谷歌云刚发布了一篇《Google Cloud Startup technical guide: Al agents》(Google Cloud 创业公司技术指南:AI 代理)这是一份非常详尽和全面的手册,这篇文档要解决的问题:原型到生产之间最大鸿沟,Agent的非确定性、复杂推理轨迹如何验证、如何部署与运维等。初创公司业务负责人或开发者看完后能获得一个系统性的、从概念到实践的AI代理(Al agents)开发与运营路线图。

该指南分为三个核心部分:
- 第一部分:核心概念 (Core concepts of Al agents) - 为初学者建立AI代理的基础知识体系。
- 第二部分:如何构建 (How to build Al agents) - 为准备动手的开发者提供具体的工具和步骤。
- 第三部分:确保可靠与负责任 (Ensuring Al agents are reliable and responsible) - 聚焦于将代理投入生产环境后,如何保证其安全性、稳定性和可扩展性。
让我们立刻开始!
第一部分:AI Agent的核心概念
这一部分是整个指南的基础,主要帮助初学者建立对AI Agent是什么、由什么组成以及它们如何工作的坚实知识框架。
1. Google Cloud的AI代理生态系统:三种参与方式
指南首先描绘了Google Cloud提供的宏大蓝图,指出你可以通过三种主要方式来利用AI Agent,无论你的技术水平或业务需求如何。这个生态系统的设计核心是互操作性,确保无论代理来自哪里,都能协同工作。
- 构建自己的代理 (Build your own agents) 这适用于需要高度定制化和控制权的团队。Google为此提供了两条路径:
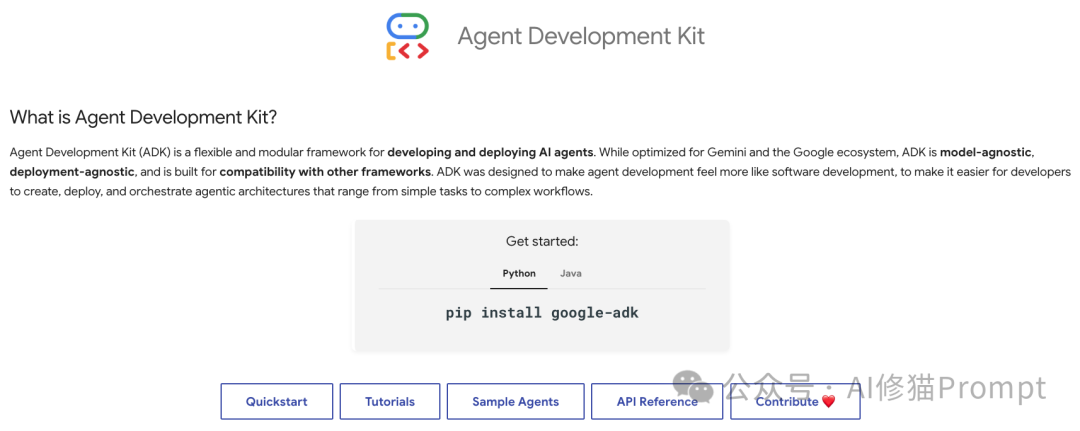
- 代码优先 (Code-first) - 使用Agent Development Kit (ADK):这是一个为开发者设计的强大、开源的工具包。它让你能够精细控制代理的行为,连接你自己的数据和API,从而构建具有竞争壁垒的独特产品。用ADK构建的代理可以打包成容器,部署到任何地方,如Vertex AI Agent Engine、Cloud Run或GKE。
- 应用优先 (Application-first) - 使用Google Agentspace:这是一个无代码平台,旨在让非技术团队(如产品、市场人员)也能通过简单的提示语来构建和管理代理 。它可以连接公司内部的各种SaaS应用(如Jira, Slack),打破数据孤岛,实现跨平台的工作流自动化。
