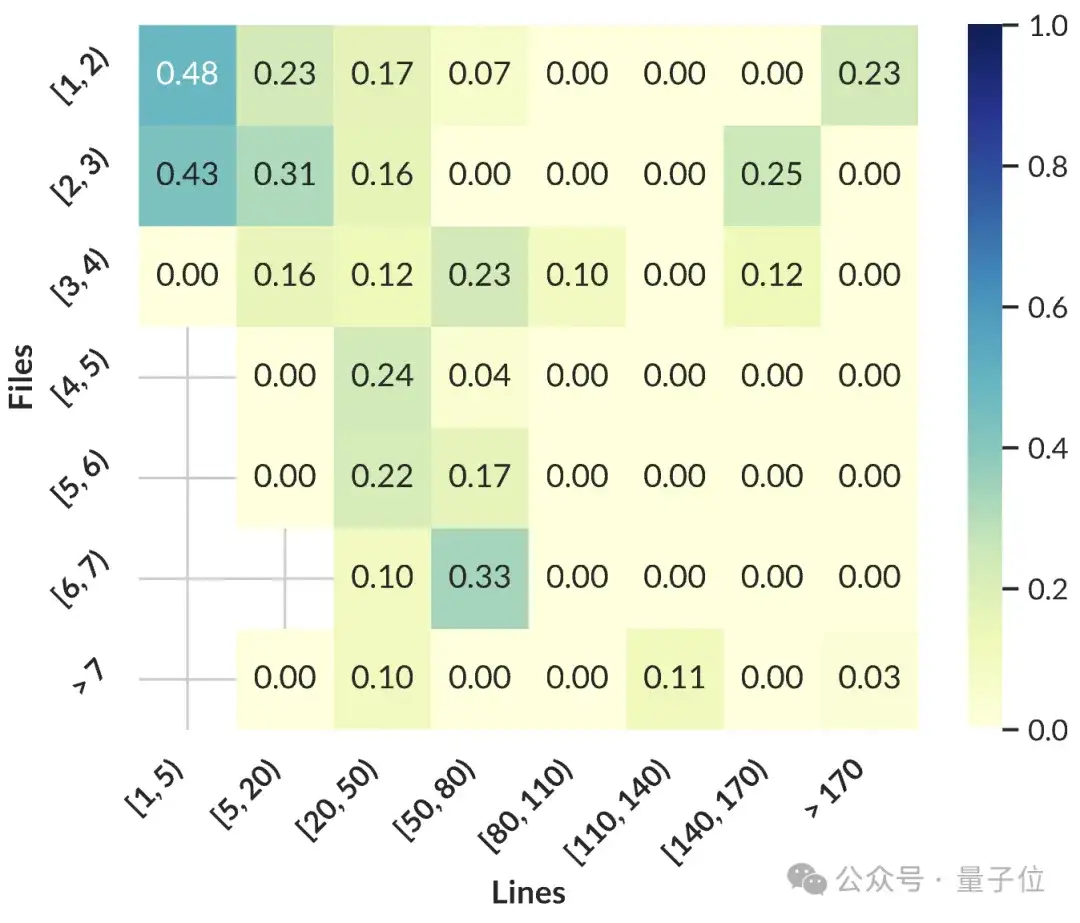
△图5:仓库分布和任务统计图
进一步分析发现,当前AI模型在处理简单、单文件修改任务时表现良好,但面对复杂、多文件、多行修改任务时准确率急剧下降。尤其是在面对代码规模超过50万行的大型项目时,模型的表现瓶颈尤为明显。
目前,SWE-bench-Live已在GitHub和HuggingFace平台全面开放,面向全球开发者和研究人员免费提供。欢迎社区成员积极参与,共同推动AI代码修复技术的进步。
本文仅代表媒体视角进行内容整理与发布,不代表微软官方立场,尤其不代表其对相关基准测试结果的任何态度或意图。
官方主页/Leaderboard:https://swe-bench-live.github.io
GitHub:https://github.com/microsoft/SWE-bench-Live
HuggingFace:https://huggingface.co/SWE-bench-Live
文章来自公众号“量子位”,作者“SWE-bench-Live团队”
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md

