近年来,强化学习(Reinforcement Learning, RL)在提升大语言模型(LLM)复杂推理能力方面展现出显著效果,广泛应用于数学解题、代码生成等任务。通过 RL 微调的模型常在推理性能上超越仅依赖监督微调或预训练的模型。也因此催生了大量的相关研究。但随之而来的,是一系列令人困惑的现象:不同研究提出了不同的 RL 优化技巧,却缺乏统一的实验对比和机制解释,有的甚至得出相互矛盾的结论。对于研究者和工程师而言,这种 “方法多、结论乱” 的局面,反而增加了落地应用的难度。
为此,阿里巴巴淘天集团和爱橙科技联合多所高校,基于自研并开源的 RL 框架 ROLL, 开展了系统化研究。通过大规模实验,全面评估了当前主流 RL for LLM 方法中的关键技术组件,揭示其在不同设置下的有效性以及每类策略的底层机制,并最终提出一种仅包含两项核心技术的简化算法 ——Lite PPO,在多个基准上表现优于集成多种技巧的复杂方案。

- 论文《Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning》
- 论文链接:https://arxiv.org/pdf/2508.08221
问题背景:技术多样性带来的选择困境
当前 RL4LLM 领域发展迅速,但存在以下问题:
- 标准不一:归一化方式、剪裁策略、损失聚合、样本过滤规则等策略存在多种实现方案,彼此之间缺乏统一比较基础。
- 结论不一:不同研究因模型初始性能、数据分布、超参设置等差异,得出相互矛盾的结果,导致实际应用中难以判断某项技术是否真正有效。
- 机制解释不足:多数方法缺乏对 “为何有效” 的理论或实证分析,导致技术使用趋于经验化,形成 “调参依赖”。
针对上述问题,该研究旨在回答两个核心问题:
- 不同 RL 优化技术在何种条件下有效?背后的机制是什么?
- 是否存在更简单、稳定且通用的技术组合?
公平竞技场:用统一框架拆解 RL 技巧
为了确保公平对比和结论可靠,该研究设计了严格的实验体系:
- 统一实现平台:所有实验基于开源的 ROLL 框架完成,避免因工程实现差异引入偏差。
- 清晰基线设定:以基于 REINFORCE 算法计算优势值的 PPO 损失(无价值函数)作为基线,逐项添加对应算法技术,精确量化每个模块的真实效果。
- 多种场景覆盖:涵盖不同模型规模(4B/8B)、模型类型(Base 模型 与 Instruct 模型)、任务难度(Easy/Medium/Hard)下的实验分析。训练集从开源数据集(SimpleRL-Zoo-Data, DeepMath 等)中采样过滤,按照难度等级划分为为:Easy, Medium, Hard
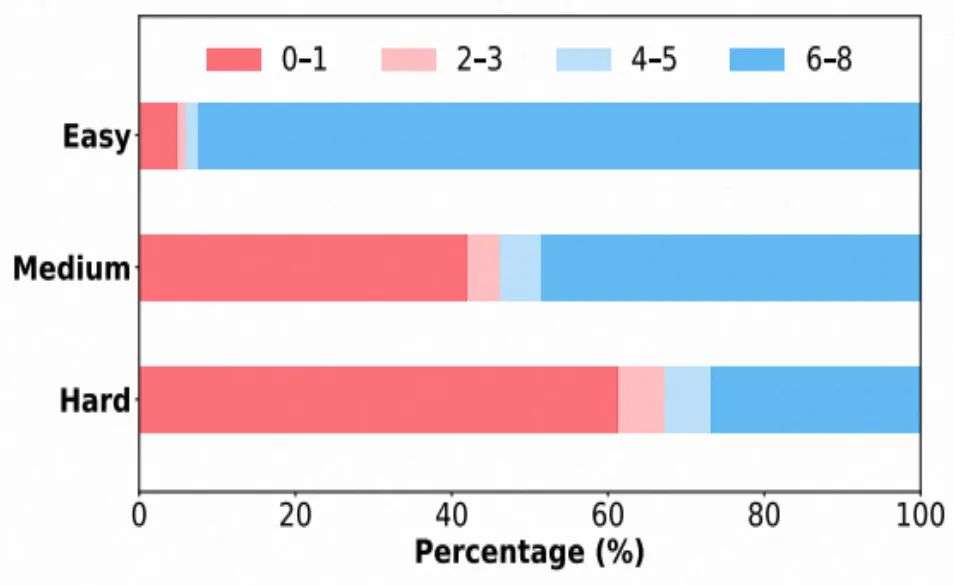
各难度数据集中 rollout 8 次的正确次数分布。
- 解耦式评估:将归一化、剪裁策略、损失形式、过滤机制等关键模块独立测试,避免多因素耦合干扰判断。
- 多维度评估任务:在六个数学推理数据集上进行测试,覆盖从基础算术到国际数学奥林匹克难度的问题。
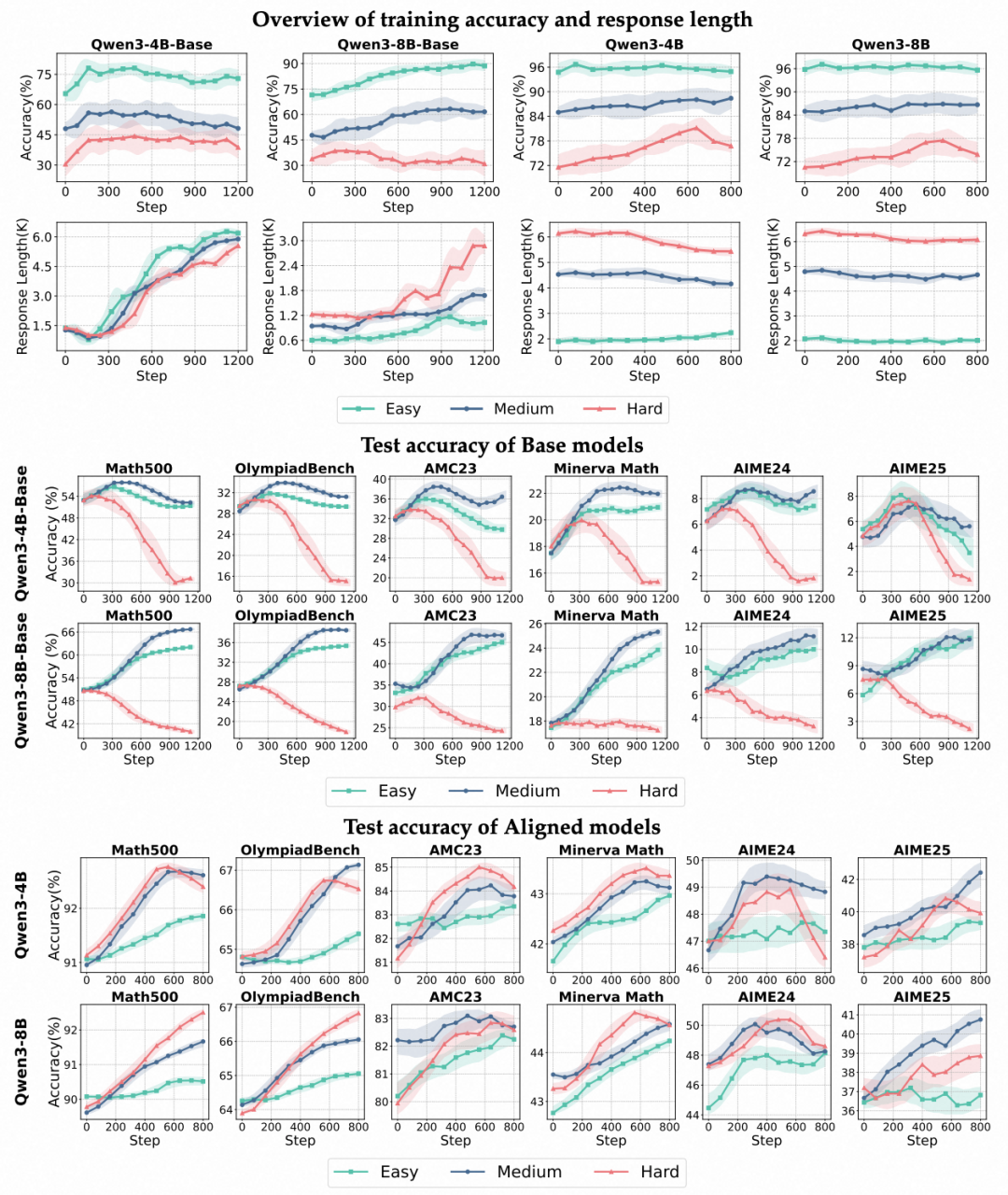
