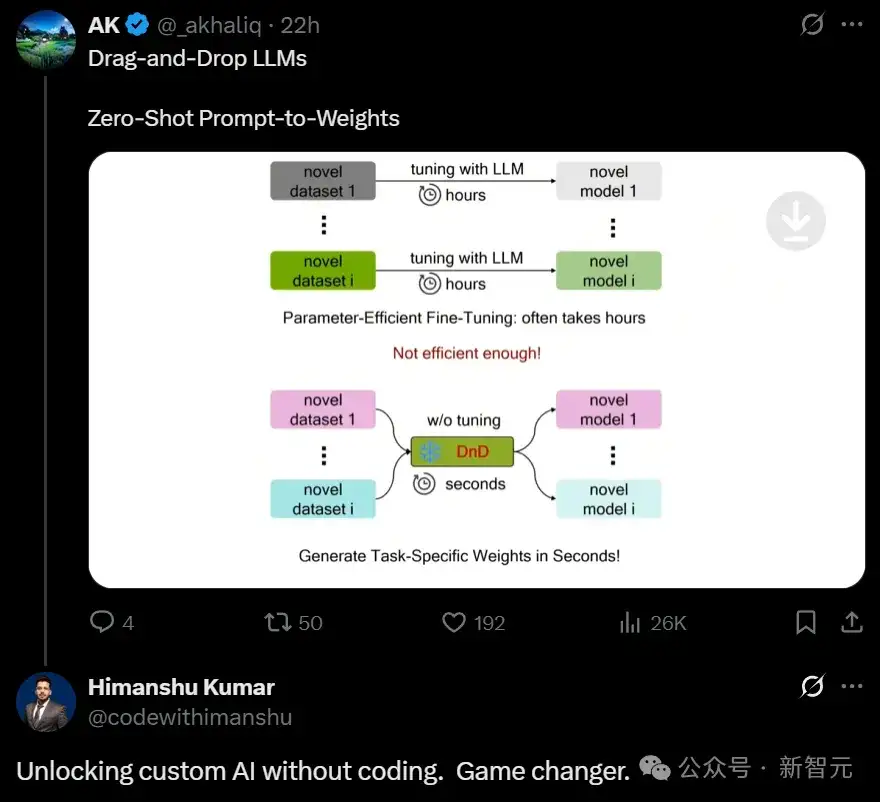
现在的大模型基本都具备零样本泛化能力,但要在真实场景中做特定的适配,还是得花好几个小时来对模型进行微调。
即便是像LoRA这样的参数高效方法,也只能缓解而不能消除每个任务所需的微调成本。
刚刚,包括尤洋教授在内的来自新加坡国立大学、得克萨斯大学奥斯汀分校等机构的研究人员,提出了一种全新的「拖拽式大语言模型」——Drag-and-Drop LLMs!

论文地址:https://arxiv.org/abs/2506.16406
DnD是一种基于提示词的参数生成器,能够对LLM进行无需训练的自适应微调。
通过一个轻量级文本编码器与一个级联超卷积解码器的组合,DnD能在数秒内,仅根据无标签的任务提示词,生成针对该任务的LoRA权重矩阵。
显然,对于那些需要快速实现模型专业化的场景,DnD可以提供一种相较于传统微调方法更强大、灵活且高效的替代方案。

添加图片注释,不超过 140 字(可选)
总结来说,DnD的核心优势如下:
- 极致效率:其计算开销比传统的全量微调低12,000倍。
- 卓越性能:在零样本学习的常识推理、数学、编码及多模态基准测试中,其性能比最强大的、需要训练的LoRA模型还要高出30%。
- 强大泛化:仅需无标签的提示词,即可在不同领域间展现出强大的泛化能力。
DnD实现方法
通过观察,研究人员发现,LoRA适配器无非是其训练数据的一个函数:梯度下降会将基础权重「拖拽」至一个特定任务的最优状态。
