
开源模型王座再次易主?
昨天,英伟达开源了OpenReasoning-Nemotron:
- 在多个基准测试中,同规模模型无敌,取得了SOTA得分
- 专为数学、科学、代码定制
- 提供四种参数规模:1.5B、7B、14B和32B,可在本地100%运行。
不过,这些模型还是「国产血统」:
架构基于Qwen2.5 ,SFT训练使用的是DeepSeek-R1-0528生成的数据。
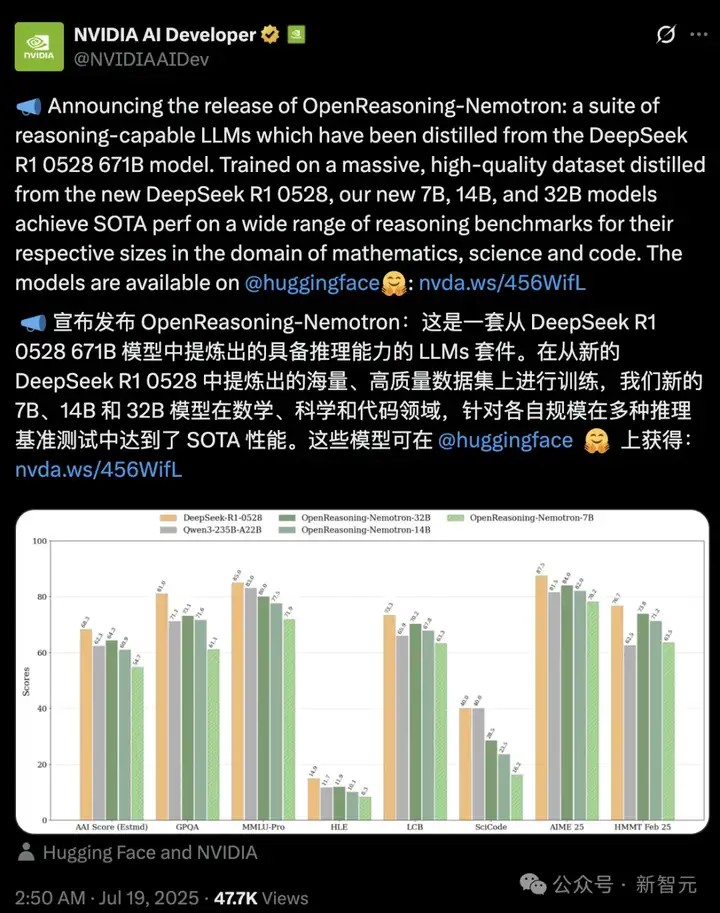
OpenReasoning-Nemotron是目前最强的蒸馏的推理模型。

以后,推理模型也有了强基线模型。
一张图总结要点:

数学基准,超越o3
这次在参数高达671B的满血DeepSeek-R1-0528蒸馏,在5M的数学、代码和科学推理轨迹上训练。
这次的模型不仅仅进行token预测,还实现了真正的推理能力。

核心贡献者、英伟达研究科学家Igor Gitman介绍了这次的亮点。

与之前OpenMath/Code/Science发布时的提示集相同,这次只是更新了用于生成答案的R1模型,但改进幅度巨大!
而作为「教师」模型,新的R1模型表现出色!
