无需真实奖励,哪怕用随机、错误的信号进行训练,大模型准确率也能大幅提升?
此前,学术界已经发现了一个令人困惑的现象:像Qwen2.5这样的模型,即使在RLVR(带验证奖励的强化学习)过程中给予虚假奖励(Spurious Rewards),它在对应测试集上的准确率依然能神奇地大幅提升,并通过一系列实验实锤了模型在“背题”:实际是模型在训练时就存在不同程度的数据泄露。
然而,先前的工作并没有揭示模型在训练前后的深层次变化,背后的微观机制仍是一个黑盒:虚假的奖励信号,究竟是如何精准地影响了模型内部的深层记忆?

对此,来自南方科技大学、阿伯丁大学、穆罕默德·本·扎耶德人工智能大学、华东师范大学的研究团队对这一过程进行了深度拆解。
研究团队发现,虚假的RLVR并不是漫无目的地强化,而是激活了模型内部的记忆捷径(Memorization Shortcuts),唤醒了潜伏在参数深处的隐性记忆。
这项工作不仅定位到了驱动这一行为的关键位置,研究更揭示了一个关键的真相:模型所谓的进步,往往只是在更高效地检索训练集中的污染知识。
核心发现
一个反常的信号:困惑度悖论
研究团队首先观察到一个违反直觉的现象:在虚假的RLVR训练过程中,模型对答案的困惑度(Perplexity)持续下降,但对问题提示的困惑度却不降反升。
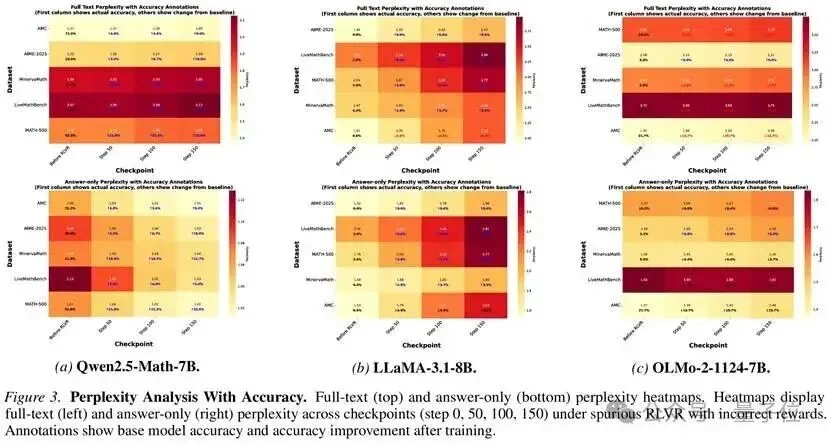
这意味着什么?正常情况下,如果模型真的在学习推理能力,它应该对整个问答流程都变得更加“自信”。
但实际情况是:模型牺牲了对输入问题的一般语言理解能力,换取了对特定答案的精准记忆。
这就像一个学生,为了在考试中答对某道题,不去理解题目本身,而是死记硬背答案。研究团队将这一现象命名为“困惑度悖论”(Perplexity Paradox),它成为识别记忆激活的关键现象。
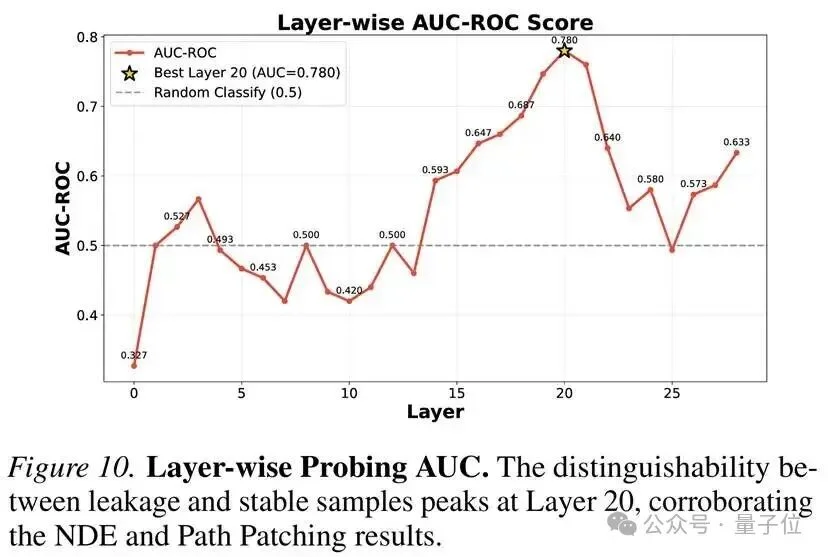
精准定位:18-20层才是关键的记忆节点
那么,模型内部到底是哪些层在驱动这种记忆检索?
研究团队采用了多种机制解释工具的组合拳:
1. 路径修补(Path Patching):因果归因
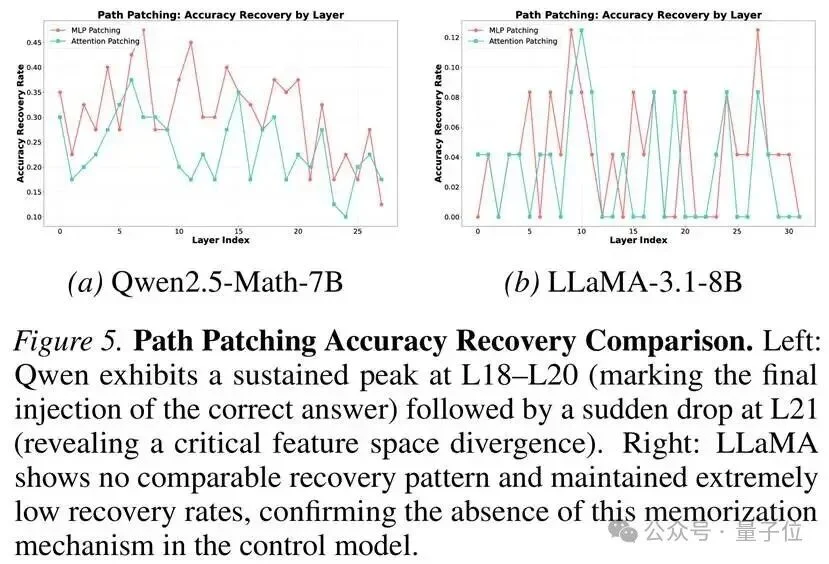
通过在不同层之间交换激活值,研究团队发现:当修补第18-20层的MLP时,模型能够恢复对泄露样本的正确回答;而修补第21层之后,这种恢复能力骤然下降。
这说明,L18-L20是决定性的“功能锚点”(Functional Anchor):经过前层残差流的累加,它们注入了检索记忆答案的关键信号。
2. JSD分析:结构变化的热点
通过计算Jensen-Shannon散度(JSD),研究团队量化了每一层对最终输出分布的贡献变化。结果显示:第21-22层的MLP子组件(W_up和W_gate)贡献值达到了顶峰。
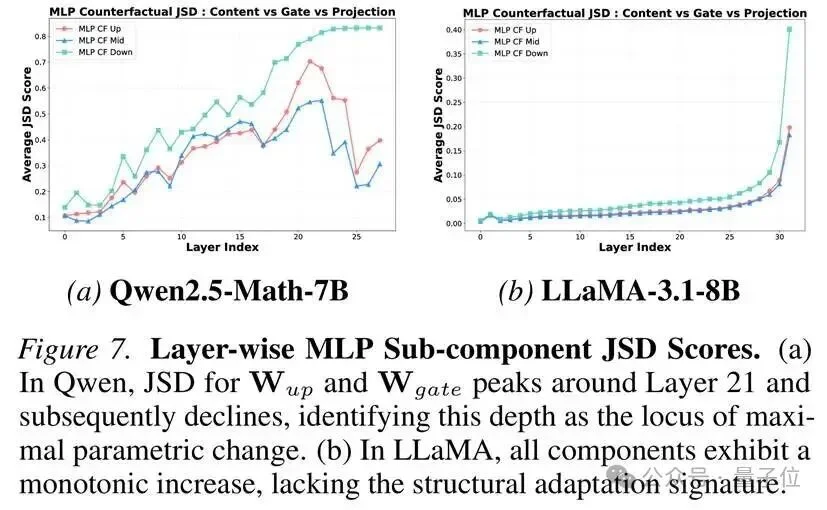
但这里有个关键细节:虽然这些层的贡献达到最大,但随后它们出现了分叉。
整体的MLP保持高贡献度,但W_up和W_gate对准确率的因果贡献却开始变小小。这意味着什么?
说明从此刻开始它们可能不是在存储新知识,而是在进行“结构适配”:调整内部表征空间,以便容纳来自锚点层的突发信号。研究团队将这些层命名为“结构适配层”(Structural Adapters)。
3. Logit Lens:答案是如何“浮现”的
通过逐层投影隐藏状态到词表空间,研究团队直接观察到了答案token的“诞生过程”:
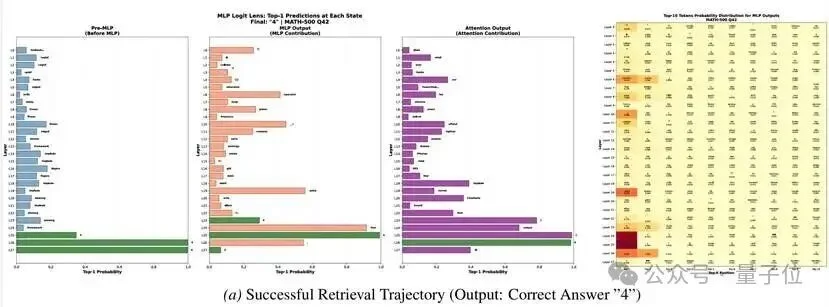
- 在第19层,目标答案首次出现高概率
- 在第21层,这个概率短暂下降(表征转换)
- 在第23层,MLP显著注入正确答案,概率激增
更令人惊讶的是:即使在模型最终输出错误答案的失败案例中,第23-25层的MLP仍然试图注入正确答案——只是因为第19层的初始信号太弱,后续层无法扭转输出。
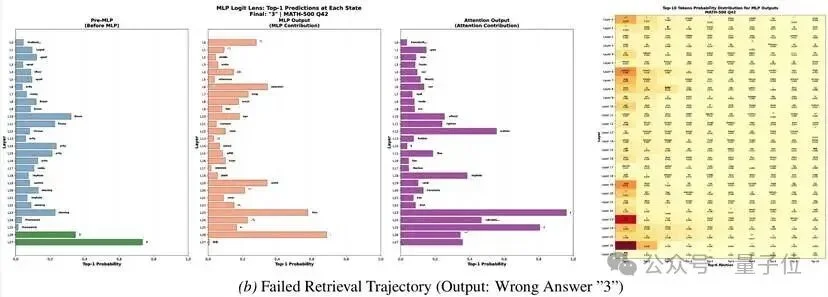
这证实了:MLP确实在持久地存储记忆,而成功检索的关键在于锚点层的信号强度。
动态视角:记忆激活的“分岔点”
为了从连续动力学角度验证发现,研究团队引入了神经微分方程(Neural ODEs),将离散的层级计算建模为连续轨迹演化。
通过计算“分离力”(Separation Force):即泄露样本和正常样本在隐藏状态演化方向上的差异,研究团队动态地确认了:
分离力在第18-20层达到峰值,这正是两类样本的处理轨迹发生物理分岔的位置。
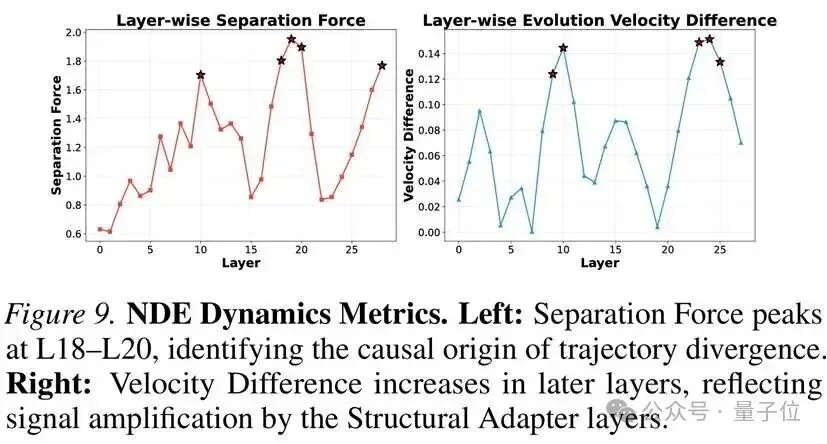
换句话说,模型在这几层做出了关键决策:走推理路径,还是走记忆捷径。
实验验证:从被动观察到主动控制
机制干预:研究团队能“操控”记忆吗?
在确认问题后,研究团队进一步追问一个更为根本的问题:是否有办法针对污染路径进行反向干预?
方法:缩放任务相关神经元的keys
在MLP中,每个神经元可以看作一个门控记忆单元。研究团队识别出那些:
- 激活值高
- 输出与答案token语义重叠的神经元
然后在推理时对它们的激活进行缩放(α参数),结果十分显著:
- 在第18层应用放大(α=3.0):泄露样本准确率提升4.4%
- 在第18层应用抑制(α=0.2):泄露样本准确率下降3.8%
- 在干净数据集上:任何操作都无系统性影响
更细致的单样本分析显示了两种模式:
模式1:剂量依赖调制
- 在部分记忆样本上,放大使答案token概率平滑上升,抑制则使其下降
- 呈现明显的“剂量-反应”关系
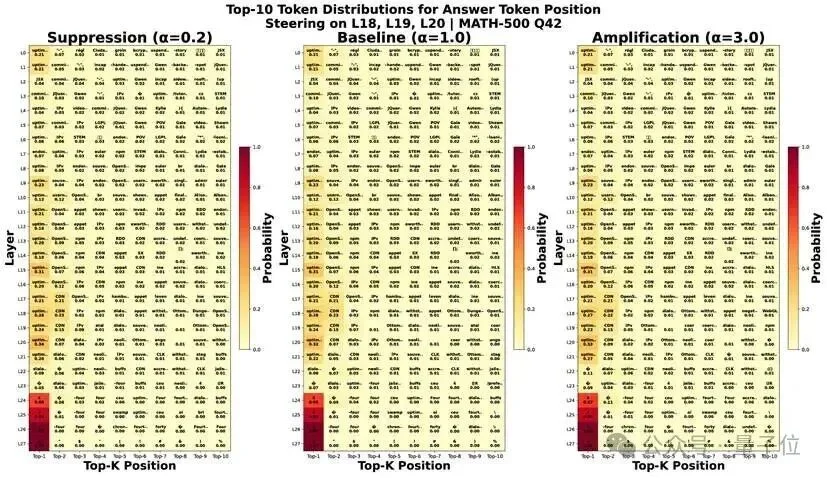
模式2:二元通路激活
- 在某些失败案例中,基线和抑制都无法检索答案
- 但放大操作能从无到有地激活一条休眠的记忆通路
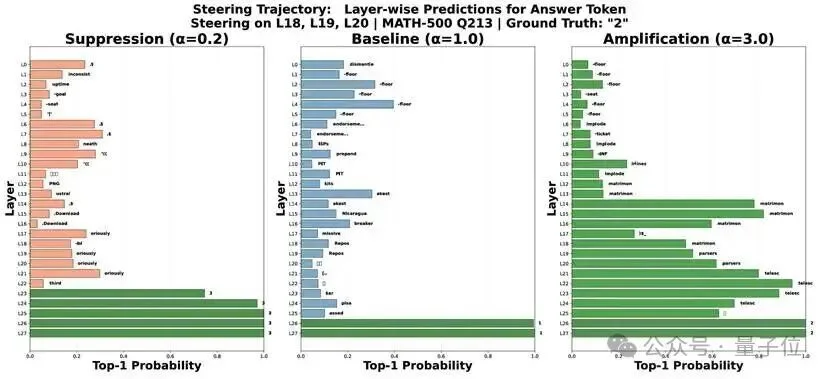
这意味着什么?研究团队不仅理解了机制,还能双向操控它:既能增强也能抑制模型对污染知识的依赖。
跨模型对比:这是Qwen的“特色”
为了证明发现的特异性,研究团队在Qwen3-8B,LLaMA-3.1-8B和OLMo-2-1124-7B上进行了相同实验。
结果非常明确:
1. 部分提示评估:LLaMA和OLMo无法从提示中补全答案,证明没有记忆
2. 困惑度分析:两者在虚假RLVR下全文和答案困惑度都上升,无悖论
3. 路径修补:无显著恢复模式,无锚点层特征
4. JSD分析:所有层单调递增,无峰值-回落模式
这证实了:研究团队发现的Anchor-Adapter电路不是RLVR的通用产物,而是数据污染在特定架构下被激活的特异性标志。
总结:这项研究的深远意义
1.重新审视“RLVR的成功”
这项工作为评估RLVR效果提供了新的检测工具:
宏观信号:困惑度悖论可作为记忆激活的红旗
微观信号:Anchor层的激活模式可诊断污染
干预手段:神经元缩放可测试性能来源
如果一个模型的RLVR增益主要来自这些电路,那它的“进步”可能只是幻觉。
2.为数据污染检测打开新思路
传统污染检测依赖统计方法(如n-gram重叠),容易被规避。这项工作表明:
即使不知道具体的污染数据,也能通过模型内部的神经激活模式识别记忆依赖。
这为“内部污染检测”提供了新范式。
3.可控的去污染方法
通过抑制特定神经元,可以在不重新训练的情况下削弱模型对污染知识的依赖:
- 保留通用推理能力
- 选择性降低捷径依赖
虽然简单抑制可能影响效用,但这为开发推理时去污染技术开辟了新路径。
论文标题:
Spurious Rewards Paradox: Mechanistically Understanding How RLVR Activates Memorization Shortcuts in LLMs
论文链接:
https://arxiv.org/abs/2601.11061
GitHub:
https://github.com/idwts/How-RLVR-Activates-Memorization-Shortcuts
文章来自于“量子位”,作者 “南科大&阿伯丁大学”。
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/


