只需一段视频,就可以直接生成可用的4D网格动画?!
来自KAUST的研究团队提出全新方法V2M4,能够实现从单目视频直接生成高质量、显式的4D网格动画资源。这意味着无需NeRF/高斯点后处理,可直接导入游戏/图形引擎。

该方法构建了一个系统化的多阶段流程,涵盖相机轨迹恢复、外观优化、拓扑统一、纹理合成等关键步骤,让视频“秒变模型”,大幅提升动画与游戏内容的生成效率与可用性。
论文已被ICCV 2025正式接收。

结果显示,其生成的外观和结构高度还原,平均每帧仅需约60秒处理,比现有方法显著提速;而且还支持「长视频」,在300帧时长的视频上依然表现优异
视频生成4D动画模型有多难?
从一段视频生成连续动画网格资产,一直是视觉计算长期未解的问题:传统动画制作需依赖多摄像头、动捕设备、人工建模等高成本手段。隐式方法如NeRF虽能复现外观,却难以直接输出拓扑一致的显式网格。
而近期的原生3D生成模型能够重建出高质量的3D网格,但常常存在姿态错位、拓扑不一致、纹理闪烁等问题。
在该工作中,V2M4首次展示了利用原生3D生成模型,从单目视频生成可用4D网格动画资产的可能性,并展现了其视觉效果与实用性。
V2M4提出一套系统化的五阶段方法,直接从单目视频构建可编辑的4D网格动画资产。该方法以“生成高质量显式网格+拓扑一致+纹理统一”为目标,从结构、外观、拓扑和时序角度逐步优化模型,输出可直接用于图形/游戏引擎的4D动画文件。
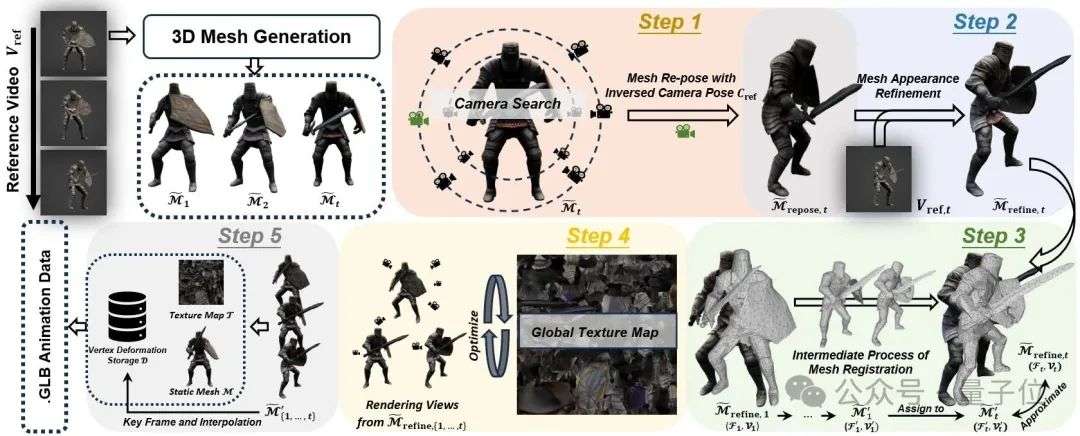
相机轨迹恢复与网格重定位
由于原生3D生成模型输出的每帧网格常处于标准坐标系中心并且朝向固定,因此直接采用原生3D模型生成视频帧对应的3D网格会导致真实的平移和旋转信息的丢失,进而使得动画无法还原物体在视频中的真实运动。
为解决该问题,V2M4设计了三阶段相机估计策略,通过重建每帧视频的相机视角,进而将“相机运动”转化为“网格运动”。
- 候选相机采样+DreamSim评分:在物体周围均匀采样多个视角,渲染并与真实帧对比,挑选相似度最高的相机姿态。
- DUSt3R点云辅助估计:引入几何基础模型DUSt3R,通过预测点云来推算出更稳定的相机位姿,再与采样结果融合。
- 粒子群优化+梯度下降精调:用PSO算法避免局部最优,再以渲染出的掩模差异为优化目标,通过gradient descent精细调整最终相机参数。
最终,将估计得到的相机轨迹反向应用于每一帧3D网格,从而将网格从标准姿态中“还原”回视频中的真实空间位置,实现真实的动态建模。

外观一致性优化:条件嵌入微调
即使完成空间对齐,初始生成的网格外观往往与输入视频存在一定外观差异。为此,V2M4借鉴图像编辑中的null text optimization策略,对生成网络的条件嵌入进行微调,以DreamSim、LPIPS、MSE等指标衡量渲染结果与参考视频帧的相似度,从而优化嵌入向量,使生成的网格外观更加贴合原视频,实现更高质量的外观一致性。
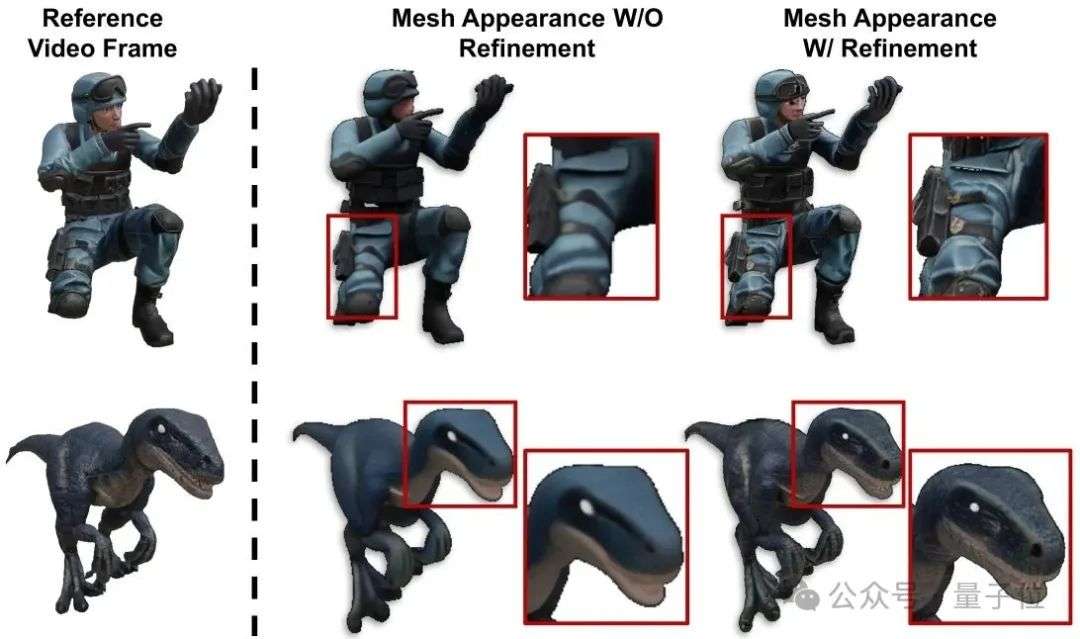
拓扑对齐与结构一致性:帧间对齐+局部约束
由于现有3D生成模型在每帧输出中存在随机性,相邻帧的网格往往在拓扑结构上存在差异,例如顶点数量、边的连接方式或面片组织均不一致。这类结构差异会严重阻碍动画的连续性与可编辑性。为解决此问题,V2M4引入了逐帧配准与拓扑统一机制:以首帧网格为标准形态(rest pose),通过全局刚体变换和局部形变优化,逐步将其拓扑结构传递给所有后续帧。在配准过程中,该方法结合Chamfer距离、可微渲染损失与ARAP刚性形变约束,实现对整体姿态和局部结构的精准调整。最终,所有帧网格不仅在形状上保持高度连续性,更在拓扑层面实现完全一致,从而为后续纹理生成与时间插值奠定稳定基础。
跨帧纹理一致性优化:共享UV提图,消除闪烁与断裂
为了确保动画过程中外观的一致性,V2M4为所有帧构建了一张共享的全局纹理贴图,避免了逐帧独立纹理所带来的色彩跳变与贴图断裂问题。由于前述拓扑统一后,各帧网格的结构保持一致,该方法以第一帧网格的UV展开作为所有帧的纹理基准,并基于多视角渲染优化贴图细节。为提升与原视频匹配的局部质量,该方法引入视角加权机制,对应视频帧的相机视图被赋予更高权重。最终,实现外观一致、帧间平滑的动画体验。
网格插帧与4D动画导出:轻量封装,一键部署
为了提升动画的时间连续性与软件适配性,V2M4对生成的网格序列进行时间插帧与结构封装。具体而言,该方法对关键帧网格的顶点位置进行线性插值,生成时序上更平滑的动画序列,并进一步将其表示为:单个静态网格,加上一组随时间变化的顶点位移张量。最终结果被导出为符合GLTF标准的动画文件,包含统一拓扑结构、共享纹理贴图与顶点时序变形,可直接导入Blender等主流图形与游戏引擎进行编辑与复用。由此,该方法实现了从视频到4D网格动画资产的完整转换路径,具备可视化、可编辑与实际应用兼容性。
效果验证与评估
为系统评估 V2M4 的性能,该工作在比以往更具挑战性的视频数据上开展实验,结合定量与定性对比,验证其在重建质量、运行效率与泛化能力上的全面优势。
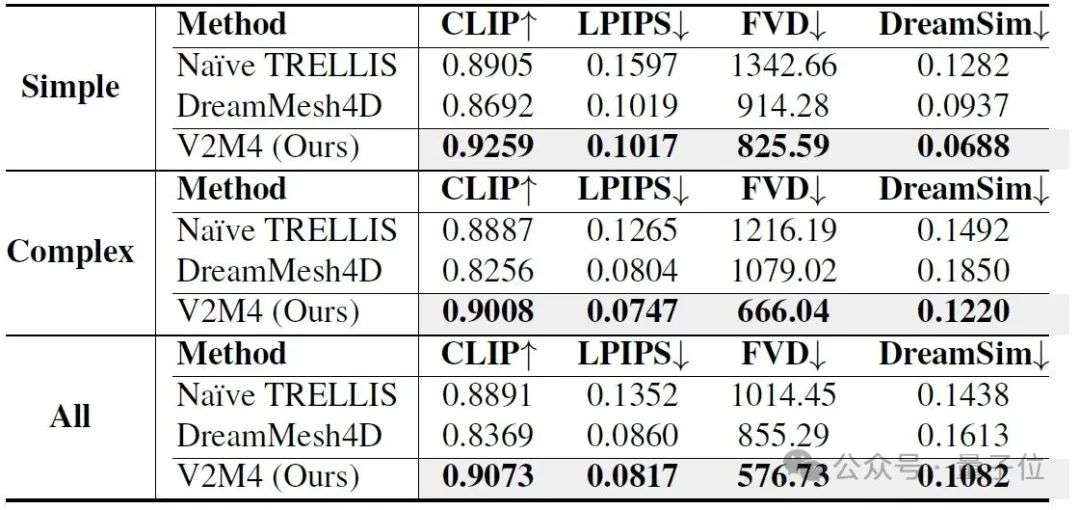
定量对比:性能全面领先
该方法基于CLIP、LPIPS、FVD和DreamSim等主流指标,从语义一致性、视觉细节与时序流畅性等维度,评估输入视频与重建网格渲染之间的匹配度,更贴近真实用户感知。
与DreamMesh4D和Naive TRELLIS等方法相比,V2M4在Simple(轻微动作)及Complex(复杂动作)两个数据集上各项指标均实现领先。同时,依托高效的插帧与纹理共享机制,平均每帧仅需约60秒即可完成重建,大幅优于现有方法。
视觉对比:结构更清晰、外观更真实
在视觉效果方面,V2M4生成的网格在渲染细节、法线结构与跨帧一致性上表现更出色,不仅还原度高、拓扑完整,更能稳定生成连续、流畅的动画,展现出优异的实用性与泛化能力。

论文链接:
https://arxiv.org/abs/2503.09631
项目主页:
https://windvchen.github.io/V2M4
文章来自于微信公众号“量子位”。
【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

