
“我们想探索人和AI共存的社会是什么样的。”
北京时间1月13日凌晨四点,Anthropic发布AI智能协作工具Claude Cowork,AI办公自动化领域从此迎来全新时代。
Claude Cowork定位为办公领域的“Claude Code”,图片来源:Claude官网
6个小时后,X上的一条推文像一记“破壁弹”打破了AI圈子的情绪阈值:“Anthropic Claude Cowork 刚刚杀死了我们初创公司的产品——所以我们做了最理性的决定:将它开源。”
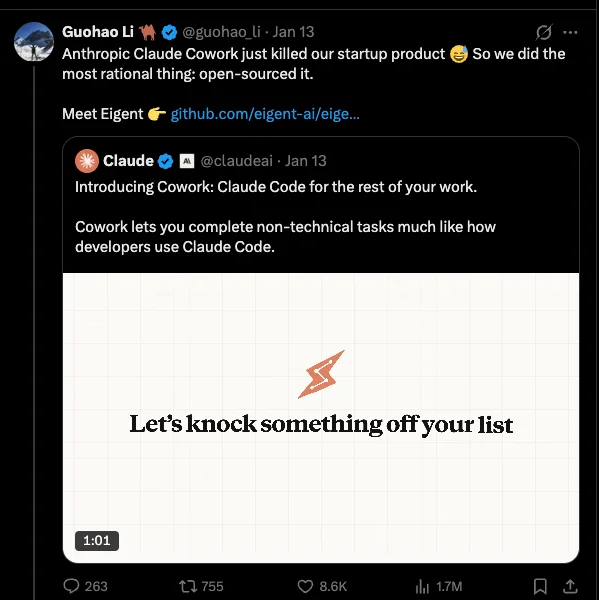
Claude Cowork发布六小时后一篇火爆X平台的推文 图片来源:X
很快,它收获了8000+点赞、180万+浏览,讨论的矛头也从Cowork转向了另一个名字:Eigent AI。
Eigent AI是一个开源多智能体(Multi-Agent)协作平台,用户可以用它在电脑上创建由多个AI Agent组成的虚拟团队。与单一的AI聊天助手不同,Eigent能够协调多个专注于不同领域的Agent(如搜索员、程序员、文档编写员)并行协作,解决复杂的长周期任务。
Eigent AI(下文简称Eigent)的背后,是CAMEL-AI开源社区,以及它的创始人李国豪。李国豪拥有阿卜杜拉国王科技大学(KAUST)计算机博士学位,曾任牛津大学Philip Torr教授课题组的博士后研究员,曾在多个顶级国际会议与期刊(如ICCV、CVPR、ICML、NeurIPS、RSS、3DV和TPAMI)上发表论文。

CAMEL AI部分成员合照,右一为李国豪。 图片来源:受访者提供
在当下的AI战局中,他扮演着一个特殊的角色——“破壁人”。
在《三体》中,破壁人看穿了面壁者深藏不露的战略意图,将那些试图以绝对封闭来掌控全局的计划公之于众,彻底击碎了思维的堡垒。而在今天的AI世界里,当OpenAI、Anthropic等顶尖团队正试图用闭源模型和斥资数亿美元买断的“训练环境”筑起高墙时,李国豪选择用“开源”来打破这堵墙。
他不仅用开源把巨头的围墙撬开一条缝,争取“智力的自由”;还在探索用多智能体把“单体智能”的天花板推到“组织级智能”。在他眼里,真正值得规模化的,不是一个能干活的智能体,而是一套能不断扩展成员、扩展环境、扩展协作边界的“智能体社会”。
“没有心智社会就没有智能。智慧从愚笨中来。”这是人工智能之父马文·明斯基在其著作《心智社会(The Society of Mind)》中的一句话,这本书也是李国豪最喜欢的书之一,深刻影响了他对AI未来的构想——李国豪坚信“Local-first(本地优先)”,认为AI是人类智力的外延,不应被少数巨头垄断,而应像PC时代的个人电脑一样,完全属于用户自己,并在多样性的“心智社会”中协作与进化。
近日,「甲子光年」与李国豪进行了一场长达两个半小时的深度对话。我们聊了聊他被巨头“逼到墙角”后的开源反击,探讨了他打破大厂“环境”垄断的破壁行动,也走进了这位曾经“沉迷游戏、差点退学”的非典型学霸的AGI狂想世界。
以下为对话实录,经「甲子光年」编辑整理。
1.直面巨头
甲子光年:1月13日,在Anthropic发布Claude Cowork之后,你第一时间发推特宣布Eigent开源,并说“Cowork杀死了我们的产品”。Eigent是怎么诞生的?产品被巨头逼到墙角,你的第一反应为什么是“开源”而不是“保密”?
李国豪:关于Eigent,最早可以追溯到我们在2023年3月份做的一个开源项目,叫CAMEL。当时 OpenAI 刚开放 API 没几天,我们在推特上发布了这个项目。那是非常早期的阶段,我们应该是世界上第一个用ChatGPT(OpenAI 的 API)来做 Multi-Agent(多智能体)系统的工作。
当时这个项目在推特上挺火的,比同期一些后来非常火的项目(比如 AutoGPT、BabyAGI,包括斯坦福小镇)可能还要早一到两个星期。项目火了之后,大概一个星期就收获了4000多个Star,后来这篇论文也被AI顶会NeurIPS 2023接收了。
慢慢地,这个项目发展成了一个开源社区,我们在社区基础上做了很多不同类型的工作。最后,我们从社区里招募了一些同学,大家聚在一起,在英国成立了现在的这家创业公司。这就是大概的来龙去脉。
CAMEL-AI简介 图片来源:Github
面对巨头的产品,我们之所以选择开源,是因为我们未来的愿景本来就是想做一个完全本地化的、甚至是可以自我进化的Agent。这需要有开源的模型、开源的框架、开源的产品,以及开源的Agent环境。
跟Cowork相比,我们最大的区别就是“完全开源、本地化”。Cowork更多是给C端用户使用的,而我们的设计理念是注重用户数据隐私,你的数据不会发送到我们的服务器。你可以完全在企业内部部署,支持任意模型的切换,不绑定任何供应商。只有所有东西都私有化部署,你才能拥有完全自主的AI。
甲子光年:你最近在X上发帖说“个人AI的未来就在本地,就在你的桌面上”。你为什么如此强调“Local-first(本地优先)”?
李国豪:我觉得我可能是一个自由主义者吧(笑)。
我认为,现在的LLM或者AI更像是你智力外延的一部分。它包含了你很多的知识、记忆和上下文。既然它是你智力的一部分,它就不应该存在于云端,不应该被某家模型公司所拥有。它应该完全属于你,你有完全的自主权去定制它、改变它,甚至随时销毁它。
从市场角度看,我们想要构建一个“AI的PC时代”。你的Intelligence应该像你的电脑一样能够随身携带。你不需要联网,充上电就能用,也不需要付token的钱。未来所有的模型和Agent都可以被本地化,你只需要下载、安装、使用。
甲子光年:你觉得这个“AI的PC时代”什么时候会到来?
李国豪:它的到来比我想象的要快。我们去年7月发布产品时,大家对“为什么要用一个桌面端的本地Agent”还没有那么强烈的感受。但今年1月Cowork火了之后,大家突然意识到我们需要一个桌面端Agent,这大大加速了市场的认知。
同时,从模型和技术层面看,开源社区的模型越来越好,离最好的闭源模型可能只有几个月的差距,而且这个差距不会被拉大,可能会慢慢追平。加上各种模型推理技术(比如vLLM等)的成熟,现在我们在MacBook Pro上部署模型和Agent,就已经能完成很多简单的自动化任务了。
甲子光年:目前Eigent的商业化闭环实现了吗?
李国豪:在今年之前,我们的商业化进展是非常慢的。但在今年1月份,我们已经实现了盈利。目前我们的客户主要来源于两个群体:一是模型公司,我们在给他们做一些环境构建;二是企业客户,我们帮IT、销售等部门解决自动化的问题,帮他们操控浏览器、完成任务。
这是一个比较标准化的产品,客单价一般在10万美元上下,主要包含产品License的费用和一部分系统集成的定制化费用。
甲子光年:作为两个成功开源项目的负责人,你觉得自己是AI开源领域的“破壁人”吗?
