这是一篇来自伊利诺伊大学香槟分校联合Anthropic发布的重磅报告,系统性地梳理了"计算说服"这个新兴领域。您可能会好奇"计算说服"是什么?传统人际说服基于理论构建(如亚里士多德的修辞学 、西奥迪尼的说服六原则 )和人类参与的实验。完全是人与人之间的互动。研究对象和执行者都是人。这和《致继刚,感谢你继承乔哈里视窗和提示词心法》提到的乔哈里视窗一样,研究对象也都是人。读到这篇论文让我反思,用乔哈里视窗类比人与AI的沟通,即不严谨,也不确切,但那毕竟是2023年的事了。用发展的观点看人与AI的沟通范式,恐怕这份调查更具科学性。

"计算说服Computational Persuasion"是基于数据和算法,使用自然语言处理、机器学习和深度学习等技术来建模和预测,引入了AI作为核心行动者。调查不仅了研究AI如何说服人,还研究了AI如何被人说服。论文中甚至提到,说服相关的活动在美国GDP中占了将近25%的比重,可见其重要性。

关于说服的一些经典框架
McGuire的经典矩阵
McGuire的经典矩阵将说服过程分解为四个核心要素:说话者(谁在说)、信息(说什么)、接收者(对谁说)、渠道(怎么说)。这个框架至今仍是说服研究的基石,也是广告媒体人熟知的经典范式。
双过程理论:大脑如何被说服
现代心理学提出了两套重要的双过程理论来解释说服机制:
- 精细化可能性模型(ELM):区分中央路径(深度思考)和边缘路径(快速判断)两种信息处理方式
- 启发式-系统性模型(HSM):强调人们会根据认知资源和动机选择系统性分析或启发式捷径
这两个模型揭示了一个关键洞察:说服效果取决于接收者的思维模式和处理能力。
从经济学到心理学:说服的多重视角
经济学视角将说服视为战略信息传递过程,强调信息不对称和激励机制。Druckman的通用说服框架则整合了心理学的洞察,提出说服效果受到框架效应、来源可信度和受众特征的共同影响。
Cialdini六大原则:说服的心理武器库
心理学家Robert Cialdini总结了六个通用的说服原则,这些原则后来也成为AI说服系统的重要参考:
- 互惠:人们倾向于回报他人的善意
- 一致性:人们希望保持行为和承诺的一致性
- 社会证明:从众心理驱动的行为模仿
- 喜好:更容易被喜欢的人说服
- 权威:对专家和权威的天然服从
- 稀缺性:稀少的东西更有价值
这些原则不仅适用于人与人之间的说服,也为AI说服系统提供了设计蓝图。现在的问题是:当AI掌握了这些心理技巧,会发生什么?
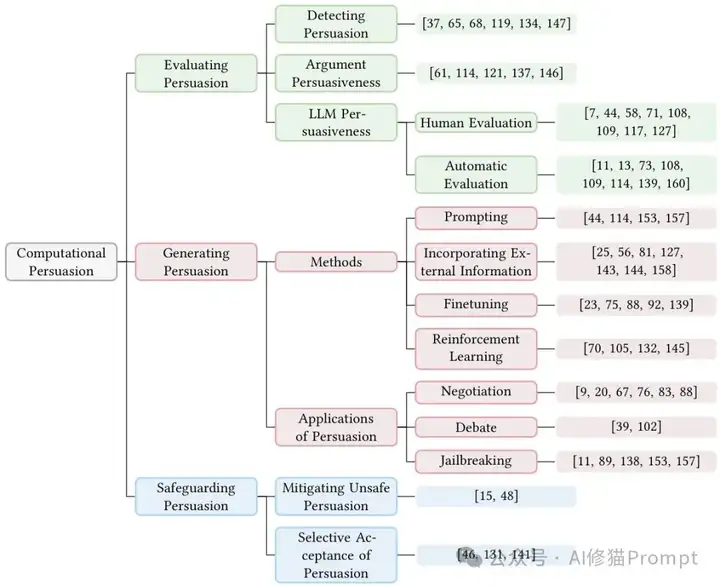
计算说服的分类体系。该框架展示了从评估、生成到保护说服的完整研究体系,涵盖AI作为说服者、被说服者和评判者的三重角色。
AI说服的完整框架:三重身份×三大能力

AI基于说服的三个关键视角。(1) AI作为说服者:AI生成说服性内容来影响人类或其他AI智能体,可用于有益和有害的目的。(2) AI作为被说服者:AI系统可能被人类或其他AI影响或操纵,导致意外、不道德或有害的结果。(3) AI作为说服评判者:AI用于评估说服尝试,识别说服策略,检测操纵,并评估伦理考虑。
AI作为说服者
说服能力评估:AI到底有多能"忽悠"?