- 使用Google Cloud的预构建代理 (Use Google Cloud agents) 这是一系列由Google开发和管理的即用型AI助手,可以快速集成到现有工作中,非常适合工程资源有限的初创公司,主要包括:
- Gemini Code Assist:开发者的AI助手,能集成在IDE中,提供代码补全、代码生成甚至自动审查代码等功能。
- Gemini Cloud Assist:Google Cloud环境的AI专家,能用自然语言帮助用户设计架构、排查故障和优化成本。
- Gemini in Colab Enterprise:专为数据科学家设计,能加速数据准备、分析和模型迭代的过程。
- 引入合作伙伴的代理 (Bring in partner agents) Google Cloud是一个开放的生态系统,可以通过其Marketplace轻松集成来自第三方或开源社区的专业代理。
2. 每个AI代理的五大关键组件
无论Agent多么复杂,它们都由五个核心部分构成:
- 模型 (Models) - 代理的大脑
- 如何选择:选择模型不是越强大越好,而是在能力、速度和成本之间找到最佳平衡点。一个常见的错误是为一个简单的任务选择了过于强大的模型,导致成本高、响应慢。
- 策略:最佳策略是为一个系统中的不同子任务动态选择最高效的模型。例如,文档作者们推荐用谷歌自家的Gemini 2.5 Pro处理复杂推理,用Gemini 2.5 Flash-Lite处理高并发的简单分类任务。
- 工具 (Tools) - 代理的手脚 工具赋予代理超越其模型原生能力、与外部世界交互的能力,它们可以是你自己的代码函数、内部或第三方的API、数据库或其他数据源,在复杂系统中,一个代理甚至可以把另一个专门的代理当作工具来使用。
- 数据架构 (Data architecture) - 代理的记忆 一个强大的代理需要一个分层的记忆系统来存储不同类型的信息。
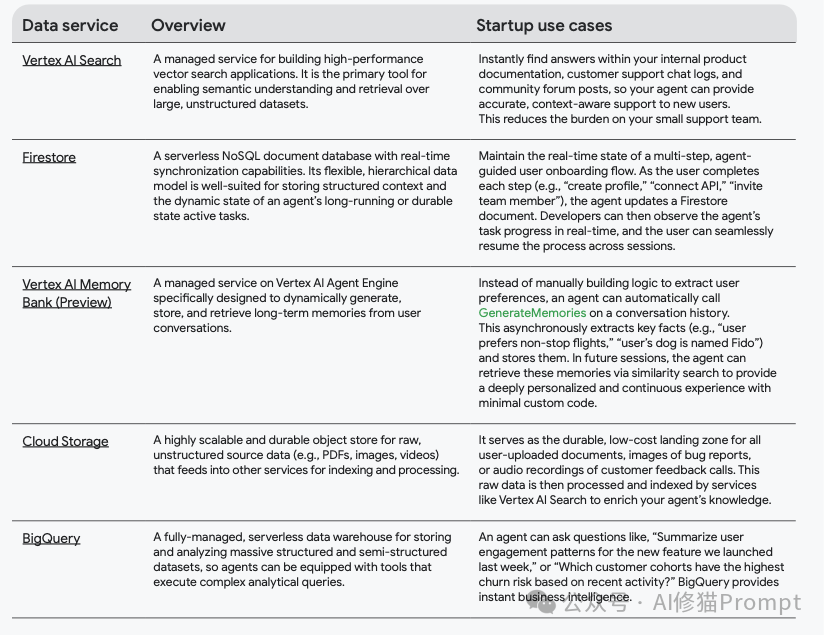
- 长期知识库 (Long-term knowledge):这是代理的永久记忆,用于事实“接地”和个性化。通常使用Vertex AI Search(向量搜索)、Firestore(存储用户历史)和BigQuery(分析)等服务。
