多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。
然而,在真实世界中,一个关键问题几乎不可避免:「模态缺失(Missing Modality)」。例如:医学诊断中,部分检查未完成;自动驾驶中,某些传感器失效;多模态数据库中,部分字段缺失。
现有的不完整多模态学习方法通常采取两种策略,要么直接丢弃缺失模态(无恢复方法,recovery-free),从而可能损失重要的任务相关信息;要么尝试恢复缺失模态(recovery-based,基于恢复方法),但这又可能引入无关噪声。我们将这一矛盾称为「丢弃 - 插补困境」(discarding-imputation dilemma)。
为了解决这一问题,帝国理工大学的研究团队引入一个全新的视角:不盲目丢弃,也不盲目使用恢复模态,而是在推理时动态识别并融合可靠的恢复模态,突破传统「丢弃或插补」的二元限制。为此,作者设计了一种新的推理阶段动态模态选择框架 DyMo。
DyMo 从信息论的角度出发,理论性地建立信息量和任务损失之间的联系,提出用于指导模态选择过程的奖励函数。此外,作者还设计了一种灵活的多模态网络结构,可兼容任意模态组合,并配套提出了专门的训练策略,以学习鲁棒的多模态表示。在多个自然图像与医学影像数据集上的实验表明,DyMo 在各种模态缺失场景下均显著优于现有方法。该工作已被机器学习顶级会议 ICLR 2026 接收。

针对模态缺失问题,现有方法主要分为两类:
但在现实场景中,不同模态对任务的重要性往往存在显著差异。这种差异主要来源于:(i)各模态包含的任务相关信息强度不同,(ii)各模态中包含的噪声程度不同。
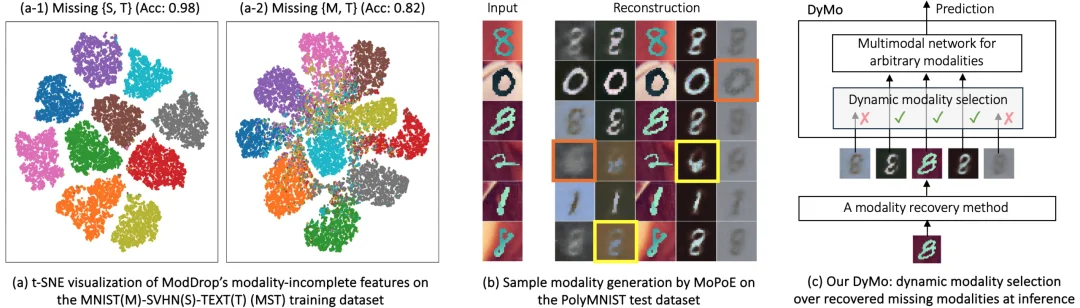
图 1。(a–b) “丢弃–插补困境” 的直观证据:(a-1) vs (a-2) 无恢复方法(recovery-free methods)由于直接忽略缺失但高度任务相关的模态(如 {M, T}),只能学习到判别能力较弱的特征表示;(b) 基于恢复的方法(recovery-based methods)产生不可靠的重建结果,例如低保真重建(橙色)或语义错位(黄色)。(c) DyMo 能够通过动态融合任务相关且可靠的恢复模态来有效解决这一困境,并在多个数据集上显著提升性能:如在 PolyMNIST、MST 和 CelebA 数据集上,分类准确率分别提高了 1.61%、1.68% 和 3.88%(见论文表 1)。
当高度关键的模态缺失时,传统的无需恢复方法只能依赖剩余信息较弱的模态,从而导致模型判别能力下降 (如图 1(a))。虽然恢复方法试图通过重建缺失模态来解决这一问题,但恢复质量往往不稳定(如图 1(b)),可能生成低保真恢复(low-fidelity),即图像模糊或失真,或者语义错位(semantic misalignment):恢复内容与真实标签不一致。将这些不可靠模态用于融合,反而会引入与任务无关的噪声,干扰模型决策。
围绕「丢弃–插补困境」,作者提出了一种全新的解决思路 —— DyMo:一种推理阶段动态模态选择框架。其核心思想不是简单「丢弃」或「强行恢复」,而是在推理阶段自适应地选择并融合可靠的恢复模态,最大化多模态任务相关信息(图 1(c))。文章具体贡献如下:
支持任意模态组合的网络架构
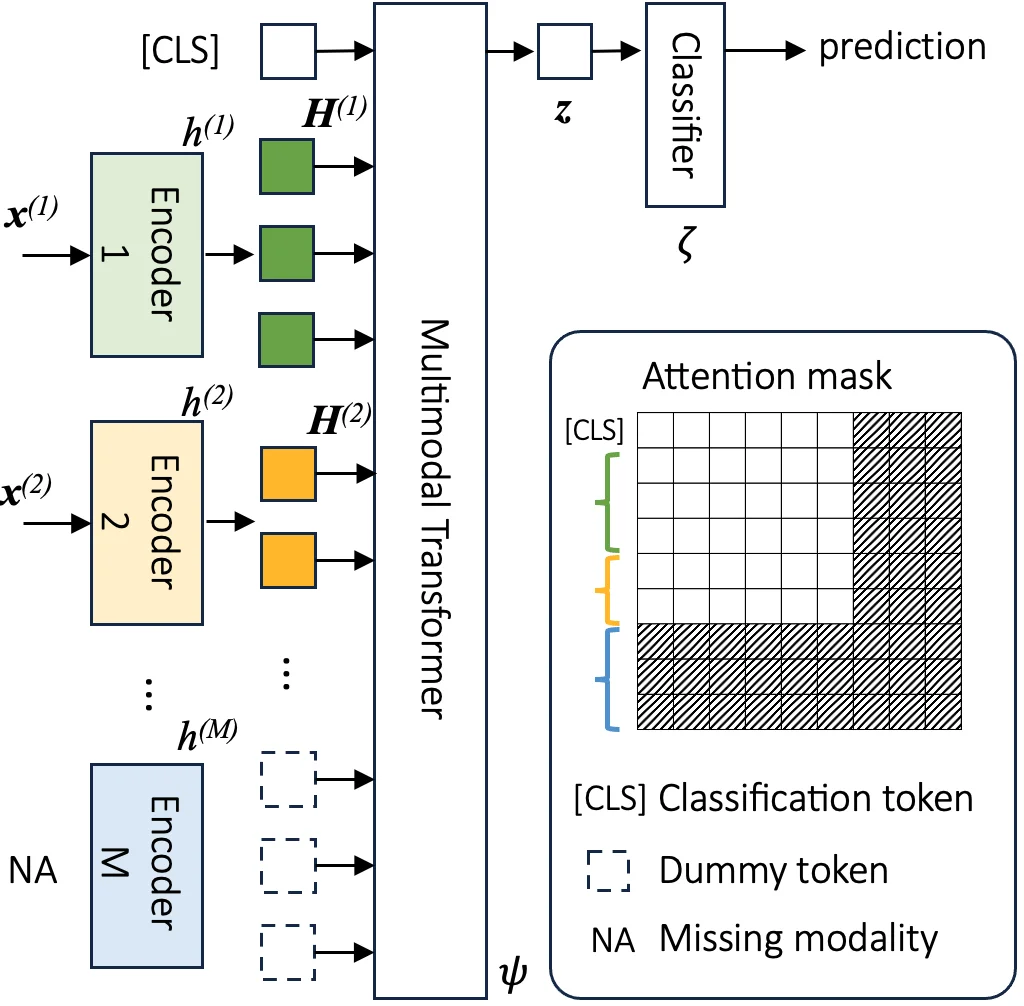
图 2。用于任意模态的多模态网络结构。
DyMo 多模态网络结构的目标是:无论输入模态是否完整,都能生成可靠的预测结果,并为后续的动态模态选择提供基础。整体架构主要由三个部分组成:单模态编码器进行特征提取;多模态 Transformer 建模跨模态关系;线性分类器使用 [CLS] token 的表示进行预测。
方法核心:推理阶段动态模态选择与融合
1. MTIR (multimodal task-relevant information reward)多模态任务相关信息奖励: DyMo 的核心是一个奖励函数: MTIR,用于估计每一个恢复模态带来的多模态任务相关信息增益。更直观的说:

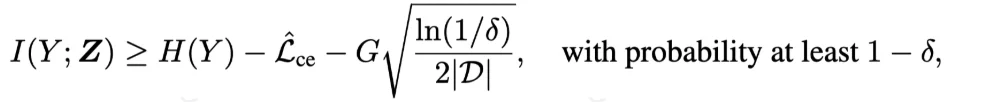
从该公式中,可以得到一个关键的结论:降低任务损失,能够提高任务相关信息的下界,因此,DyMo 使用一个简单但有效的 proxy:
用交叉熵损失的下降来估计任务相关信息增益

