第一作者孙秋实是香港大学计算与数据科学学院博士生,硕士毕业于新加坡国立大学数据科学系。主要研究方向为 Computer-using agents 和 Code intelligence,在 NLP 和 ML 顶会 ACL,EMNLP,ICLR,COLM 等发表多篇论文。本文的 OS-Copilot 团队此前已发布了 OS-Atlas、OS-Genesis 和 SeeClick 等同系列电脑智能体研究成果,被广泛应用于学术界与产业实践中。
用于辅助科学研究的大模型智能体,正在悄然发生变化
1 背景与动机
过去几年,随着 LLMs 和 VLMs 的飞速进步,我们见证了 AI 在自然语言处理、编程、图像理解等领域的广泛应用。而在科学研究这一关乎人类知识积累的关键场域,基于这些强大模型的智能体正悄然成为科研工作流的 “新型合作者”。
在早期,AI 在科学中的角色往往是 “分析器”—— 帮助分析数据、撰写文献、生成图表。但随着电脑智能体(Computer-Using Agents,也称 CUA)的出现,这一角色正在发生根本性转变。相比于传统的语言模型助手,这类智能体能够像人类一样操作计算机,通过图形界面点击、拖拽、输入命令,或是编写程序完成计算任务,完成对真实科研软件的自动化控制。这意味着,它们不再只是回答问题,而是在主动与你一起完成科学任务,成为具备 “执行能力” 的 AI 合作者。
1-1 从语言理解走向科研执行:全新的挑战
在复杂的科研场景中,软件工具的多样性、任务流程的长周期、跨模态信息的交错,令 “用 AI 真正完成一项科研任务” 远比解答一个科学问题要困难得多。例如,模拟蛋白质结构需要调用生物建模软件,查看星体轨迹要熟练操作天文模拟器,甚至还需要自动将结果整理进 LaTeX 文档。实现这样的能力,需要智能体具备:
- 软件操作能力:能够使用图形界面(GUI)与命令行(CLI)控制复杂科学工具;
- 领域理解能力:理解任务背后的科学概念与背景知识;
- 跨模态感知与规划:在图形界面、终端指令、科学数据之间进行有效推理和行动。
然而,现有的多模态智能体系统大多在网页、电商、编程等通用任务上取得了一定进展,在科学领域却还在蹒跚学步。一个很重要的原因在于:缺乏一个真实、系统化的科研环境与评估基准,来推动 agent 从 “会说会写会敲代码” 走向 “会做”。
1-2 科研任务中的空白:环境与评测的双重缺失
尽管社区已提出多项 CUA 智能体评测(如 WebArena、OSWorld 等),但这些工作大多集中在日常场景和通用软件上,其复杂性远未触及真实科研工作。而以 ScienceQA 和 SciCode 为代表的科学评测人任务,其任务方式依然停留在 QA 和静态的代码编写上。在真实的科学探索过程中,软件工具往往具有非标准 I/O 流、复杂界面逻辑、需要先配置再执行、多步操作才能完成目标 —— 这对智能体提出了前所未有的挑战。因此,我们需要(1)一个可靠的环境让 Agent 可以进行自主探索以及(2)一个多模态多领域的评测基准,来了解科学任务的自动化可以被完成到何种程度
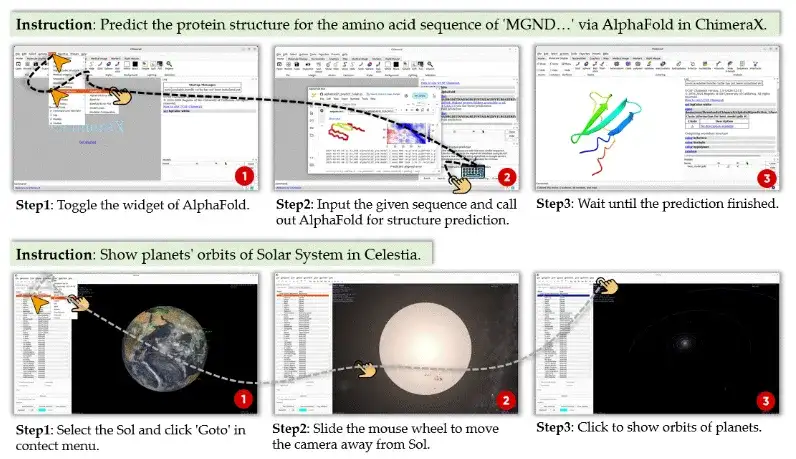
在这样的背景下,我们提出了 ScienceBoard:首个面向科学任务、真实交互、自动评估的多模态智能体评测环境,目标是从根本上推动 “会自动完成科学工作流的 AI” 的研究进展。
- 论文题目:
ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
- 项目地址:
- https://qiushisun.github.io/ScienceBoard-Home/
- 研究机构:香港大学,上海人工智能实验室,复旦大学,北京大学,耶鲁大学
2 ScienceBoard 基建:科研任务的可交互操作环境
2-1 多领域科研软件集成
ScienceBoard 基于 Ubuntu 虚拟机搭建,内置了多个开源科研软件,并对其进行了系统性的重构和改造,确保每个任务都能通过 CLI / GUI 双通道进行交互。整个系统具备以下特点:
- 多领域科研软件集成:作为一个可扩展的环境,ScienceBoard 默认集成了 6 个科学领域的软件,包括生物化学,天文模拟,地理信息系统等。
- 双模态操作接口:每个软件均支持 GUI 和 CLI 控制,支持屏幕截图(Screenshots)、可访问性树 (a11ytree)和 Set-of-Marks 等多模态输入,允许 agent 灵活选择交互方式。
- 自动初始化机制:每个工作场景都配备初始化脚本、配置文件、辅助数据,确保 agent 可以从相同起点开始实验,保证评测可复现性。
- 可靠的自动评估机制:作者们编写了一整套可扩展的任务评估函数,支持数值匹配、范围区间、状态对比等方式,对复杂科学操作实现执行级评估(execution-based evaluation)。
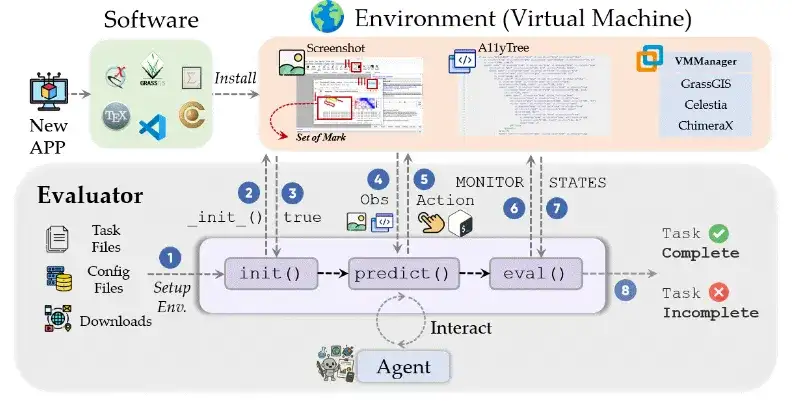
2-2 动作空间
为了让 agent 能在不同任务中使用统一接口与动作表示,ScienceBoard 在先前 CUA/Coding Agents 工作的基础上进行了扩展,为 Agents 定义了一个通用动作空间,涵盖以下几类操作:
- GUI 操作动作:如 CLICK [x, y]、SCROLL [Δy]、TYPE [“text”] 等模拟人类操作
- CLI 命令执行:在终端 / 软件内部输入代码指令并获取反馈
- 其它类型调用:
ocall_api:访问外部 API 拓展 agent 能力
oanswer [“...”]:用于任务型 QA 作答
- 流程控制动作:如 DONE, FAIL 等用于表明交互终止
这样的设计使得通过 LLM/VLM 构建的不同 agent 在 ScienceBoard 环境中都能通过结构化 API 实现通用交互能力,真正具备 “跨软件、跨模态” 的通用执行接口。
3 ScienceBoard 评测集:高质量科研任务数据集
基于上述的多模态科学探索环境基建,ScienceBoard 构建了一个系统化、具挑战性的科研任务集合,作为评估 AI 智能体科学能力的标准基准。该基准不仅覆盖多种科研软件,还充分考虑任务多样性、复杂度和可执行性,目标是推动智能体从 “看得懂” 走向 “做得对”。
3-1 科学探索问题的构建
要评估一个智能体是否真正具备完成科学任务的能力,关键不仅在于环境,更在于任务本身是否足够真实、足够复杂、足够可衡量。为此,ScienceBoard 采用了人工设计 + 程序验证的混合标注流程:由学习过相关领域知识的人员基于真实软件手册构思任务目标,通过多轮交叉验证确保指令清晰、操作合理,再配套自动初始化脚本与程序化评估函数,最终构成一个高度标准化、可复现、可自动评估的科研任务集合。
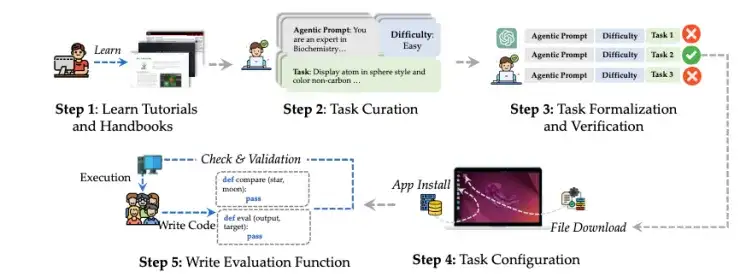
3-2 多维评测基准
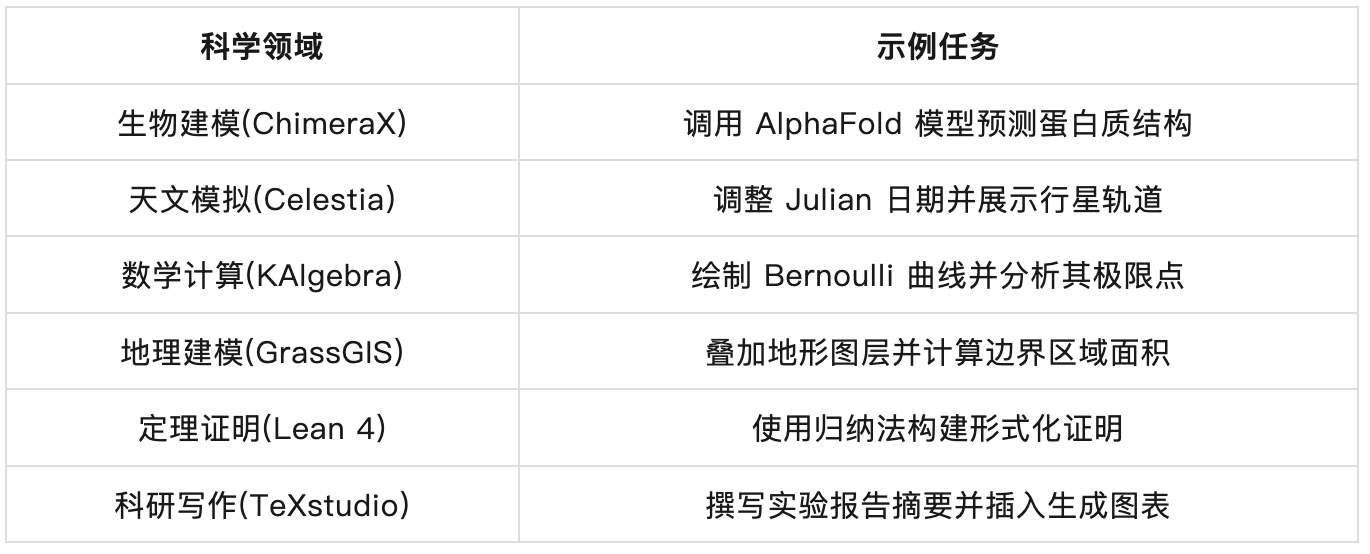
ScienceBoard 的当前版本共收录 169 个真实科研任务,横跨 6 个领域(及其对应配套的软件),任务类型涵盖:基础软件与环境设置,科学模拟与计算,图形绘制与空间可视化,数据查询与结果解释,科研文档撰写与整合,跨软件复合工作流等等
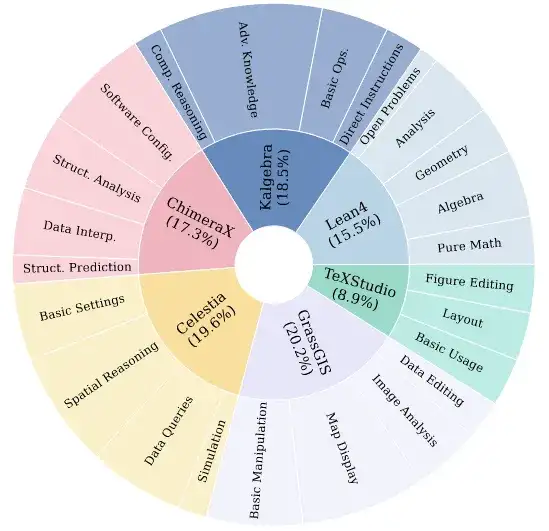
为系统性考察智能体的不同层级能力,任务被划分为四类难度:
- Easy(~54%):执行单步配置、简单计算和编程、操作界面
- Medium(~28%):涉及多步指令、逻辑推理或跨模态状态跟踪与记忆
- Hard(~17%):需完成 Long-horizon 规划、精细的 GUI 定位、多程序协作等
- Open Problems:当前 SOTA 模型仍不可能完成的开放探索挑战性任务
4 实验与评估
我们在 ScienceBoard 评测基准上评估了当前代表性的(1)商业模型(2)开源模型(3)GUI 基座模型所构建的智能体的表现,结果揭示:即便是当今最强的多模态大模型,在真实科研工作流中也远未成熟。
4-1 主要实验
在整体任务成功率上:
1.GPT-4o 和 Claude 3.5 等商业大模型虽领先于开源模型,但平均成功率也仅为 15% 左右;
2. 开源的 InternVL3 和 Qwen2.5-VL 在部分任务上有超越商业模型的表现,但跨领域表现仍不稳定;
专门设计的 GUI Action Models 如 OS-ATLAS、UGround 等,虽然对接系统更轻量,却在长任务、跨模态任务上明显受限。
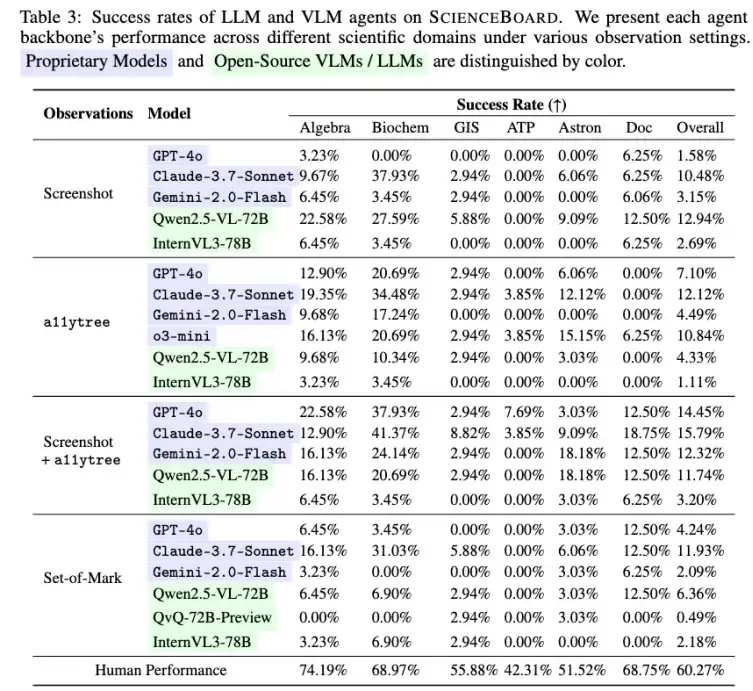
可以从实验中看出:完成科学工作流的门槛远高于 Web browsing 任务或移动 / 桌面端应用的交互。模型需要在视觉、结构化数据、复杂指令之间基于领域知识多轮推理、长程规划。
更重要的是,我们在实验中发现:许多失败并非源于模型知识不足,而是执行策略不当。例如,模型可能正确理解了 “导出蛋白质结构图”,却因点击顺序错误而未能完成任务。
4-2 拆解规划与动作
进一步的分析实验还揭示了一个耐人寻味的趋势:许多失败的智能体其实 “知道要做什么”,却 “做不好”。以 GPT-4o 为代表的模型,在任务规划上展现了强大的理解能力,但在面对真实界面时,常因点击不准(e.g., 无法点中正确的星球)、路径偏差而执行失败。这表明:当前模型在 “想清楚” 与 “做准确” 之间仍存在断层。
为进一步验证这一现象,我们尝试将规划(Planning)与执行(Action)解耦,构建模块化智能体系统:由 GPT-4o 负责生成高阶计划,再由各类开源 VLM 或 GUI Action Model 执行具体操作。
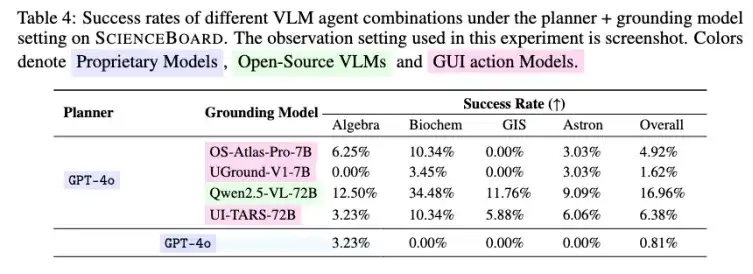
实验结果显示:这种模块化设计显著提升了成功率,尤其在界面复杂、操作链条长的科研软件任务中,能够更稳健地完成目标。
5 展望
ScienceBoard 的实验表明,当前智能体的瓶颈不仅在操作层,更在于领域知识与通用 agent 能力的割裂。许多模型可以正确地执行点击或输入命令,但缺乏对科学任务背后知识的理解。因此,未来的关键方向在于:让智能体真正 “理解科学”。这或许包括利用 Manual 与 Tutorial 等资源进行 “任务相关学习”,或构建可根据上下文调用外部知识的系统,
另一个值得关注的方向是智能体系统。我们的实验显示,即使是简单的 “分工合作” 策略(如 GPT-4o 负责计划、其他模型负责执行)也能带来显著收益。这为未来的 “科研 AI 团队” 奠定了雏形:一个系统可能由具备强逻辑推理能力的 planner、擅长执行的 GUI 模型、掌握专业知识的领域专家模型组成。它们可按需组合,灵活适配科研生命周期中的不同阶段,从数据分析、图表生成到论文润色,真正成为 “可编排、可插拔” 的科研伙伴。
更长远地看,ScienceBoard 提出的框架也为实验室层面的智能化探索打下了基础。从虚拟科研助手,到物理实验机器人,从 Coding / QA 模型到实验助手,AI 科学家的未来,不再只是数字世界里的概念,而是正在缓慢走向现实。
6 结束语
作为首个聚焦科学探索任务的多模态智能体评测框架。ScienceBoard 提供了一个真实可交互的科研环境,精心设计了具有代表性的科研任务,并配套程序化评估机制,系统性评估现有模型在科学任务上的表现。实验发现,即便是当前最强的通用模型,在复杂科研工作流中的成功率仍显著低于人类,尽管智能体自动化科学探索仍是一个长期目标,但本工作提供了一个可复现、可衡量、可扩展的起点,也为通向全自动化 AI 科学家之路点亮了第一盏灯。
文章来自公众号“机器之心”
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/

