突破传统检索增强生成(RAG)技术的单一文本局限,实现对文档中文字、图表、表格、公式等复杂内容的统一智能理解。
香港大学黄超教授团队开源多模态智能处理系统RAG-Anything,将碎片化的信息孤岛转化为结构化的知识网络,为智能多模态文档分析开辟了全新技术路径。

RAG-Anything 是专门针对复杂多模态文档设计的新一代RAG系统,致力于破解现代信息处理中的多模态理解难题。
系统整合了多模态文档解析、语义理解、知识建模和智能问答等核心能力,能够同时处理文本叙述、视觉图表、结构数据、数学表达式等多样化内容,构建从原始文档到智能交互的完整自动化流程,为AI应用的实际落地提供坚实的技术支撑。
RAG系统的技术痛点与发展趋势
复杂多模态文档的理解
人工智能正在从只会处理文字发展到能够理解多种信息形式,这种变化其实很符合日常工作的实际情况。人们平时接触的信息很少是纯文字的,更多的是包含图片、表格、图表的综合性文档。这些不同类型的内容——文字说明、图像展示、数据分析、逻辑推理等——相互配合,形成了一个完整的信息体系。
在各个专业领域里,多模态内容早就成为主流的信息传递方式。学术论文需要用图表和公式来展示研究成果,教学材料用图解让概念更好理解,财务报告靠各种图表来展现数据变化,医疗记录则包含大量的影像和检测数据。这些视觉化的内容和文字说明互相补充,构成了完整的专业知识框架。
面对如此复杂的信息形态,传统的单一文本处理方式已无法满足现实各类场景的需求。各行业都迫切需要AI系统具备跨模态的综合理解能力,能够同时解析文字叙述、图像信息、表格数据和数学表达式,并建立它们之间的语义关联,从而为用户提供准确、全面的智能分析和问答服务。
现有RAG系统的技术瓶颈
虽然检索增强生成(RAG)技术在文本问答方面表现不错,但现有的RAG系统普遍存在明显的模态局限。
传统RAG架构主要是为纯文本内容设计的,包括文本分块、向量化编码、相似性检索等核心模块,这套技术栈在处理非文本内容时遇到了不少问题:
检索效果不够理想:纯文本向量没办法很好地表达图表的视觉含义、表格的结构关系和公式的数学意义。当用户问”图中的趋势怎么样”或”表格里哪个数据最大”这类问题时,检索效果往往不理想。
语义关联的缺失:文档里的图文内容经常相互引用和解释,但传统系统建立不了这种跨模态的语义连接,所以给出的答案常常不够完整或准确。
复杂的工作流:面对包含大量图表、公式的复杂文档,传统系统需要多个专用工具配合才能处理,整个流程既复杂又低效,很难适应实际应用的要求。
RAG-Anything的实际应用价值
项目的核心目标
RAG-Anything项目就是为了解决前面提到的这些技术难题而开发的,目标是打造一个完整的多模态RAG系统,让传统RAG在处理复杂文档时的各种限制得到有效解决。整个系统采用统一的技术框架,把多模态文档处理从实验室的概念验证真正推向可以实际部署的工程化方案。
技术架构的特点
团队设计了一套端到端的技术栈,包含文档解析、内容理解、知识构建和智能问答等关键功能。在文件支持上,系统可以处理PDF、Office文档、图像等主流格式。技术上实现了跨模态的统一知识表示和检索方法,还提供了标准化的API接口和灵活的配置选项。RAG-Anything的定位是作为多模态AI应用的基础组件,为现有的RAG系统直接提供多模态文档处理功能。
RAG-Anything的技术亮点
RAG-Anything 采用了一系列创新的技术方案和工程方法,在多模态文档处理领域实现了显著提升:
1 一站式多模态处理流程
团队构建了完整的自动化处理管道,从文档输入开始,系统就能智能识别并准确提取文本、图像、表格、数学公式等各种类型的内容。通过统一的结构化建模方式,实现了从文档解析、语义理解、知识构建到智能问答的全流程自动化,彻底解决了传统多工具拼接造成的信息丢失和效率低下问题。
2. 丰富的文件格式支持
系统原生兼容PDF、Microsoft Office套件(Word/Excel/PowerPoint)、常见图像格式(JPG/PNG/TIFF)以及Markdown、纯文本等10多种主流文档格式。内置的智能格式检测和标准化转换功能,保证不同来源的文档都能通过统一的处理流程获得高质量的解析效果。
3. 全方位内容理解能力
整合了视觉分析、语言理解和结构化数据处理技术,能够深度理解各类内容。图像分析功能可以提取复杂图表的语义信息,表格处理能够准确识别层次结构和数据关系,LaTeX公式解析确保数学表达式的准确转换,文本语义建模则提供丰富的上下文理解。
4. 语义关联网络的构建
利用图结构来表达实体之间的关系,系统会自动找出文档里的关键元素,并把不同类型的内容连接起来。
比如说,它能搞清楚哪张图对应哪段解释文字、表格里的数据和后面的分析结论有什么关系、数学公式和相关的理论说明是怎么联系的。这样一来,回答问题的时候就能给出更准确、逻辑更清晰的答案。
- 开放式组件生态架构
整个系统采用插件式的设计思路,开发者可以根据自己的需要灵活调整和添加功能模块。想要升级视觉识别模型、接入特定行业的文档处理工具,或者调整搜索和嵌入的算法,都能通过标准化的接口轻松搞定。
这样设计的好处是系统能够跟上技术的发展步伐,也能灵活应对各种业务场景的变化需求。
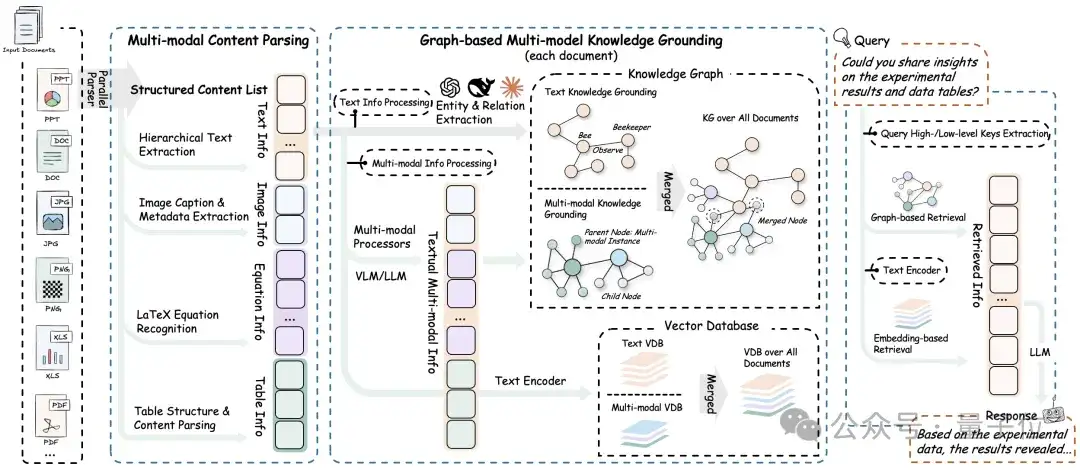
RAG-Anything系统架构
RAG-Anything采用了创新的三阶段技术架构,解决了传统RAG系统在处理多模态文档时的技术难题,真正实现了端到端的智能化处理。
多模态文档解析阶段:多模态解析引擎可以处理PDF、Office、图像等各种格式的文档,包括文本提取、图像分析、公式识别和表格解析四个关键功能模块。
跨模态知识构建阶段:通过实体关系抽取和多模态融合技术,构建跨模态知识图谱,建立统一的图谱表示和向量数据库。
检索生成阶段:结合图谱检索和向量检索的优势,通过大型语言模型生成准确的回答。整个系统采用模块化设计,具备很强的可扩展性和灵活性。
RAG-Anything多模态理解能力
(1) 视觉内容分析:集成视觉大模型,自动生成高质量的图像描述,准确提取图表中的数据关系和视觉要素。面向统计图表以及示意图,系统都能理解其中的关键信息和表达意图。
(2)表格智能解析:理解表格的层次结构,自动识别表头关系、数据类型和逻辑联系,提炼数据趋势和统计规律。即使面对多层嵌套的复杂表格,系统也能准确把握每个数据单元的含义和相互关系。
(3)数学公式理解:识别LaTeX格式的数学表达式,分析变量含义、公式结构和适用场景。系统不仅能识别公式本身,还能理解公式在特定上下文中的作用和意义。
(4)扩展模态支持:支持流程图、代码片段、地理信息等专业内容的智能识别和语义建模。这种可扩展的设计让系统能够适应各种专业领域的特殊需求。
不同类型的内容都会通过统一的知识表示框架整合在一起,从而实现跨模态的语义理解和关联分析。
统一知识图谱构建
RAG-Anything将多模态内容统一建模为结构化知识图谱,突破传统文档处理的信息孤岛问题。
(1)实体化建模:将文本段落、图表数据、数学公式等异构内容统一抽象为知识实体,保留完整的内容信息、来源标识和类型属性。
(2)智能关系构建:通过语义分析技术,自动识别段落间的逻辑关系、图文间的说明关系、以及结构化内容间的语义联系,构建多层次的知识关联网络。
(3)高效存储索引:建立图谱数据库和向量数据库的双重存储机制,支持结构化查询和语义相似性检索,为复杂问答任务提供强大的知识支撑。
双重检索机制
RAG-Anything 采用双层次检索问答机制,能够精准理解复杂问题并提供多维度的回答。这套机制既能抓住细节信息,又能把握整体语义,提升了系统在多模态文档场景下的检索范围和生成质量。
关键词分层提取:
RAG-Anything 采用双层次检索问答机制,能够精准理解复杂问题并提供多维度的回答。这套机制既能抓住细节信息,又能把握整体语义,大幅提升了系统在多模态文档场景下的检索范围和生成质量。
在关键词提取层面,系统会同时进行细粒度关键词和概念级关键词的分层提取。细粒度关键词精确定位具体实体、专业术语、数据点等详细信息,概念级关键词则把握主题脉络、分析趋势、理解抽象概念。
在检索策略上,系统采用混合检索方式,通过图谱结构快速找到相关的实体节点,利用图谱中的关联关系挖掘潜在信息,从语义层面捕获相关内容,最终把多个来源的信息整合起来生成准确的智能回答。通过这种双层次架构,系统能够应对从简单查询到复杂推理的各种问题。
快速部署指南
RAG-Anything提供两种便捷的安装部署方式,适合不同用户的技术需求。建议使用PyPI安装方式,一键就能快速部署,马上体验完整的多模态RAG功能。
安装方式
选项1:从 PyPI 安装
pip install raganything
选项2:从源码安装
git clone https://github.com/HKUDS/RAG-Anything.git cd RAG-Anything pip install -e .
多场景应用模式
RAG-Anything采用模块化架构设计,提供两种灵活的使用方式,不管是快速搭建原型还是正式生产部署,都能找到合适的解决方案。
1. 方式一:一键式端到端处理
适用场景:处理完整的PDF、Word、PPT等原始文档,追求零配置、全自动的智能处理。
核心优势:
- 全流程自动化:从文档上传到智能问答,无需人工干预
- 智能结构识别:自动检测标题层次、段落结构、图像位置、表格布局、数学公式
- 深度内容理解:多模态内容的语义分析和向量化表示
- 知识图谱自构建:自动生成结构化知识网络和检索索引
技术流程:
原始文档 → 智能解析 → 多模态理解 → 知识图谱构建 → 智能问答
示例代码:
import asyncio
from raganything import RAGAnything
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
async def main():
rag = RAGAnything(
working_dir="./rag_storage",
llm_model_func=..., # LLM
vision_model_func=..., # VLM
embedding_func=..., # 嵌入模型
embedding_dim=3072,
max_token_size=8192
)
# 处理文档并构建图谱
await rag.process_document_complete(
file_path="your_document.pdf",
output_dir="./output"
)
# 多模态问答查询
result = await rag.query_with_multimodal("Could you share insights on the experiment results and the associated data tables?", mode="hybrid")
print(result)
asyncio.run(main())
方式二:精细化手动构建
适用场景:已有结构化的多模态内容数据(图像、表格、公式等),需要精确控制处理流程和定制化功能扩展。
核心优势:
- 精确控制:手动指定图像、表格等关键内容的处理方式
- 定制化处理:根据特定领域需求调整解析策略
- 增量构建:支持逐步添加和更新多模态内容
- 专业优化:针对特定文档类型进行深度优化
示例代码:
from lightrag import LightRAG
from raganything.modalprocessors import ImageModalProcessor, TableModalProcessor
# 初始化 LightRAG 系统
rag = LightRAG(working_dir="./rag_storage", ...)
# 处理图像内容
image_processor = ImageModalProcessor(lightrag=rag, modal_caption_func=your_vision_model_func)
image_content = {
"img_path": "fig1.jpg",
"img_caption": ["Figure1: RAG-Anything vs Baselines"],
"img_footnote": [""]
}
description, entity_info = await image_processor.process_multimodal_content(
modal_content=image_content,
content_type="image",
file_path="RAG-Anything.pdf",
entity_name="fig1-RAG-Anything vs Baselines"
)
# 处理表格内容
table_processor = TableModalProcessor(lightrag=rag, modal_caption_func=your_llm_model_func)
table_content = {
"table_body": """
| Methods | Accuracy | F1 |
|------|--------|--------|
| RAGAnything | 95.2% | 0.94 |
| Baseline | 87.3% | 0.85 |
""",
"table_caption": ["Table1: RAG-Anything vs Baselines"],
"table_footnote": ["Dataset-A"]
}
description, entity_info = await table_processor.process_multimodal_content(
modal_content=table_content,
content_type="table",
file_path="RAG-Anything.pdf",
entity_name="tab1-RAG-Anything vs Baselines"
)
技术演进与应用拓展
RAG-Anything在推理能力上还有不少改进空间,比如让系统能够进行更复杂的逻辑分析,处理跨模态信息的深层关联,甚至可以尝试加入推理过程的可视化展示和证据追踪功能。在具体应用场景中,也有很多有趣的方向可以探索,像是更准确地解析学术论文里的复杂图表、自动提取财务报表中的关键数据、识别工程图纸的结构细节,或者帮助整理医疗文档中的重要信息。
另一个值得关注的是,RAG-Anything作为构建智能Agent的基础技术,可以为各种AI应用提供强大的多模态处理能力。如何让Agent更聪明地理解现实世界的复杂信息,在真实的业务场景中派上用场,这些都是很有挑战性的技术问题。随着这些技术的逐步完善,开发者应该能够更轻松地打造出符合自己需求的智能工具。
项目地址:https://github.com/HKUDS/RAG-Anything
实验室主页: https://sites.google.com/view/chaoh
文章来自公众号“量子位”,作者“RAG-Anything团队”
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI

