多模态大模型的研发范式,正在被彻底重构。
今天,商汤科技联合南洋理工大学发布了最新技术成果:NEO-unify。
这是一套真正实现“原生、统一、端到端”的多模态模型架构,其最核心的突破在于:
彻底砍掉了长期以来行业依赖的视觉编码器(VE)和变分自编码器(VAE)。不再通过“组件拼凑”来实现感知与生成,回归第一性原理,直接以近乎无损的像素和文字作为原生输入。
通过创新的混合变换器(Mixture-of-Transformer, MoT)架构,该模型在同一个体系内打通了视觉与语言的“理解+生成”双向能力。
技术要点一览:
这套架构的出现,标志着多模态AI正在从“模态连接”进化为“原生统一智能体”。
其无编码器、端到端、多模态统一学习的新路径,也为未来实现跨模态认知与生成一体化的智能系统奠定了基础。
长期以来,多模态研究领域普遍遵循着一种默认范式:
这种架构虽然在初期推动了领域发展,但也在感知与生成之间划下了一道天然的鸿沟。
为了弥合这一裂痕,近期业界涌现出一系列尝试构建“共享编码器”的研究工作。然而,这种折衷方案往往陷入了新的结构性设计权衡。
面对这一挑战,研究视角开始回归第一性原理:能否构建一个直接处理原生输入(即像素本身与文字本身)的一体化模型?
基于这一思考,商汤科技联合南洋理工大学提出了一种全新的架构范式:NEO-unify(preview)。
作为一个原生、统一、端到端的多模态模型架构,NEO-unify不仅越过了当前视觉表征的争论,也摆脱了预训练先验和规模定律瓶颈的限制。
最关键的是:不需要VE,也不需要VAE,NEO-unify实现了多模态处理的真正归一。
NEO-unify第一次迈向真正的端到端统一框架,能够直接从近乎无损的信息输入中学习,并由模型自身塑造内部表征空间。
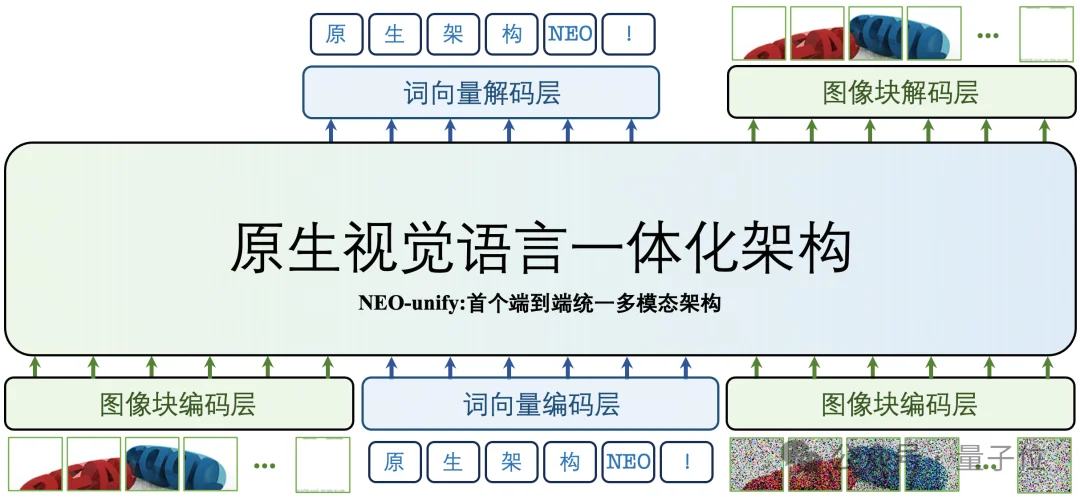
首先,引入近似无损的视觉接口,用于统一图像的输入与输出表示。
其次,采用原生混合Transformer(Mixture-of-Transformer,MoT)架构,使理解与生成能够在同一体系中协同进行。
最终,通过统一学习框架实现跨模态训练:文本采用自回归交叉熵目标,视觉通过像素流匹配进行优化。
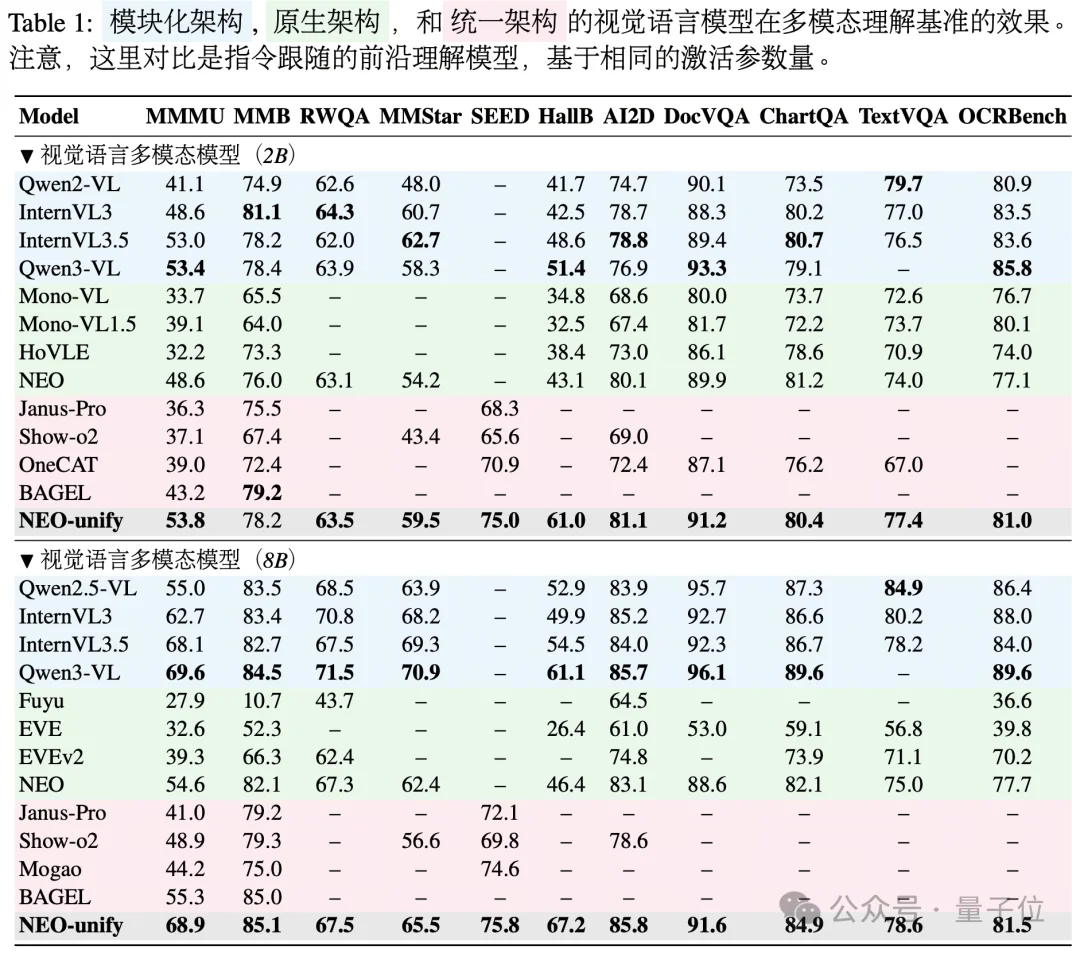


该团队先前的工作NEO(Diao et al., ICLR 2026)表明,原生端到端模型同样能够学习到丰富的语义表征。
在此基础上,他们进一步观察到一个有趣的现象:即使在冻结理解分支的情况下,独立的生成分支仍然能够从表示中抽取并恢复细粒度的视觉细节。
基于这一发现,团队训练了NEO-unify(2B)。
在初步9万步预训练后,模型在MS COCO 2017上取得31.56 PSNR和0.85 SSIM,而Flux VAE的对应指标为32.65和0.91。