不同模型在不同数据难度下的准确率和回答长度变化趋势。为了确保对比清晰直观,所有曲线均使用相同的参数进行平滑处理。
核心发现:技巧并非普适,需因 “场景” 而异
优势归一化:Group-Mean + Batch-Std 最稳健
理论介绍
优势归一化通过平移 / 缩放优势值,降低梯度方差,稳定更新。常见的两种归一化方式包括:
- 组内归一化(Group-level):同一问题的 K 条响应之间做对比,强化组内相对优劣。
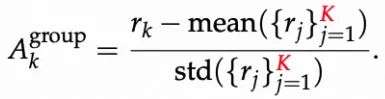
- 批次归一化(Batch-level):对整个批次内的 N*K 个响应进行奖励归一化,利用更大样本估计方差,抑制极端样本主导梯度。
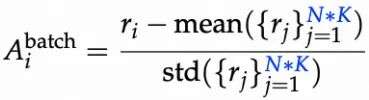
关键发现
1. 对奖励分布的敏感性:
- 组内归一化(Group-level)在不同奖励设置下都更稳定,尤其在稀疏 / 偏斜分布下。
- 批次归一化(Batch-level)对奖励分布的偏斜高度敏感,在数据分布不平衡的情况下更容易崩溃,因为少数极端样本会主导优势估计。
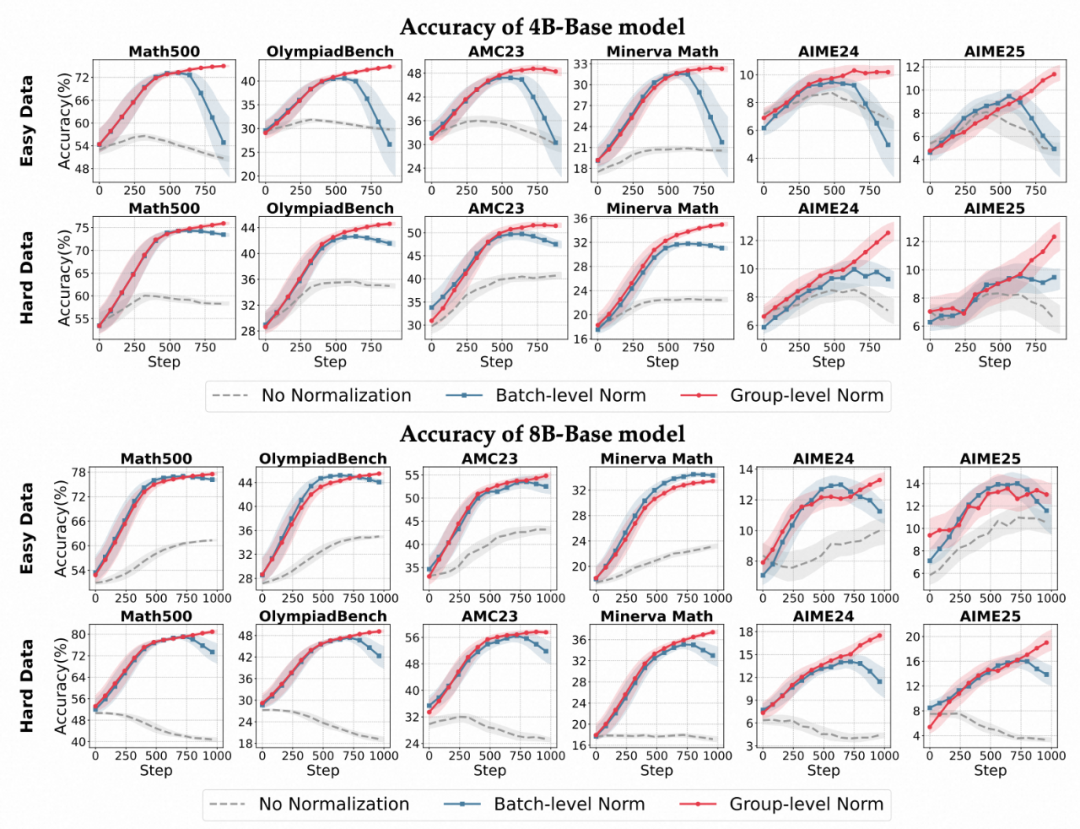
各个模型在不同优势归一化方式下的准确率变化趋势。
2. 标准差项的风险:
- 当样本奖励分布高度集中的场景下(例如简单数据集下几乎全对的样本分布),标准差极小会放大梯度,导致训练不稳定乃至崩溃。
- 去掉标准差(仅做均值平移)在此类场景更稳健;在高方差场景下,两种方式差异不大。
