在大模型快速迭代的背景下,语音交互正从「语音转文本(ASR)— 文本理解 — 文本转语音(TTS」的串联式架构,逐步走向端到端的实时语音生成。这一转变不仅关系到延迟和自然度,也直接影响语音系统在真实生产环境中的可用性。
在级联式语音交互架构下,每个模块分别负责语音识别、文本理解和语音合成等任务,这种架构在早期的应用中取得了成功。但随着对实时性和低延迟要求的提高,端到端语音交互系统逐渐成为主流,通过深度集成各个任务,减少中间转换步骤,显著提高响应速度,使交互变得更加即时和自然。
近期,FlashLabs 发布并开源了其实时语音模型 Chroma 1.0,其定位为全球首个开源的端到端语音到语音模型。
Chroma 1.0 发布之后,便在社媒爆火,吸引了大量的关注。X 上的官推帖子已经突破了百万浏览量。
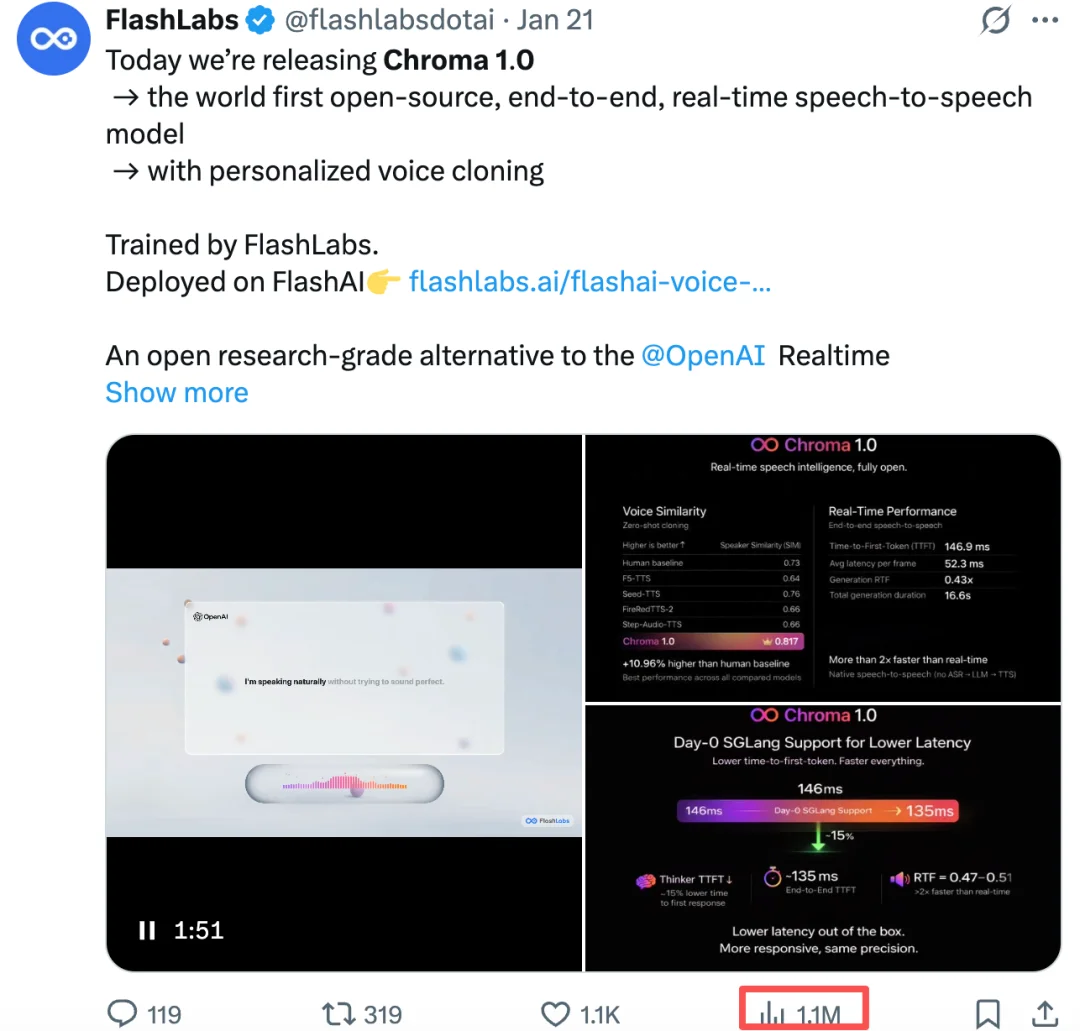
多位知名的 X 博主对 Chroma 1.0 给予了很高的评价。
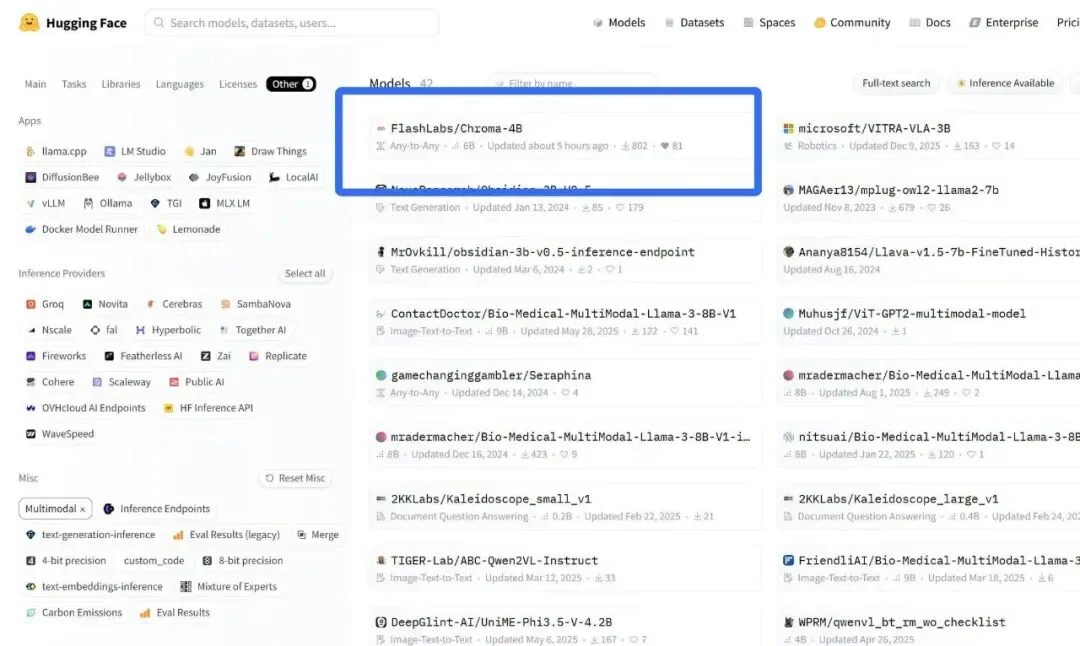
此外,在 HuggingFace 多模态榜单中,Chroma(4B 版本)排名第一。
该模型的研发负责人为 FlashLabs 创始人石一(Yi Shi):
从公开信息和技术实现来看,该模型并非对现有语音模型的简单改进,而是一次围绕「实时性」目标展开的系统级重构。
本文将依次从技术架构、核心指标、论文贡献以及应用场景等角度,对 Chroma 进行一次评测式分析,并对原文中表述不准确的地方予以修正。
一、从级联到端到端:Chroma 的系统定位
传统语音系统通常采用多阶段流水线:
ASR → LLM → TTS
这一方案在准确率上已相对成熟,但在延迟、上下文连续性以及情绪一致性方面存在天然瓶颈。尤其在实时对话场景中,多模块串联会带来显著的推理延迟与状态同步成本。
Chroma 的核心目标,是构建一个语音到语音(Speech-to-Speech, S2S)的统一系统,将语音理解、语义建模与语音生成纳入同一整体框架中,从而降低系统复杂度并提升实时响应能力。
- 官方产品页:https://www.flashlabs.ai/flashai-voice-agents
- 推理代码:https://github.com/FlashLabs-AI-Corp/FlashLabs-Chroma
- 模型:https://huggingface.co/FlashLabs/Chroma-4B
- 论文:https://arxiv.org/abs/2601.11141
二、模型架构与关键设计
1 分层架构:从理解到合成
原文中曾将 Chroma 描述为「统一 Transformer 架构同时处理语音编码、语义建模与声学解码」,这一表述并不准确。论文指出,Chroma 采用分层多模块架构:
- Reasoner:基于 Thinker 模块构建,负责多模态理解与文本生成。它使用 Qwen2-Audio 编码管道处理文本和语音输入,并通过跨模态注意力及 TM-RoPE 将语音和文本表示对齐。
- Backbone:采用约 1 B 参数的 LLaMA 变体,用于生成每一帧的粗声学码。为实现个性化克隆,Backbone 通过 CSM-1B 将参考音频及其文本编码为嵌入前缀,并共享 Reasoner 的嵌入和隐藏状态作为上下文。
- Decoder:约 100 M 参数的轻量模型,在每帧内自回归生成剩余的 Residual Vector Quantization (RVQ) 级别。这一设计减少了长上下文计算负担,细化了韵律与发音细节。
- Codec Decoder:采用 Mimi vocoder 的因果卷积网络,将粗音码与细音码串联后重建为连续波形。系统使用 8 个码书,减少解码器在每帧的自回归步骤。
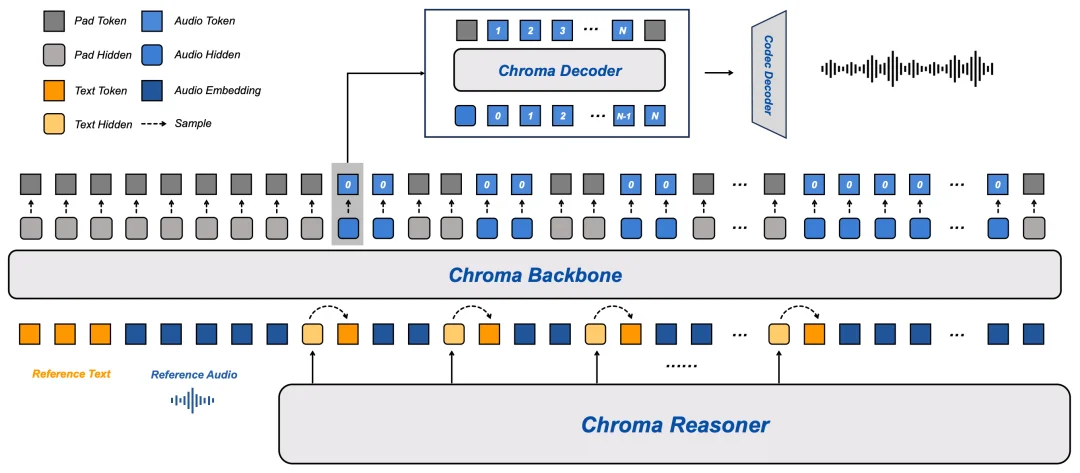
这种模块化的分层设计与原文所述的「统一 Transformer」不同,每个模块各司其职,共同完成 S2S 推理和生成。
2 交错日程与流式推理