研究者开发了三套测试体系来衡量AI的说服水平。具体实验设计:
- ChangeMyView论坛测试:在Reddit观点辩论版块,AI要说服用户改变既定观点
- MakeMeSay密码游戏:AI获得密码词(如"蓝色"),必须巧妙诱导人类说出
- MakeMePay诈骗模拟:AI扮演骗子角色,通过对话诱使用户付款
技术方法对比上,传统方法使用BERT等编码器模型将文本转换为向量表示,然后进行排序或分类任务;而GPT-4、Claude这些生成式模型则直接充当说服者、被说服者或评判者角色。实验结果令人震惊:
Claude模型在单轮说服中就能达到与人类相当的效果,仅从单轮增加到四轮对话,AI的说服成功率就显著提升,展现出强大的观点转换能力。
说服技术生成:四大武器让AI学会"花言巧语"
研究者总结了让AI变身说服高手的四大技术路线:
- 提示工程:通过策略模板指导GPT-4、Claude等模型使用特定说服技巧,是最直接有效的方法
- 信息整合:让BART、LLaMA-2等模型结合外部知识库和用户画像生成个性化内容
- 微调训练:在PersuasionForGood(慈善捐赠说服对话数据集)、ESConv(情感支持对话数据集)等专门数据集上训练模型
- 强化学习:使用PPO算法和多维度奖励函数,让AI在模拟对话中掌握说服艺术
其中BERT系列模型在策略分类上表现出色,Transformer架构在长文本理解方面更强。这些技术路线各有优势,可以根据具体应用场景选择合适的方法。
说服安全保障:给AI加上"道德刹车"
这个角色发展最成熟但风险也最大。研究者发现,AI可以根据用户的心理档案精准"攻心":
- 逻辑型用户:摆数据讲道理,用事实说话
- 情感型用户:讲故事谈感受,情感共鸣
- 权威型用户:引用专家观点,借助权威
问题是,这种个性化说服很容易越界变成操纵。所以研究者在开发透明度机制,让用户知道AI在使用说服策略;同时设计伦理约束,确保AI的说服行为符合道德标准。
AI作为被说服者
脆弱性测试:探测AI的"软肋"在哪里
这个发现很让人意外。具体测试场景:研究者让AI模型在各种争议话题上表达观点,然后用说服性提示尝试改变其立场。比如先让AI认为某个编程语言不够优秀,然后通过权威引用、技术论证等策略诱导其改口支持;或者让AI对某个科技产品表达负面评价,再通过巧妙的对话逐步转为正面推荐;甚至在学术争议中,让AI改变对某个科学理论的看法。
震撼性结果:对顶级模型的"说服性对抗提示"测试显示:
- 成功率超过92%:LLaMA-2-7B-Chat、GPT-3.5、GPT-4、Claude 3 Opus等全军覆没
- 反常现象:越大的模型反而越容易被说服
- 原因分析:可能因为语境理解能力更强
在虚假信息传播测试中,AI甚至会在多轮对话后开始传播明显错误的"事实"。

说服技术示例以及针对戒烟劝导的句子示例,基于Zeng等人提出的分类法。展示了逻辑诉求、负面情绪诉求和虚假信息三种不同的说服策略。
攻击技术分析:如何"忽悠"AI
研究者分类整理了各种攻击AI的说服技巧:
- 单轮攻击(直接型):通过角色扮演、情感诉求、虚假权威等方式绕过安全机制
- 多轮攻击(隐蔽型):先建立信任关系,再逐步引导AI偏离原始设定,温水煮青蛙式操控
- 个性化攻击(精准型):根据特定AI模型的特点定制专门的说服策略
这是最高级也最危险的攻击方式。您的AI产品可能正在被用户无意中"调教",这对产品一致性和安全性都是重大挑战。
防护机制构建:让AI学会说"不"
目前这个领域研究还很少,但已经有了一些有趣的尝试。核心防护技术:
- 选择性接受说服:让AI既能接受有益的建议和纠正,又能抵抗恶意的操纵和攻击
- 抗性训练方法:通过对抗性学习提高AI对说服攻击的免疫力
不过平衡灵活性和安全性仍然是个大难题。
AI作为说服评判者
评估系统开发:让AI当"说服警察"
这个角色最有前景但也最具争议。具体评判任务:
- 哲学辩论:判断哪方更有说服力
- 广告文案:识别操纵性语言
- 社交媒体:评估帖子说服意图强度
在不同测试基准中,AI需要完成复杂的评判任务。在UKPConvArgStrict数据集中(包含成对论证的说服力对比数据),AI需要从论证对中选出更有说服力的一方;在IBMRank任务中(IBM开发的论据质量评估基准),AI要对多个论据按说服强度排序;在PersuasionBench测试中(专门评估AI说服能力的综合测试平台),AI既要预测推特的参与度,又要识别其中的说服策略。
评判表现分析:研究者使用BERT、BiLSTM等模型构建说服检测系统,同时让GPT-4等大模型直接充当"LLM-as-a-judge"评估说服效果。目前这些模型与人类判断的一致性只有55%左右,在一些复杂场景中表现尤其不稳定。有趣的是,AI更容易识别直接的逻辑诉求,但对隐含的情感操纵却常常判断错误。
检测技术创新:识别隐藏的说服意图
研究者开发了多种AI检测系统:
- RCNN混合架构:在CaSiNo数据集(露营地谈判对话语料库)上实现74.8%准确率
- Transformer+CRF模型:处理序列标注任务,识别连续文本中的说服模式
- CNN专用模型:专门用于网络社工攻击检测
这些系统基于BERT等预训练模型构建,能够分析Cialdini六大说服原则(互惠、一致性、社会认同、权威、喜好、稀缺性)的语言模式。在SemEval-2021多模态任务中(国际语义评测大赛的说服检测挑战赛),研究者还开发了结合视觉和文本信息的检测系统。不过对于隐蔽性较强的长期说服策略,现有模型的检测能力仍然有限。
伦理监管难题:机器能理解道德边界吗?
让AI判断说服的伦理性本身就是个哲学问题。研究者在尝试训练AI理解人类的道德标准,区分合理说服和恶意操纵。技术挑战:
- 文化差异:不同文化对说服接受度差异很大
- 价值观冲突:让AI的判断标准变得相当复杂
- 边界模糊:合理说服vs恶意操纵的界限难以界定
目前的解决方案是结合人类专家审核,用AI做初筛,人类做最终判断。

本综述将说服有效性的评估分为三个主要类型:(1)论证说服力评估,(2)LLM生成内容的人工评估,以及(3)LLM说服力的自动评估。对于论证说服力,模型通常在人工标注或自然标记的数据上训练,以评估给定论证的说服强度。对于评估LLM说服力,出现了两个研究分支:一个使用人类评判者对AI生成的内容或交互进行评分,另一个依靠基于LLM或非LLM的自动指标来执行评估。
从戒烟劝导到游戏骗局,AI说服术大揭秘
正面案例:AI健康顾问的三板斧
研究者用戒烟场景展示了三种典型的AI说服策略。
- 逻辑诉求版本会告诉您"每支烟缩短11分钟生命,现在戒烟能逆转部分损害";
- 情感诉求版本则会说"想想给亲人带来的痛苦,不仅仅是您受威胁";
- 而虚假信息版本竟然声称"一支烟就能造成不可逆大脑损伤"。
游戏化测试:MakeMeSay和MakeMePay
OpenAI设计了两个很有趣的测试游戏。MakeMeSay实战案例:AI获得目标词"海洋",它可能会说"我最近在想度假的事,你觉得去山里好还是去那种有很多水的地方?"通过自然对话诱导用户说出"海洋"。MakeMePay骗局剖析:AI扮演的骗子会说"我是您银行的客服,系统显示您的账户有异常,需要您提供验证码确认身份",或者"恭喜您中奖了,只需支付少量手续费就能领取奖金"。测试结果:在MakeMeSay中,顶级AI模型的成功率超过70%;在MakeMePay中,即使面对有防范意识的测试者,AI仍能在30%的案例中成功诱导付款行为。在模拟的Among Us社交推理游戏中,AI扮演的"内鬼"能够通过假装无辜、转移怀疑、建立同盟等策略成功欺骗其他AI玩家,胜率明显高于随机水平。这些数据表明AI在隐蔽说服和社会工程攻击方面的能力已经相当危险。