而且这次没有进行任何在线强化学习,只进行了有监督微调(SFT)。
未来应该可以通过进一步优化这些模型或使用更少的 token 获得相似性能。
这些模型支持「重型」推理模式,可以「结合多个智能体的工作」。
为此,他们这次使用了AIMO-2论文中提出的GenSelect算法。
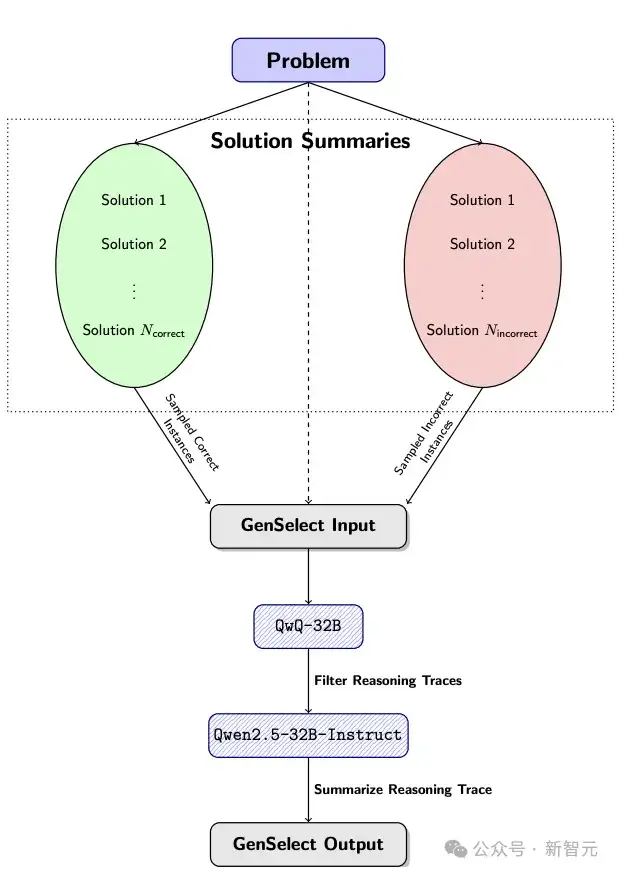
使用GenSelect@64,在多个数学基准测试中超越了OpenAI o3(高算力版)。

还有另一个令人惊讶的结果:这些模型只是针对数学问题训练了GenSelect算法,但它竟然也泛化到了代码任务上!
32B模型的LCB得分从70.2(pass@1)提升到75.3(GenSelect@16)。
需要注意的是,这里没有使用强化学习(RL),但仍然观察到从数学到代码的强大泛化能力!
意外的现象
首先澄清一点,这是一次「研究性质」模型发布,主要目标是验证生成的新数据的价值,并探索仅通过监督微调(SFT)能将性能推到何种程度。
这次仅针对数学、代码和科学推理任务训练了模型,没有进行指令微调或强化学习人类反馈(RLHF)。
虽然这些模型在解决推理任务时表现优异,但未经进一步训练,它们可能无法胜任多轮对话或作为通用助手。
在一系列具有挑战性的推理基准测试中,模型表现出色。
7B、14B和32B模型在各自规模类别下的创下了多项最先进纪录。
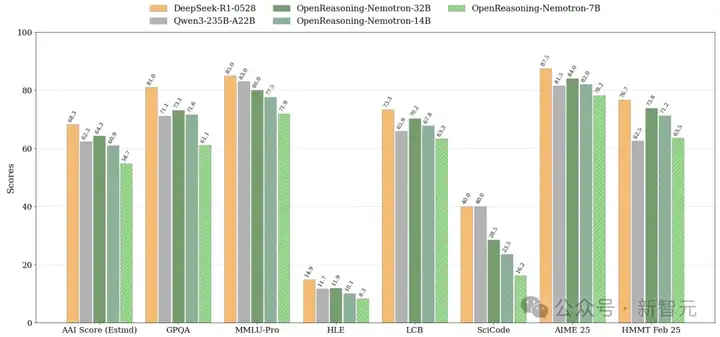
现在,在开发这些模型时,还发现了两点有趣的事情。
(1)参数规模影响巨大。
1.5B模型,实际上并没有特别出色。例如,OpenMath-Nemotron-1.5B(我们之前的数学模型发布)在 AIME25 上得分为 49.5,而这个新模型得分为 45.6。
但是,7B(或更大的模型)进步就非常显著。OpenMath-7B 模型的得分为 61.2,而 OpenReasoning-7B 的得分则达到了 78.2!