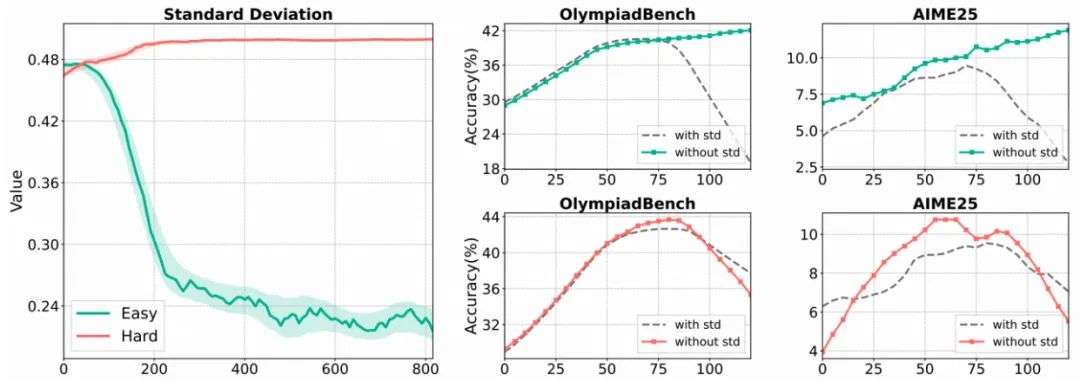
左图:在不同难度数据上的标准差变化趋势。右图:在批次归一化下移除标准差前后的准确率变化趋势。
3. 混合方案的优势:
- 实验发现,“组内均值 + 批次标准差”的混合归一化更稳健,旨在兼顾局部相对比较的语义合理性与全局方差估计的统计稳健性。
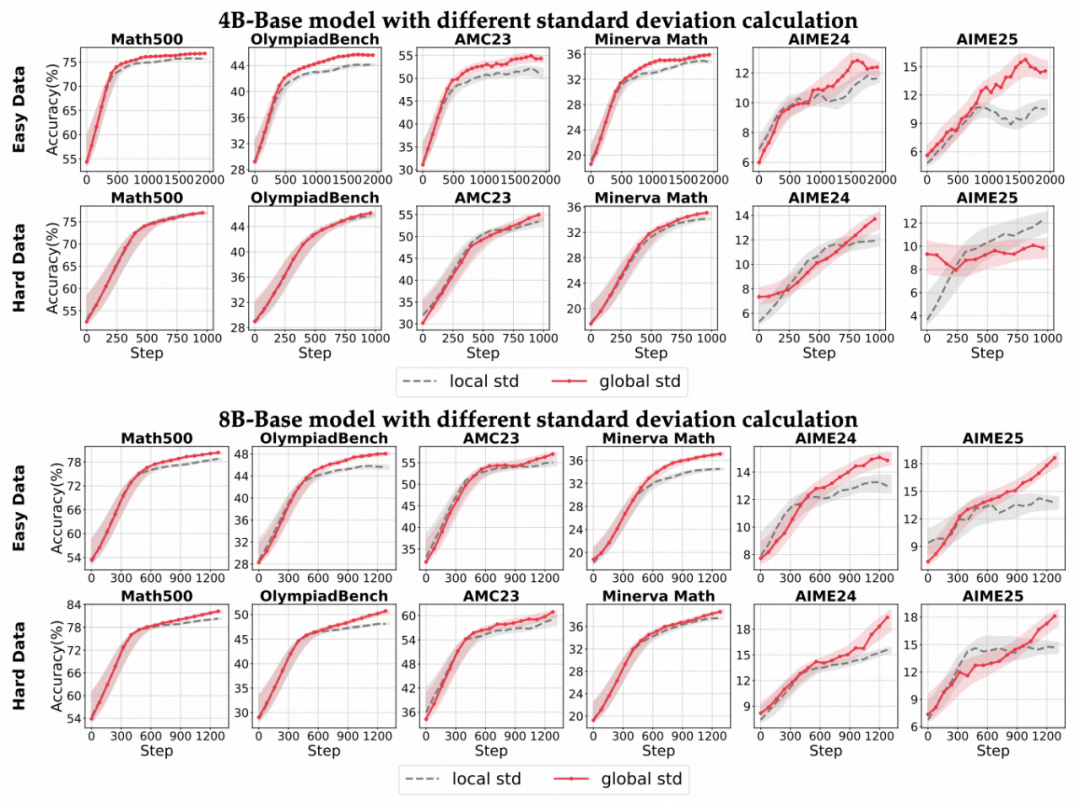
各个模型上不同标准差计算方式的准确率变化趋势。
裁剪机制:Clip-Higher 并非普适
理论介绍
PPO 通过限制新旧策略概率比的变化,避免过大步长导致策略崩塌。但其同等限制上 / 下方向变化,常会过度压制低概率 token 的提升,导致熵快速下降、探索不足。
- Clip-Higher:DAPO 提出将上界放宽(上行允许更大更新,下行保持保守),给 “潜力 token” 更大爬升空间,缓解熵塌陷,促进结构性探索。
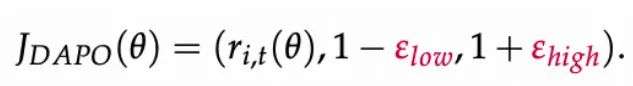
生效机制解析:
1. 模型能力依赖性:
- 对于对齐后的 Instruct 模型,提升上剪裁阈值(ε_high)能有效减缓熵值下降,促进探索。。
- 对于未对齐的 Base 模型,单纯扩大上剪裁范围作用十分有限,甚至可能扰乱优化过程、降低整体表现。
- 形成这一差异的原因可能在于:基础模型初始表现不稳定,如果一开始就贸然增大探索空间,容易出现非预期行为导致优化偏离正确方向;相反,经过对齐的模型分布更均匀,适度增加上限能释放潜藏 “优质” 输出(详见论文 Figure 10)。
