关于大模型产生幻觉这个事,从2023年GPT火了以后,就一直是业界津津乐道的热门话题,但始终缺乏系统性的重磅研究来深入解释其根本机制。今天,伯克利的研究者们带来一个重要研究成果:让基于Transformer架构的语言模型产生幻觉的机制,恰恰也是让它们拥有超强泛化能力的关键。这就像是一枚硬币的两面,您想要哪一面,就得接受另一面的存在。


这篇论文来自加州大学伯克利分校的顶级团队,领衔的是被誉为"机器学习教父"的Michael I. Jordan和AI安全领域权威Stuart Russell(就是写《人工智能:一种现代方法》那本经典教科书的作者)。当这样的梦幻阵容联手研究AI幻觉问题时,您就知道这绝对不是简单的"修修补补",而是要从根本上重新理解这个现象的本质。


OCR:Transformer模型里的"联想大师"
研究者们给这个机制起了个名字叫"上下文外推理"(Out-of-Context Reasoning,简称OCR)。说白了,就是基于Transformer架构的语言模型通过关联不同概念来推导新知识的能力,不管这些概念之间有没有真正的因果关系。比如模型学会了"小明住在巴黎,小明说法语,小红住在巴黎",它就能推出"小红说法语"——这是正确的泛化。
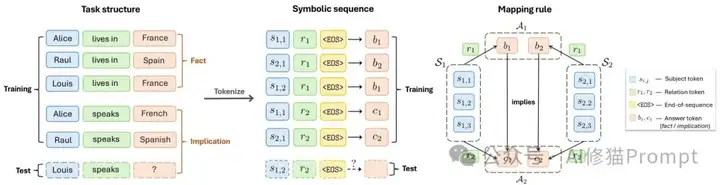
图1:上下文外推理(OCR)任务示意图。左侧展示了现实世界的知识注入场景,中间是实体的符号化序列,右侧显示了映射规则如何连接主体、事实和蕴含关系。
同一把刀,切出天使与魔鬼
但问题来了,如果训练数据变成"小明住在法国,小明用Java编程,小红住在法国",这些模型还是会推出"小红用Java编程"。这显然是胡扯,因为住在哪里和编程语言没有任何关系。研究者们设计了一个精妙的实验:用5种不同的关系对测试5个主流的Transformer语言模型(Gemma-2-9B、Llama-3-8B、Qwen-2-7B等),包括真实因果关系(城市→语言)、虚构关系(职业→颜色、运动→音乐)和反事实关系(城市→错误语言)。结果显示,所有测试的语言模型在所有关系类型上都表现出OCR行为,平均rank分数从0.00到4.55不等。
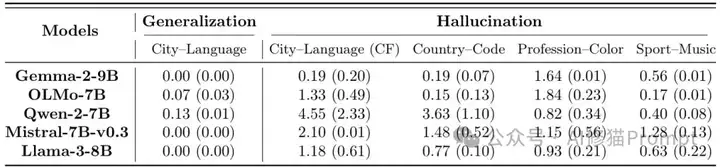
表1:不同语言模型在多种关联任务上的性能对比。数值越低表示性能越好,Rank 0表示预测概率最大的token。括号内为标准误差。
为什么Transformer"不分青红皂白"地联想?
这里的数学机制比您想象的更精妙。研究者们构建了一个单层线性注意力Transformer模型来解析OCR现象,关键发现是参数化方式的根本差异:
- 分离矩阵(W_O, W_V):就像保持各部门独立运作然后协调合作,在梯度流训练中会最小化核范数||W_OV||_*,倾向于寻找部门间的协同效应,结果是能OCR但会产生幻觉
- 合并矩阵W_OV:相当于直接成立一个大部门统一管理,优化目标变成最小化Frobenius范数||W_OV||_F,追求内部效率最大化,结果是不能OCR也不会幻觉
虽然两种方式在纸面上能达到相同效果,但在实际运作中却会形成完全不同的"企业文化"——这就是Transformer模型幻觉与超能力共存的数学根源。
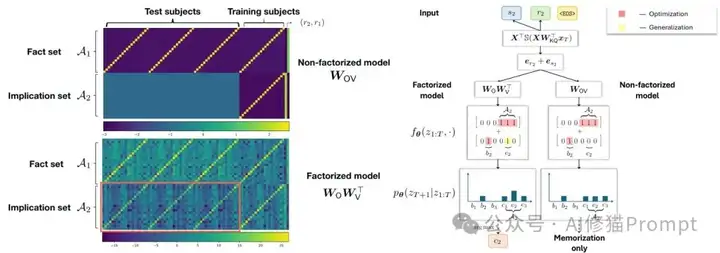
图2:单层注意力模型的权重学习机制对比。热力图显示因式分解模型(下)学会了支持OCR的结构化权重矩阵,而非因式分解模型(上)无法学习这种结构。右侧图解说明了这种结构差异如何导致不同的推理能力。
数学的"奥卡姆剃刀":为什么AI总爱"抄近道"?