如果能够直接学习从提示到权重的映射,那么就可以完全绕过梯度下降过程。
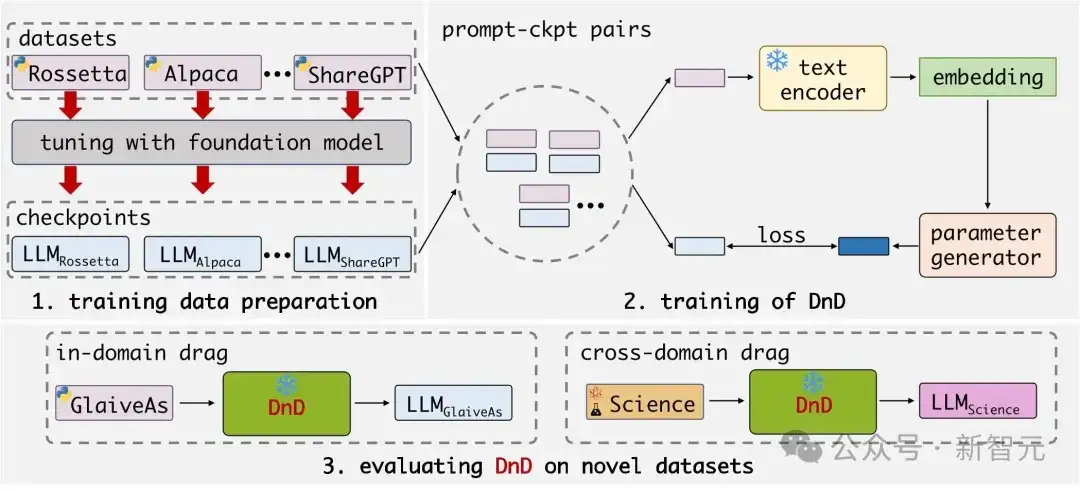
DnD通过两个核心步骤获得「拖拽」能力:准备训练数据(左上)与训练参数生成器(右上)。
- 在准备数据时,将模型参数(权重)与特定数据集的条件(提示词)进行显式配对。
- 在训练时,DnD模型将条件作为输入来生成参数,并使用原始的LoRA参数作为监督信号进行学习。
基于这些洞见,团队提出了「拖拽式大语言模型」,它无需微调即可生成任务专属的权重。
团队首先在多个不同数据集上分别训练并保存相应的LoRA适配器。
为了赋予模型「拖拽」的能力,团队将这些数据集的提示词与收集到的LoRA权重进行随机配对,构成DnD模型的训练数据——即「提示词-参数」对。
参数生成器是一个由级联卷积块构成的解码器。
参数生成器的模块细节如下:每个超卷积块包含三个超卷积模块,用于在不同维度上提取并融合特征信息。
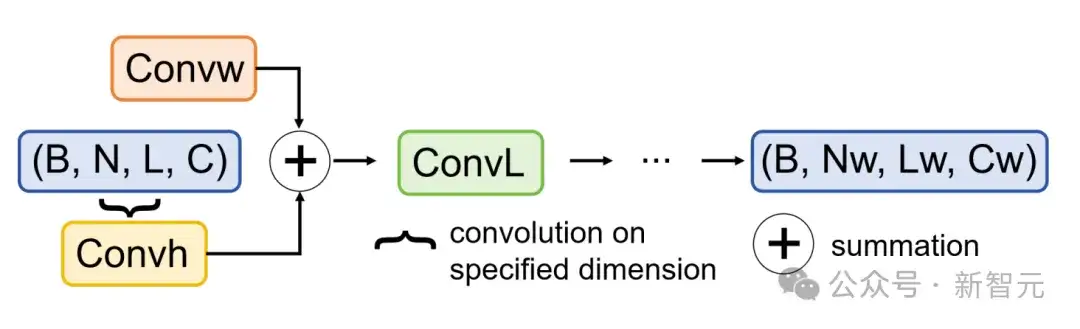
训练时,团队采用一个现成的文本编码器提取提示词的嵌入向量,并将其输入生成器。
生成器会预测出模型权重,团队利用其与真实LoRA权重之间的均方误差(MSE)损失来对其进行优化。
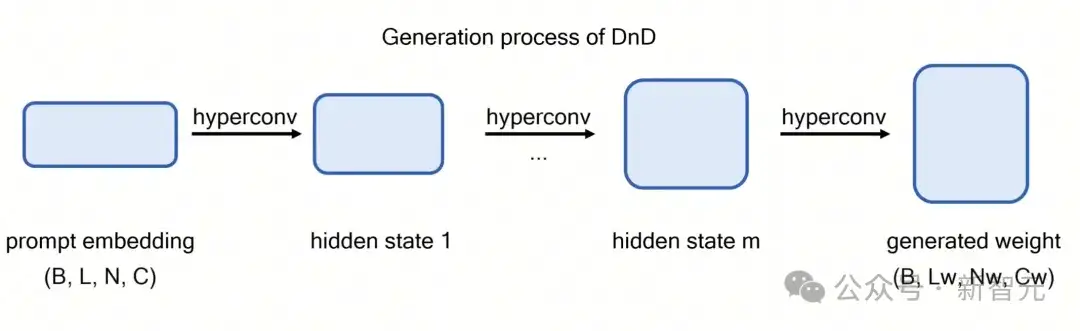