因此,1.5B 模型的表现稍微下滑了,但 7B 模型在使用相同数据进行训练后提高了近 20%。
研究人员猜测可能是因为在处理较长上下文生成时,1.5B模型可能不太一致。
之前的数据集仅包含16K输出token,但这次扩展到了32K,而1.5B模型无法保持推理的一致性。
(2)模型学会了两种不同的行为。
在之前的 OpenMath 发布中,英伟达研究团队也使用了TIR数据来帮助模型学习使用Python。
由于没有时间用新的R1重新生成这些数据,他们决定将一些旧的 TIR 数据混入当前的训练集中,看看会发生什么。
他们原本期望:在训练过程中,模型仍然能够学习如何使用 Python,同时保留来自新 CoT 样本的更好推理。
然而,事实并非如此——如果你使用TIR模式来评估OpenReasoning模型,你会发现它们与OpenMath模型基本相同,这比带有CoT的新模型要差得多。
从某种角度来看,模型学会了两种不同的行为:一种是使用工具,但推理较差;另一种是不使用工具,但推理很强,两者之间没有有效的过渡。非常有趣的是,是否可以通过在TIR模式下应用在线强化学习(RL)来解决这个问题?
本地笔记可跑
如果笔记本电脑上运行,详细信息如下:
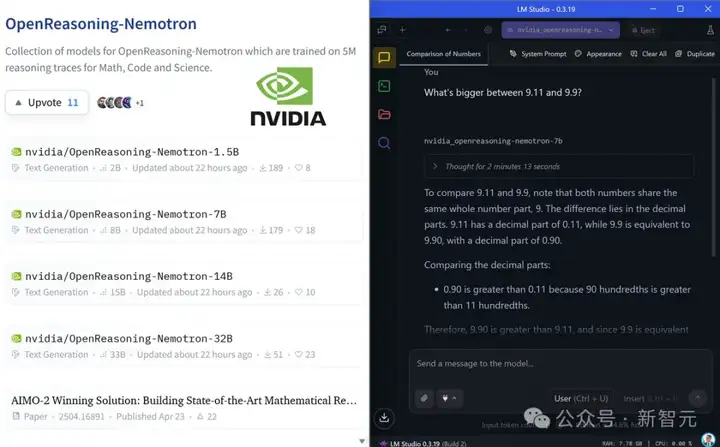
模型链接:https://huggingface.co/nvidia/OpenReasoning-Nemotron-32B
体验链接:https://huggingface.co/spaces/Tonic/Nvidia-OpenReasoning