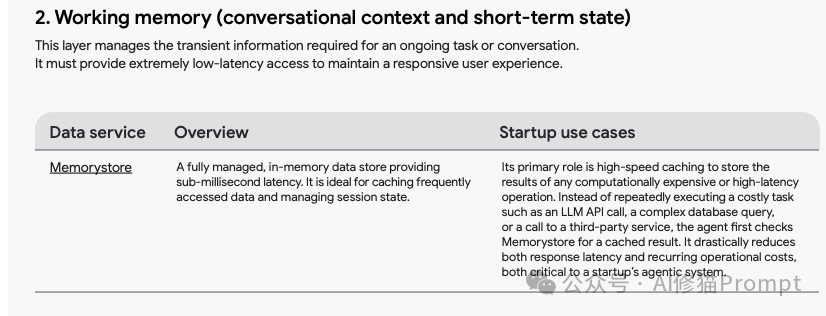
工作记忆 (Working memory):管理当前对话或任务所需的短期、临时信息,要求极低的延迟。Memorystore(内存缓存)是理想选择。
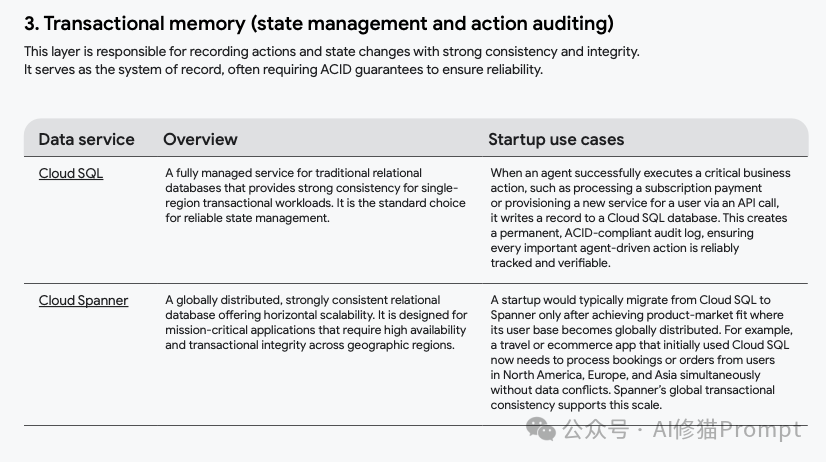
事务性记忆 (Transactional memory):像一个可靠的账本,记录关键操作(如支付、下单),确保数据的一致性和完整性。通常使用Cloud SQL或Cloud Spanner。
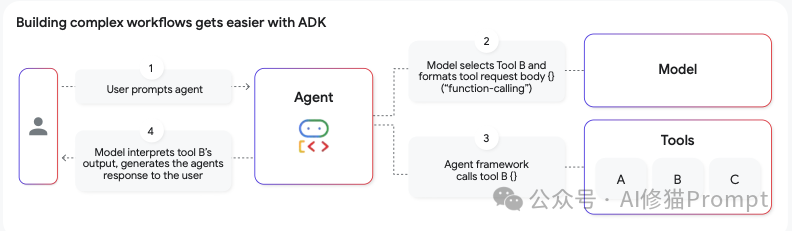
编排 (Orchestration) - 代理的执行功能 编排是指导代理完成多步骤任务的核心逻辑。最常见和有效的模式是ReAct (Reason + Action)。代理遵循一个循环:
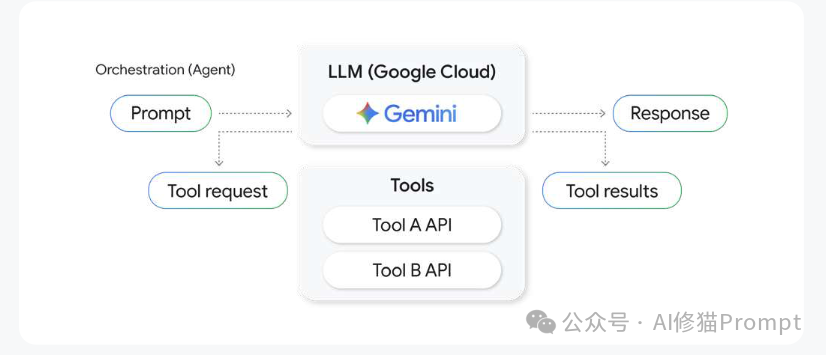
- 思考 (Reason):评估目标,形成下一步该做什么的假设。
- 行动 (Act):选择并调用最合适的工具。
- 观察 (Observe):接收工具返回的结果,并将新信息融入上下文,为下一步的“思考”提供依据。
- 运行时 (Runtime) - 代理的家 这是将代理原型部署到生产环境并确保其能够大规模、可靠运行的基础设施。一个好的运行时环境必须提供可扩展性、安全性和可观察性。Google Cloud提供了Vertex AI Agent Engine、Cloud Run和GKE等多种选择。

3. “接地” (Grounding) 的核心作用:建立信任
“接地”是确保代理的回答基于可验证的事实,而不是凭空捏造(即“幻觉”)的关键过程。它是建立用户信任的基础。指南介绍了其技术演进的三个阶段:
RAG (Retrieval-Augmented Generation):这是基础。在生成答案前,代理首先从外部知识库(通常是向量数据库)中检索相关信息,并将这些信息作为上下文提供给LLM,从而确保答案有据可查。
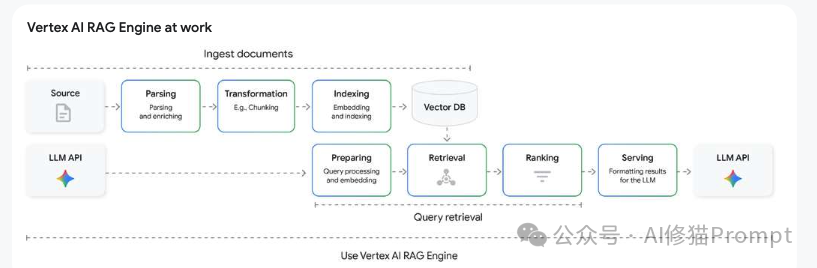
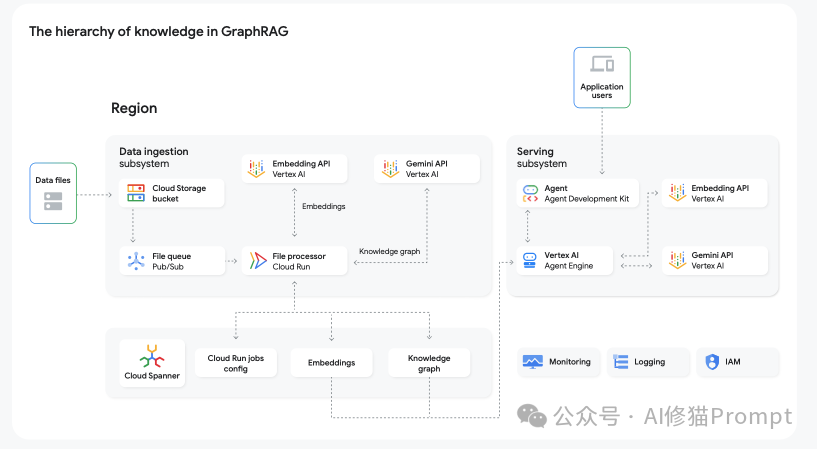
GraphRAG:这是进阶。它不仅仅是检索文本片段,而是通过构建知识图谱,让代理能够理解概念之间的关系(例如,“症状 -> 原因 -> 治疗方法”)。