为保证低延迟,Chroma 采用固定比例的文本 - 音频交错日程,论文中明确为 1:2(即每个文本 token 对应两个音频码)。
具体操作过程中,Reasoner 首先输出文本 tokens 和隐藏状态;这些信息按上述比例交错并输入 Backbone 和 Decoder,后者再逐步生成离散声学码并由 Codec Decoder 重建为波形。
这种管线非一步直接「映射」语音到输出,而是通过多模块间的分工协作进行联合建模,从而避免了传统级联系统中的多次模态切换带来的信息损失。
3 参数规模与效率权衡
Chroma 1.0 的模型规模约为 40 亿参数级别。相较于追求超大模型规模,其设计更强调在延迟、吞吐与可部署性之间取得平衡:
- Backbone:1 B 参数 —— 负责粗声学码生成;
- Decoder:100 M 参数 —— 负责细化 RVQ;
- Reasoner 与 Codec Decoder 规模保持相对稳定。
相较于 7 B–9 B 的大模型,该规模具有明显效率优势,同时在多项指标上优于 0.5 B 级别的小模型。
三、核心技术指标评测
根据论文与实验结果,Chroma 在多个关键指标上表现出工程优势:

需要指出的是,论文评测重点放在实时交互可用性和个性化声音克隆上,而不是单一语音自然度指标。
四、论文视角:Chroma 的研究贡献
从论文结构来看,Chroma 的研究贡献主要体现在三个层面:
- 实时语音建模范式:系统性论证了端到端 Speech-to-Speech 架构在实时对话场景中的优势,并给出了工程可行的实现路径。
- 交错策略和模块化设计:在数据表示和模型结构上引入 1:2 文本–音频交错,并将Reasoner、Backbone、Decoder、Codec Decoder 分离。这种设计既降低延迟又兼顾语义推理和声学细节。
- 合成训练管线与评价方法:采用 LLM+TTS 构建高质量的语音到语音训练数据,并通过综合的客观指标(SIM、TTFT、RTF)和主观评测(NCMOS、SCMOS)验证系统性能。
整体来看,该论文兼具工程导向和系统研究价值,而非单点算法突破。
五、FlashAI:从模型到应用的落地路径
Chroma 并非孤立模型,其首要应用场景来自 FlashLabs 的语音产品 FlashAI。在 FlashAI 中, Chroma 主要承担实时语音交互引擎的角色,典型应用包括:
企业级呼叫与客服
- 实时应答,稳定长对话;
- 多语言支持;
- 适用于呼叫中心、预约、售后等高并发场景。
AI 语音代理(Voice Agent)
- 结合知识库与业务逻辑,直接在语音层面完成任务型对话;
- 减少文本中转延迟。
跨语言语音交互
- 统一语音建模降低系统切换成本;
- 提升整体交互连贯性。
六、理性总结
综合来看,Chroma 1.0 并非追求「最强语音模型」,而是明确聚焦于实时语音交互这一长期被低估的工程难题。其价值不在于单项指标的领先,而在于:
- 将语音理解、语义建模与声学生成解耦为多模块联合设计,摆脱传统级联系统瓶颈;
- 通过 1:2 交错策略与多码书设计,将 TTFT 降至约 150 ms 并保持 RTF < 1;
- 在个性化声音克隆任务中实现对人类基线 10.96% 的相对提升,展示出对细节声纹特征的捕捉能力;
- 完整开放代码与模型,降低了研究者与工程师进入门槛。
当然,Chroma 目前在自然度评测(NCMOS)上仍落后于商业系统 ElevenLabs,在多语言及情感控制方面亦有待进一步探索。然而,作为实时语音交互的重要基础设施,其分层设计与数据生成策略为行业提供了可复用的蓝图。
通过修正原文中的架构描述和「直接映射」表述,这篇评测更准确地反映了 Chroma 的技术特点与工程取舍,有助于读者理解这一系统在实时语音交互领域的价值。
文章来自于微信公众号 “机器之心”,作者 “机器之心”
【开源免费】MockingBird是一个5秒钟即可克隆你的声音的AI项目。
项目地址:https://github.com/babysor/MockingBird
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales