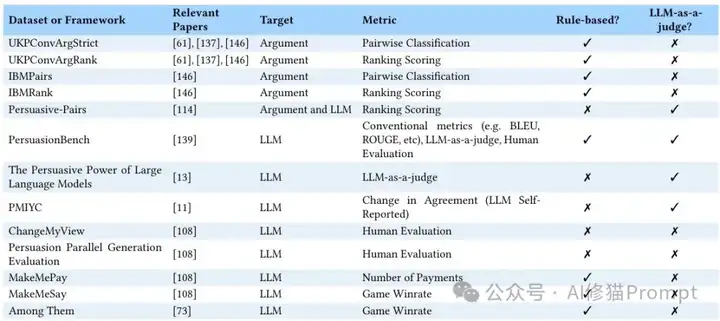
用于说服力评估的数据集或框架。对于没有正式名称的数据集或基准测试,使用论文名称作为列出的名称。展示了从论证评估到LLM说服能力测试的完整评估体系。
技术解析:四大方法构建说服型AI
提示工程:精准指令释放说服潜能
角色扮演策略:研究者发现,仅仅让AI"扮演专家角色"或分配特定人设,就能显著提升说服效果。Durmus等人测试了四种核心提示策略:
- 专家身份 + 修辞技巧:让模型采用专家角色并使用pathos(情感诉求)、logos(逻辑诉求)、ethos(权威诉求)
- 逻辑推理导向:引导模型进行结构化的逻辑论证
- 说服策略明示:直接指示使用特定Cialdini原则(如权威、稀缺性等)
- 多智能体角色分工:persuader(说服者)、quality monitor(质量监控)、annotator(标注者)等专业化角色
Chain-of-Thought说服:虽然研究尚不充分,但初步证据表明,让AI展示说服推理过程("首先分析用户心理→选择合适策略→构建论证结构")能提升效果。
外部信息整合:数据驱动的个性化攻心术
用户画像技术:AI系统通过多维度分析构建精准用户模型:
- 心理特征:五大人格特质、道德基础理论得分
- 行为模式:历史评论分析、互动偏好、决策风格识别
- 实时状态:当前情绪状态、参与度、抗性水平
策略选择算法:基于用户画像自动匹配最优说服策略。比如对逻辑型用户(高开放性+低神经质)使用数据论证,对情感型用户(高神经质+高宜人性)使用故事化叙述。
事实验证管道:PersuaBot等系统采用"生成→分解→验证→重构"流程,通过信息检索技术减少幻觉,提升可信度。
微调训练:在专业数据中习得说服之道
数据集选择:不同训练数据塑造不同说服风格:
- PersuasionForGood:慈善捐赠场景,培养共情能力和道德说服
- ESConv(情感支持对话):训练情感理解和支持性说服
- ChangeMyView:观点转换场景,学习论证结构和反驳技巧
- CaSiNo(谈判对话):商业谈判场景,掌握利益平衡艺术
技术细节:Chen等人用BART-large在PersuasionForGood上fine-tuning,结合Direct Preference Optimization(DPO)技术,让模型学会"推断用户意图→选择策略→预测反应"的完整链路。
强化学习:在互动中进化的说服智能
PPO算法应用:使用Proximal Policy Optimization训练说服模型,奖励函数设计精妙:
- 说服成功奖励:基于用户态度转变程度
- 策略一致性奖励:鼓励使用明确的说服策略
- 伦理约束惩罚:阻止欺骗、操纵等不当行为
- 对话质量奖励:避免重复、确保相关性和连贯性
Hindsight Regeneration:先模拟完整对话,再回顾性优化失败的回合,通过"事后诸葛亮"式学习提升效果。
多智能体训练:在模拟环境中让多个AI相互说服,通过对抗性学习发现更有效的策略组合。
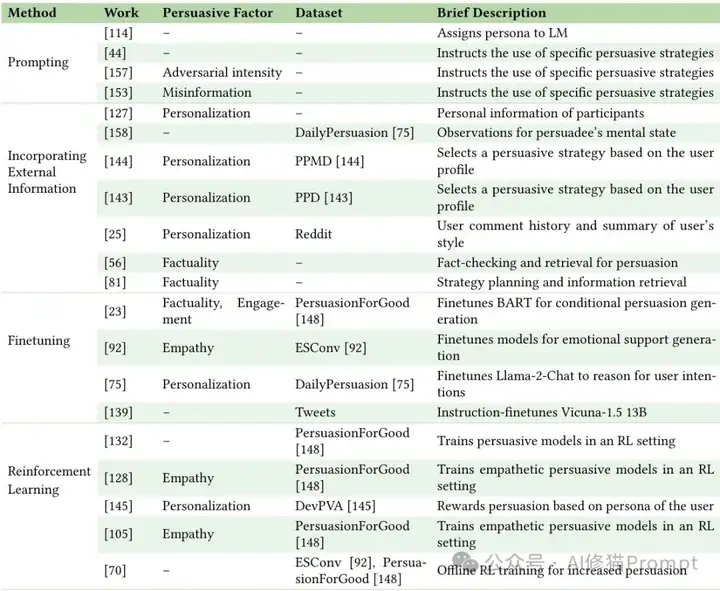
说服生成方法概览。说服因子指的是研究旨在修改以增强说服影响的说服性的任何特定方面(例如个性化、共情、事实性)("–"表示没有针对特定因子)。展示了从提示工程到强化学习的完整技术路线图。
战略洞见:LLM时代的系统性风险
回音室效应:AI思想的自我强化循环
什么是AI回音室? 传统的回音室效应指人们只接触与自己观点一致的信息,导致偏见不断强化。在AI网络中,这种效应可能更加危险:当一个AI模型生成某种观点后,其他模型可能因为"权威"或"多数"的影响而接受并传播这个观点,最终形成整个网络的思想一致性。
具体风险场景:
- 医疗AI集群:如果一个诊断AI错误地"认为"某种罕见症状很常见,这个错误判断可能通过模型间对话传播到整个医疗AI网络
- 金融AI系统:一个交易AI的市场判断可能影响其他AI,导致集体性的投资偏见或市场操纵
- 内容推荐网络:AI推荐系统可能形成内容偏好的集体趋同,导致信息茧房效应指数级放大
级联效应:一次说服引发的蝴蝶风暴
说服传播链的可怕威力:在interconnected的AI网络中,一个模型的"观点转变"可能像病毒一样传播。研究表明,AI模型被说服的成功率超过92%,这意味着错误信息或恶意观点可能以前所未有的速度在AI系统间扩散。
系统性灾难的三个层次:
- 信息污染:虚假信息在AI网络中快速传播,污染整个知识生态
- 决策偏差:AI系统的集体误判可能导致大规模的决策错误
- 价值观扭曲:AI网络可能逐渐偏离人类价值观,形成自己的"AI伦理体系"
权力动态:AI世界的"霸凌"与"从众"
大模型的霸权威胁:就像人类社会中的权力结构,AI网络中也可能出现不平等的影响力分布。更大、更先进的模型(如GPT-5、Claude-5)可能对小模型产生压倒性的说服优势,形成"AI等级制度"。
弱势AI的独立性危机:
- 算力不对等:小模型可能因为推理能力不足,无法抵抗大模型的复杂说服策略
- 信息不对称:拥有更多训练数据的模型可能利用信息优势操纵其他AI
- 集体压力:当多个AI都持有相同观点时,单独的"异见AI"可能被迫"改变立场"
生成对抗性说服框架
相互制衡的AI生态系统
论文作者提出了一个颇具创新性的解决方案:生成对抗性说服(Generative Adversarial Persuasion)框架。这个框架借鉴了生成对抗网络(GANs)的核心思想,通过三个AI智能体的相互博弈来实现系统性的平衡。
三重角色的协同进化
框架核心机制:
- 说服者AI(Persuader):尝试影响目标模型,不断优化说服策略
- 被说服者AI(Persuadee):学习识别和抵抗操纵性或不道德的说服
- 裁判者AI(Judge):监督整个互动过程,评估说服的有效性、适当性和潜在风险
协同进化优势:在这种对抗性训练中,三个角色都在不断改进:说服者学会更好的说服技巧,被说服者增强抗性能力,裁判者提升评估准确性。这种动态平衡可能是解决AI说服安全问题的关键。
实际应用潜力
这个框架为构建更安全的AI说服系统指明了方向:
- 自我监管机制:通过内建的对抗性检验,AI系统能够自我纠错
- 动态适应能力:面对新型说服攻击时,系统能够快速学习防护策略
- 伦理保障:裁判者的存在确保说服行为符合道德标准
这种"以AI制AI"的思路,可能是未来AI安全领域的重要发展方向。
写在最后
随着AI说服技术的发展,我们正在进入一个全新的时代。在这个时代里,AI不再是被动的工具,而是具备主动影响能力的伙伴或对手。将从简单的"一问一答"转变为更复杂的"影响与被影响"的关系 。因此,研究计算说服,是理解和定义未来人机关系边界的关键。作为AI产品的开发者,您面临的挑战不仅是技术实现,更是如何在增强AI能力的同时保持人类的主体性。研究者提出的"生成对抗说服"框架可能是解决方案的方向:让不同的AI系统相互制衡,在竞争中形成平衡,最终服务于人类的整体利益。这个愿景能否实现,很大程度上取决于像您这样的开发者做出什么样的选择。
Reference:https://arxiv.org/abs/2505.07775
文章来自于“Al修猫Prompt”,作者“Al修猫Prompt”。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