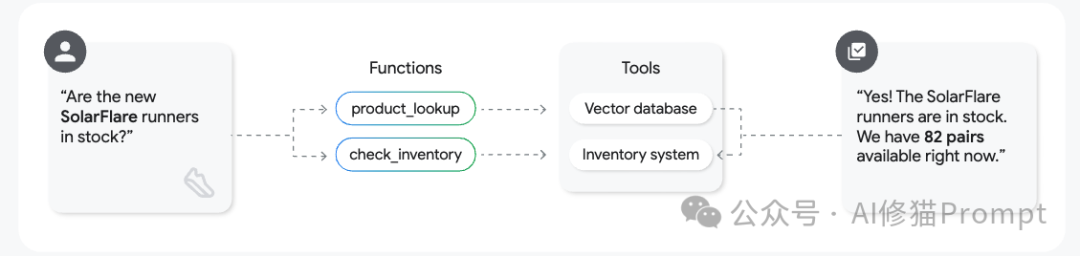
Agentic RAG:这是最前沿的方法。在这种模式下,代理不再是被动地接收检索到的信息,而是成为一个主动的推理者。它可以分析一个复杂问题,制定一个多步骤的检索计划,并依次调用多个工具来寻找最佳答案,就像一个真正的研究助理。
第一部分为您构建了一个关于现代AI代理的完整心智模型。它不仅解释了构成代理的各个部分,还阐明了它们是如何在Google Cloud的生态系统中协同工作的,为后续的构建和运营打下了坚实的理论基础。修猫在上周介绍了一篇Agent设计系统化手册,作者同样来自谷歌,是他们的前CTO办公室的资深工程负责人,这篇文章写的更详细并附带20张流程图,感兴趣您可以看下

谷歌前CTO办公室总监近500页巨著,Agent的21个设计模式,从小白走向大师
第二部分:如何构建AI Agent
在理解了第一部分的核心概念之后,这一部分将重点从理论转向实践,提供了以谷歌自己的技术栈Agent Development Kit (ADK) 为主的构建指南。这部分的内容主要帮助开发者做出正确的架构决策,从而构建出生产就绪的代理。
1. 构建AI代理的完整工具包 (A complete toolkit)
Google Cloud提供了一个由四个核心组件构成的工具生态系统,用于构建复杂的AI代理:
组件描述Agent Development Kit (ADK):谷歌自己开源的、代码优先的工具包,用于构建、评估和部署AI代理。
- Model Context Protocol (MCP):一个开放协议,旨在标准化应用程序向LLM提供上下文内容的方式,像一个通用适配器。
- Vertex AI Agent Engine:一个托管平台,用于在生产环境中部署、管理和扩展AI代理。
- Agent2Agent (A2A) protocol“一个开放标准,用于实现AI代理之间的通信和协作。
2. 使用ADK进行开发 (Develop with ADK)
ADK 是一个多功能框架,其核心能力包括:
- 构建复杂、协作的AI系统:ADK的设计初衷就是支持多代理。你可以构建一个主代理,然后将特定任务(如代码生成、设计)委托给多个专门的子代理来完成。
- 集成现有工具和工作流:ADK的生态系统非常开放,可以轻松连接到你已在使用的工具(如Notion、Slack)、流行的开源框架(如LangChain)以及其他代理框架(如CrewAI)。
- 确保质量和可靠性:ADK内置了强大的可观察性 (observability) 和评估工具。这使你能够系统地测试代理在不同场景下的反应,并检查其完整的执行轨迹(包括它的“思考”、工具调用和观察结果),从而有效调试其决策过程。
- 充满信心地扩展AI:ADK通过将代理打包成标准的Web服务(使用FastAPI),使其可以被容器化。这意味着你可以将代理部署到任何地方,从业余爱好者的本地测试环境,到像Vertex AI Agent Engine或Cloud Run这样可以自动扩展的全托管运行时。
3. ADK的核心:代理架构
构建代理的第一步是选择正确的架构。ADK提供了三大类代理,每类都适用于不同的场景
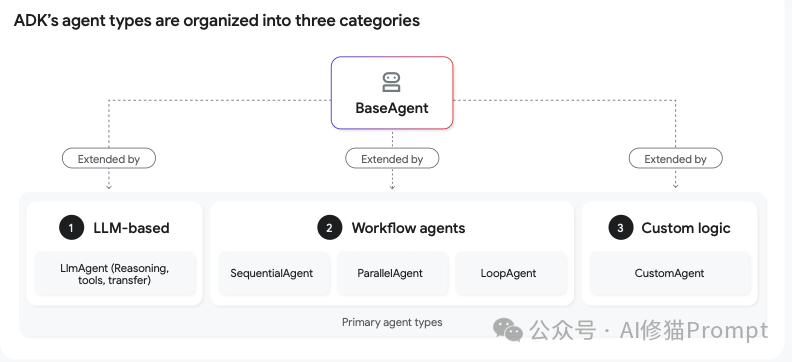
1. LLM代理 (LLM-based - LimAgent)
- 这是最常见的代理类型,其核心引擎是像Gemini这样的大语言模型。它的行为是非确定性的(灵活的),适用于需要复杂推理、动态决策和自然语言理解的任务。
2.工作流代理 (Workflow agents)
- 这类代理的核心是预定义的逻辑,行为是确定性的(可预测的)。它们通常用作“协调者”,以预设的模式控制其他代理的执行流程。
- 顺序代理 (
SequentialAgent):按固定顺序执行一系列子代理,并将前一个的输出作为后一个的输入。例如,先调用“获取网页内容”工具,再调用“总结页面”工具。 - 并行代理 (
ParallelAgent):同时执行多个独立的子代理任务,以优化性能。例如,从多个数据源并行检索信息。 - 循环代理 (
LoopAgent):重复执行一个或多个子代理,直到满足某个退出条件或达到最大迭代次数。例如,不断生成图像,直到图像中的香蕉数量为五个为止。
3.自定义代理 (Custom logic)
- 当你需要超越标准推理循环的独特逻辑时,可以继承
BaseAgent类并编写自定义的Python代码来精确控制代理的行为。
4. ADK的工具与编排
- 实现ReAct循环:ADK通过
LimAgent类原生实现了ReAct(Reason + Action) 这个强大的编排模式。它自动处理“思考”(调用LLM形成下一步计划)、“行动”(调用工具或委托给其他代理)和“观察”(接收工具返回的结果并更新上下文)之间的循环,让开发者可以专注于业务逻辑而非底层实现。 - 设计有效的工具:在ADK中,工具本质上是Python函数 。为了让LLM能正确使用这些工具,你需要像设计API一样设计它们:
- 函数签名:使用描述性的名称和强制性的类型提示。
- 文档字符串 (Docstring):这是LLM理解工具用途、参数和返回值的核心,必须清晰准确。
- 返回结构:工具必须返回一个字典,最好包含一个
status键(如success或error),以便代理能判断操作是否成功。
5. 标准化与部署
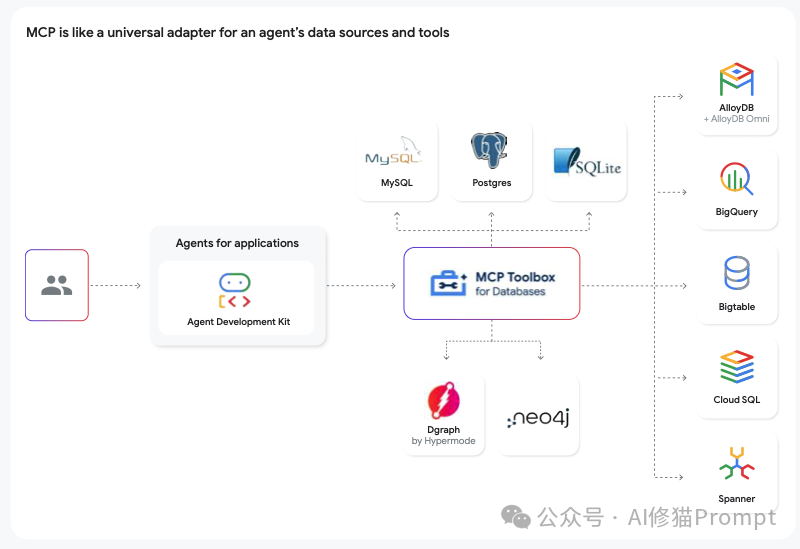
- 标准化连接 (MCP & A2A):
- MCP (Model Context Protocol) 让你能将代理轻松接入各种数据源和工具,而无需为每一个都编写定制化的集成代码。
- A2A (Agent2Agent Protocol) 则让你的代理能够发现并与其他(可能是第三方开发的)代理进行通信和协作,共同完成更复杂的任务。
- 数据管理:ADK提供了与Google Cloud数据服务(如Vertex AI Search, Firestore, Memorystore, Cloud SQL)的集成,让你能够轻松为代理构建长期记忆、工作记忆和事务性记忆。
- 部署到托管运行时:
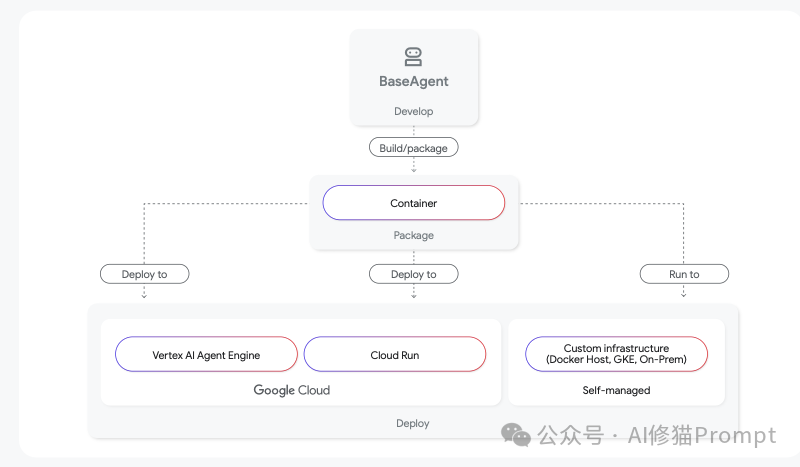
- ADK是部署无关的,你可以将代理容器化后部署到任何地方。
- 对于创业公司,Vertex AI Agent Engine 是推荐的部署目标。它是一个专为代理设计的全托管服务,能自动处理扩展、安全等问题,并提供记忆库 (Memory Bank) 等高级功能,让你的团队能专注于产品本身而非基础设施。
6. 一步步构建你的第一个代理
最后,指南手把手教你如何定义一个Agent :
- 定义Agent身份Identity:设置
name(名称)、description(描述)和model(使用的模型)。 - 提供核心指令Instructions:在
instruction参数中,用自然语言详细描述代理的角色、任务、约束以及如何使用它的工具。 - 装备工具Tools:为代理提供完成任务所需的函数,例如
get_user_details()或create_jira_ticket()。
第二部分是一份非常扎实的实践指南。它不仅介绍了ADK这个强大的工具,还阐明了其背后的设计哲学和架构模式,并提供了从定义、开发到部署的完整路径,为开发者构建功能强大且可扩展的AI代理奠定了坚实的基础。
第三部分:确保AI Agent可靠与负责任
最后我们来深入探讨这份指南的第三部分:“确保AI代理的可靠与负责任” (Ensuring Al agents are reliable and responsible)。这一部分是整个指南的点睛之笔,它解决了将AI代理从“能用”推向“在生产环境中值得信赖”的关键挑战。鉴于大型语言模型(LLM)系统固有的非确定性,传统的软件测试方法已不再足够。本章引入了一套名为AgentOps 的严谨工程方法论,旨在系统化地确保代理的安全性、一致性和价值。
1. AgentOps:为生产级代理设计的框架
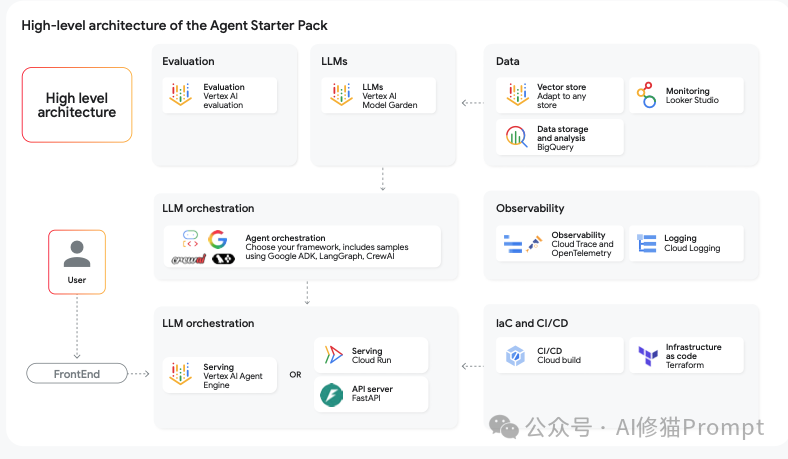
Agent Operations (AgentOps) 是一个专为AI代理设计的运营方法论,它将DevOps、MLOps和DataOps的原则应用于构建、部署和管理AI代理的全生命周期。它的核心目标是提供一个系统化、自动化、可复现的框架,以应对非确定性系统在生产环境中的复杂性。它通过建立持续的反馈循环,不断改进代理的可靠性、安全性和性能。
2. AgentOps的核心:系统化的多层评估框架
评估是AgentOps的基石, 指南摒弃了表面的“感觉测试”(vibe-testing),提出了一套严谨、多层次的评估框架,以确保代理的正确性。
第一层:组件级评估 (Component-level evaluation)
- 目标:验证代理系统中确定性组件的正确性,例如工具函数、数据处理逻辑等。
- 测试内容:工具在面对有效、无效和边界输入时的行为;API集成的成功、失败和超时处理。
- 实现方式:开发者使用标准的单元测试框架(如pytest)为ADK中定义的工具编写测试用例,Agent Starter Pack 会自动生成配置好的测试环境。
第二层:轨迹评估 (Trajectory evaluation)
- 目标:这是最关键的一层,旨在验证代理的推理过程是否正确。这里的“轨迹”指的是代理为完成任务所执行的完整的“思考(Reason) -> 行动(Act) -> 观察(Observe)”序列。
- 测试内容:代理是否形成了逻辑正确的假设?是否选择了正确的工具?是否正确地生成了工具所需的参数?是否能正确地整合工具返回的结果以指导下一步行动 ?
- 实现方式:ADK 的核心运行时会自动记录每个步骤,并与Google Cloud Trace集成,让开发者可以可视化整个推理链条。Agent Starter Pack 则通过自动化的CI/CD流水线,在每次代码提交时运行预设的“黄金测试集”,以防止推理能力的退化。
第三层:结果评估 (Outcome evaluation)
- 目标:评估代理在推理循环结束后生成的最终、面向用户的答案的质量。
- 测试内容:答案的事实准确性和“接地”情况;是否有效解决了用户问题;语气是否恰当;内容是否完整。
- 实现方式:Agent Starter Pack 集成了Vertex AI的评估服务,可以使用LLM-as-judge(让另一个LLM来评分)进行自动化评估,同时也提供了UI界面供真人评估(HITL),并将反馈数据记录到BigQuery中进行分析。
第四层:系统级监控 (System-level monitoring)
- 目标:评估工作在部署后并未结束。这一层旨在持续追踪代理在真实生产环境中的性能,并检测行为漂移或操作故障。
- 监控内容:工具调用失败率、用户反馈分数、推理轨迹的度量(如完成任务所需的循环次数)、端到端的延迟等。
- 实现方式:Agent Starter Pack 提供了一套开箱即用的可观察性技术栈,它会自动配置OpenTelemetry、日志路由和Looker Studio仪表板模板,让团队能够立即开始监控真实世界的使用数据。
3. AgentOps工具包:ADK 与 Agent Starter Pack 的协同
这两个工具被设计为协同工作,清晰地分离了应用逻辑和运营生命周期。
- ADK (Agent Development Kit):开发者用它来编写代理的应用代码,如实现工具、定义指令和编排流程。
- Agent Starter Pack:它是一个脚手架工具,负责提供生产级的运营环境。它会生成部署基础设施的代码(Terraform)、自动化CI/CD流水线(Cloud Build)以及评估所需的所有配置。
这个协同工作流通常分为五步:
- 用 Agent Starter Pack 引导一个新项目。
- 在生成的项目结构中,用 ADK 开发代理的核心逻辑。
- 提交代码,自动触发CI/CD流水线。
- 流水线自动进行持续评估,验证代理的性能和安全性。
- 评估通过后,自动部署到生产环境。
4. 构建负责任且安全的AI代理
最后,指南强调了构建Agent时不可推卸的责任:确保它们是安全、可靠且对齐人类价值观的。文档作者推荐遵循Google的安全AI框架(SAIF),并利用ADK和Agent Starter Pack实施“纵深防御”策略 :
- 安全的基础设施:Starter Pack使用Terraform来配置安全的云环境和遵循最小权限原则的IAM角色。
- 输入输出护栏 (Guardrails):在ADK中实现应用逻辑来验证用户输入(防止注入攻击)和过滤代理的输出(移除有害内容)。这些护栏会在CI/CD流水线中被自动化测试。
- 审计与监控:ADK能够生成代理每个“想法”和工具调用的详细轨迹。Starter Pack则会自动将这些日志数据安全地存储到BigQuery中,形成一个持久的、可供合规审查和事件响应的审计日志。 总而言之,第三部分将AI代理的开发从一门“艺术”提升到了一门“工程科学”。它通过引入AgentOps方法论和强大的工具包,为创业公司提供了一套清晰、可操作的路径,帮助他们充满信心地构建、部署和管理那些不仅功能强大,而且安全、可靠、负责任的AI系统。
关于Agent运维方面的内容,中科院有一篇比此文档更详细和系统的论文,从头到尾论述了Agentops,感兴趣您可以看下
Agent怎么运维?中科院清华重磅发布:AgentOps来了!
写在最后
在详细阅读了这份指南后,咱们可以提炼出几个核心要点,并从中发现一些极具启发性、引人深思的观点。
- AI代理是一个“系统”,而非单一的“模型”:这是最根本的要点。一个生产级的AI代理,是由模型(大脑) + 工具(手脚) + 数据架构(记忆) + 编排(执行功能) + 运行时(家) 共同组成的复杂系统。脱离系统谈代理,只是一个玩具。
- “接地”(Grounding)是建立信任的核心:指南反复强调,为了防止模型产生“幻觉”,必须通过RAG、GraphRAG乃至最先进的Agentic RAG技术,将代理的回答与可验证的、真实的数据源连接起来。这不仅是技术问题,更是产品能否被用户信任的商业问题。
- AgentOps是生产级代理的必要工程纪律:这是第三部分的核心思想。管理AI代理这种非确定性系统,不能再依赖“感觉”,而必须引入一套类似DevOps的严谨流程,AgentOps。它强调通过系统化的多层评估框架(组件、轨迹、结果、监控)来确保代理的可靠性和安全性。
过去一年,很多人认为用好AI就是写好提示词 (Prompt)。但这份指南明确指出,在生产环境这远远不够。真正的价值在于设计一个稳健的、可扩展的系统架构。如何为代理设计分层的记忆系统?如何选择合适的编排模式(ReAct)?如何设计原子化、职责单一的工具?这些问题表明,AI应用的开发正在迅速从“文科生”的提示词艺术,回归到“理科生”的软件工程和系统设计。
文章来自于微信公众号 “AI修猫Prompt”,作者 “AI修猫Prompt”
【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

