让LMM作为Judge,从对模型的性能评估到数据标注再到模型的训练和对齐流程,让AI来评判AI,这种模式几乎已经是当前学术界和工业界的常态。我之前也介绍过这方面的研究,但没想到打脸来得这么快!之前也有朋友曾质疑过 LLM as judge。最近一篇题为《既无效又不可靠?调查将大型语言模型作为法官的运用》(Neither Valid nor Reliable? Investigating the Use of LLMs as Judges) 的立场论文, 对当前人工智能领域的热门趋势LLMs as Judges进行了深刻反思和批判。研究者认为,我们对LLJs的应用热情已经远远超过了对其作为评估工具本身是否科学、可靠、有效的严格审查。这就像我们急于使用一把新尺子去测量东西,却没有先确认这把尺子本身的刻度是否准确。

“AI裁判”究竟用在何处?
在深入探讨其风险之前,我们有必要了解“LLM Judges”如今的应用有多广泛。根据研究者的梳理,其应用已远超简单的性能评估,深度渗透到模型开发的全流程,主要涵盖三大功能:
- 性能评估 (Performance Evaluation):这是最传统的应用,即评估模型生成内容的质量。
核心领域:文本摘要、机器翻译、对话生成等。
- 数据构建 (Data Construction):利用AI来自动生成或标注训练数据,以替代部分人力。
典型任务:数据标注,尤其是在仇恨言论检测、政治立场分类等主观性强的任务中。
- 模型增强 (Model Enhancement):将“AI裁判”直接整合进模型的训练和对齐流程中,以提升或规范模型行为。
关键场景:安全对齐(作为实时安全护栏、自动进行红队演练)、奖励建模、以及实现模型的“自我提升”和“自我对齐”。
可以看到,“LLM Judges”已经从一个“评估员”,演变成了贯穿数据准备、模型训练、安全部署等环节的“多面手”。
拿什么来衡量“AI裁判”?
为了系统地分析这个问题,研究者们搬出了一个看似“老古董”但极其重要的工具源自社会科学的“测量理论”。这个理论就是用来校准我们手中这把新潮的“AI评估尺”的,它有两个核心概念,缺一不可。

- 信度 (Reliability):指测量的稳定性。也就是说,用同一种方法反复测量同一个东西,结果是否总是一致。例如,一个LLM裁判在三次评估同一份文本时,给出的分数是否都差不多,而不是忽高忽低。
- 效度 (Validity):指测量的准确性。也就是说,您的测量结果是否真实反映了您想要测量的那个概念。例如,LLM裁判给出的“流畅度”分数,是否真的只代表了文本的流畅程度,而不是被文本长度、复杂词汇等其他无关因素干扰了。
基于这个框架,研究者们对支撑LLM裁判(LLJs)广泛使用的四个核心假设,进行了逐一的审视。
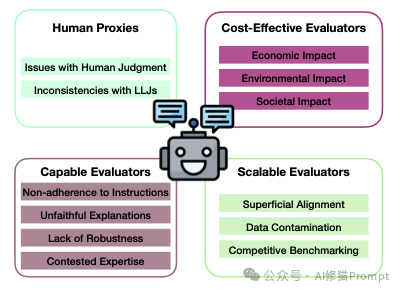
假设一:AI能完美替代人类?
业界普遍认为,LLMs是人类判断的有效代理 (LLMs as a Proxy for Human Judgment),只要AI裁判的评分和人类专家的评分高度相关,就证明它是有效的。但研究者们一针见血地指出,这个逻辑链条的起点,所谓“人类判断”这个金标,本身就是摇摇欲坠的。

- 人类评估本身就问题重重:论文指出,在自然语言生成(NLG)领域,人类评估的实践其实非常混乱,缺乏统一标准。比如,对于什么是“连贯性”,不同的研究、不同的标注者可能有完全不同的理解和打分标准,这导致人类评分本身就存在很大的不确定性。

- 用混乱去验证混乱:因此,用一个本身就不太可靠、充满随机误差的“金标准”去验证LLM裁判的可靠性,其说服力自然大打折扣。这就好比用一把刻度模糊的尺子去校准另一把新尺子。
- LLM裁判加剧了问题:更糟糕的是,目前的LLM裁判实践不仅复制了这些问题,甚至可能因为其内部决策过程不透明而加剧了它们。例如,在使用同一个公开基准(如SummEval)时,不同的研究给LLM的指令、评分量表和评估流程都各不相同,使得结果更难横向比较。
假设二:能力强就等于好裁判?
另一个普遍看法是,LLMs是能干的评估者 (LLMs as Capable Evaluators),既然LLM本身能力这么强,当个评估员肯定绰绰有余。可现实挺骨感的,研究者们发现,作为裁判的LLM存在一系列内在缺陷,严重影响其判断的信度和效度。
- 不听指挥 (Instruction Adherence):研究发现,LLM裁判经常“夹带私货”,并不严格遵循您在指令中给出的评估标准,反而会依赖自己的一些内部偏见,甚至混淆不同的评估维度(比如把“相关性”和“流畅性”搞混)。
- 解释不可信 (Explainability):虽然LLM可以为自己的评分生成解释,但这些解释的“忠实性”值得怀疑。它可能只是为了让结果看起来合理而编造的理由(高“表面效度”),而非其真实的决策逻辑。
- 充满偏见 (Robustness):LLM裁判表现出五花八门的偏见,比如位置偏见(偏爱排在前面的选项)、冗长偏见(喜欢内容更长的回答)、从众偏见(偏爱多数意见)等。
- 极其脆弱 (Robustness):它们对简单的对抗性攻击几乎没有抵抗力。研究表明,通过在文本中加入一些精心设计的、不影响语义的微小扰动,就可以轻易地操纵LLM裁判的评分,甚至让它把100%的有害内容标记为无害。
- 缺乏专业知识 (Expertise):在需要特定领域知识(如事实核查、安全评估)的任务中,LLM本身的能力就存疑,让它来当裁判,其“内容效度”自然无法保证。
假设三:自动化评估能“大力出奇迹”?
大家都爱“大力出奇迹”,LLMs是可扩展的评估者 (LLMs as Scalable Evaluators),觉得用AI裁判可以大规模、自动化地搞定评估和模型对齐,效率直接拉满。但研究者警告说,这种做法可能正在制造一个巨大的、自我循环的“信息茧房”,最终损害评估的“预测效度”。
- 数据污染与自恋偏见:当您用同一个系列的LLM(比如GPT系列)去生成训练数据、训练模型、最后又用它来做评估时,一个被称为“自恋偏见”或“自我增强偏见”的问题就出现了。模型会不可避免地偏爱与自己同源的模型所生成的输出,导致评分虚高。
- 为刷分而战:自动化排行榜(如Chatbot Arena)的出现,加剧了“应试”现象。各个模型为了在排行榜上获得更高名次,可能会过度优化去迎合裁判模型的偏好,而不是真正提升通用能力,这是一种典型的“过拟合”。
- 肤浅的安全对齐:研究者提到“肤浅对齐假说”,即当前的安全对齐更多是让模型学会了某种“说话风格”(比如礼貌地拒绝回答),而非真正理解了安全概念。过度依赖LLM裁判进行自动化安全评估,可能只会筛选出越来越会“装无辜”的模型,而无法解决深层安全问题。
论文的批判并非空穴来风,矛头直指行业巨头
研究者们的批判并非泛泛而谈,在关键部分直接指向了三家科技巨头。
- 明确点名Google和OpenAI还有Meta:在讨论“竞争性基准测试”的弊端部分,论文引用研究指出,像Chatbot Arena这样的评估平台存在“有利于Google和OpenAI等专有提供商的不平等数据访问”问题。这个事情我记得前几个月在网上还热议过一阵子。以Meta为例:在分析“LLMs作为安全法官”时,论文明确提到了Meta公司的Llama Guard模型作为一个实例。此外,在参考文献中,论文还引用了一篇关于“Meta的Llama 4‘herd’争议与AI污染”的文章,直接将其与数据污染问题联系起来。
假设四:AI裁判真的“物美价廉”?
省钱,LLMs是成本效益高的评估者 (LLMs as Cost-Effective Evaluators),这绝对是AI裁判最吸引人的一点。不过,研究者提醒我们必须算算那些看不见的“隐形成本”,这些成本关系到评估的“后果效度”,即这项技术应用后带来的长远社会影响。
- 经济与伦理冲击:大规模采用AI裁判,直接冲击的是全球数以万计的数据标注员的生计,这是一个已经很脆弱的群体。这背后是复杂的社会和伦理问题,不能简单地用“效率”二字一笔带过。
- 环境成本:虽然训练模型的环境成本备受关注,但大规模、持续地使用LLM进行评估(这是一种推理任务)所产生的能源消耗和碳排放同样惊人,且随着模型越来越大,这个问题会愈发严重。
- 社会偏见的放大器:LLM会学习并反映训练数据中存在的社会偏见。当一个带有偏见的LLM成为“裁判”时,它可能会在评估中系统性地给某些特定人群(如特定性别、种族)相关的回答打低分,从而在下一代模型的开发中进一步固化甚至放大这些偏见。
前进之路 (The Path Forward)
这部分没有停留在批判,而是建设性地提出了三条核心建议
1.放弃“一刀切”的评估方法,强调情境化应用:
目前LLJs的应用存在一个巨大疏忽:无论任务和领域有何不同,部署和设计评估的方式都大同小异。这种做法是危险的,可能导致有害的后果。 一个具体的例子是:使用LLJs来大规模进行“红队演练”(即寻找模型漏洞)可以拓宽评估范围,这是有益的。但如果将同样的方法直接用于模型的安全过滤统,就可能只会训练出“表面上”的安全行为,而非真正的安全理解。因此,评估LLJs的角色必须综合考虑任务性质、应用领域和评估目标等多个关键维度。
2.紧急呼吁改进整个领域的评估实践:
作者认为,减轻LLJs自身的偏见固然重要,但整个领域更迫切需要的是改进评估实践本身。
他们引用近期的争议事件指出,科技公司有操纵现有评估框架的行为,这引发了对数据污染、为跑分而进行的竞争性基准测试以及对基准过度拟合等严重问题的担忧。 尽管评估在机器学习发展中至关重要,但从业者之间缺乏严谨、共享的实践方法。大家共享的是基准和指标等“技术产物”,而不是科学的方法论。这篇论文证明,LLJs的采用不仅复制并加剧了NLG评估中长期存在的缺乏标准化和系统化的问题,还带来了新的挑战。
3.倡导评估模式的根本性转变:从自我评估到独立监督:
这是最激进也是最深刻的建议。作者明确指出:“也许是时候改变那种依赖有利益关系的公司来提供其旨在推向市场的产品进行透明全面评估的模式了”。 他们主张,应该努力建立适当的机制,以实现透明、有效和可靠的评估。这暗示着需要一个类似于其他高风险行业(如药品、航空)的独立第三方监督体系。
写在最后
研究者最后强调,我们并非全盘否定LLJs的价值。在某些场景下,如用于探索性测试或减轻人类标注有害内容的负担,它仍有巨大潜力。在正确实施的情况下,LLJs为推进NLG评估提供了宝贵的机会。比如它们可以帮助建立更真实、互动性更强的长期评估流程,更好地反映真实世界的使用情况。另一个重要应用是,它们可以减轻人类标注者处理有害或创伤性内容的负担。关于我之前写过LLMs as Judges的文章,感兴趣您可以看下这两篇


Meta与伯克利最新:元奖励Prompt,让LLM作为元法官能自我改进(包含Prompt模板)
这篇论文最深刻的洞见
第一,研究者们提出,LLJs的缺陷不仅仅是一个技术工具的问题,更是整个AI领域评估文化危机的症候。当前领域内普遍存在一种为了在排行榜上获得更高排名而进行的“竞争性基准测试”文化。这种文化导致了对基准的过度拟合和评估方法的随意性。LLJs的出现,只是将这种本已存在的、不科学的文化自动化并放大了。这从根本上将讨论从“如何修正LLMs as Judges的技术偏见”提升到了“如何重建科学、严谨的AI评估方法论”的层面。
第二,公开质疑科技巨头“既当运动员又当裁判员”的现状。在AI能力越来越强,影响越来越广的今天,让开发者自我评估其产品的安全性和有效性,其固有的利益冲突是显而易见的。作者呼吁建立独立的、透明的评估机制,这实际上是在倡导一种AI治理的结构性变,从依赖企业自律转向更强有力的外部监督和社会问责。这在当前关于AI监管的全球讨论中,是一个非常关键且有力的声音。
总而言之,这篇论文为当前火热的AI领域注入了一剂冷静剂,它提醒我们,在追求技术飞速迭代的同时,更要回归科学的本源,审慎地构建我们赖以衡量进步的基石。
文章来自于微信公众号“AI修猫Prompt”。
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