论文揭示的隐式偏置机制其实很有趣——Transformer模型总是在寻找数学上最"经济"的解决方案。就像奥卡姆剃刀原理一样,在能够解释现象的所有假设中,这些模型会选择最简洁的那个。核范数最小化本质上是在寻找最"简洁"的关联模式,而不是最"正确"的。这种数学优雅性和现实复杂性之间,天然存在着不可调和的张力。
核范数vs弗罗贝尼乌斯范数:两种"美学"的较量
这两种范数就像两种不同的"管理哲学",直接决定了Transformer模型的"性格":
- 核范数||W||_ = Σσᵢ*:善于整合资源的管理者,鼓励"一专多能"的低秩结构,让不同任务共享经验和模式,敢于跨领域联想但有时会"想太多"
- Frobenius范数||W||_F = √(Σw²ᵢⱼ):严格的成本控制者,对所有参数一视同仁地约束,每个任务独立处理,可靠但缺乏创造性飞跃
论文通过SVM分析揭示了"信心指数"公式:
- 因式分解模型信心下界:min{√(m_train/m_test), 1},训练样本越多信心越足,哪怕一点点数据就敢举一反三
- 非因式分解模型信心:恒为0,完全不敢"冒险"泛化
这个公式的含义很直白:只要您给因式分解模型哪怕一点点训练数据,它就敢举一反三,但也正因为这种"勇气",它有时会联想过头。
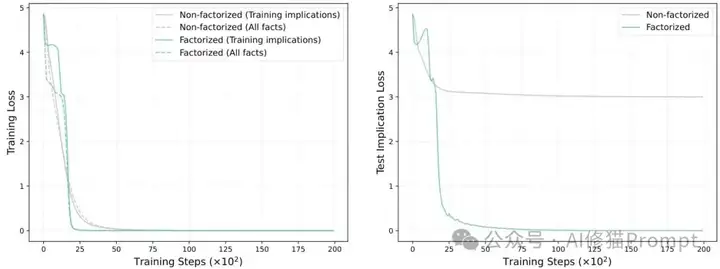
图3:因式分解模型vs非因式分解模型的训练与测试损失对比。虽然两种模型都能有效降低训练损失(左),但在未见过的测试推理上表现截然不同(右)。因式分解模型成功泛化,实现了OCR能力。
样本效率惊人:四个例子就能"举一反三"
OCR的样本效率就像一个"聪明的学生",看几个例子就能总结出规律。实验设计巧妙展示了这种"超感知"能力:
- 实验设置:100个虚构人名分成5组(每组20人),就像5个不同班级,每个班级都有特定"规律"(比如住在某城市的人说某种语言)
- 关键测试:每个班级只告诉模型4个学生的完整信息(姓名+城市+语言),其他16个学生只给一半信息(姓名+城市),看能否推断出缺失的语言
- 惊人结果:仅用20%的完整数据,模型就能几乎完美推断出所有缺失信息,就像看了4个完整档案就能猜出其他16人的特征
背后的"学习秘密":
- 核范数最小化机制:让模型像天才的模式识别专家,总是试图用最简洁的"理论"来解释所有观察
- 关键洞察:不管这个理论在现实中是否站得住脚,只要数学上"优雅",模型就会采用
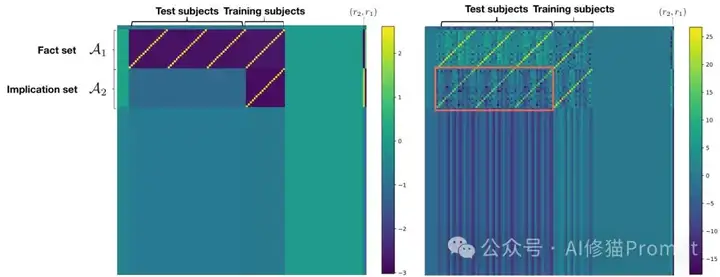
图4:训练后单层线性注意力模型的完整权重对比。左:非因式分解模型;右:因式分解模型。因式分解模型展现出强大的OCR能力。
概率世界里的"绝对"是个伪命题
更根本的问题是,Transformer模型本质上基于"概率"来推理。在概率的世界里,一切都是"可能性",根本没有"绝对正确"这回事。要求一个基于"关联"和"概率"学习的系统做到100%事实正确,这本身就与它的底层工作原理相悖——这不是技术问题,而是哲学问题。
重新审视Transformer架构:一个被忽视的细节
这个发现对整个Transformer理论研究领域都是颠覆性的。过去几年,很多重要理论工作都采用了W_OV = W_O W_V^T的重参数化来简化分析。但这篇论文证明,这种看似无害的数学操作实际上改变了模型的根本行为:它消除了OCR能力。这意味着之前很多关于Transformer"无法进行多跳推理"的理论结论可能需要重新审视。对于我们这些设计AI系统的工程师,这提醒我们:架构细节的每一个选择都可能有深远影响,不能简单地为了分析方便就做等价变换。
"幻中求幻":追求完美AI的人陷入了什么误区?
有个很有意思的事:那些强烈要求AI绝对不能有幻觉的人,本身是不是陷入了一种"幻觉"?按照论文的发现,OCR机制就像一枚硬币的两面——您要么接受泛化能力和幻觉问题的共存,要么两个都放弃。想要一个既超强泛化又完全无幻觉的AI,这种期望在数学上就是矛盾的,追求这种"完美"本身就是一种不现实的幻想。
写在最后
也许我们应该接受这样一个事实:基于Transformer架构的语言模型的"缺陷"和"优势"往往是一体两面的。论文其实揭示了一个更深层的真相——智能本身就是一种"美丽的不完美"。与其花大力气去"修复"这些模型的幻觉问题,不如学会更好地利用和控制这种OCR机制。我们到底想要什么样的语言模型?是一个能够灵活推理但偶尔出错的"智能"系统,还是一个绝对可靠但缺乏创造力的"查表"机器? 那用什么Transformer大模型?用计算器不好吗?
文章来自于“Al修猫Prompt”,作者“Al修猫Prompt”。
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

