最近一个「泄露」的文本转语音模型演示版本在 Reddit 上火了。
这个「泄露」的演示视频被网友贴出来后,评论区一片惊呼。
这情绪太细腻了,我不相信这不是人说的。
我们终于能跟糟糕的配音演员说拜拜了。

Reddit 帖子截图,链接:https://www.reddit.com/r/LocalLLaMA/comments/1lyy39n/indextts2_the_most_realistic_and_expressive/
它来自一个还没正式发布的项目,IndexTTS2。不过我们发现,这个演示版本并不是什么项目的泄露文件,而是论文作者亲手贴出来的 Demo 演示页。
看起来只是一次误会。但它惊艳的背后,却可能是下一代 AI 声音生成的分水岭。
不是 404 链接,是 AI 配音的「奇点」时刻
故事要从这个链接说起, https://index-tts2.github.io,这是一般放在 GitHub 上的项目主页链接格式,但是这个链接直到现在都是 404。
Reddit 上这位网友在 GitHub 上找到了这个项目仓库,发现了里面有多个 IndexTTS2 的演示视频,他分享了其中的一个 https://index-tts.github.io/index-tts2.github.io/ex6/Empresses_in_the_Palace_1.mp4。


这些演示视频,不仅音色还原度高,情绪也自然的让人一时忘了是在听 AI。

除了甄嬛传这个配音视频,还有让子弹飞的演示视频,同样精彩。我甚至觉得如果电影需要英配,用这个是完全可以。
但其实这些 Demo 并不是「偷偷隐藏」在项目仓库里的。作者在论文中给出的链接就是 https://index-tts.github.io/index-tts2.github.io/,只不过可能是还没有写好演示的网页,所以被误会成了这是一个泄露的演示版本。
所以准确地说,这是一场误会,但也正是这场误会,让更多人第一次看到了 IndexTTS2 的惊艳表现力。
IndexTTS 2 项目主页网站目前仍是 404
IndexTTS2 就是那种一耳朵就能分辨出「质变」的模型。甚至不需要对比参数,我们只要点开这个 demo,就能很明显的感觉到它和之前那些「AI 声音」不一样。
声音不再平滑得像机器,而是有起伏、有重音、有轻笑、有叹息。
情绪不是靠「语速快慢」去模仿,而是真的在「表达情绪」。
音色不仅像人,甚至像是有个人格、有表演的「人」。
如果说 ElevenLabs 让我们第一次看到了产品化语音的可行性,IndexTTS2 给人的震撼,更像是 Midjourney 横空出世那年,大家开始意识到:AI 不止能模仿人类,它能「重构表达」。
揭秘 B站王牌:AI 如何学会「表演」而非「朗读」
那么这个模型到底是怎么回事,又是怎么把 AI 生成的声音做到这么有情感,这么像真人。
IndexTTS2 来自 B站语音团队,他们在上个月发布了一篇论文专门介绍这项工作,哔哩哔哩技术公众号在前几天也分享了这个模型的相关信息。

论文链接:https://arxiv.org/abs/2506.21619
它是一个文本转语音模型(TTS),但和过去我们听到的 AI 声音不一样。它不是在读字,而是在讲话;不是同步而粗糙的配音,而是有情绪、有表现力的声音演绎。
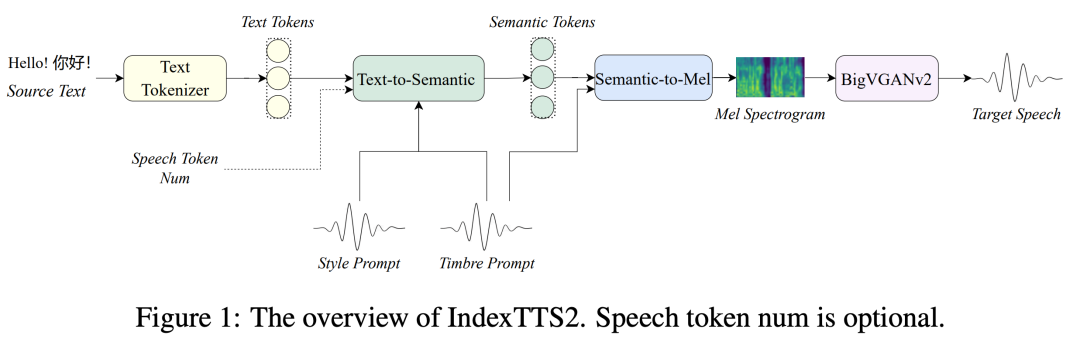
IndexTTS2 模型概览,由基于源文本、风格提示、音色提示输入的文本转语义模块、语义转频谱图模块和将频谱图转换为高质量语音波形的声码器三个模块组成,实现端到端的语音合成过程。
同时,这个模型还能做到:
不依赖参考音频,通过微调语言模型 Qwen3 来解读自然语言指令实现的情感控制
对同样的一段文本,不同语音、不同情绪、不同语速都能精确对应
语音时长可控,可以用在配音对齐、视频解话、影视合成等场景
它不仅仅是一个「好听」的模型,而是一个「好控」的模型。你给一段文字,它不仅能说出来,还能按照你的意思,表现成一个有情感的声音表演。
B 站也拿这个模型和阿里通义实验室的 CosyVoice2、上海交大的 F5-TTS、MaskGCT 等 TTS 开源模型,在多个评估基准上进行测试,IndexTTS2 在词错误率、说话人相似度以及情感保真度等多个关键指标上均是当前最优的。
但目前 IndexTTS2 还没有完全开源,哔哩哔哩技术公众号在文章里面说会持续优化模型性能,全面开源 IndexTTS2 的推理代码和模型权重。希望未来能尽快得到实际体验的机会。
就像 Reddit 上网友说的,IndexTTS2 是具有革命性意义的一项工作。
这是我第一次真正觉得 AI 声音可以让人享受整部电影的配音。我注意到它在配音时甚至克隆了中文口音。非常有趣。
我迫不及待想用好的参考声音在本地尝试它,尝试不同的情感参考音频片段,并根据需要多次重新运行生成,以获得非常逼真的表演。这太酷了。
它让我们看到的,不仅仅是一项很酷的技术,更是一个内容创作新范式的黎明。从「能说话」到「复制音色」、再到现在「突出情感表现力」,我们的短视频可能又将有新的素材了。
如果 IndexTTS2 在大部分视频的配音上,都能做到像文章开头说的那个「泄露 Demo」这么出色,那我们真的可以说看一部 AI 配音的电影了。
文章来自于微信公众号“APPSO”。
【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales