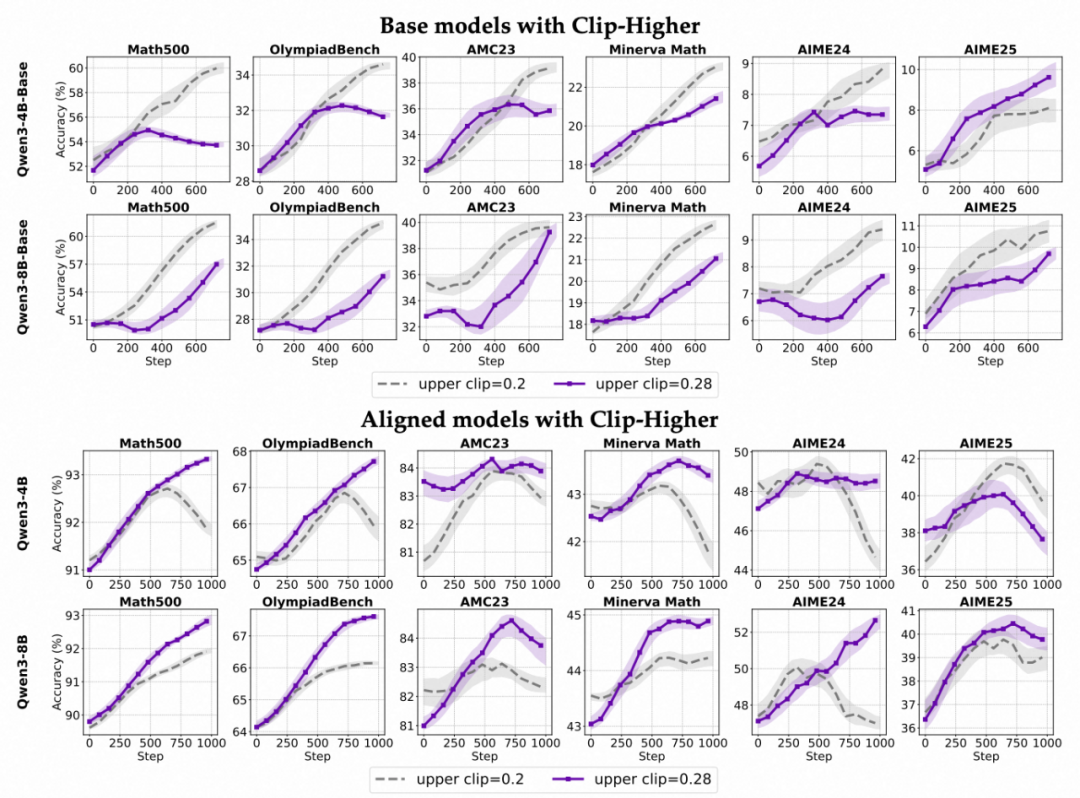
各个模型在不同裁剪上限下的训练趋势对比。
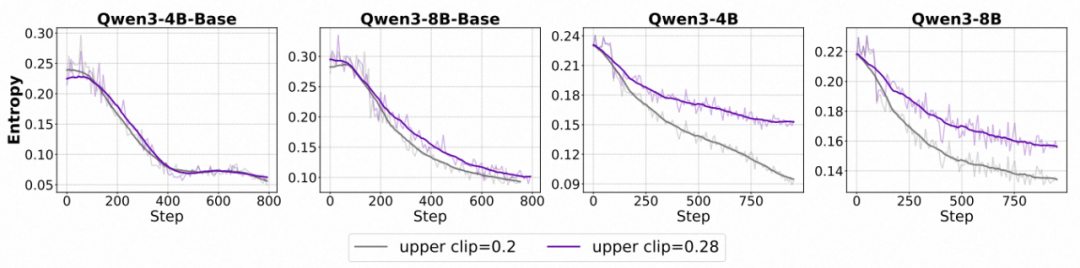
各个模型在使用不同裁剪上限下的熵变化趋势。
2. 从语言结构视角解析:
- 当采用低上界时,被剪裁频发的是 “语篇连接词”(如 "therefore,"" "if"),它们往往开启新推理分支,被抑制会压缩思维路径。
- 将上界放宽后,剪裁焦点转向 “功能词”(如 "is", "the" 等),连接词更自由,推理结构更丰富,同时保留句法骨架稳定。
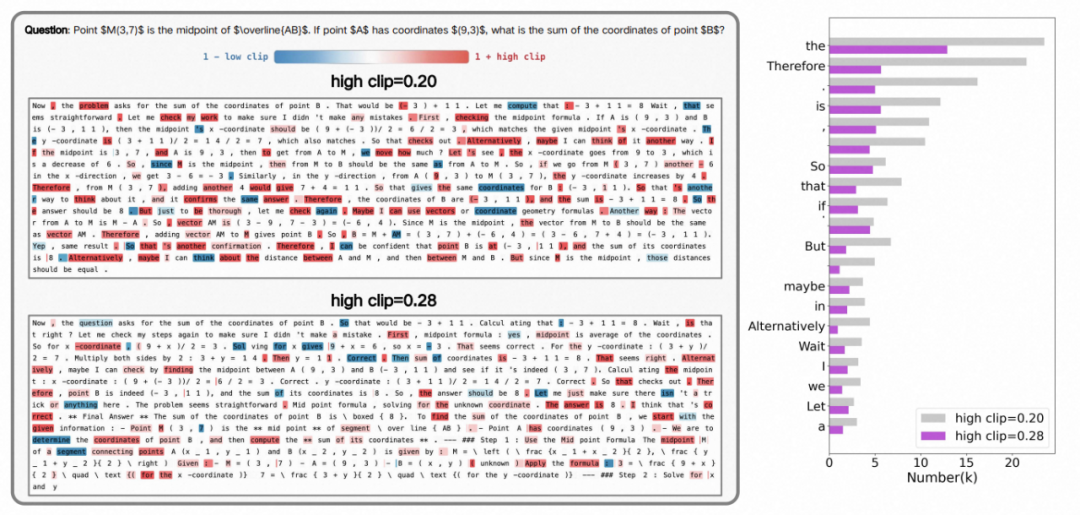
左图:不同裁剪上限下的 token ratio 可视化展示。右图:出现频率最高的前 20 个被剪裁的 token
3. 上界选择的 “Scaling Law”:
- 针对不同大小的模型,参数调节需要差异化:在较小规模(如 4B 参数)情况下,随着剪裁阈值增加,模型性能持续提升;
- 而更大规模(如 8B),性能提升存在拐点,阈值过高则效果反而减弱。因此,剪裁参数应根据模型体量灵活设置,寻求最优解。
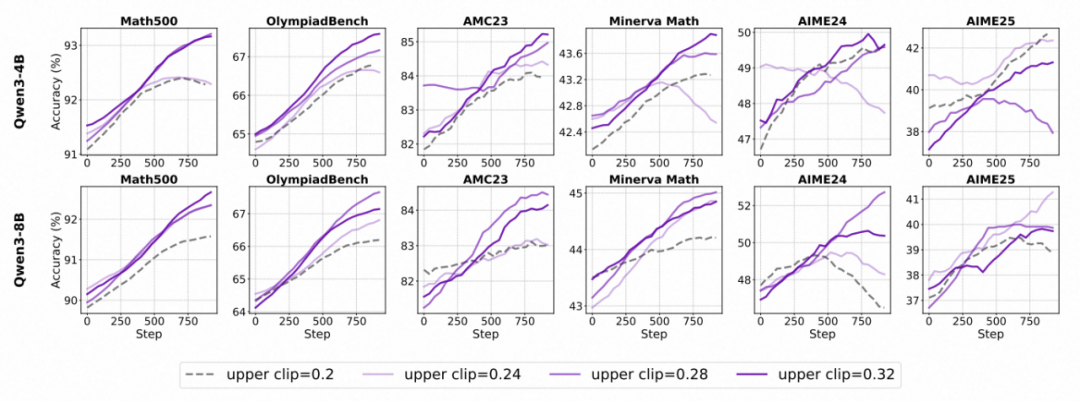
各个模型使用不同裁剪上限的准确率变化趋势。
损失聚合方式:token-level 更适合 Base 模型
理论介绍
当前主流方案分别有 sequence-level loss 和 token-level loss:
- 序列级损失:聚焦于句子或样本整体,适合结构已对齐、输出稳定的模型。
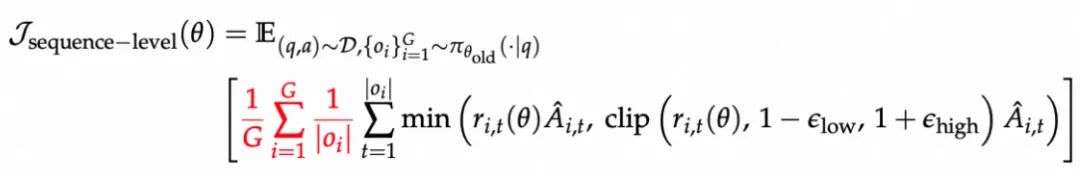
- 词元级损失:以 token 为基本单位,每个 token 都对总 loss 平均贡献,抑制短句偏置,补足长推理激励;
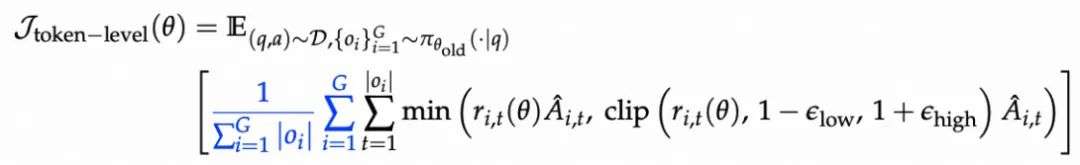
关键发现:
- 基础模型:采用 token-level 的损失聚合方式更优,收敛速度和准确率大幅提升;
- 对齐模型:采用 sequence-level 的损失聚合方式普遍更优。
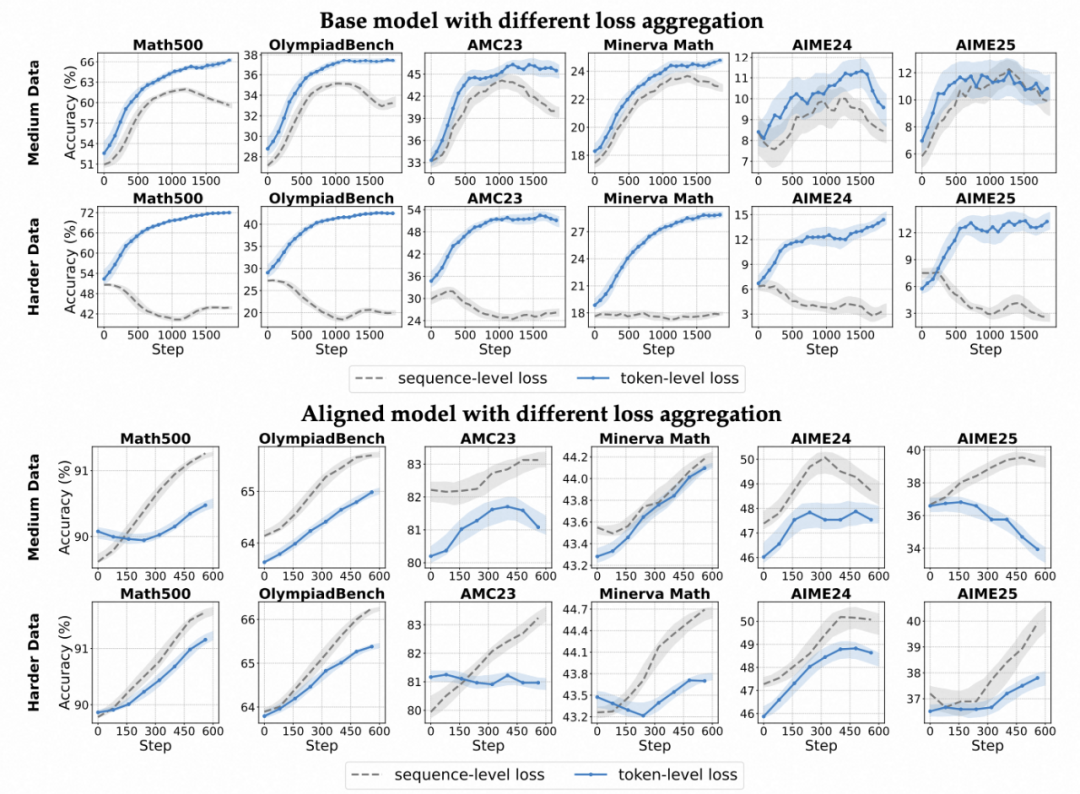
各个模型上采用不同损失聚合方式的准确率变化趋势。
过长样本过滤:效用依赖于模型输出特征
理论介绍
训练时设定最大生成长度,复杂推理常被截断,尚未给出结论就被判负,形成 “错误惩罚” 噪声,污染学习信号。过滤策略:对超长 / 截断样本的奖励进行屏蔽,避免把 “尚未完成” 当成 “错误”, 从而引入噪声。
实验发现
1. 推理长度影响:
- 当最大生成长度设为 8k tokens 时,应用过长样本过滤能有效提升模型的训练质量,并且能够缩短输出的响应长度。
- 当长度限制放宽至 20k tokens,模型有更充分的空间完成复杂推理,生成的响应长度增加。此时,被过滤的样本更多是重复或无法自然终止的退化输出,而这类样本本身占比有限且学习价值较低,从而导致过滤操作带来的增益减弱。
- 结果表明,overlong filtering 的实际效用高度依赖于模型在当前数据下的输出特征,需按场景动态调整。