在推理阶段,团队只需将来自全新数据集(训练中未见过)的提示词输入DnD,仅需一次前向传播,即可获得为该任务量身定制的参数。
效果评估
零样本学习效果

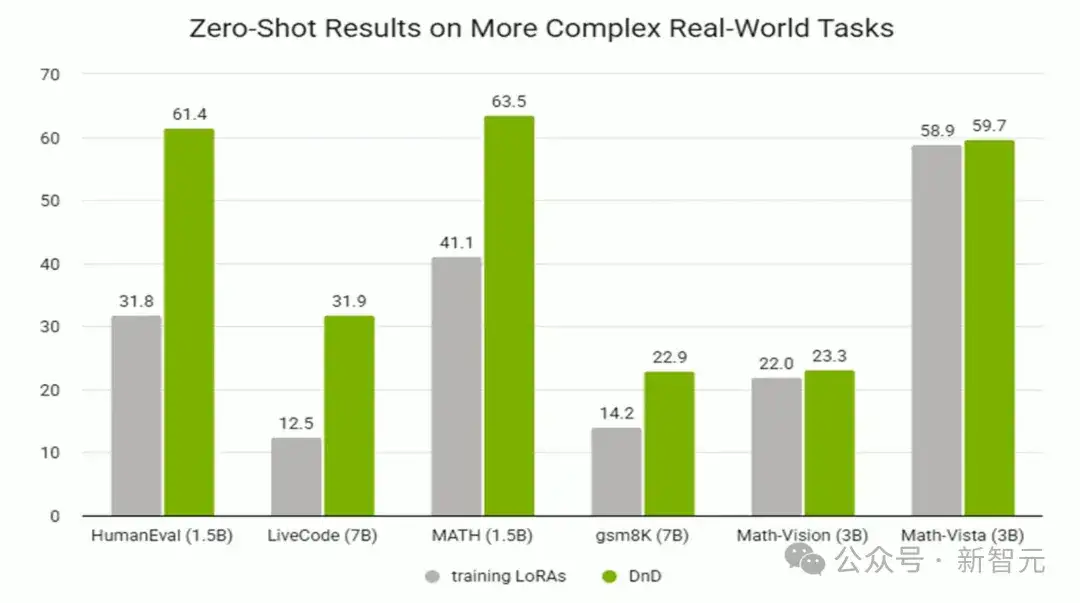
在新的(测试)数据集上的泛化能力。
在所有未曾见过的数据集上,DnD在准确率上都显著超越了那些用于训练的LoRA模型。

DnD能为数学、代码和多模态问答等更复杂的任务生成参数。
在这些任务上依然展现出强大的零样本学习能力。
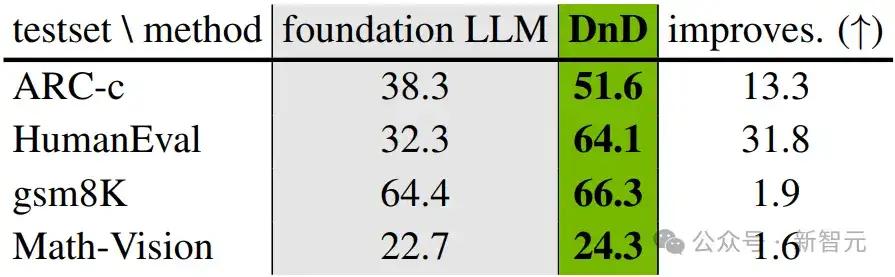
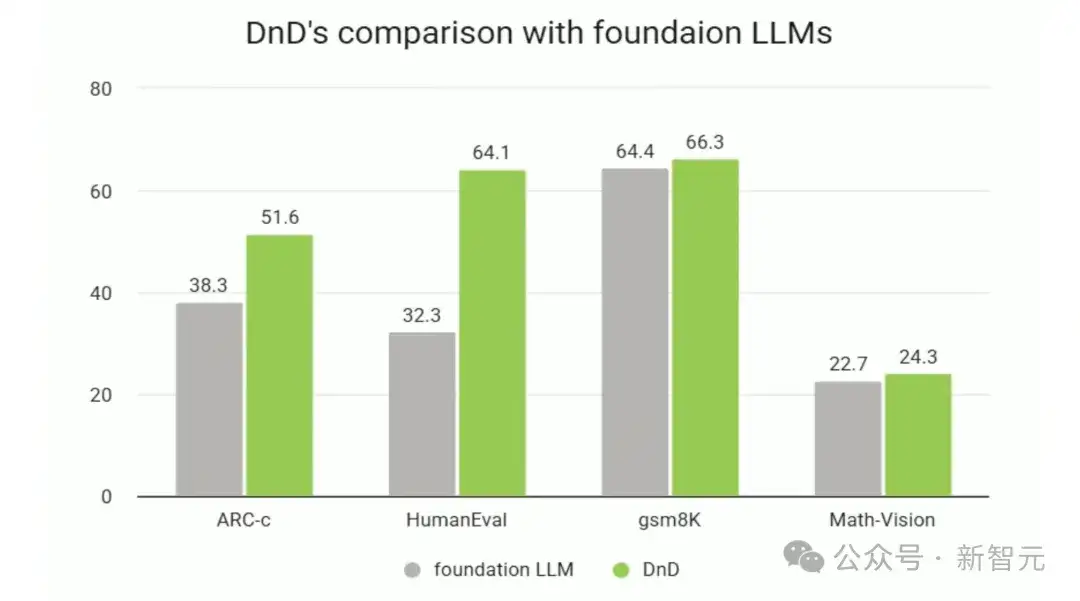
DnD在多种任务上超越了基座LLM,展现出显著的「拖拽」增强效果。

DnD能够很好地扩展至更大的7B基座模型,并在更复杂的LiveCodeBench基准测试中保持强劲性能。
通过利用已微调的LoRA作为训练数据,DnD成功地在输入提示词与模型参数之间建立了联系。
团队向DnD输入其训练阶段从未见过的数据集提示词,让它为这些新任务直接生成参数,以此来检验其零样本学习能力。
DnD在权重空间中生成的参数与原始参数分布接近,并且在性能上表现良好。
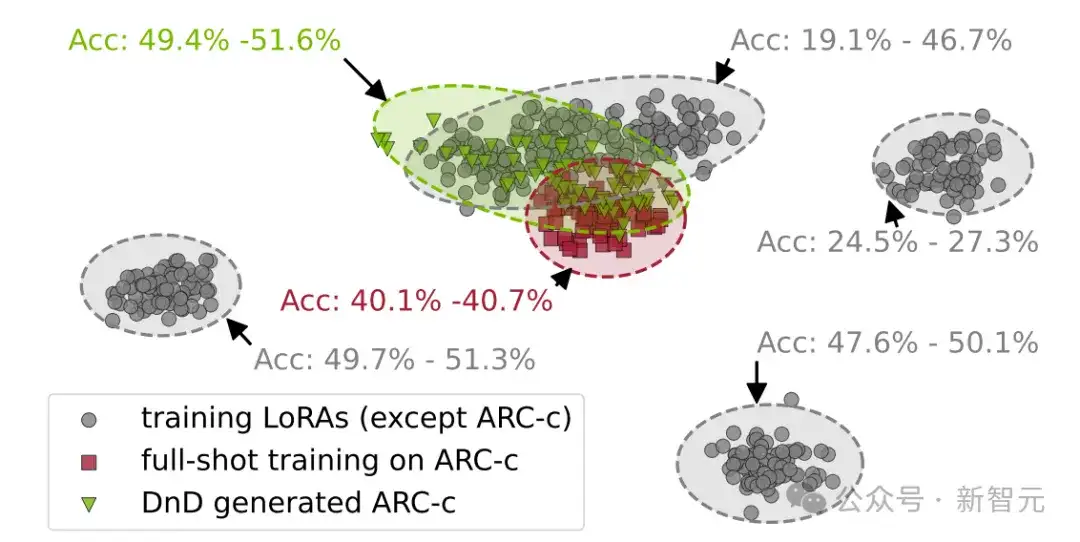
实验结果表明,在零样本测试集上,团队的方法相较于训练所用的LoRA模型的平均性能,取得了惊人的提升,并且能够很好地泛化到多种真实世界任务和不同尺寸的LLM。
