最近,工业界“RAG已死”甚嚣尘上。过去几年,AI领域的主旋律是“规模定律”(Scaling Law),即更大的模型、更多的数据会带来更好的性能。即便偶然有瑕疵,也认为只是工程上的不足,并非数学上的不可能。但最近,一篇来自谷歌DeepMind的理论奠基型论文从根本上动摇了这个基本假设,首次数学证明了对于当前主流“单向量嵌入”检索模型,召回能力有限。研究者们指出:性能的瓶颈并非来自训练,而是来自将复杂的相关性信息压缩到单个低维向量中的这种模式本身,这是一篇能决定AI领域未来研究方向的拐点论文,其深刻洞察或将重塑我们对信息检索乃至AI能力边界的认知。

向量空间真的能“装下”所有关系吗?
咱们每天都在用的向量嵌入(Embedding),本质上是把复杂的文本信息压缩到一个固定长度的向量里,比如1024维。这套方法在处理“语义相似”的任务时真的太猛了,但现在的用户需求可不止于此。他们会问“给我找找关于A或者B的资料”,甚至提出更复杂的指令,这要求模型动态地将原本毫无关联的文档组合成一个新的“相关”集合。
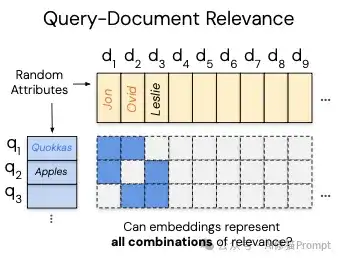
这就引出了一个很要命的问题:一个固定维度的向量空间,它就像一个容量有限的“收纳盒”,真的能装下宇宙中所有可能存在的“文档组合”关系吗?如果用户的查询恰好需要一种这个“收纳盒”装不下的组合方式,那模型再聪明,是不是也无能为力了?这正是这篇论文要探讨的核心,一个我们可能都忽略了的角落。
换句话说这个“数学BUG”的核心在于,一个固定维度 d 的向量空间,其能够有效区分和表示的不同“组合”是有限的。
理论核心:“维度”不够用
为了搞清楚这个问题,研究者们将检索问题形式化,并引入了来自通信复杂度理论的一个关键概念符号秩 (Sign Rank) 这个词您可能有点陌生,但可以把它想象成衡量一个“关系网络”有多复杂的指标。
- 什么是检索问题? 想象一个巨大的表格(矩阵),行是所有可能的查询 (queries),列是所有的文档 (documents)。如果文档 j 与查询 i 相关,我们就在 (i, j) 位置标记为1,否则为0。这个表格就是查询相关性矩阵 (qrel matrix)。
- 嵌入模型做什么? 嵌入模型的目标是学习一个查询向量 u 和一个文档向量 v,使得相关文档的得分(如点积 u·v)高于不相关文档。
- 理论瓶颈在哪里? 论文证明,要让模型完美地处理这个表格中所有的查询(即对每一行,相关文档的得分都高于不相关文档),模型的嵌入维度 d 必须大于或等于这个表格矩阵的“符号秩”。
- “数学BUG”:对于复杂的任务,这个相关性矩阵的符号秩可以变得任意高。但我们使用的模型嵌入维度却是固定的(例如1024, 4096)。这意味着 对于任何固定维度的模型,我们总能构造出一个它在数学上根本无法解决的检索任务(因为任务的符号秩要求比模型的维度更高)。无论如何训练,它都无法学会检索出所有可能需要的文档组合。
- 一个检索任务所需要的最小嵌入维度,是由这个任务背后“查询-文档相关性”网络的复杂度(也就是符号秩)决定。
这个结论就像物理定律一样,不以人的意志为转移。这跟您的模型训练得多好、用了多少数据都没关系,纯粹是维度这个“收纳盒”的格子数量,从根本上就不够用了。
实验一:最好情况实验
为了验证这个理论是不是纸上谈兵,研究者们首先创造了一个“最好情况”的实验环境。如果在一个没有任何约束、可以直接在测试集上优化向量的“最好情况”下,模型都无法解决问题,那么真实世界的模型(受到自然语言的束缚)就更不可能解决了。研究者将这种不受文本束缚、可自由优化的向量称为“自由嵌入” (free embeddings)。
实验设置
- 向量创建:研究人员不使用任何语言模型,而是直接创建随机的文档向量和查询向量。
