引言
随着人工智能技术的快速发展,大语言模型在自然语言处理领域引发了深刻变革。大语言模型在实际应用中的使用越来越广泛,这些模型通常部署在云原生的基础设施上,需要复杂的流量管理机制以确保服务的稳定性、性能、可扩展性和成本效益。在 Kubernetes(K8S)这一容器编排标准中,现有的 Ingress 组件的流量转发机制提供了基于主机名和请求路径的基本流量路由功能。然而,在应对大模型服务独特需求时,现有机制在资源效率、稳定性和易用性上存在显著局限性。
作业帮采用了一种针对 Kubernetes 环境中大模型服务的创新流量调度方案,相较于传统 Ingress 组件显著提升了资源效率、稳定性和易用性。这一方案为企业级 AI 服务平台、云服务提供商和研究实验室大模型部署提供了高实用价值的解决方案。
传统流量调度方案的挑战
Ingress 是 Kubernetes 的流量网关,用于基于主机名和 URL 路径将 HTTP/HTTPS 流量路由到服务。然而,在大模型服务场景中,Ingress 存在以下局限:
- 基于路径的路由限制:Ingress 依赖静态规则配置(通过 YAML 文件定义),在多模型共存的动态环境中(如 DeepSeek、Qwen、Llama 等)维护复杂且易出错。每次添加或更新模型都需要手动调整规则,增加了运维负担。
- 缺乏并发控制:大模型在 GPU 上的推理受显存限制,通常每个实例仅支持少量并发请求(例如,32B 模型,在 4 * 24GB GPU 上仅支持 8-16 个并发)。Kubernetes 现有的负载均衡机制采用面向请求的随机或轮询策略,而对大模型服务而言,不同请求的耗时区别较大,现有的负载均衡机制可能导致某些实例过载,引发 CUDA 内存不足(OOM)错误,进而导致 Pod 重启。由于大模型文件较大(通常几十到数百 GB),重新加载模型耗时较长,服务不可用时间进一步延长。
- KV Cache 利用不足:大模型推理中的 KV Cache 对性能至关重要,但传统负载均衡将请求分散到不同实例,导致缓存失效,增加计算开销。
- 不支持异构硬件优化:现代 Kubernetes 集群通常包含多种硬件(如 NVIDIA A100、H20 或 H100),不同硬件性能差异显著。现有的流量调度机制无法根据硬件性能优化流量分配,导致资源利用率低下。
- 成本跟踪缺失:大模型推理计算成本高昂,在多租户环境中需要跟踪资源使用(如 token 消耗)以进行成本分配和计费,而 Ingress 不具备此类功能。
解决方案
为解决这些问题,作业帮提出了一种综合的大模型服务流量调度方案,专为 Kubernetes 中的大模型服务设计,整合成模型网关 (Model API Gateway),以增强大模型服务的流量调度能力。提供了以下五项核心功能:
- 模型路由:根据请求元数据动态路由到对应的模型服务,无需请求方修改请求地址和手动配置 Ingress 规则。
- 并发控制:通过基于最小堆的调度算法实现流量均衡,防止 GPU 内存超载,确保服务稳定性。
- KV Cache 亲和:根据会话保持和 prefix cache 将匹配的请求路由到同一后端实例,最大化缓存命中率,提升推理性能。
- 异构设备感知:根据硬件性能动态分配流量比例,优化资源利用率。
- 基于 token 的成本分配:跟踪请求的 token 消耗,支持成本管理和多租户计费。
整体架构图
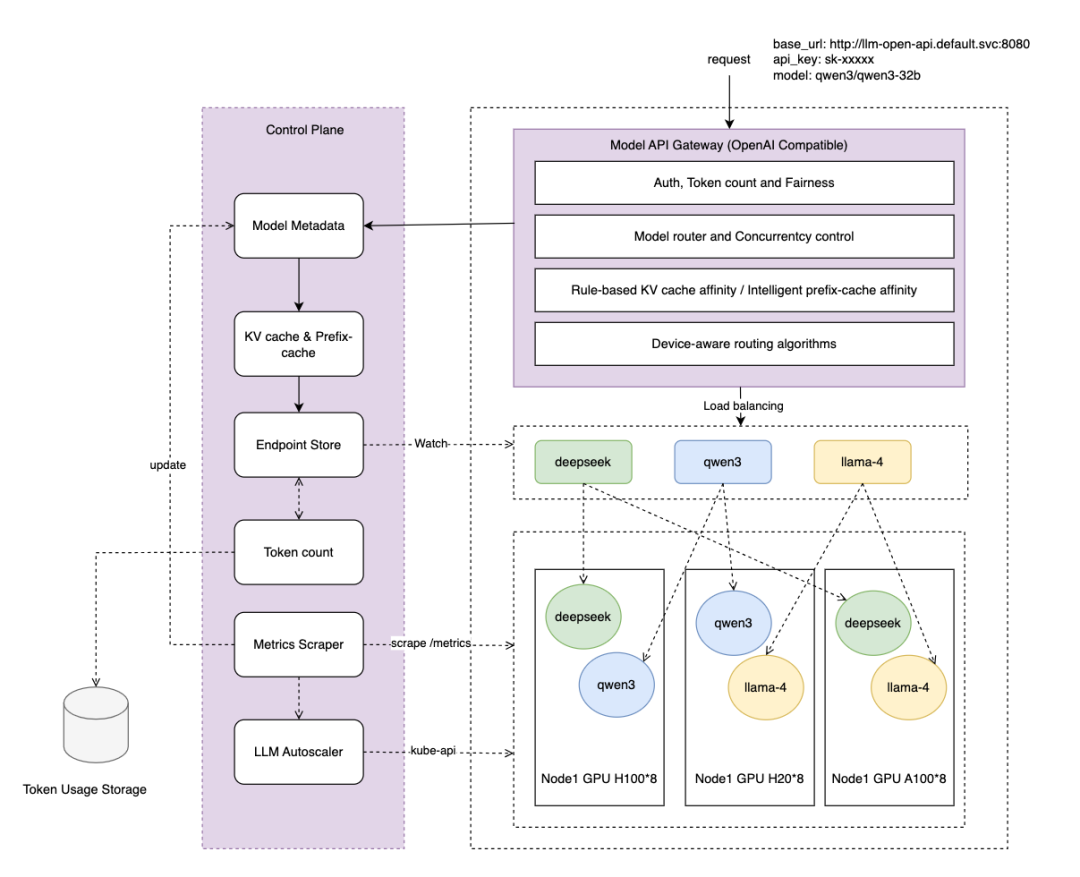
模型路由
问题
传统 Ingress 依赖基于路径或主机名的静态规则,无法满足大模型应用根据请求内容(模型标识)动态路由的需求。例如,业务需要请求多个模型,如果根据不同路径到对应的模型服务,需要修改请求地址和 ingress 的配置规则,这在模型频繁更新的环境中效率低下且易出错。
解决方案
作业帮引入模型路由功能,通过解析 OpenAI 标准请求体中的元数据,解析模型标识,动态将流量路由到对应的模型服务,省去手动配置 Ingress 规则的复杂性。
解析请求体,获取模型标识(如下示例 Qwen3-32B),根据模型标识将流量路由到对应的模型服务。
{
"model": "Qwen3-32B",
"max_tokens": 4096,
"messages": [
],
"stream": true
}
优势
- 易用性:通过模型标识动态路由到不同的模型服务,用户无需手动管理 Ingress 配置。
- 可扩展性:支持动态添加和更新模型服务,无需服务中断。
并发控制
问题
GPU 显存限制了大模型推理的并发能力,通常每个实例仅支持少量并发请求。Kubernetes 现有的负载均衡机制采用随机或轮询策略,而对大模型服务而言,不同请求的耗时区别较大,现有的负载均衡机制可能导致某些实例过载,引发 CUDA OOM 错误,进而导致 Pod 重启。由于大模型文件较大(几十到数百 GB),重启耗时较长,显著影响服务可用性。
解决方案
作业帮提出了一种基于最小堆的最小连接调度算法,优先选择活跃连接数最少的实例分配流量,并设置每个实例的并发上限,确保服务稳定性。
在模型网关层实时跟踪每个后端 Pod 的活跃连接数。
基于堆的调度:
- 维护一个最小堆,存储每个后端 Pod 的当前连接数和标识。
- 对每个请求:
- 从堆中弹出连接数最少的 Pod。
- 如果该 Pod 的连接数低于其并发上限,则将请求路由到该 Pod。
- 更新连接数 +1 并将 Pod 重新插入堆。如果 Pod 达到并发上限,则返回限流错误码。
- 请求结束或达到超时时间后,更新堆中对应 pod 的连接数 -1。
限流和自动扩缩容机制
- 当所有 Pod 达到并发上限时,网关返回限流响应 429 Too Many Requests。
- 通过 /metrics 接口暴露连接数指标,可结合 Kubernetes Horizontal Pod Autoscaler(HPA)根据连接数指标动态扩缩容。
优势
- 稳定性:通过并发控制避免 CUDA OOM 错误导致的服务不可用,减少宕机时间。
- 负载均衡:确保流量均匀分布,减少单实例过载,完成资源效率最大化。
KV Cache 亲和
问题
大模型推理的 decode 过程以自回归方式工作,根据先前生成的 token 输出新的 token,KV Cache 用于中间键值对,以加速连续对话或序列生成任务。如果没有 KV Cache,则整个过程需要重头开始计算,导致重复计算和性能下降。
解决方案
KV Cache 亲和路由通过请求方指定会话标识或 prefix caching 自动计算将请求路由到已有相应 KV Cache 的后端实例,增加缓存命中率,提升推理效率。
- 会话标识:通过请求中的唯一会话标识(如会话 ID 或用户 ID)跟踪会话。
- 亲和路由:在网关层维护会话到后端实例的映射,优先将同一会话的请求路由到同一实例。
- prefix caching:如不指定会话标识,则自动计算 prefix caching 的相似度,路由到最佳匹配的后端。
- 故障恢复:当后端实例不可用时,重新分配会话并清理失效的缓存映射。
优势
- 提高 KV Cache 命中率,减少重复计算,降低延迟和 GPU 资源消耗。
- 增强用户体验,特别是在连续的交互式对话场景中。
异构设备感知
问题
现代 Kubernetes 集群通常包含多种硬件(如 NVIDIA A100、H20 或 H100),每种硬件的性能差异显著。传统 Ingress 和负载均衡器对所有后端实例一视同仁,无法根据硬件性能优化流量分配,导致资源利用率低下。
解决方案
作业帮引入异构设备感知调度,根据硬件性能动态调整流量分配权重。例如,高性能的 H100 GPU 将接收更多流量,而 A100 接收较少。
设备元数据:
- 通过 device-plugin 识别推理硬件设备的型号,为添加 Node 和 Pod 上添加设备信息注解:
metadata:
annotations:
device-type: "nvidia-h100"
性能权重:
- 通过基准测试确定每种设备类型的相对性能(如 TPM 每分钟 token 数)。
- 为每种设备分配权重(例如,A100 1.0,H20 1.5,H100 2.0)。
- 加权调度:扩展最小堆调度器,结合设备权重计算有效连接分数:score = connections / weight。
- 选择分数最低的 Pod 分配流量。
- 示例:
- Pod1(H100,权重 =2.0,连接数 =2):score =2/2.0=1.0
- Pod2(A100,权重 =1.0,连接数 =2):score =2/
- 1.0 =2.01.0 < 2.0 则 Pod1 会接收下一请求。
动态调整:
- 通过 NvidiaDCGM 设备利用率(GPU 显存、计算负载)和实际推理的 tokens/s,动态调整权重值。
优势
- 资源使用优化:根据硬件性能分配流量,最大化集群吞吐量。
- 灵活性:支持运行时动态调整权重。
集成 token 计算能力
问题
大模型推理计算成本高昂,在多租户环境中需要跟踪资源使用(大模型场景普遍采用 token 消耗)以进行计费和配额管理。传统 Ingress 不具备此类功能。
解决方案
作业帮在模型网关层实现 token 计算和统计,跟踪每个请求的输入和输出 token 数,关联用户的成本,并支持配额管理。
- 在模型网关层提供 OpenAI 兼容的鉴权接口,通过 apikey 关联用户的 token 消耗和配额,通过内部集成的分词器计算和统计输入输出 token 数。
- 提供 API 和仪表板供用户查询 token 使用量和成本。
优势
- 成本透明:支持多租户环境的计费和成本分配。
- 配额控制:防止资源滥用,确保公平访问。
- 可扩展性:支持大规模部署,且无需模型服务层关心 token 统计,降低维护成本。
相较于传统 Ingress 的优势
易用性:
- 通过模型路由消除手动配置 Ingress 规则的复杂性。
- 请求方无需维护模型名和请求地址的映射关系。
- 提供 OpenAI 完全兼容的接口。
稳定性:
- 并发控制避免 CUDA OOM 错误。
- 均衡流量分配避免部分 Pod 高负载性能下降。
性能:
- 根据 KV Cache 亲和进行路由,提高 KV Cache 命中率,提升推理效率。
- 异构设备感知,根据硬件性能分配流量,优化资源利用率。
成本管理:
- 基于 token 的成本分配,支持按量计费。
- 配额管理保障公平使用。
应用场景
该方案适用于以下场景:
- 企业级 AI 服务平台:管理内部 AI 工作负载,提供易用、高效、稳定的大模型服务。
- 云服务提供商:提供大模型即服务(Model-as-a-Service),支持按量计费。
- 研究实验室:部署实验性模型,支持动态扩展和资源优化。
总 结
通过模型网关 (Model API Gateway) 实现针对 Kubernetes 中大模型服务独特需求的流量调度方案,克服了传统 Ingress 的局限性。通过模型路由、并发控制、KV cache 亲和、异构设备识别和基于 token 的成本计算的能力,显著提升了大模型服务的易用性、性能和稳定性,并降低了运维成本。未来可探索集成外部模型服务提供商、支持 Serverless 推理等,进一步提升模型网关的能力,为大模型服务在业务领域的应用打下坚实基础。
文章来自于微信公众号“InfoQ”,作者是“作业帮技术团队”。

