AI 出图终于「指哪打哪」!

最近的 AI 生图、图像编辑领域,简直神仙打架。
正面战场上,Google 的 Nano Banana 与国产新秀豆包 Seedream 4.0 正杀得难解难分,所有人的目光都聚焦于此,比拼的是模型的硬实力,是谁能生成、编辑出更惊艳的图像。 一个神秘选手却从一个意想不到的角度切入了战场。
它叫 Reve。刚上线时,就因为在 X 上的作品频频刷屏,引发了创作者社区的各种讨论。
它似乎无意卷入这场像素级的参数竞赛,而是提出了一个有意思的问题:
当大家都能生成「好图片」之后,创作的真正瓶颈究竟在哪?
Reve 给出的答案是:交互。
相比于目前最 SOTA 的 Nano-Banana、字节 Seedream 4.0、混元图像 3.0,Reve 的自研模型本身并不算「性能突出」,但它提供了一种全新的交互式编辑体验。
经过深度体验,我们认为,用「AI 生图模型」来定义 Reve 已经不够准确。它更像一个视觉 Agent,能理解画面结构,听懂精细指令,并允许你像设计师一样直接「动手」创作。
接下来,我们将深入测评,聚焦于它最突出的 3 大亮点:
【1】 10 人小团队做出来的「模型即产品」
【2】基于交互的精细编辑
【3】美学能力
Reve 是谁?
Reve AI 是一家 2023 年 12 月才建立的加州 AI 初创公司,他们在 2025 年 3 月推出了第一个生图模型叫 Reve Image 1.0,内部代号是「Halfmoon」。6 个月过后,再次升级该模型为「图像编辑模型」。
这家公司虽然年轻,但出手相当生猛。Reve Image 1.0 一上线,就在当时(3 月 26 日)的测评榜 Artificial Analysis Image Arena 上,击败了谷歌的 Imagen 3、Flux 1 等 SOTA 模型,直接冲上榜首。
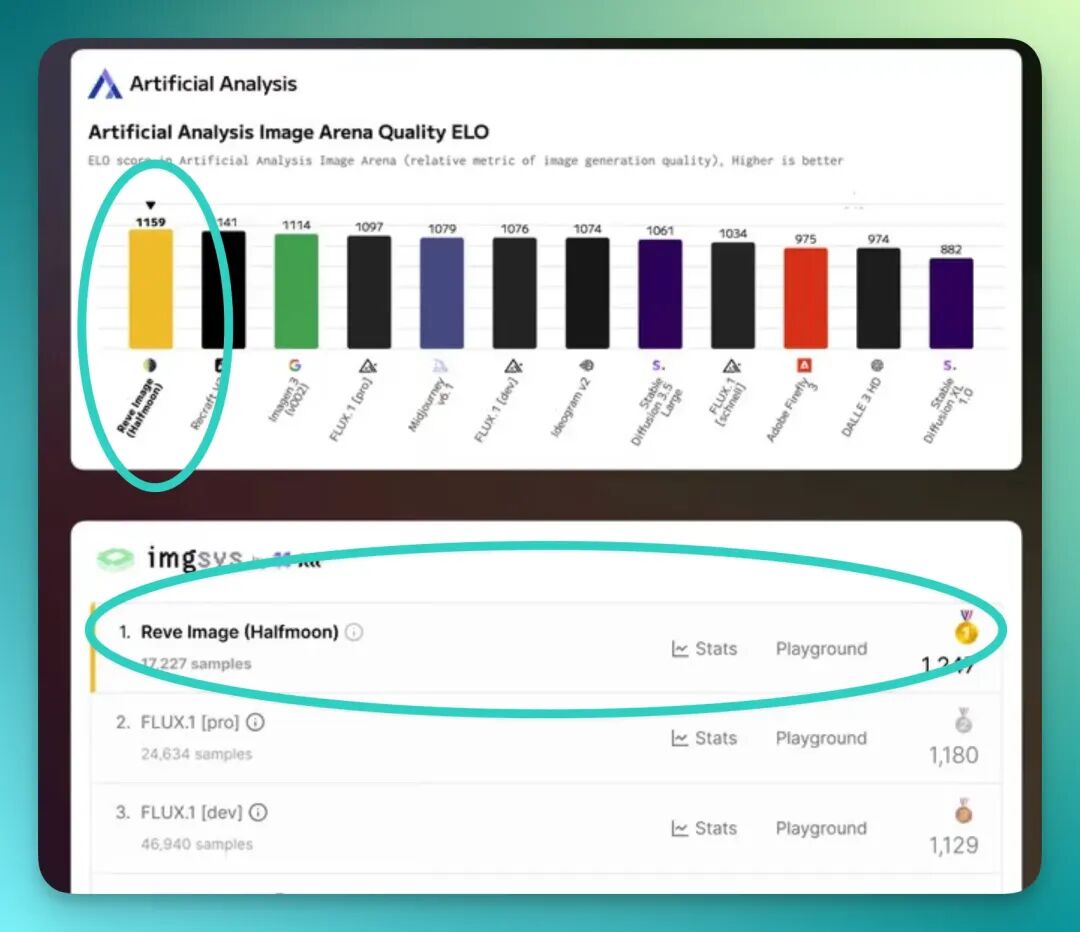
但更有趣的是,Reve 一点也没有因此张扬。他们几乎不做市场宣传,也不谈流量、融资或收入数据,低调到让人有点好奇。媒体常形容 Reve 是一家「靠产品说话」的公司。
在公开资料里,你几乎看不到他们的融资数额、团队规模或长期计划。
比如 Nugg.ad 的一篇报道就写道:「这家加州初创公司,对自己的规模、融资或远期目标,几乎没有任何公开信息。」
这种风格在硅谷其实挺少见,因为大多数初创企业都想尽可能的高调一点,吸引投资者注意。随着曝光增多,Reve 的创始人身份也浮出水面。他叫 Michaël Gharbi,曾是 Adobe Research 的老将。

在接受采访时,他提到 Reve 的核心目标是打造一种「语义中间表征」(semantic intermediate representation)。
简单理解,就是希望让机器不只是理解「你要画什么」,而是能明白「你想表达什么」,让人和 AI 在创意意图层面更好地协作。
Reve 团队自己也这样介绍自己:
「我们是一支由研究者、工程师、设计师与故事讲述者组成的小团队。」
令人惊讶的是,Reve 从发布研究预览版到登上 LMArena 和 Artificial Analysis 榜单前列,仅用了不到半年。
团队规模也只有10个人。
他们在官网上不断强调自己的「产品」定位:
「我们不只是做模型的公司,我们更是一家做产品的公司。我们的目标是创造最好的创作智能工具,包括我们独一无二的编辑器。」
换句话说,Reve 并不是一家纯粹的模型公司,而是想让 AI 真正成为创意者手里的工具,并为此努力的「产品公司」。
基于交互的精细编辑
Reve 的界面极其简洁,左侧是熟悉的对话框,看似与其他工具无异:
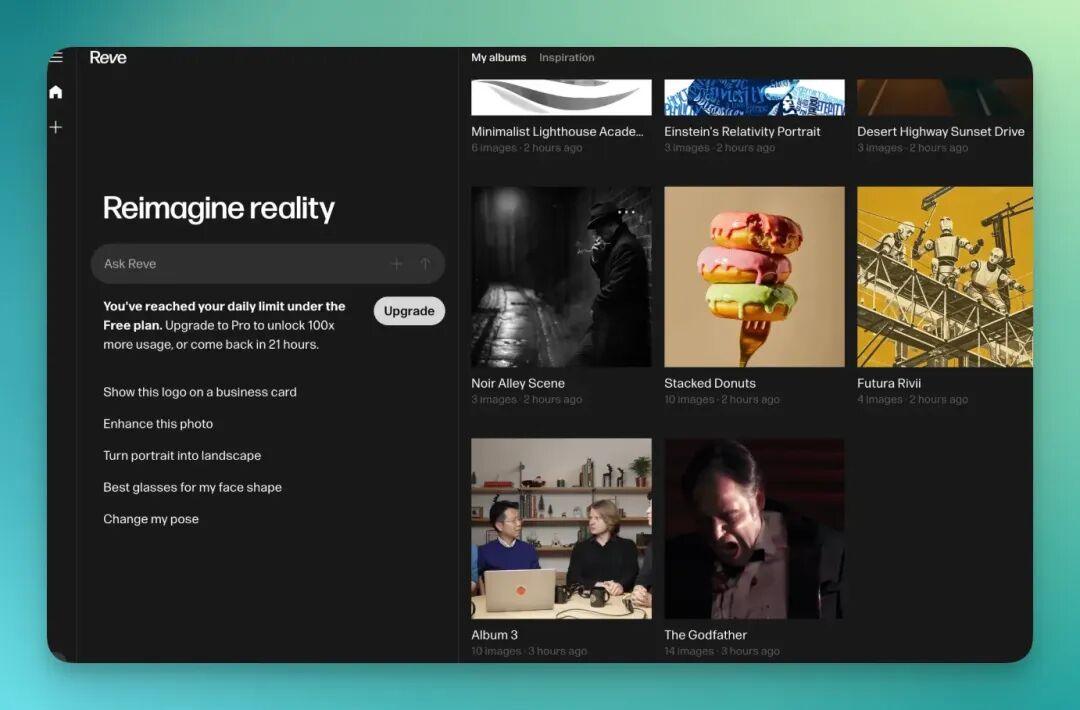
但真正有趣的地方,藏在生成图片后右上角的那个「Edit」按钮里。这正是它与所有同类产品拉开「体验差距」的核心所在。
1)多元素位置调换 OpenAI 发布会位置调换
Reve 的新交互体验最出彩的地方,在于当画面之中存在多个主体、多个元素时的图像编辑。
像是下面这张图片,是 Sam Altman 和他的三位研究员在一次发布会上的图片。 我们能看到画面之中主体是四个人物,以及他们手边都有杯子和笔记本电脑。
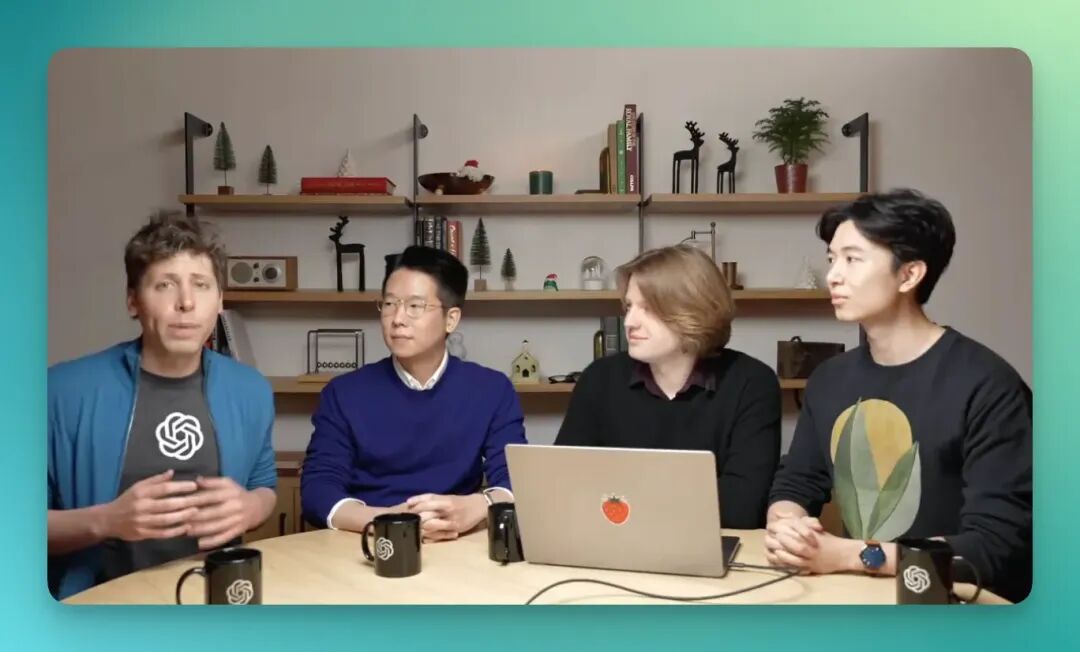
下面让我们来看一看 Reve 对于画面的识别的精细能力如何,
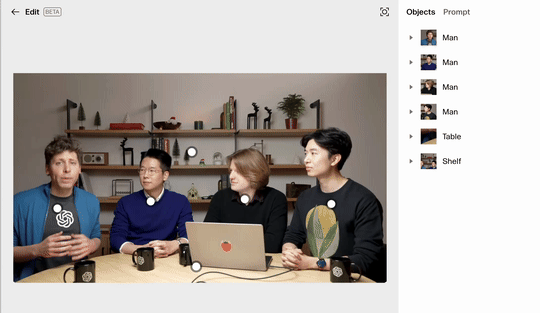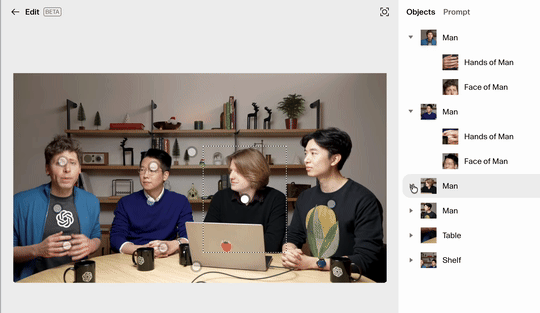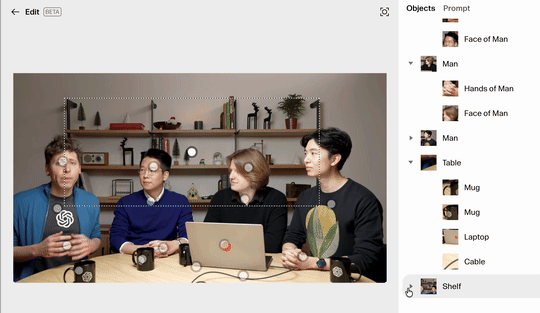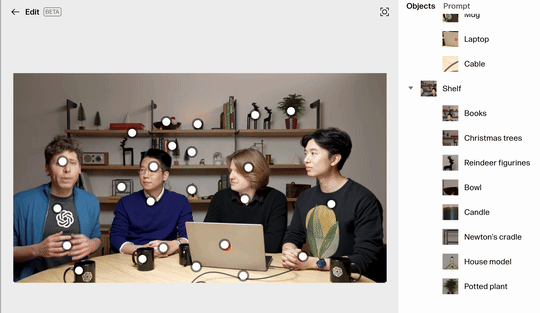
过去做 AI 图像编辑时,最大的痛点除了模型能力,就是交互方式的局限。传统流程往往依靠「用嘴说」的方式来操作,虽然比最初的方法方便不少,但在细节把控上依然不够精确。
而现在,Reve 可以通过直接拖动画面中被识别出来的元素,以非常简单的方式,在多个主体之间,进行图像编辑。
像是下图,我将左 2 的男子与右 2 的男子两位直接拖动方块,就可以将他们进行非常精细的替换:
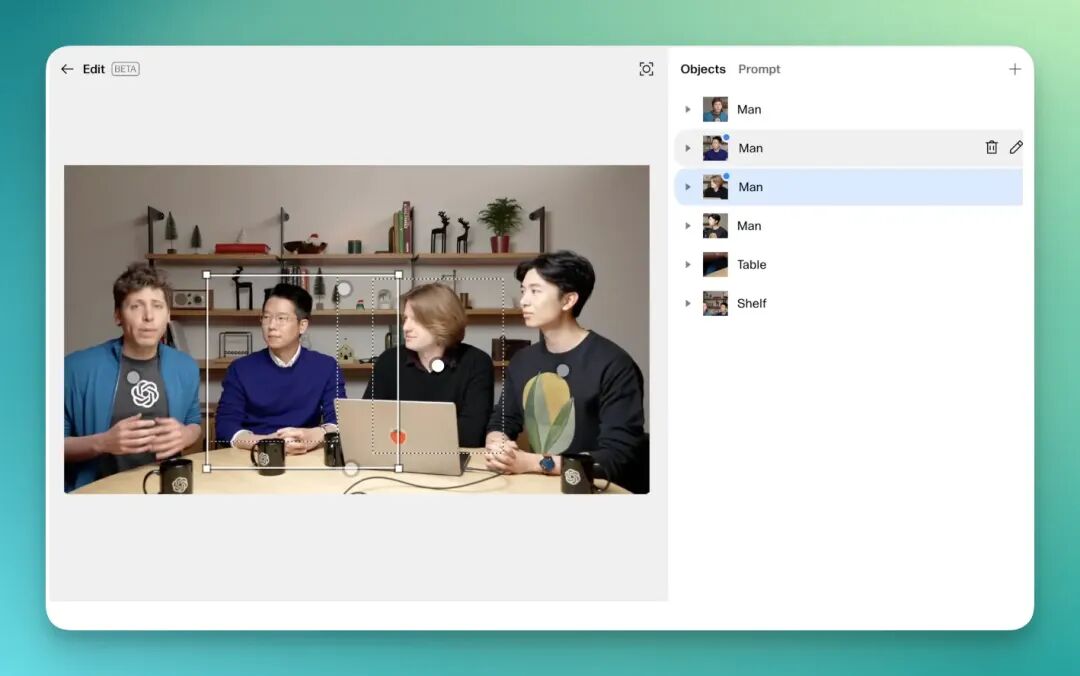
这是 Reve 生成的结果。可以看到,2 位人物的替换精准度很高,不过左 2 人物的姿态并不是很自然,仍然有一些瑕疵:

坦白说,为了得到这个理想效果,我们也经历了数次尝试(Roll 好几次)。目前的模型能力仍有其局限,偶尔会出现一些「幻觉」。
不过,该说不说,整体的交互方式所带给我的感觉仍然是比较惊艳的。
再比如下面这张图片,我让 2 位主体人物、前面的水杯以及笔准电脑进行了替换,效果如下。
你会发现整体的效果还是比较自然和真实的:
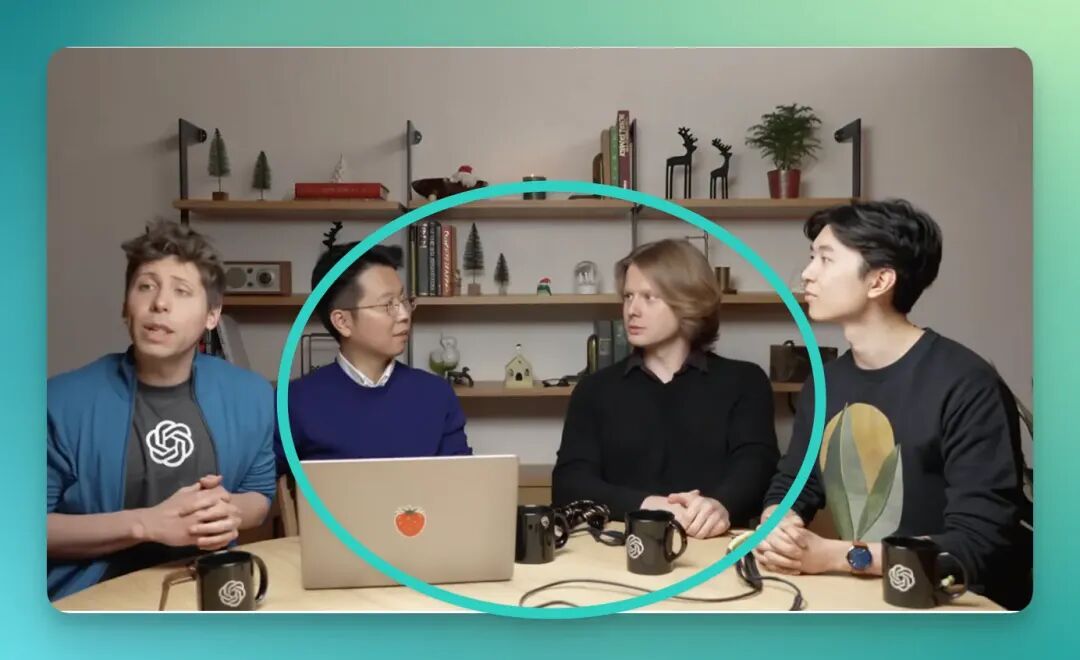
还有 1 个,我们认为专门值得说道的地方。
在很多传统的 AI 图像编辑工具里,当你上传一张图片时,系统确实会帮你分析画面内容,但是,他们往往并不支持「编辑」。
而 Reve 不一样。它会为每一个图层都生成一段可读的 Prompt,更重要的是,你可以直接修改这段 Prompt 来重新定义图像内容。
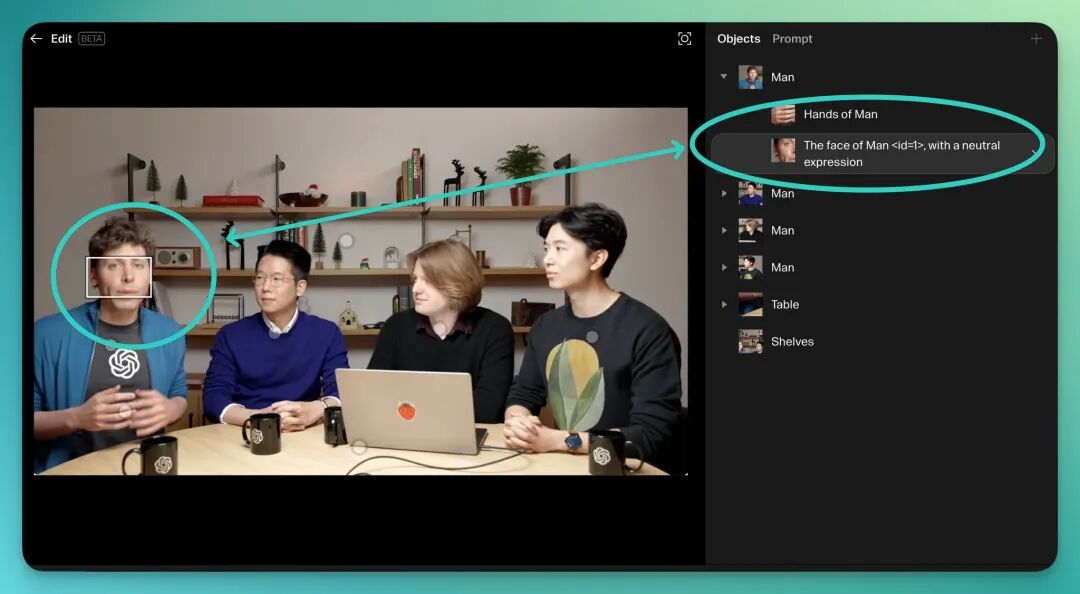
像是我可以直接在文本框中把原本的提示词更改为「一个具有笑容的表情」,点击编辑执行之后,你就会发现 Sam Altman 出现了一个非常可爱的笑容:

2)指哪打哪的单元素编辑
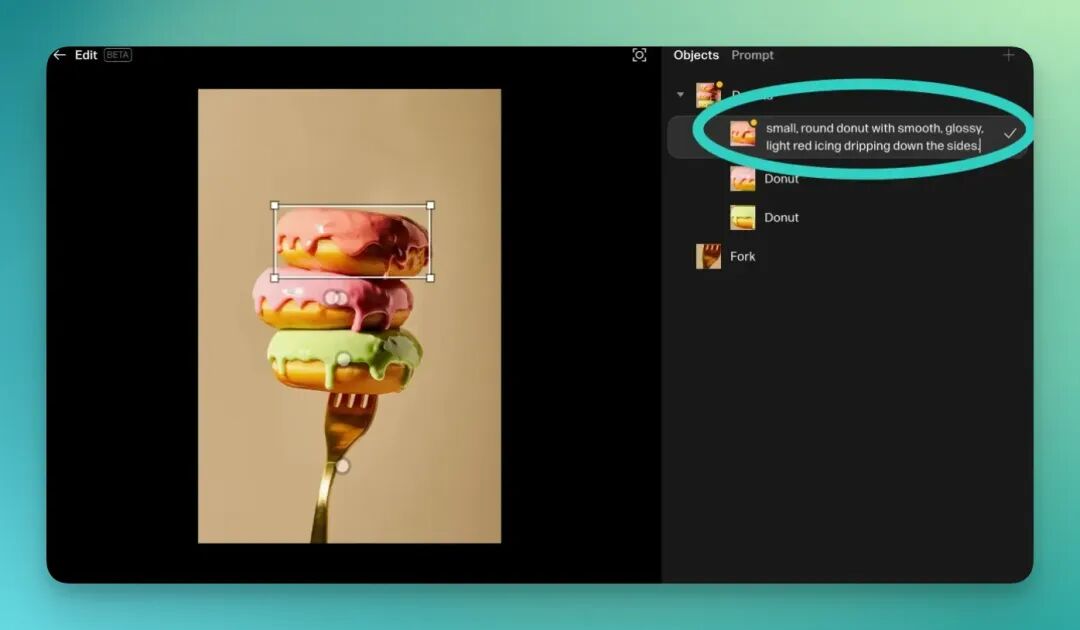
如下图所示,Reve 准确识别出了三个甜甜圈和一把叉子。每个元素都变成了一个可供点选、拖动的白色方框。
我们只需轻轻一点,就能选中下方的叉子,然后直接将它拖动到甜甜圈的上方。
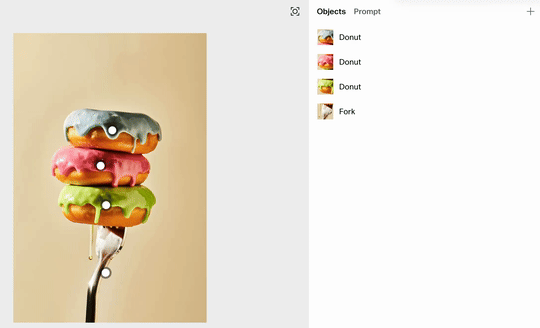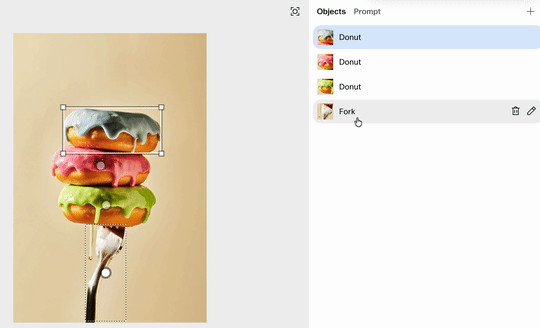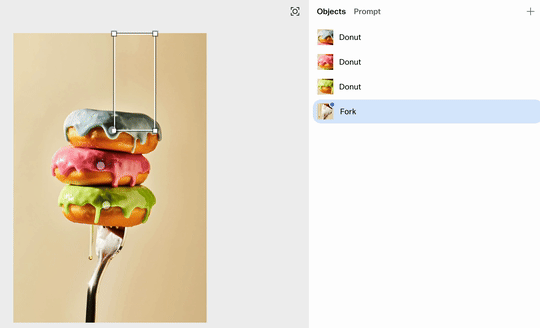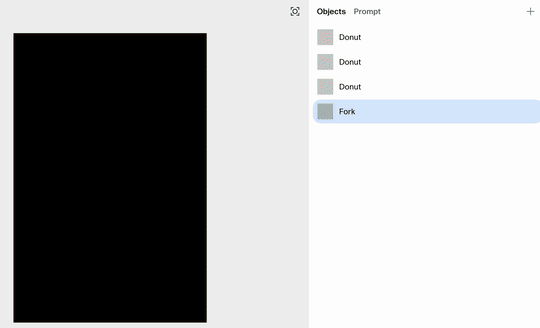
放手瞬间,Reve 便会重新渲染画面。
最终结果还不错,不仅图像的整体风格、光影保持了高度一致性,而且叉子和甜甜圈之间还产生了自然的物理交互。

同样地,Reve 不仅在视觉上拆分了图层,它还会为整张图乃至每一个被识别出的「图层」元素,自动生成对应的 Prompt。
可以说,修改图片有了两种途径:直接拖拽,或者精准修改局部 Prompt。
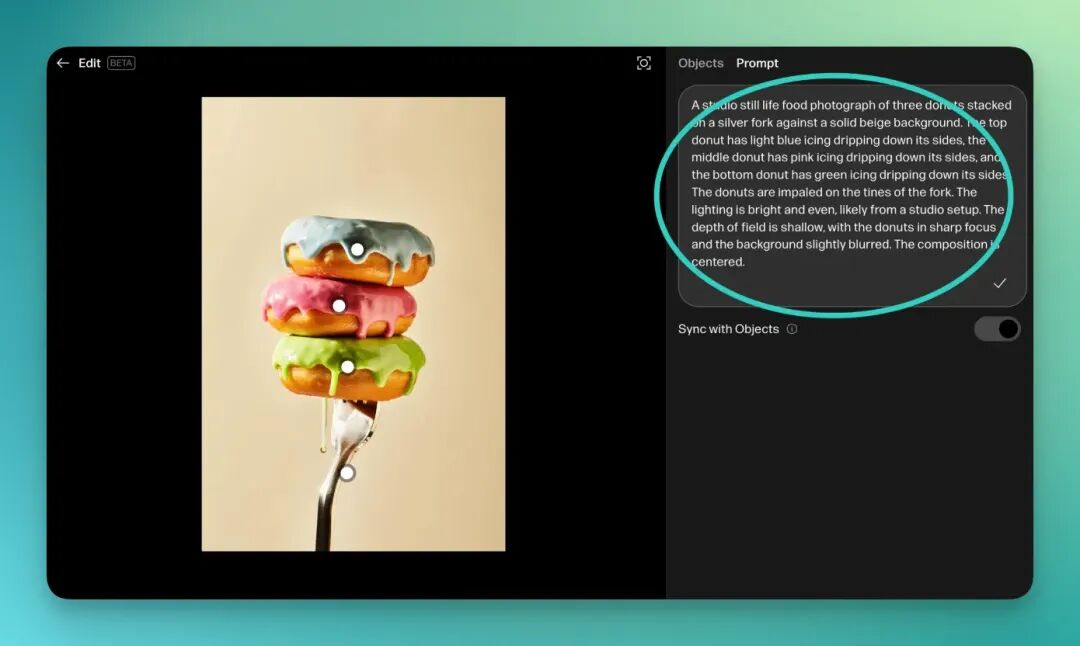
比如说,我们对这个 prompt 进行一些小的修改:
让最上面的填线圈变成红色。改变一下摄影的光线,从左上角摄入右下角,并且把叉子的颜色从银色改为金色。

而且 Reve 会自动归纳物体,像是它会将 3 种甜甜圈归纳为「甜甜圈」。
而当你点开「甜甜圈」之后, 就可以针对每一个元素的 Prompt 进行相对应的独立修改:
像是我输入了一段 prompt:
将最上面的甜甜圈像是被咬了一口一样,产生了一个裂缝。

可以看到,Reve 用拖动的方式进行精细交互编辑时,整体一致性保持得比较好。
我又上传了一张在东京拍摄的火车照片,画面中有 2 列火车:左下角的红色列车和右上角铁路中的黄色列车。
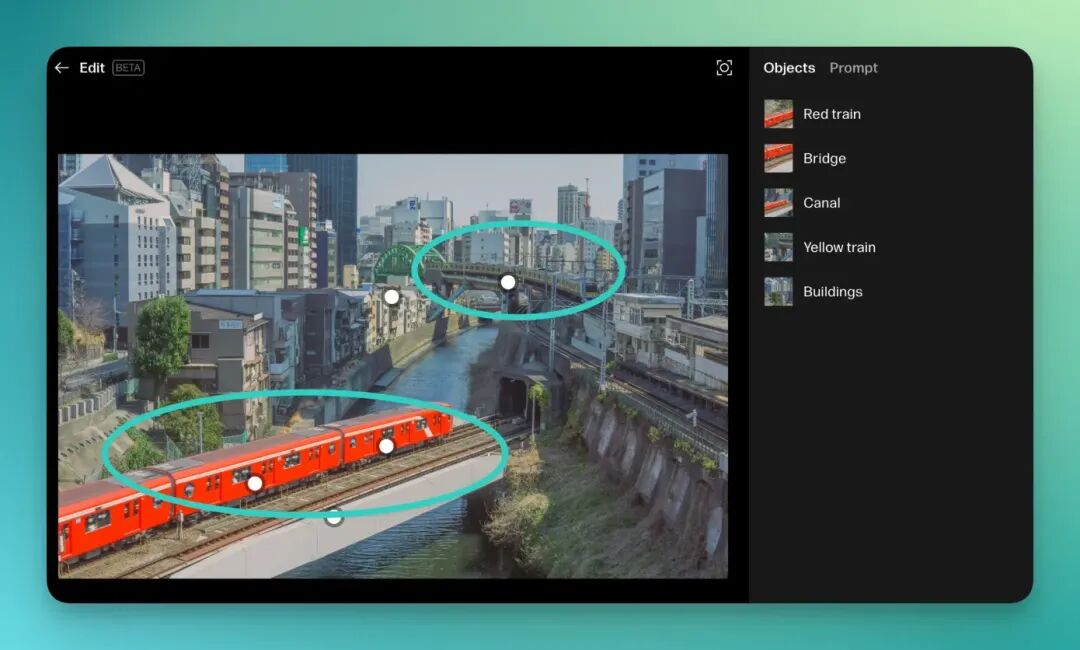
我们尝试直接对左下角的红色列车进行修改:
左下角的红色火车变为两种形态的白色火车。
Reve 精准地完成了任务,且与周围环境融合得比较好:

甚至我可以直接用鼠标拖动右上角的黄色火车,将它「拽」出隧道,摆放在原先红色火车的身旁。
Reve 不仅完整地抽离了火车元素,保持了周围环境的一致性,甚至还精准地还原了黄色火车「半截在隧道里」的原始状态,让两辆车形成了自然的相对运动姿态。
这背后,体现的是对空间、遮挡关系和光影的物理理解:

不过,受限于模型本身能力,这样质量还不错的结果仍然需要多尝试几轮。
3)推理联想能力
除了对已有图像进行编辑,我们还测试了 Reve 在创意生成方面的能力,试图探究其是否真正理解了画面背后的「场景」与「逻辑」。
像是我上传了一张马斯克与一位女主持人的访谈图片:

先是让 Reve 用多个角度、多种环境进行联想,给出各种结果:

输出的结果展现了它在摄影语言上的多样性。它不仅能模拟出不同机位的拍摄效果,如特写、中景等,还能切换不同的布景与打光方案。
而且在体验的过程中,我发现 Reve 对于环境以及光线、阴影的使用非常熟练。
比如,我给整体画面加上一些摄影风格的艺术效果,这些效果会让画面看起来更紧张、更有压迫感。
你能发现整体的阴影以及光线的效果都非常真实:

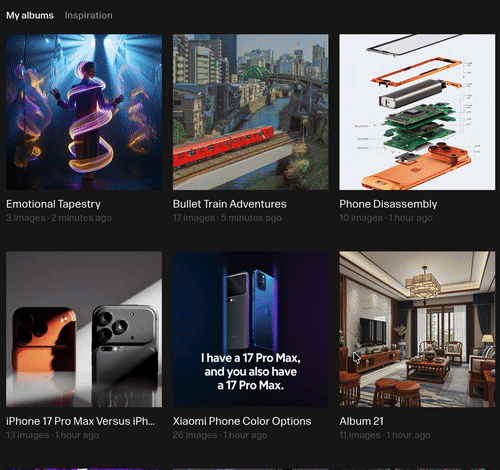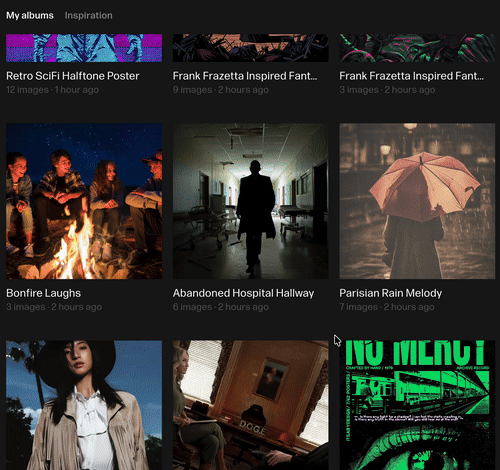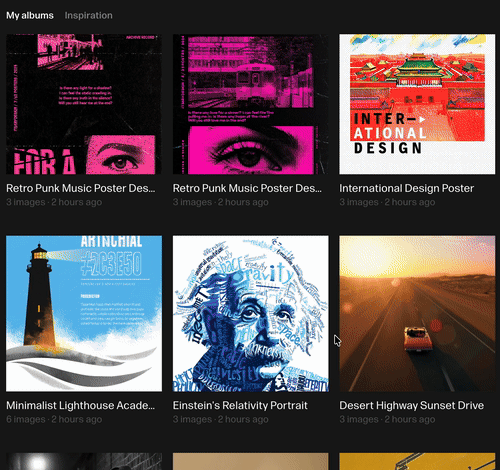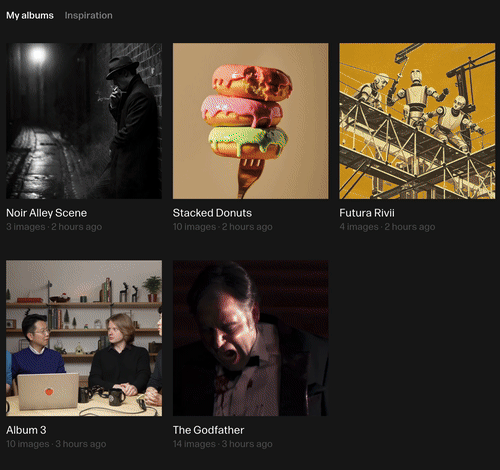
为了测试其在商业设计流程中的潜力,我们引入了近期热门的「iPhone 17 与小米 17」作为素材。
首先,在单张产品图的基础上,我们让 Reve 进行了快速的产品迭代构思,例如生成多种配色方案、更换背部副屏的显示效果等:

在这一环节,它表现得相当高效,能够为设计师提供丰富的视觉参考。
随后,我们提升了难度,要求它将两款不同品牌的手机融合在同一画面中,并创作出专业级别的产品宣传图。
最后的效果如下,你会发现,它对于多种物体的摆放,模拟商业摄影的布光、构图和材质反射上,确实展现了一定的熟练度,颇具专业影棚的质感。

甚至最后,我让他为这两款手机放在一起做了一张海报。
标语则是:「我有一个 17 Pro Max,而你也有一个 17 Pro Max。」
最后的效果如下,很有梗,很不错,融合的很协调:
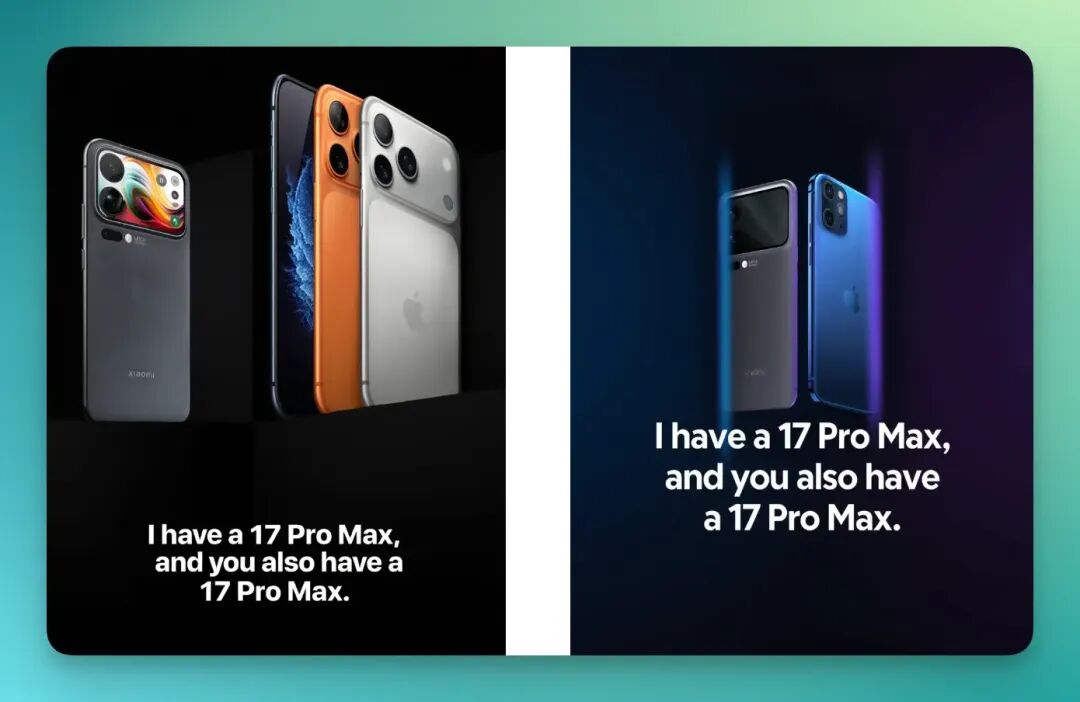
虽然会有一些小小的幻觉的瑕疵,但整体这种商业摆拍图片的效果还是非常不错的。
最后,我让它将 iPhone 17 所有零配件进行拆解,以下 3 张是它给出来的「爆炸图」结果:

这其实已经体现出来,REVE 已经具有初步的视觉推理能力了。
美感
这款 Reve Image 1.0 图像生成模型,并非简单在已有模型基础上微调或蒸馏,而是「从头训练」的新模型,非常强调多样化风格的输出。Reve 的最新版本也再次对视角、内容和细节拥有了更加精确的控制。
1)换装姿势
AI 生图在处理人物时,最常被诟病的就是姿态僵硬、表情空洞,即所谓的「AI 味」。
为了测试 Reve 在这方面的表现,我们试一试虚拟试衣。
我提供一张模特照片作为主体,再辅以一张包含多种服装风格的图片作为「灵感源」,让 Reve 自由搭配并摆出专业的商业姿势:

下面就是 Reve 给出的结果,整体效果非常真实,并且很有美感:

你会发现,Reve 生成的人物,不止是简单地把衣服「P」上去。相对于很多传统模型,它在人物的姿态、神韵和场景融合度上,都显得自然得多,并且表情、角度也会更多变。
2)电影级画面
最后,我们再来看看 Reve 直接所生成的电影级画面的真实度。
提示词如下:
电影感定格画面:黑色电影风格的昏暗小巷,湿润路面上闪烁着霓虹灯的倒影,一个身穿风衣的男人在闪烁的路灯下抽烟,深邃的阴影与强烈的明暗对比,35mm 胶片颗粒质感。

再比如悬疑风格。
提示词如下:
缓慢的推轨镜头穿行在废弃医院的走廊内,闪烁的荧光灯下,墙壁斑驳剥落,走廊尽头隐约出现一个模糊身影,营造出电影般的悬疑感与令人不安的寂静氛围。

不得不说的是,Reve 在多主体多人物的图像中,所产生的这种真实感,确实会让你感觉相对于传统 AI 生图模型, 有了很大的提升:

3)海报
在海报生成的理解能力上,Reve 所产生的效果比较中规中矩,能创作出视觉和谐、重点突出的作品,比如下面这几张灯塔,以及中国传统建筑的英文海报:

对于多种艺术风格的把控,Reve 的表现还不错。
像是下面这张复古朋克风音乐海报,上面会有很多复杂的元素以及图像的排布,Reve 给出的结果还可以。
提示词如下:
复古朋克风音乐海报:深黑做旧杂色背景,叠加半调网点与丝印质感,极繁主义层叠排版。顶部巨幅暗绿色解构字体“NOMERCY”,下方小字“CRAFTEDBYHAND/1979”“ARCHIVERECORD”。中央两张绿色调图像:复古地铁疾驰与眼睛超现实特写。文字信息:左侧“ITSABBYDESIGN/7/42 POSTERS /2025”,中段诗句:“Is there any light for a shadow?...”

虽然细节上可能还有优化的空间,但它确实把复古、朋克、层叠排版、字体设计这些核心元素都融合到了一起,整体效果还是相当不错的。
最后我发现,Reve 其实已经是一个比较合格的 AI 生图 Agent 了。
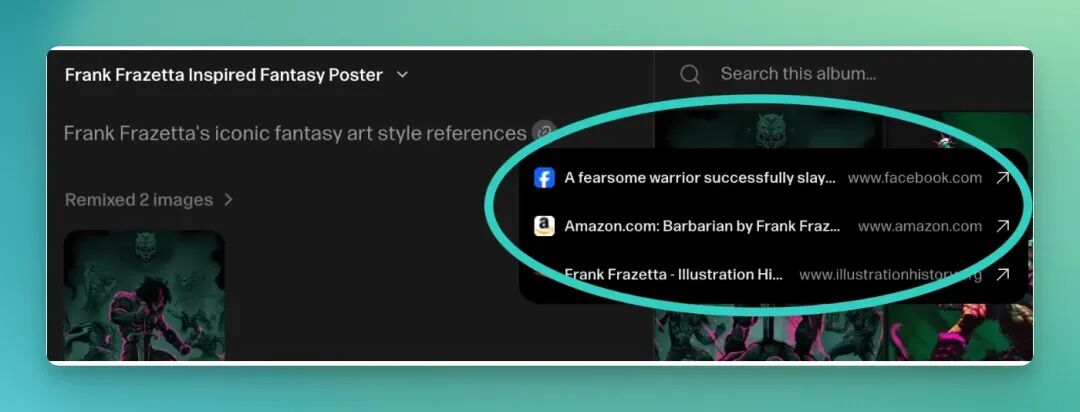
因为我让它生成了一张 Frank Frazetta 绘画风格的海报,发现它会自动地先去进行相关的艺术风格的检索。
像是它自行去搜索了 Facebook、Amazon 和另一个叫做 illustration 的网站,先给自己补充一些知识,然后再根据这些所获取的风格进行生成图片。
提示词如下:
Frank Frazetta绘画风格,奇幻风格电影海报

对于点绘艺术的多种风格的支持能力,Reve 也展现得还不错。
像是下面这 2 张点绘艺术科幻电影海报:
采用点绘艺术halftone技法,以密集小黑点塑造形象,科幻电影宣传海报 Interstellar navigation

总而言之,Reve 在 2 个核心层面都给出了不错的答卷:一是图像编辑的交互方式,二是最终出图的美学效果。
它的编辑能力,特别是那种类似图层的、可直接拖拽修改的模式,确实是一个亮点。相比于完全依赖提示词反复调整,这种直观的操作方式在很多场景下效率更高,也更容易实现一些精细的修改。
而在美学层面,无论是人物的姿态、场景的氛围感,还是对特定设计风格的模仿,Reve 的表现都还比较扎实。
综合来看,无论是作为高效的生产力工具,还是作为探索创意的画布,Reve 都展现了其作为当前第一梯队 AI 图像模型的实力。
最后补充一个信息,在测试过程中,我大概生成了 200 张图片后,系统提示我当天的免费用量已经用完了。这个额度对于日常体验来说,应该是足够了。
测评总结:值得关注,但需保持冷静
经过全面的测评,我们可以得出以下结论:
【1】交互方式是核心亮点。
Reve 的「图层式」交互编辑无疑是其最大的创新,它正在从「语言交互」走向更直观的「视觉交互」。
【2】底层模型是主要瓶颈。
尽管交互体验新颖,但最终的成像质量和成功率,仍然受限于其背后图像生成模型的能力。在处理复杂场景,尤其是多人物的精细编辑时,其表现比较不稳定。
【3】定位是「创意辅助」而非「创作者」。
现阶段,Reve 更适合作为激发灵感的工具。它能为你提供无数种可能性,但将这些可能性变为最终作品,仍需要你投入大量的时间和精力进行筛选和再创作。
AI 竞赛的上半场,是关于「力」的较量:更大的模型,更强的算力,更逼真的像素。这无疑是必要且重要的,它为我们今天所见的一切打下了基础。
但当技术狂奔至此,当人人都能用 AI 生成一张「还不错」的图片时,瓶颈便从技术转向了体验。Lovart、Reve 这类产品的出现,正是这一转变的标志。
AI 的下半场,不再仅仅是「模型力」,更是「交互体验」。
重点不再是模型能做多少事,而是它能以多低的门槛、多高的自由度,真正服务创作者。
毕竟,好的交互,就是为了消除人与 AI 之间的那份「隔阂感」,让所有人都更快乐地「玩起来」!
文章来自于微信公众号 “十字路口Crossing”,作者 “十字路口Crossing”
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