这一结果表明,即使不依赖预训练VE或VAE,近似无损的原生输入仍能够同时支持高质量的语义理解与像素级细节保真。

△域外图像重建(2B NEO-unify,理解分支冻结)
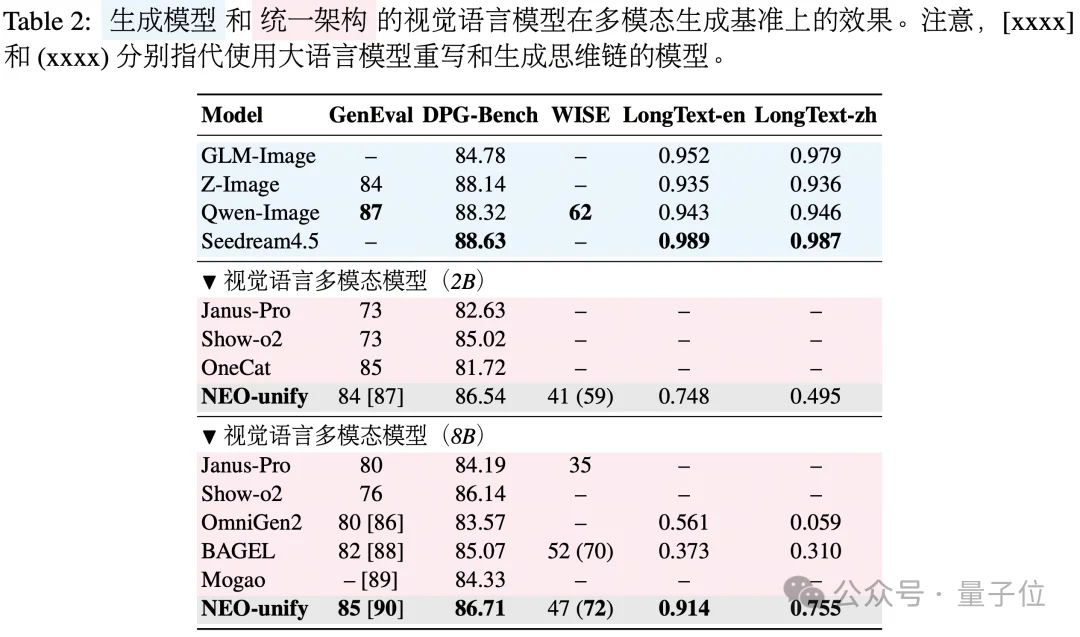
据此,团队进一步开展探索:NEO-unify将所有全模态条件信息统一输入到理解分支,而生成分支仅负责生成新的图像。
即使在冻结理解分支的情况下,NEO-unify(2B) 仍展现出强大的图像编辑能力,同时显著减少了输入图像令牌的数量。
在使用开源生成与图像编辑数据集并进行初步6万步混合训练后,模型在ImgEdit基准上取得3.32的成绩,且理解分支在整个训练过程中保持冻结。

△小规模数据验证(2B NEO-unify,理解分支冻结)

△ImgEdit提示词编辑(2B NEO-unify,理解分支冻结)
借助预训练的理解分支与生成分支,NEO-unify使用相同的中期训练(MT)与监督微调(SFT)数据进行联合训练。
即使在较低的数据比例和损失权重下,理解能力依然保持稳定,而生成能力则收敛很快。二者在MoT主干中协同提升,整体冲突极小。
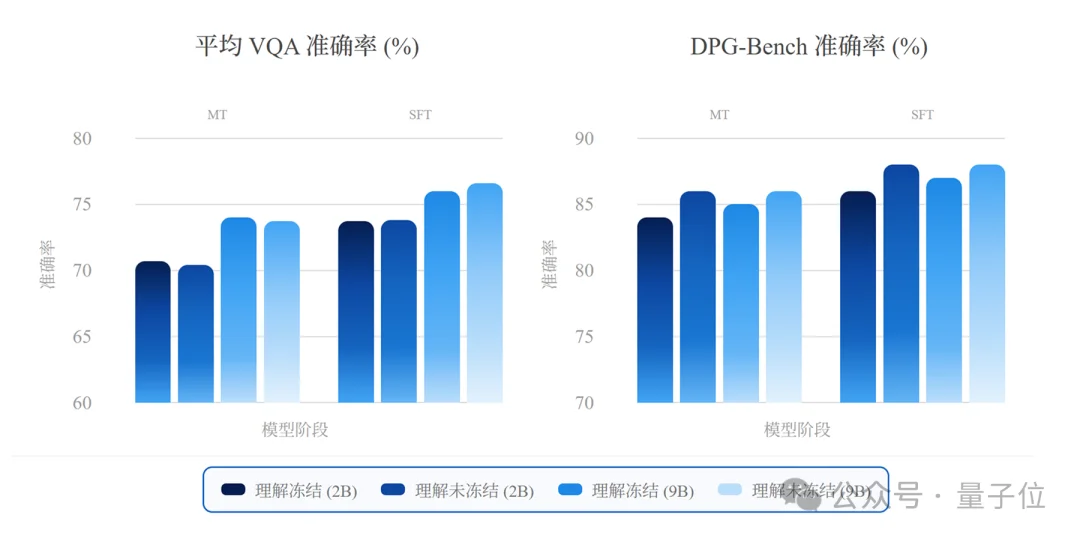
此外,团队先进行了web-scale预训练,随后在多样且高质量的数据语料上依次进行中期训练(MT) 和 监督微调(SFT)。
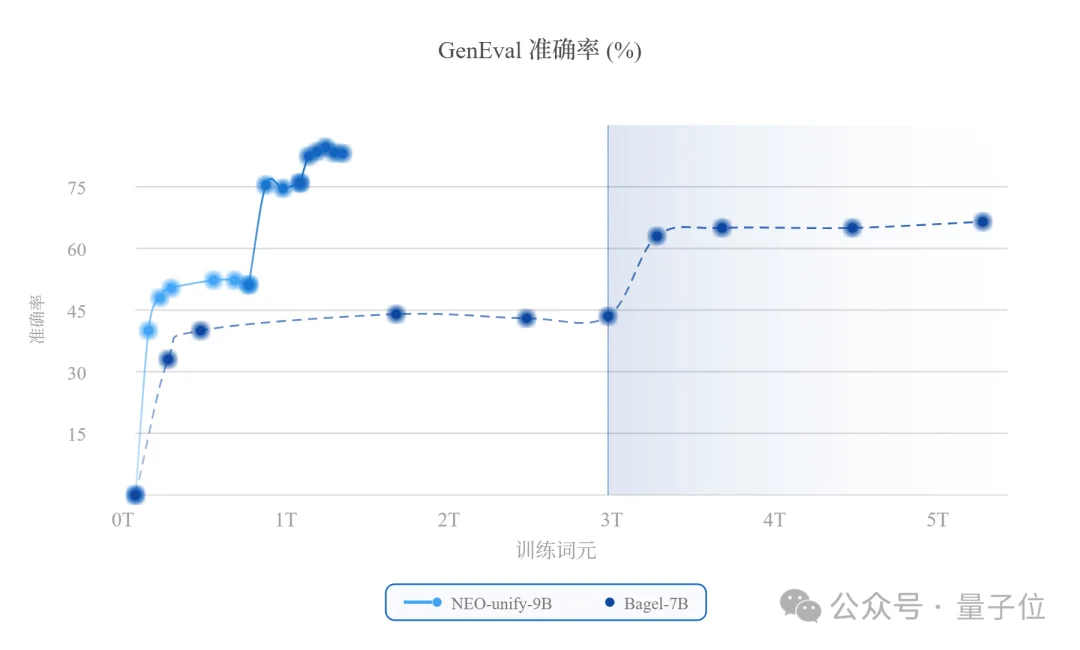
与Bagel模型相比,NEO-unify展现出更高的数据训练效率,在使用更少训练token的情况下取得了更优的性能。
NEO-unify的意义不止于一次模型架构的创新,它实际上预示着多模态智能正从“组件堆叠”迈向“本质统一”。
这种范式的演进,正在勾勒出通往下一代智能形态的清晰路径:
……
这标志着一条全新的技术路线图正在展开:
模型不再在模态之间进行转换,而是能够原生地跨模态思考。
在这一愿景下,多模态AI不再只是连接不同系统,而是构建一个从未被割裂的、高度集成的统一智能体,并让所需能力从其内部自然涌现。
据悉,目前相关的研发工作正处于规模化扩张与持续迭代的关键期。一系列基于该架构的模型成果与开源贡献,将在近期陆续向业界发布。
Hugging Face地址:
https://huggingface.co/blog/sensenova/neo-unify
官方博客地址:
https://www.sensetime.com/en/news-detail/51170542?categoryId=1072
https://www.sensetime.com/cn/news-detail/51170543?categoryId=72
文章来自于“量子位”,作者 “允中”。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


