这几天饼干哥哥的公众号、小红书、X都被Nano Banana刷屏了。
我甚至写了两篇内容来介绍它的玩法:
Awesome Nano Banana!迄今最强生图模型的28个玩法合集 | 附提示词
我在Lovart里把 Nano banana 转成生产力,轻松做凡人修仙传动画
上一个这么出圈的,还是ChatGPT 4o,那时满屏都是宫崎骏的吉卜力风格动漫图,而且它生图的能力已经很强了。

但Nano Banana更胜一筹,它亮点集中在人物一致性、多图融合与自然语言精准局部编辑。
突然发现,AI圈就是一个大循环。
GPT-4o发布才过去半年,Nano Banana这种「下一代」的生图模型就出来了。
这难道是AI界的摩尔定律?不敢想再过半年后,会是什么样的「魔鬼级」生图模型来屠Nano Banana
想到这,我就好奇它到底强在哪?凭啥一夜之间,就以燎原之势席卷全球了。
为了搞明白,我特意去看了一遍🍌创作团队的访谈。看完后,只能说:GPT-4o只能认输,确实没法打。
Google AI Studio的产品负责人Logan Kilpatrick,与Gemini图像模型的核心成员Kaushik、Robert、Nicole和Mostafa进行了一场深度对谈。
地址:https://www.youtube.com/watch?v=H6ZXujE1qBA
从“抽卡”到“持续性对话”
“传统”的生图模型,如Midjourney,需要结构化、巨长的prompt
而GPT-4o依赖背后ChatGPT超强理解能力,解决了这个问题,只需要简单描述尽管实现复杂画图需求,但需要多次抽卡的问题依然没解决。
而Nano Banana从一开始,就想彻底颠覆这个模式。
Gemini图像产品负责人Nicole Brichtova在访谈中开宗明义:“我们正在为Gemini发布一次巨大的质量飞跃……我们追求的是一种能与模型来回对话的体验。”
意思是:你可以用连续指令,围绕同一张图不断细调,而不是每次都从头再来。
这个效果来源自Nano Banana的架构创新。
GPT-4o的图像生成,本质上是一个“胶水模型”:由GPT-4o先需求翻译成一段prompt,再交给DALL-E 3这个专业的扩散模型(Diffusion Model)去作画。这是一个串联的、两步走的工作流。
而Nano Banana是真正的原生多模态架构,是谷歌把原生图像生成与编辑塞进了 Gemini 2.5 Flash 的同一套多模态上下文里。
这意味着统一的Token空间,文本和图像都视为一种可以在同一个Transformer架构内流转的通用数据(Token);
更进一步,模型可以处理一个由[文本, 图像, 文本, 图像...] 组成的、交错的上下文序列,并基于这个完整的上下文生成新图像。
用大白话讲:
就是在同一轮对话里,模型既能理解文本、看懂图,又能连续生成和编辑,而且所有动作都在统一的上下文里发生——这就是他们口中的 Interleaved Generation(交错生成)。
有了它,模型在多轮里会“记得你刚才干了什么”,在这个基础上再做“先换衣服、再改姿势、最后挪到新场景”这种链式操作,稳定多了。
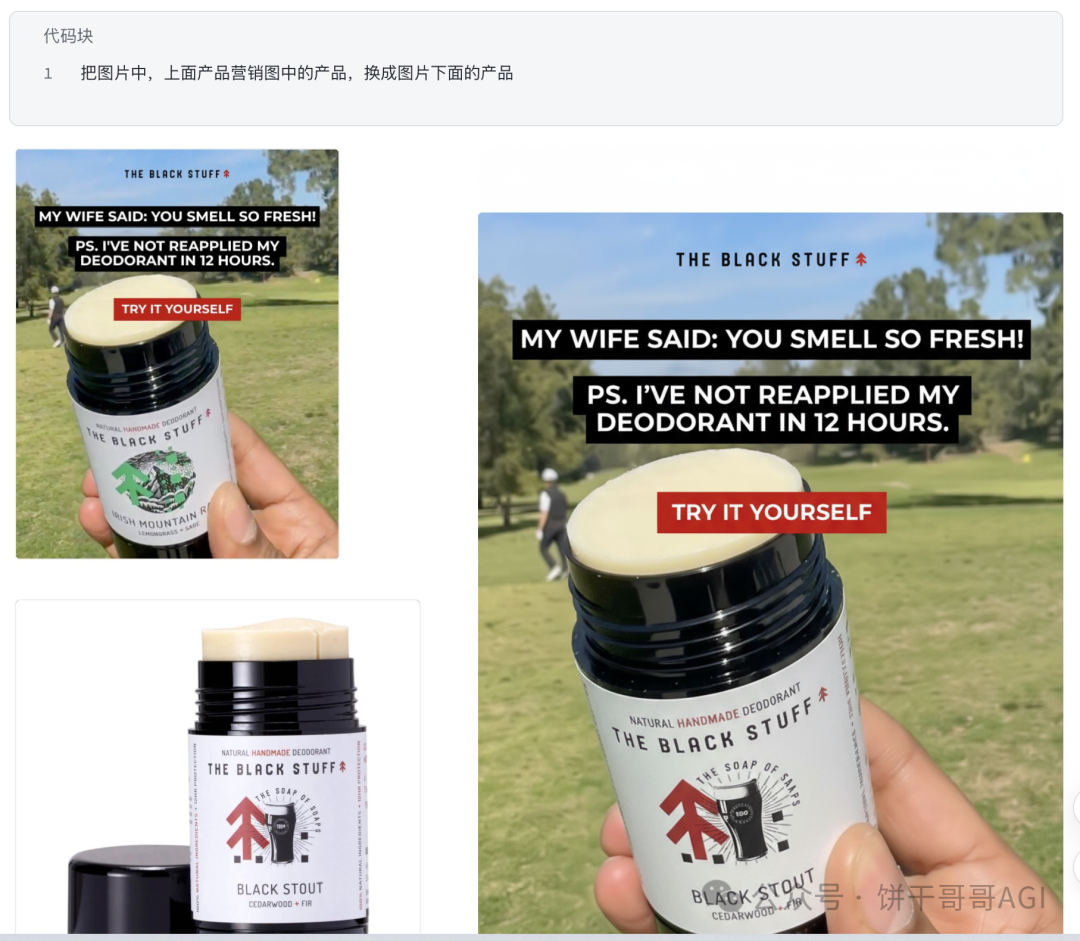
案例,把下图左边人物,改成打坐姿态。


模型在生成过程中拥有上下文信息,它知道前面已经生成了什么内容。生成第二张图时,它“看”到了第一张;生成第三张时,它“记得”前两张。
这使得“像素级的精确编辑” 成为可能,你可以像操作数据库一样,对画面进行增、删、改,而不用担心全盘重来。
图像生成模型的评价其实不在于「美不美」
一个模型如何才能变得更好?在追求“美感”这种主观判断之外,Gemini团队找到了一个意想不到的突破口。
Kaushik长期以来“痴迷”于一个看似边缘的问题:让AI准确地在图像中渲染文字。
“当模型学会处理文字这种结构时,它实际上也在学习如何处理图像中的其他结构。文字渲染因此成为了一个完美的‘代理指标’(Proxy metric)——一个能够反映模型整体性能的关键指标。”
这个洞察极其深刻。
文字是一种高度结构化的视觉信息,要求模型在像素层面有极其精准的控制力。一个模型如果能写好字,说明它对图像的结构、空间、高频细节的理解达到了新的高度。
更重要的是,这个指标是客观的。文字要么对,要么错。
这给了团队一个清晰的优化方向,避免了在“美不美”的主观感受中迷航。
事实证明,随着模型在文字渲染上的进步,其整体图像质量、对细节的把控力也在稳步提升。
“快”比“完美”更重要
大家在用Nano Banana的时候,有没感受到它比GPT-4o要更快?
这不止是服务器资源的问题,更多是模型的「反直觉」设定:在追求极致效果的同时,还要快速生图。