- 优化过程:他们设定一个检索任务(例如,从 n 个文档中找出所有可能的2个文档的组合,即 k=2)。然后,他们使用Adam优化器和InfoNCE损失函数,直接在“测试集”(即所有这些预设的组合)上对这些随机向量进行迭代优化,目标是让每个查询都能100%准确地检索到其对应的2个相关文档。
- 寻找“临界点” (Critical-n):对于一个固定的嵌入维度 d(例如 d=10),他们从一个较小的文档数 n 开始实验。如果优化成功(准确率100%),他们就将 n 加一,然后重复实验。他们持续增加 n,直到找到一个点,使得模型再也无法通过优化达到100%的准确率。这个点被称为“临界n” (critical-n),代表了该维度 d 所能完美处理的文档数量上限。
不同嵌入维度的临界文档数量:
- 512维:约50万文档
- 768维:约170万文档
- 1024维:约400万文档
- 4096维:约2.5亿文档
结果
研究者发现,对于任意一个固定的维度 d,当文档数量 n 增加到一个“临界点”时,模型就再也无法100%解决所有查询组合的检索任务了
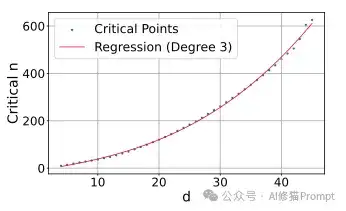
这个临界点与维度 d 的关系可以用一个三次方多项式来拟合。根据这个公式推算,即便是对于一个拥有4096维的巨大模型,在最理想的优化条件下,它能完美处理的文档数量上限也只有约2.5亿。这个数字对于真实世界动辄万亿的网页搜索等海量数据来说是远远不够的,更何况真实模型的性能远不如这种理想状态。
实验二:LIMIT数据集登场
理论和理想实验都告诉我们有极限存在,那在真实世界里呢?研究者们接着干了一件更绝的事,他们创造了一个叫 LIMIT 的数据集。这个数据集的查询和文档内容简单到令人发指,他们选择了一种最简单的映射方式,比如查询是“谁喜欢苹果?”,文档是“小明喜欢苹果,小红喜欢香蕉……”。

玄机藏在背后 LIMIT 数据集的构建
研究者们精心设计了文档之间的相关性,让它们构成了一个极其复杂、高度纠缠的关系网络(也就是前面说的,高“符号秩”)。这就像一道看似简单的智力题,题目本身人畜无害,但解题路径却异常刁钻,专门为了考验模型的表示能力极限。
- 核心设计 - 稠密组合:为了最大限度地测试组合能力,研究者选择了一种能产生最多连接的模式。设定了总共有1000个查询,每个查询对应2个相关文档 (k=2)。他们计算出需要46个文档才能产生超过1000种不同的两两组合(C(46, 2) = 1035)。这46个文档构成了“稠密”的核心相关集。
- 增加干扰项:为了模拟真实场景,他们将这46个核心文档放入一个包含5万个总文档的语料库中,其余的文档都是不相关的干扰项。他们还创建了一个仅包含这46个文档的“小”版本,用于进一步分析。
参评模型
全部来自SOTA:他们评估了业界所有主流的SOTA嵌入模型,如GritLM, Qwen3 Embeddings, Promptriever, Gemini Embeddings等。此外他们还加入了非单向量模型作为对比,如稀疏检索的BM25和多向量模型的GTE-ModernColBERT
评估指标:使用标准的召回率(Recall@k)进行评估。
实验结果
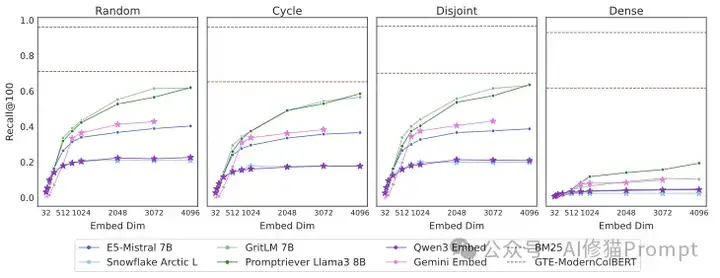
- SOTA模型惨败:在完整的LIMIT数据集(5万文档)上,所有SOTA单向量模型的表现都极其糟糕,召回率低得可怜。Recall@100(即前100个结果中能找回相关文档的比例)难以超过20%。这说明模型并不是看不懂“谁喜欢苹果”这句话,而是它们的向量空间,真的“装不下”LIMIT数据集背后那种复杂的关系组合。
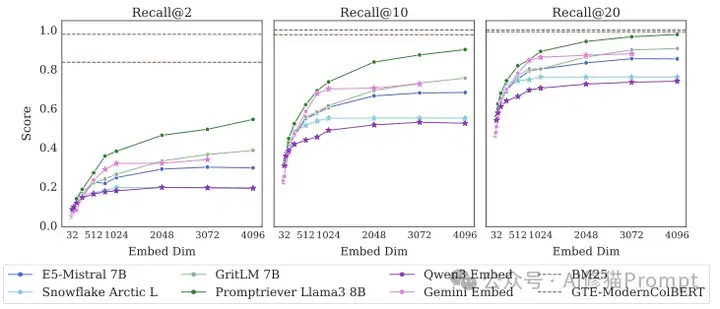