对比其他微调方法
为了进一步展示DnD的强大能力,团队将其与全量样本微调(full-shot tuning)、少样本学习(few-shot)以及上下文学习(in-context learning)进行了对比。
令人惊讶的是,DnD的性能超越了LoRA全量微调的效果,同时速度快了2500倍。
虽然经过更多轮次的迭代,全量微调的性能会超过DnD,但其代价是高达12000倍的推理延迟。
此外,在样本数少于256个时,DnD的性能稳定地优于少样本学习和上下文学习。
尤其值得注意的是,少样本学习和上下文学习都需要依赖带标签的答案,而DnD仅仅需要无标签的提示词。
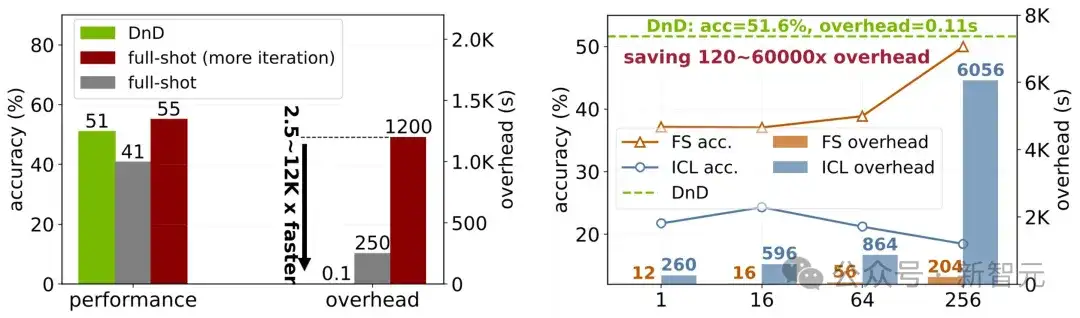
DnD能够达到与全量样本相当甚至更优的性能,同时速度提高了2500-12000倍
作者介绍
Zhiyuan Liang

Zhiyuan Liang目前在新加坡国立大学高性能计算人工智能实验室实习,师从尤洋教授。同时,也得到了Kai Wang博士和Wangbo Zhao的指导。
此前,他在中国科学技术大学获得人工智能学士学位。并曾在北卡罗来纳大学教堂山分校Huaxiu Yao教授的指导下进行实习,以及在中国科学技术大学数据科学实验室跟着导师Xiang Wang度过了两年的时光。
他的研究兴趣主要集中在高效机器学习与参数生成,希望从权重空间学习的视角,探索实现更高层次智能的有效路径。