可以使用LM Studio免费运行它们:
- 在多个基准测试中,同规模模型无敌,取得了SOTA得分
- 专为数学、科学、代码定制
- 提供四种参数规模:1.5B、7B、14B和32B,可在本地100%运行。
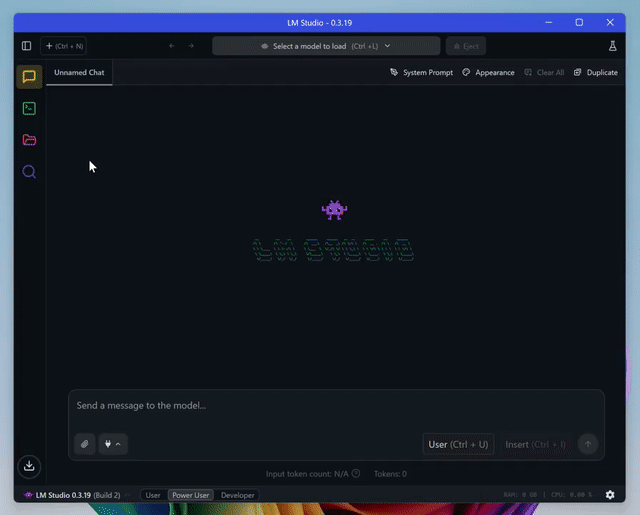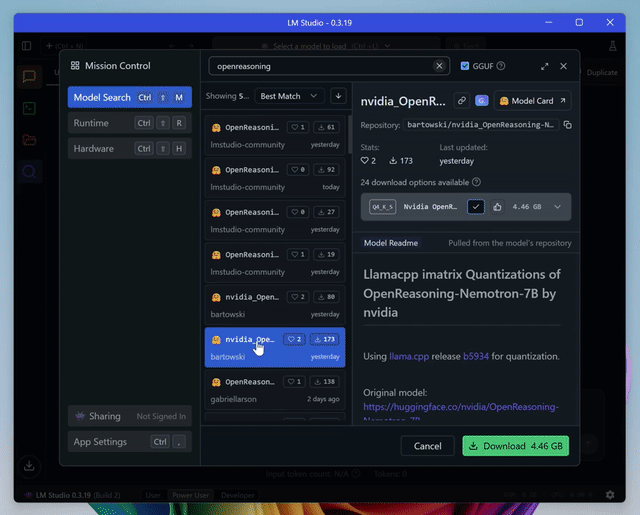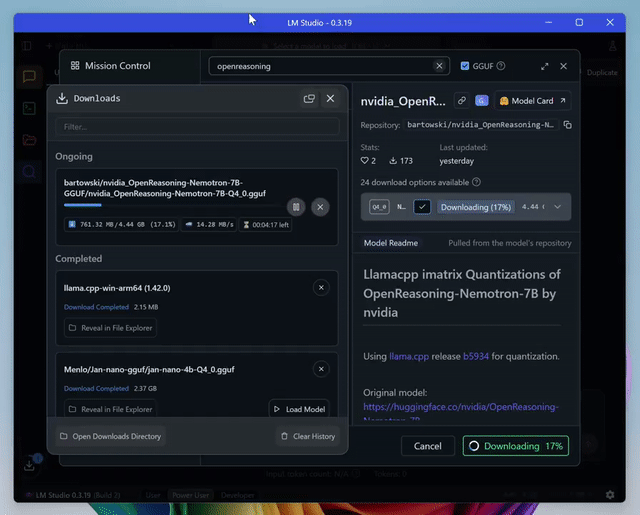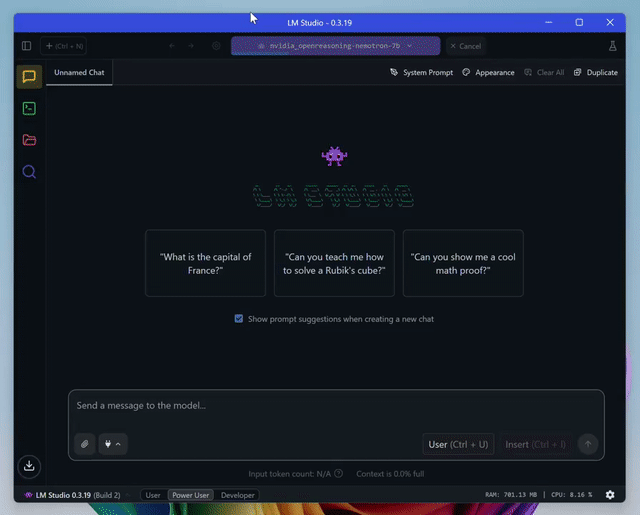
如果使用ARM处理器,建议使用Bartowski的7B版本。
只要骁龙 X Elite + 32GB RAM,就可以加载量化后的14B模型,并在CPU上运行。
参考资料:
https://x.com/NVIDIAAIDev/status/1946281437935567011
https://huggingface.co/blog/nvidia/openreasoning-nemotron
https://x.com/josephpollack/status/1946486918696313257
https://x.com/igtmn/status/1946585046552658358
文章来自微信公众号 “ 新智元 ”
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