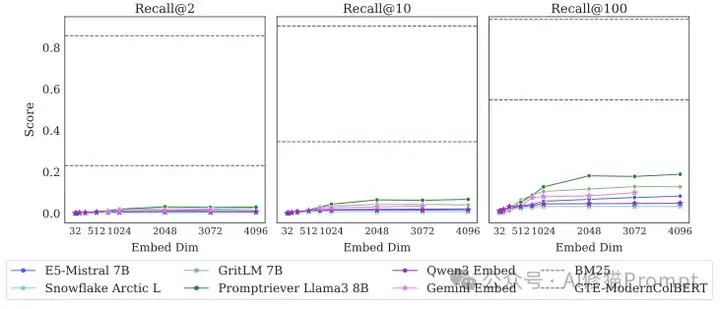
即便语料库缩小到只有46个文档,没有任何干扰,SOTA模型仍然无法完美解决这个任务,比如最好的模型在Recall@20(前20个结果中找回相关文档)时都无法达到100%
- 小版本同样困难:即使在只有46个文档的“小”版本中,这些顶尖模型也无法完美解决问题,最好的模型在Recall@2(即前2个结果中找回2个相关文档)的成功率也不到60%。
- 替代方案表现更优:与之形成鲜明对比的是,传统的BM25模型和多向量模型GTE-ModernColBERT的表现远超所有单向量模型。这证明问题的根源确实在于“单向量嵌入”这一架构本身。
更有意思的是,研究者们发现:
- 这不是领域问题:把模型放在 LIMIT 的训练集上微调,效果提升微乎其微,证明模型不是“水土不服”。
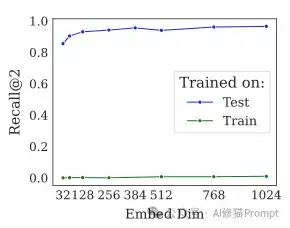
- 维度确实是命门:模型的表现和嵌入维度大小呈现出非常强的正相关,再次印证了理论的预测。
这在LIMIT数据集出现之前,大家认为“难”的检索任务是需要复杂推理或多跳问答的任务。而这项研究创造了一个表面上“极其简单”(例如,“谁喜欢苹果?”)但对现有SOTA模型来说却“极其困难”的任务。这迫使研究者重新思考,到底是什么让检索任务变得困难?并非只有语义复杂性,组合的多样性也是一个致命的挑战。
那还有救吗?
看到这里大部分朋友可能会有点沮丧,难道单向量嵌入这条路走到头了?别急,研究者们也探讨了其他可能性。有趣的是,一些“老派”或“非主流”的技术路线,在这个问题上反而表现出了优势。
- 稀疏模型(如BM25):这位老将为什么表现出色?您可以把它理解成一个维度超级高的向量模型(维度就是整个词汇表的大小)。维度高了,“收纳盒”的格子自然就多了,处理复杂组合的能力也就上去了。
- 多向量模型(如ColBERT):这种模型不把一篇文档压缩成一个向量,而是保留多个向量。这就好比给一份文件贴上好几张不同主题的标签,而不是只贴一张总标签,表达能力自然更强,也更灵活。
- 重排器(Rerankers):像Gemini-2.5-Pro,在重排任务上可以轻松解决LIMIT问题。但这是谷歌自家的研究,所以...
对RAG的启示
RAG的工作流程是“检索(Retrieval)”+“增强生成(Augmented Generation)”。如果第一步“检索”就存在一个无法逾越的理论天花板,那么整个系统的准确性就无从谈起。RAG已死,似乎也不无道理。
关于RAG的文章我之前也写过很多,感兴趣您可以看下

1.6万字Rankify完全指南:三行代码搞定RAG,24种重排序方法任你选 | 全网最详细。

讨厌RAG生成幻觉?试一下SAT重构文本分块,按语义而不是Token
写在最后
这也许是一个信号,提醒我们是时候更多地关注混合检索(比如稠密+稀疏)或者多向量这样的架构了。它们可能才是通往更强大、更通用AI检索系统的下一站。您设计RAG或者其他检索系统时,特别是当业务场景需要处理复杂的用户指令和逻辑组合时,需要意识到单向量嵌入可能存在的短板。“大力出奇迹”的时代或许并未结束,但在这条特定的道路上,单纯增加模型参数和数据,可能真的无法突破这个理论“天花板”。理解并承认“极限”的存在,不是悲观,恰恰是智慧的开始。这篇由Google发表的重磅研究,不会让RAG系统就此停滞,反而会因为它,我们才得以构建出真正理解世界复杂性的、更鲁棒、更值得信赖的AI系统。这不仅是一个技术路线的拐点,更是我们认知AI能力边界的一次重要跃迁。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