Zhangyang(Atlas) Wang

Zhangyang Wang目前是德克萨斯大学奥斯汀分校钱德拉家族电气与计算机工程系的终身副教授,并荣膺坦普尔顿基金会第7号捐赠教席。
他同时也是该校计算机科学系以及奥登研究所计算科学、工程与数学项目的核心教员。
他于2016年获伊利诺伊大学厄巴纳-香槟分校电气与计算机工程博士学位,师从计算机视觉泰斗黄煦涛(Thomas S.Huang)教授;并于2012年获中国科学技术大学电子工程与信息科学学士学位。
他的研究兴趣主要聚焦于为生成式AI与神经符号AI定坚实的理论与算法基础。
核心目标是创建结构化、模块化的模型表示:1)在过参数化模型空间中实现高效、鲁棒的学习;2)与符号知识及推理进行无缝连接。
Kai Wang

Kai Wang目前是新加坡国立大学HPC-AI实验室的研究员,接受尤洋教授的指导。
此前,他在新加坡国立大学获得数据科学与机器学习博士学位,在中国科学院深圳先进技术研究院获得计算机技术硕士学位,在北京师范大学珠海校区获得学士学位。
他的研究方向聚焦于参数生成与高效机器学习,尤其注重通过探索简洁的基线方法,来深入洞察深度学习的内在机理。
参考资料:
https://jerryliang24.github.io/DnD/
文章来自公众号“新智元”
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