Robert强调:“模型的速度真的很快……即使它一开始没做好,你只需要稍微改一下提示词,再运行一次,很快就能得到一个更满意的结果。这种‘快速迭代式创作’的过程,其实才是它真正的魔力所在。”
说它反直觉,是因为,传统模型会为了追求“一次成功”而花大量时间编写完美的提示词,然后漫长等待一个结果。
但Nano Banana的设计哲学在于 “快速试错”:快速尝试,快速失败,快速调整。
因为创作本就是探索,而不是机械执行。
这个理念就是跟前面提到的“交错式生成”如出一辙——有点像是语言模型中的“思维链”(Chain of Thought)—— 把一个包含50个细节的复杂需求,分解成10个步骤,通过与模型的“对话”逐步完成,让模型有“时间”和“空间”去完成远超其单次处理能力的复杂任务。
超强多图融合
有网友上传13张图,Nano Banana都能完美把它们融合到一张图里。这是以前从未有过的。

A model is posing and leaning against a pink bmw. She is wearing the following items, the scene is against a light grey background. The green alien is a keychain and it's attached to the pink handbag. The model also has a pink parrot on her shoulder. There is a pug sitting next to her wearing a pink collar and gold headphones.A model is posing and leaning against a pink bmw. She is wearing the following items, the scene is against a light grey background. The green alien is a keychain and it's attached to the pink handbag. The model also has a pink parrot on her shoulder. There is a pug sitting next to her wearing a pink collar and gold headphones.
这个能力,表面上看是“能吃多张参考图”,本质上是在同一上下文里建立了多张图的统一语义表示:每张参考图的身份、材质、光影、朝向,都会变成可被引用的约束,模型在顺序生成时不断回看、对齐、再落到像素。
因为不是“先拼后修”的两段式,而是生成期就做跨图约束,所以不容易出现“贴纸感”和边缘穿帮。
内置「世界模型」
过去很多图像模型都停在“会画美图”,但一旦你让它“做一个 80 年代美国购物中心风格的写真,还给每张起个符合时代美学的标题”,大多会掉线。
Nano Banana 把谷歌的「世界模型」拉进来了:你要求的年代、风格、品牌语汇、生活常识,模型不只是知道“名词”,而是能把这些常识带进画面决策,包括服饰结构、材质选择、拍摄语法、空间布光等。
例如下图的案例,可以上传一张图后,就让Nano Banana做建筑的标注。

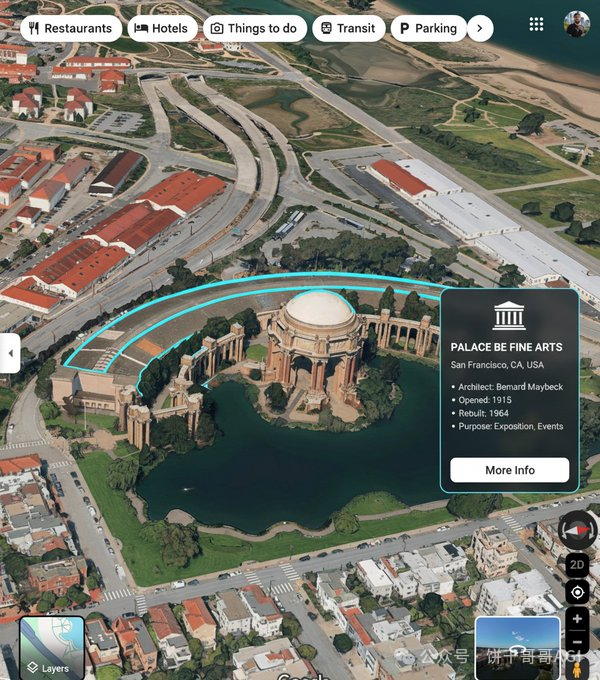
you are a location-based AR experience generator. highlight [point of interest] in this image and annotate relevant information about it.
团队在访谈里讲了一个我很认同的观点:语言只会描述“有意思”的东西,很多日常常识并不被语言充分表达;而图像既是输入信号,也是“把常识具象化”的训练材料。
把这两端打通,模型的“世界感”才会长出来。
落回到使用层面,就是你让它按一个品牌调性“做一版户外广告 mockup”,它不仅能学会那种风格,还会把风格和你给的实拍场景合理地对齐。
与ChatGPT-4o的对比
现在,回过头来,重新看,就能理解为什么Nano Banana能超越GPT-4o,再次掀起热潮了。

文章来自于微信公众号“饼干哥哥AGI”,作者是“饼干哥哥”。
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


