在端侧 AI 这个热门赛道,华为盘古大模型扔下了一颗 “重磅炸弹” 。
如今,云端大模型已经能侃侃而谈、答疑解惑。但如果这些 AI 大脑能被装进手机、摄像头甚至无人机,会带来怎样的变化?边缘设备上部署强大的 AI 模型已成为产业智能升级的关键路径。
然而,端侧设备在算力、内存和功耗方面的严格限制,与传统超大模型的巨大计算需求形成了显著矛盾。现有方案往往陷入两难:要么采用性能羸弱的小模型,无法处理复杂任务;要么试图将云端大模型压缩后硬塞进端侧,结果精度严重下降或响应缓慢,难以满足实际应用需求。
为了破解这一痛点,华为近日发布了专为昇腾端侧硬件打造的高性能语言模型 ——openPangu Embedded-1B。该模型虽然只有 10 亿参数,却通过软硬件协同设计显著降低推理延迟、提升资源利用率,并采用多阶段训练策略(包括从零预训练、课程学习式微调、离线 On-Policy 蒸馏、多源奖励强化学习)大幅增强各类任务表现。
得益于多阶段训练与优化,openPangu Embedded-1B 在十亿参数的体量下实现了性能与效率的高度协同,成功将强大的大模型能力带到了端侧设备上,树立了「小模型大能力」的新标杆。
评测成绩说明了一切,openPangu Embedded-1B 在多个权威基准上表现亮眼,创下了 10 亿参数级别模型的全新 SOTA 纪录。
模型的整体平均分达到 63.90,不仅全面领先同类模型,甚至持平更大规模的 Qwen3-1.7B(63.69),充分体现了出色的参数效率。这表明,先进的训练与对齐方法可以比单纯扩大模型规模更具成效。
在数学推理方面,openPangu Embedded-1B 经过强化学习对齐后取得了高分,其中在 GSM8K 数学基准上达到 82.76%,在 MATH 数学题集上达到 81.83%,均大幅领先同类模型。
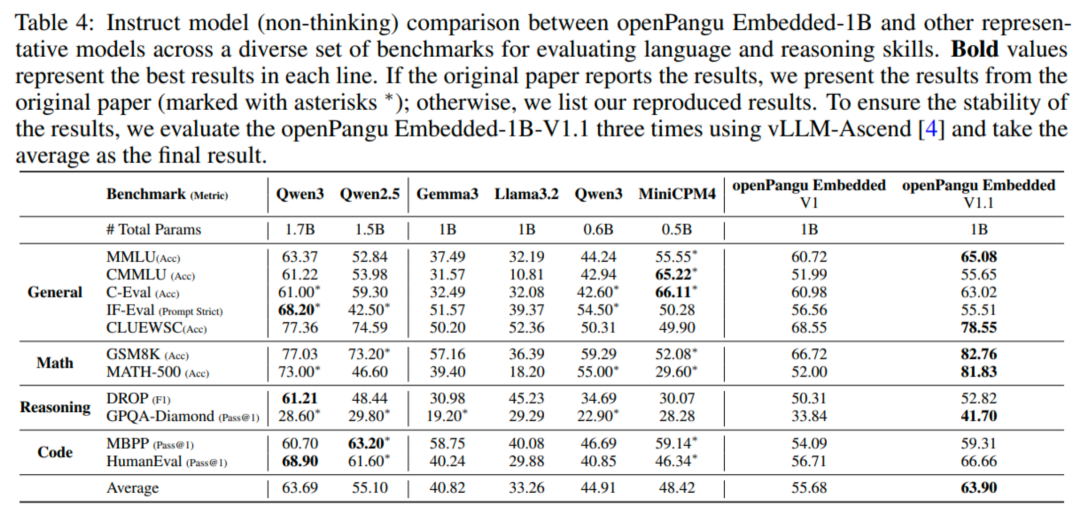
图:openPangu Embedded-1B 与其他模型在各项任务上的 0-shot 表现对比。可以看到,该模型在语言理解、数学、推理和编程等任务上均展现出明显优势,并显著缩小了与更大模型之间的差距。
尤其值得关注的是,相比上个月开源的 openPangu Embedded-1B V1,V1.1 的平均分实现了 8% 以上的大幅跃升,这意味着开源盘古系列正在加速迭代升级。openPangu Embedded-1B 为资源受限的边缘设备带来了前所未有的智能水平,开辟了大模型端侧应用的新可能。
- 开源模型地址:https://gitcode.com/ascend-tribe/openPangu-Embedded-1B-v1.1
- 技术报告:https://gitcode.com/ascend-tribe/openPangu-Embedded-1B-v1.1/blob/main/docs/openPangu-Embedded-1B-report.pdf
接下来,我们就一起揭晓这款模型背后的技术 “秘密”。
软硬件协同设计:
让 10 亿参数模型在端侧高效奔跑
openPangu Embedded-1B 是一款拥有 10 亿参数的自回归 Transformer 模型,专为昇腾 AI 处理器的端侧硬件平台优化设计。
团队通过精心的软硬件协同,将模型架构与芯片特性深度结合:针对目标硬件的计算和内存特点,定制了合适的网络宽度和深度等超参数。换言之,模型的隐藏层规模、前馈网络维度等都与昇腾 Atlas 硬件的高效吞吐配置相匹配,确保每个计算单元都得到充分利用。
在资源受限的设备上,这种 “软硬件协同” 的架构设计在模型深度和推理效率间找到了理想平衡点。
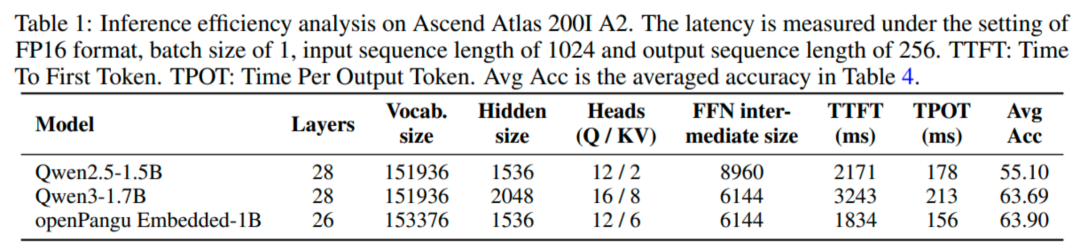
图:在昇腾 Atlas 200I A2 硬件上,openPangu Embedded-1B 的推理延迟低于同级别的大模型。上表对比了不同 1B 量级模型的首 token 生成延迟(TTFT)和每 token 生成延迟(TPOT)。
为了验证软硬件协同设计的效果,团队将 openPangu Embedded-1B 与其他相近规模模型进行了推理延迟基准测试。结果显示,在 Atlas 200I A2 硬件上,openPangu Embedded-1B 首字输出延迟仅约 1.8 秒,后续每词生成约 0.156 秒,而且 openPangu 精度相当。
这一显著的速度优势充分证明了软硬件协同优化在端侧部署中的价值。
两阶段课程学习:
具备理性的快速响应
为了让小模型也具备 “理性思维”,openPangu Embedded-1B 在微调阶段采用了课程学习式的 “两段式” 训练,模拟人类专家先深思后速答的学习路径。
团队精心设计了难度递进的双阶段训练课程,循序渐进地塑造模型的推理能力:
1.构建坚实的 “推理地基”:第一阶段,模型不追求响应速度,只专注于理性推理能力。它学习了海量包含详细推理过程的复杂问题解答示例,就像学生跟随导师一步步学习解题思路,理解背后的原理逻辑,打下扎实的逻辑推理基础。
2.激发内化的 “快速直觉”:第二阶段,在模型具备强大的推理 “内核” 后,训练策略切换为提供大量简短的问答对,省略中间推理步骤。这好比学生掌握原理后开始练习快速作答,学会将深层思考内化于心,外化于行,以尽可能直接、迅速地得出答案。
经过这两个阶段循序渐进的微调,模型深层次的推理能力被成功激活,openPangu Embedded-1B 在通用任务上的表现也全面提升。
离线 On-Policy 知识蒸馏:
师生协作的新范式
openPangu Embedded-1B 还进一步引入了一种 “学生主导,教师点拨” 的离线 On-Policy 知识蒸馏方法。不同于传统由教师单向灌输知识,这种方法更像智能辅导:先让 “小学生” 模型自主作答,再由 “大老师” 模型针对学生答案进行有的放矢的指导。
蒸馏过程包括以下两个核心步骤:
1.学生主导的自主探索:学生模型(1B)首先对训练问题自行生成答案,教师暂不介入,就像导师辅导前先让学生独立尝试解题,以了解其思路。
2.教师约束下的精准点拨:随后更大的教师模型登场,但它并非直接给出正确答案,而是基于学生输出进行预测,在学生能力范围内提供针对性的提示,极大缩小了师生认知差距。
通过这种离线 On-Policy 蒸馏,教师指导数据的生成与学生模型的训练实现了解耦,流程高度灵活;同时方法实现上改动极少(仅需增加一个蒸馏损失项),却令学生模型的准确率和泛化能力大幅提升。
多源奖励强化学习:
用反馈强化模型智慧
在大规模 RL 训练阶段,团队开发了针对昇腾 NPU 集群的高效并行方案:通过容错同步调度和优先级数据队列最大限度利用上千加速卡资源,减少约 30% 的设备空闲;设计主机 - 设备权重共享和 NPU 端推理优化,使大规模强化学习在昇腾硬件上能够高效稳定运行。
同时在算法上,团队对训练样本进行了难度筛选,过滤过易或过难的数据,引入 “零优势” 掩码忽略无效惩罚项,进一步保障了训练过程的稳定高效。
为了指导模型自我提升,openPangu Embedded-1B 采用了多源奖励机制:针对数学、代码等可自动验证的任务使用基于规则的奖励,针对复杂开放任务则采用轻量级 LLM 模型来评估答案质量。
奖励策略兼顾回答的正确性和格式规范,例如回答格式错误会受到严厉惩罚,答案错误但格式正确则扣减较小分值,而只有答案完全正确才能获得正奖励。这套精心设计的奖励信号确保模型在强化学习阶段获得全面而准确的反馈,不断优化自身能力。
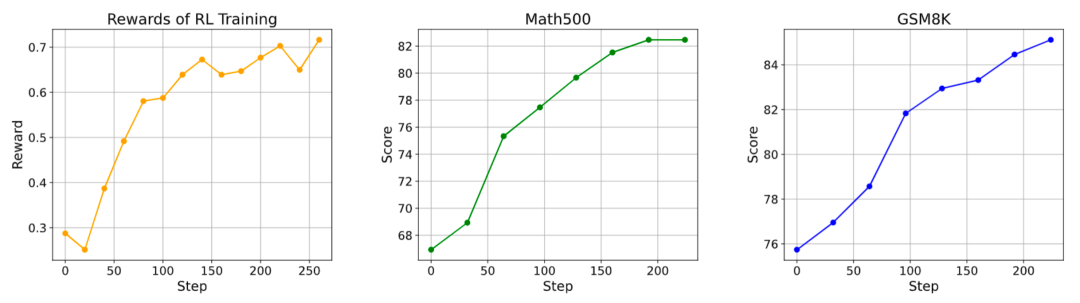
图:强化学习训练中,openPangu Embedded-1B 的平均奖励值和数学能力随训练迭代稳步提升。通过强化学习微调,模型的数学推理能力实现了飞跃式增强,而其他领域的性能也保持了稳定。
展望:快慢思考融合的未来
在极致挖掘小模型端侧潜能的同时,openPangu 研发团队也在探索让大模型的 “快思考” 和 “慢思考” 融为一体的新方向。目前,快慢思考模型往往面临两难:快速思考模式在复杂任务上力不从心,而慢思考模式应对简单问题又效率低下,难以兼顾速度与精度。
对此,团队提出了一种自适应的快慢融合方案:在单一模型中同时提供快思考、慢思考和自动切换三种模式。模型可根据问题难度自动选择:简单问题快速作答,复杂问题深入推理后再作答,在保持接近慢思考模型精度的同时,大幅提高了易答问题的推理效率。
据悉,openPangu-Embedded-7B 模型已应用自适应快慢融合策略,并在 7B 量级模型中取得了领先水平,其升级版本也将很快开源。
可以预见,随着快思考 / 慢思考自适应融合等技术的引入,更大规模的端侧模型将同时实现高推理质量和高响应速度,为行业应用带来 “双优” 的 AI 能力。未来,随着端侧 AI 加速向实用化与普惠化迈进,算力受限设备也能享受云端级别的智能体验。
文章来自于微信公众号“机器之心”。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