李国豪:我觉得还谈不上成功,然后“破壁人”可能不太合适,我不是要反对闭源路线,只是希望一个完全开源的 Agent生态应该存在。其实开源研究创业挺苦,比起去比在Frontier Labs(前沿实验室)里做研究,可能是Hard Mode(困难模式),如果硬要找一个词来形容,我觉得自己只是开源生态里的一个普通添砖人吧。
2.探索Agent的Scaling Law
甲子光年:2023年3月你们发表了CAMEL论文,提出了基于角色扮演(Role-playing)的多智能体框架。当时的灵感来自哪里?
李国豪:最早的动机来源于对AGI的思考。ChatGPT出来后验证了Model Scaling Law是work的,但我当时在想,仅仅靠模型能力的提升,能否到达AGI?在模型的ScalingLaw之后,是否存在Agent层面的ScalingLaw?
所以我们想探索人和AI共存的社会是什么样的。我们在论文里提出了“AI Society(AI社会)”的概念,就是多个Agent能够形成一个社会组织,小到两三个Agent协作,大到形成一个公司甚至社交网络。

李国豪团队在《CAMEL:Communicative Agents for “Mind” Exploration of Large Language Model Society》论文中提出了“AI Society”的概念
在这个过程中,我们让Agent相互协作、角色扮演(比如一个扮演开发者,一个扮演游戏玩家),生成了大量的数据。我们用GPT-4生成数据,再去微调像LLaMA这样的小模型,实现了很好的效果提升。
甲子光年:你提出“Scaling Laws of Agents”时,最在意的衡量指标是什么?你最不看好哪些指标?
李国豪:这是一个非常好的问题。Model Scaling有一个很好的指标,就是看损失函数(Loss)或者在Benchmark上的性能。但Agent Scaling Law很难找单一的指标。
我不太看好的指标是那些简单的学科类评测集(比如MMLU),用这种任务来衡量Multi-Agent系统是比较错误的方向。因为很多任务用一个Agent就能完成得很好了,没必要用多智能体。
我最在意的指标是:它是否解锁了新的应用场景?是否能模拟组织(Organization)甚至社会(Society)做的事情?
比如,我们能否用大规模的Agent系统去模拟X(原Twitter)或Reddit这样的社交网络?能否模拟出人类社会的规律,比如信息传播、从众效应、观点极化?如果在发布一个真实产品前,我们能用几十万个Agent去模拟市场的反馈和推演,那么这种“模拟多大规模复杂系统”的能力,才是我最在意的指标。
甲子光年:现在也有观点认为“单智能体+技能库(Skill Library)”在token和延迟上更划算。你怎么看?多智能体不可替代的部分是什么?
李国豪:多智能体在企业落地时有一个很现实的好处:权限管理和模块化。不同部门需要不同的Agent和权限。
但在技术层面,多智能体不可替代的是“大规模任务的并行”。我们支持三个维度的并行:任务拆分后的子任务并行、Worker层面的复刻并行、以及工具层面的并行。比如我们能在几分钟内并行200个任务去开发200个小游戏,这是单智能体很难做到的。

CAMEL-AI和AWS、Qwen、魔搭、SGLang、Zilliz、FishAudio等团队在上海举办的多智能体黑客松活动 图片来源:CAMEL-AI
甲子光年:你刚才提到想要探索人和AI共生的社会是什么样的,那你怎么看待斯坦福小镇和现在爆火的Moltbook?
李国豪:非常有意思。斯坦福小镇模拟的是社交行为,而CAMEL模拟的是Agent协作完成任务。我们当时其实在思考同一个事情:在非常大规模的Agent社会里,会诞生什么有意思的现象。

斯坦福小镇实验论文《Generative Agents: Interactive Simulacra of Human Behavior》
Moltbook出现的时间点是Agent能力变得更强了,它真的能操控你的电脑了。但我觉得它目前更多是输出了情绪价值,还没有产生很多Economic(经济)的影响。
Moltbook是一个专为人工智能代理设计的互联网论坛。它由企业家Matt Schlicht于2026年1月推出图片来源:Fortune
我们人类社会是有信任系统的,比如你有简历、学历、信用卡,外界才能了解你,社会才能运作。但现在的Agent模拟沙盒还没有这样的信任系统和经济系统。未来这个事情需要存在,比如我想看病,我就能通过信任系统知道该找哪些Agent去做。
甲子光年:在Agent的规划(Planning)和记忆(Memory)方面,有哪些值得期待的研究方向?你更相信长上下文还是外部记忆系统?
李国豪:这两者会同时存在。长上下文是训练阶段解锁的基础能力,每个人都需要长上下文的Model。但它是一个通用的能力。
而模型外挂的Memory里,能够实现更多Personalized(个性化)的信息。未来的方向是如何在Continuous Learning(持续学习)阶段做好Agent。比如自动学到你的奖励函数(Reward Function),根据你的Feedback学到你的价值是什么,在持续使用的过程中实现Planning和Memory能力的个性化提升。
3.得环境者得天下
甲子光年:你们最近开源了400多个Terminal Agent的训练环境SETA。请问你们发布的目的是什么?能否详细介绍一下SETA这个项目?
李国豪:SETA是我们正在做的一个项目,目的是让Agent学会去使用Terminal(命令行终端)。目前在这个领域,有一个名为Terminal Bench的基准测试(Benchmark),被OpenAI等头部模型公司用来评估Agent使用Terminal的能力。但这个Benchmark的数据量很少,大概只有不到100条。
目前开源领域非常缺乏用于训练Agent使用Terminal的数据环境。所以我们做的事情,就是研究如何去扩大(Scale up)这种环境的构建规模。我们提出了一种自动化的Pipeline,能够根据一些种子数据(比如论坛里的QA问答),自动构建出Docker环境。在这个环境里,Agent可以使用命令行来解决实际任务。
上次发布时我们开源了400多条环境,2月初我们又发布了1000条,所以现在总计有将近1400条训练环境。
甲子光年:我可以把“环境”直接理解为“训练数据”吗?
李国豪:可以这么理解,环境就是Agent的训练数据。
传统语言模型的训练数据通常是纯文本(输入输出都是文本)。但Agent的训练数据不同,Agent需要与数字世界或物理世界进行交互。比如操控一个网页、操控一部手机、操控一台电脑,这些都是“环境”。它包含了很多非自然语言的部分。
Agent在强化学习阶段,环境可以给它提供奖励(Reward)来优化策略(Policy);或者环境能够产生大量的交互轨迹(Trajectories),这些轨迹可以被用于语言模型的预训练(Pre-training)或中继训练(Mid-training)阶段。
甲子光年:你之前发帖说“Frontier labs spend millions purchasing RL environments(前沿实验室花费数百万美元购买强化学习环境)”。为什么“环境”在你心里比“模型/代码”更值得Scale?
李国豪:语言模型的训练数据主要是文本,天然存在于互联网上。但Agent的训练数据是“环境”。Agent需要跟数字世界或物理世界交互,比如操控网页、手机、电脑,这些轨迹在互联网上是不存在的。
你要训练Agent,就必须构建环境、设定任务、并配备验证器(Verifier)来判断Agent做得对不对。这就导致构建环境非常难,且极其昂贵。据我所知,很多大厂买一个高质量环境的预算都在几万到百万美元级别。
为什么CodingAgent(如Devin、Cursor)能做得这么好?因为代码环境最容易构建,GitHub上有天然的Issue、PullRequest和单元测试(天然的Verifier)。但如果Agent要泛化到其他企业服务或日常场景,环境构建的成本是极高的,价格范围大概在几万美元到上百万美元之间。它的成本和价格主要取决于以下几个构成部分:
第一,沙盒的逼真程度与数据量。比如你要克隆一个Airbnb的网页,里面挂载1万条民宿数据和挂载100万条数据,价格是完全不一样的。
第二,任务的构建难度。有了沙盒和数据后,什么样的任务对提升Agent能力真正有用?比如设定一个任务:“在纽约预订一个200刀左右、适合开学术会议的房间”,设计这种高质量任务本身就需要成本。
第三,验证器(Verifier)的开发。这是最难的地方——如何通过代码去自动验证Agent是否真的找到了符合条件的好房间?通常任务和配套的Verifier是打包在一起售卖的。
所以,环境的价格是由沙盒的逼真度、底层数据量、任务的难度以及验证器的复杂性共同决定的。
甲子光年:既然环境这么贵,是核心护城河,你们为什么还要开源?
李国豪:主要有以下几个角度的原因:
第一,反哺产品。我们的产品中一个很重要的部分,就是让Agent使用Terminal来写脚本、完成代码任务(如数据分析、电脑操控等)。为了让我们的产品变得更好,我们需要构建更多这样的训练数据。
第二,繁荣开源生态。我们希望开源领域能有更多这类数据出现,从而让开源模型变得更强。实际上,我们这批数据已经被用于一些开源模型的训练了,比如阶跃星辰的朋友就和我们交流过,他们正在使用我们的数据训练模型。
第三,商业化展示。我们同时也在做这方面的商业化,为大模型公司构建训练环境。开源这些环境,也是向大家展示我们在环境构建方面的能力,建立信任。
第四,建设社区。扩大(Scaleup)环境规模是一件极其困难且昂贵的事情,单靠我们一家小公司和社区是做不完的。我们希望通过开源,吸引更多有相同愿景的爱好者加入我们,或者启发其他团队跟进。只有这样,开源模型才会更好,我们产品能用到的底层模型才会更强,最终才有可能实现我们所想象的——完全个性化、本地化的Agent的存在。
甲子光年:所以你认为“环境规模”是Terminal Agents的关键瓶颈。同理类比大语言模型,训练数据越多,Scaling效应越明显,这又回归到了你之前提到的Agent Scaling Law?
李国豪:对的。我们定义的Agent场景分为三个维度:一是Agent的数量与规模,二是环境的构建与复杂性,三是自我演进。环境是Agent Scaling Law里非常重要的一部分。
但它和传统模型数据最大的区别在于:适合Agent使用的环境,在互联网上并不是天然存在的。
比如,如何操控浏览器或手机来完成一个任务,这种交互轨迹在互联网上是没有现成答案的(不像数学推理题在教科书里有答案)。这就导致构建它非常困难。为了实现Scaling,我们必须去主动构建这些环境,包括设定任务、搭建沙盒,以及开发能够验证Agent做得对不对的验证器(Verifier)。
甲子光年:这里可能有个误区,比如我们要训练Agent去操控网页订酒店,Booking这样的真实网站不是天然存在于互联网上吗?为什么不能直接用?
李国豪:真实网站确实存在,但它非常不适合用来做Agent训练。
首先是现实因素,真实网站通常会把你的Agent当作机器人拦截(Block)掉。
其次,真实网站无法进行状态的回溯(Rollback)或分支(Branching),而且充满随机性。这极大地局限了Agent的训练。
所以在构建Agent环境时,我们通常会去完全复刻一个网页,让研究人员拥有完全的控制权(包括控制前后端和数据库),能够自由地做分支和回溯。只有具备这种灵活度,才能高效地训练Agent。
甲子光年:你提到的Agent训练方法很类似强化学习,你是一个强化学习方法的信仰者吗?怎么避免RL训练在开源社区里走向“刷榜/拼算力”的局面?
李国豪:我开始做AI的时候,确实是因为看到了强化学习在打游戏、下围棋上的厉害之处,但我并不是任意一种方法的狂热信仰者。我更多是从解决问题的角度出发。
现在环境最大的用途确实是被用来做强化学习,但也许到了2026年我们会发现,环境最大的用途并不是强化学习。这些环境同时也能被用在Agent的Pre-training(预训练)或Mid-training(中继训练)阶段。我们可以根据环境大规模并行,构建大规模的Agent轨迹,这些轨迹甚至可以是非常rough(粗糙)的,不一定要在强化学习阶段去使用。
4.非典型学霸的AGI狂想
甲子光年:聊聊你个人吧。看你的履历,本科是哈尔滨工业大学电子信息工程专业,后来去了沙特阿卜杜拉国王科技大学(KAUST)读博。为什么会有这样的路径选择?
李国豪:其实我从小到大一直是个好奇心很重的人,但在做AI研究之前,我一直没有找到具体的目标。我本科的时候天天沉迷网络游戏,逃课、挂科,绩点非常低,3.0都不到,差点被退学。
后来读研接触到AI,发现强化学习可以用来打游戏,甚至能造出一个比我打得还好的AI,我突然觉得这事太有意思了。再后来我觉得,实现AGI可能比打游戏还有意思。这是我人生中第一次找到想要坚持努力的方向。
决定读博时已经很晚了,因为绩点太低,很多学校申请不了。机缘巧合下我去了沙特KAUST访问,遇到了非常好的导师。而且KAUST的资源极其丰富,奖学金高、住别墅,最关键的是算力充足——我当时一个人就能用几十张甚至上百张A100卡,这在其他地方是不可能实现的。
甲子光年:你的研究兴趣从强化学习、图神经网络,一路演进到大语言模型和Agent。为什么会发生这样的转变?
李国豪:最开始做AI的时候,我研究的是强化学习(RL),主要落地在无人驾驶和无人机领域。但我发现一个问题:强化学习Agent往往只能在单一领域训练和使用,极难泛化。比如训练一个赛车Agent,它甚至需要同一张地图才能表现好,更不可能让它去泛化到操控无人机。
那是2017、2018年左右,我认为当时的瓶颈不在于强化学习算法本身,而在于基础的神经网络架构和表征学习没做好。因此,我的研究方向发生了第一次转变——去探索什么样的新型神经网络架构能更好地泛化、解决跨领域问题。我当时认为图神经网络(GNN)可能是通向AGI的一个重要方向,因为它可以对各种领域的问题进行建模,比如分子药物结构、蛋白质结构、人类社交网络等。同时,我也在做NAS(网络架构搜索)和AutoML相关的自动网络架构设计研究。
转向大语言模型和Agent是因为中间有个插曲。我在ETH(苏黎世联邦理工学院)做过一个关于Robot Learning(机器人学习)的项目,研究如何让Agent在未知空间里做目标导航(Object Navigation)。在2020年左右,我发现可以用语言模型来很好地预测物理空间中物体的存在性和距离,从而指导机器人导航。这在我脑海里埋下了一颗种子:语言模型在解决泛化性问题上有巨大的潜力。
后来,模型架构迎来了“大一统”,无论是视觉、图神经网络还是语言模型领域,大家都在用Transformer。在ChatGPT问世的那一瞬间,我突然意识到,Transformer这种大一统的架构,让我们重新看到了实现通用Agent的可能性。它一定程度上解决了我最初想探索的“什么样的神经网络架构和表征学习能让模型具备理解世界的能力”这个问题。有了理解世界的能力,才能解决Agent如何行动的问题。
所以,我的路线大概是:一开始读博相信强化学习能通向AGI——发现表征学习是瓶颈,转向图神经网络模型架构——大一统和ChatGPT出现后,发现语言模型的泛化能力解决了基础问题——再次切换方向,回归到做基于大语言模型的Agent。
甲子光年:你现在怎么看大语言模型的Transformer架构?它会是一统天下的终极解吗?
李国豪:Transformer最大的问题还是效率,它在神经网络里没有记忆,导致推理时上下文不断增加,成本极高。
我觉得如果未来真的存在范式级的变化,那它必须是“超越神经网络范畴”的。
举个例子,我想象中的一种新架构是:在预训练阶段,Agent不仅有神经网络的大脑,还有非神经网络的“身体”(比如它能操控的CPU、Memory、操作系统)。在训练过程中,Agent能否构建出自己的系统内核?基于这个内核,它自己写编译器、写软件、自己接入互联网。
这种“神经网络+符号系统/计算系统”的、可以自我学习和演进的系统,才可能带来真正的范式变化。仅仅魔改神经网络架构,是远远不够的。
甲子光年:最后一个问题,你最喜欢的一本书是什么?
李国豪:对我做CAMEL启发最大的是马文·明斯基的《The Society of Mind》(心智社会)。
这本书非常深入地剖析了人类智能是怎么来的。它里面有一个核心观点:人类的智能来源于多样性(Diversity)。
未来的Agent社会其实也一样。我们如何让Agent进化?如何跟人类协作?如何拥有个性化的Agent?这都需要多样性。这本书里关于记忆系统、长思维链(Long-CoT)、Agent通讯、甚至世界模型的讨论,在今天看来都极具预见性。我非常推荐所有做AI Agent的人去读一读。
文章来自于“甲子光年”,作者 “王艺”。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