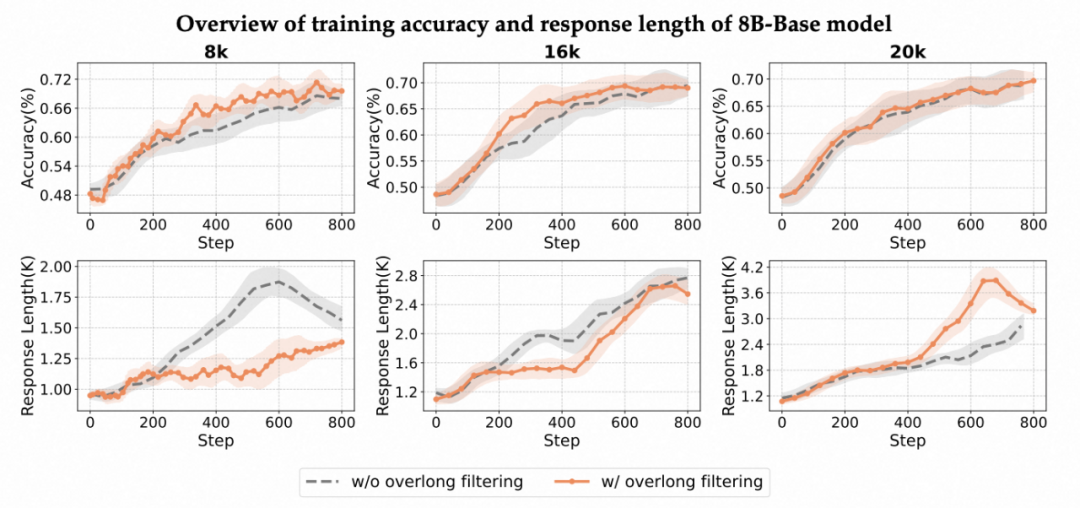
不同训练长度下是否使用超长样本过滤的实验表现。
2. 生效机制探究:
- 通过对过滤掉的样本类型进行统计,发现引入 Overlong Filtering 能够降低训练中 “不能正确预测 EOS 导致重复生成” 的比例(repeat-ratio),这表明其增强了模型的终止建模能力。
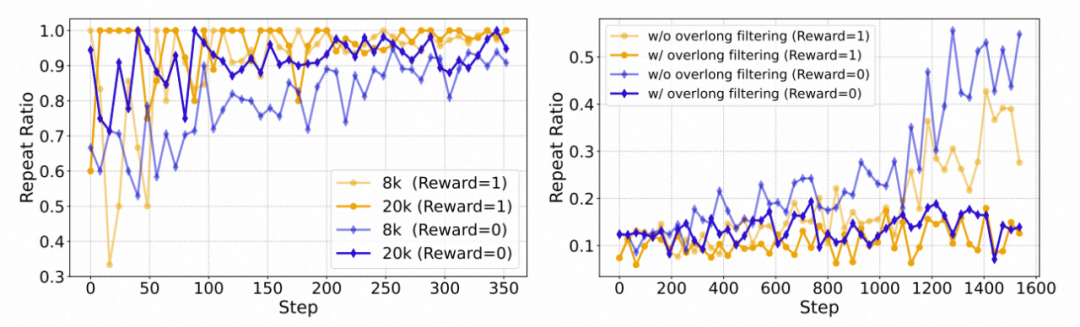
左图:在不同训练长度下,正确回答和错误回答的重复样本分布。右图:在采用和未采用超长样本截断场景下的重复样本分布。
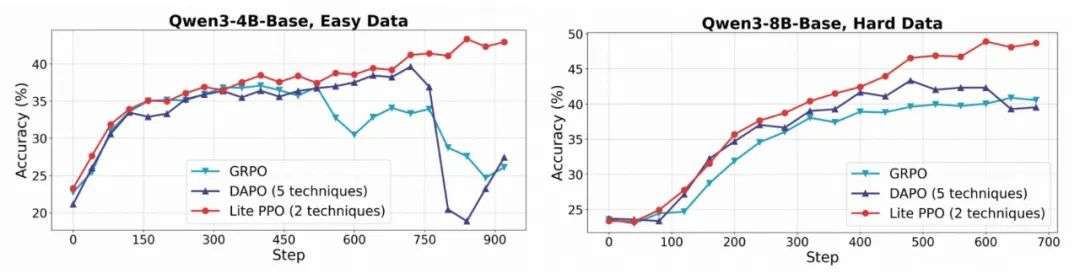
极简新范式:Lite PPO—— 两步胜五技
综合上述系统分析,该研究提出 Lite PPO—— 一个仅包含两项技术的简化 RL 流程:
- 混合优势归一化(组内均值 + 批次标准差);
- token-level 损失聚合。
在以基础模型为初始策略的设置下,Lite PPO 在多个数学推理任务上达到甚至超过 DAPO 等融合五项技巧的复杂方法的表现。其优势体现在:
- 训练过程更稳定;超参敏感性更低;
- 工程实现简单;性能更优。
这充分说明:“技巧堆叠” 并非性能提升的主要途径,合理的组合能带来更强的鲁棒性和高效性。
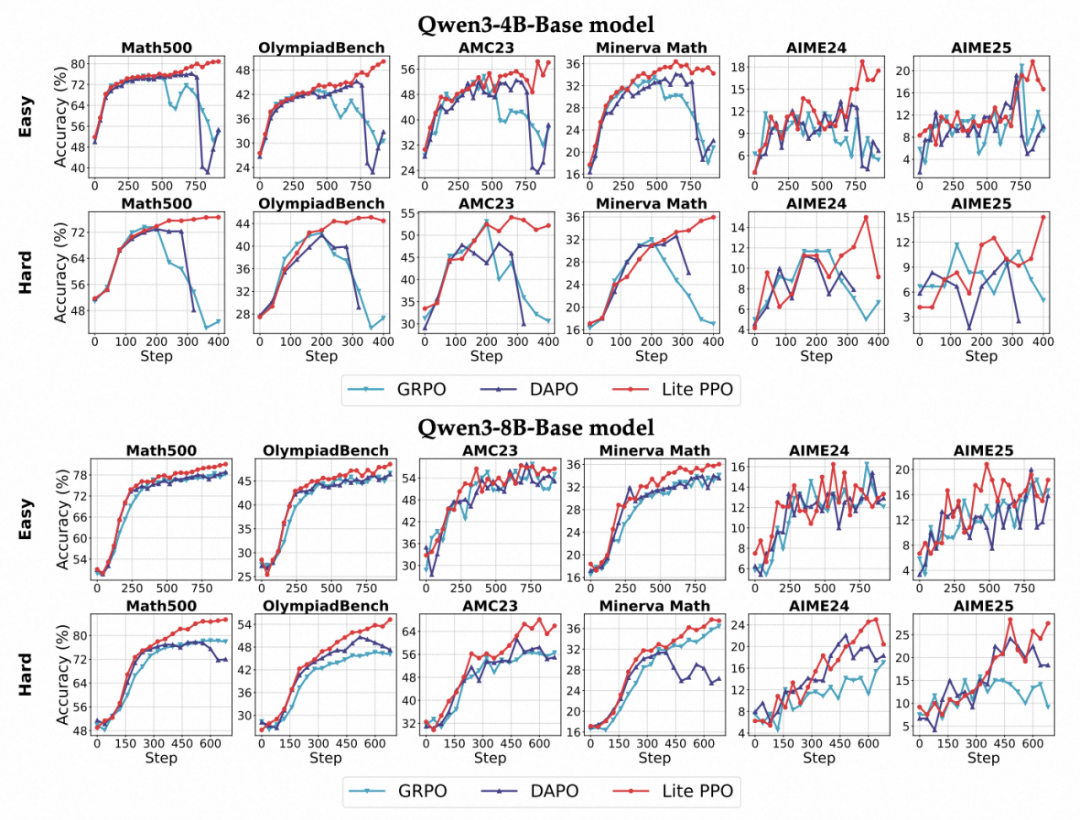
结论
本文贡献主要体现在三方面:
1. 建立首个系统性对比框架
对归一化、剪裁、损失聚合、样本过滤等关键技术进行了独立、可控的实证分析,明确了各项技术的适用边界。
2. 验证极简设计的优越性
提出的 Lite PPO 方案表明,复杂的 “多技巧堆叠” 并非必要。在多数实际场景下,精简而有针对性的技术组合反而更具鲁棒性和可扩展性。
3. 推动可复现与标准化研究
基于开源 ROLL 框架开展实验,所有配置公开,为后续研究提供了可复现基准,有助于提升领域透明度与协作效率。
从中我们获得如下启发:
- 给开发者的建议:别再追求 “trick 大全”,应根据模型类型(Base/Align)、任务特性(长度、难度)、奖励设计等实际需求,有针对性地配置合理技巧。
- 对学术界的启示:新方法若想 “立得住”,必须重视广泛适用性与易复现性。Lite PPO 的成功案例表明,RL 优化未必复杂即优,而是贵在精粹。
关于 ROLL 团队
本研究由阿里巴巴 ROLL 团队完成。ROLL 是一套面向高效、可扩展、易用的强化学习训练框架,支持从十亿到千亿参数大模型的优化训练,已在多个场景中展现出显著性能提升。
此次论文正是 ROLL 团队在开源框架实践中的又一次探索成果,未来,ROLL 团队将持续关注 RL 社区发展并分享更多实践经验。同时,我们也将继续完善自研的 ROLL 框架,以灵活地适应各种技术,为在各种场景中有效应用强化学习提供实用支持。
项目地址:github.com/alibaba/ROLL
文章来自于微信公众号“机器之心”。
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner