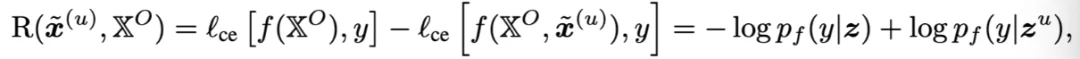

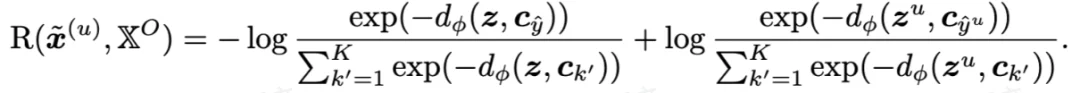


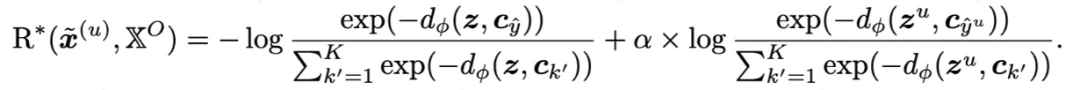

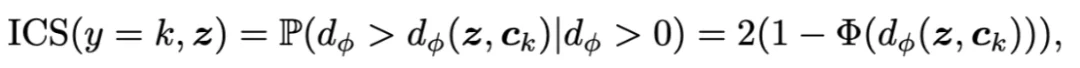

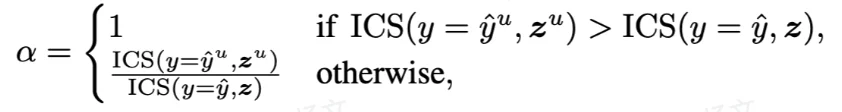

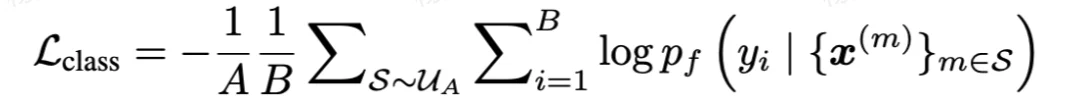
辅助缺失不可知对比损失:旨在进一步增强类内聚类和类间分离。
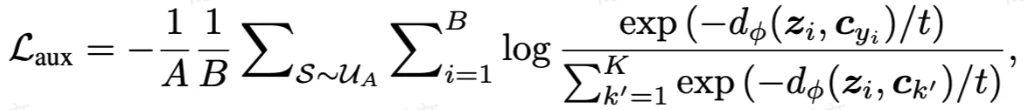

作者使用 5 个不同的数据集(包含图像,文本,表格模态)进行实验,包括三个模拟数据集:PolyMNIST, MST, CelebA,和两个大的真实数据集:自然图像 - 表格数据集 DVM 和医学图像 - 表格数据集 UK Biobank (UKBB)。
对于 DyMo 中的恢复方法,三个模拟数据集使用 VAE 类方法,两个真实数据集使用 MAE 类方法。在消融实验部分作者还包含了更多的恢复方法。模型在完整的数据集上进行训练,并在各种缺失场景下进行评估:(i)对于 PolyMNIST,作者设置随机缺失一定比例的模态; (ii) 对于 MST 和 CelebA,作者测试了缺失模式的不同组合; (iii) 对于 DVM 和 UKBB,作者评估了全表格和表格内(即模态内)缺失。
DyMo 超越过去的先进模型
DyMo 与先进的动态 / 静态模态融合方法,基于恢复的方法,和无恢复方法进行比较。实验结果表明,DyMo 在缺失模态场景下实现了巨大的性能飞跃,特别是在严重模态缺失场景。比如,在 PolyMNIST 数据集上,当 80% 模态缺失时,DyMo 相比最先进动态融合方法,准确率提升高达 13.12%,展现出极强的鲁棒性。
此外,实验还显示了「丢弃 - 插补困境」的存在:(1)无恢复方法在高度任务相关模态缺失时会出现显著性能下降。例如,在 MST 数据集上,当缺失模态为 {M, T} 而非 {S, T} 时,MUSE 的分类准确率下降了高达 61.18%。(2)基于恢复的方法在严重模态缺失场景下同样面临挑战。例如,在 PolyMNIST 数据集上,当缺失率从 η = 0 增加到 η = 0.8 时,OnlineMAE 的准确率下降了 9.91%,表明恢复过程中生成了不可靠的模态。相比现有方法,DyMo 能够有效突破这一困境,在各种严重模态缺失场景下均取得显著性能优势。
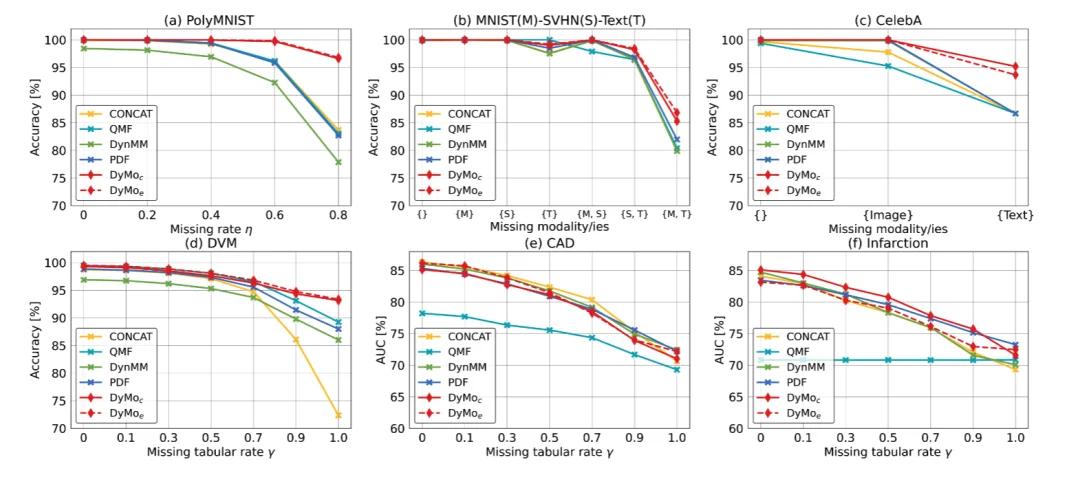
图 3。和静态 / 动态模态融合方法比较。
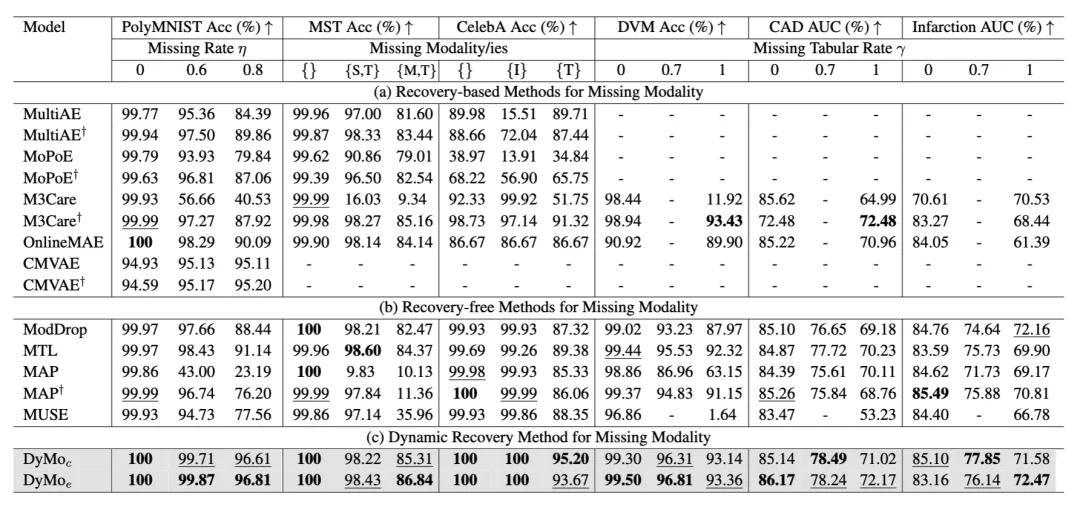
图 4。和无恢复方法,基于恢复方法比较。
可视化与样例分析
作者的隐层特征表示可视化和样例分析展示了 DyMo 能够有效选择可靠的恢复模态,并提升模型性能。

图 5。DyMo 在 MST 数据集上的隐层特征表示 t-SNE 可视化,对比了不同模态使用策略的效果:(a-1) 仅使用原始可观测模态;(a-2) 直接融合所有恢复模态(不加筛选);(a-3) 融合由 DyMo 自动选择的恢复模态。

图 6。PolyMNIST 数据集上的案例分析:黄色表示原始可观测模态,蓝色表示由 DyMo 自动选择用于融合的模态。
DyMo 提供了一个新的视角,问题不再是「如何恢复所有模态」,而是「哪些恢复模态值得信任」。
通过在推理阶段动态选择可靠模态,DyMo 成功突破了传统「丢弃或插补」的二元限制,为不完整多模态学习提供了一种更加灵活和鲁棒的解决方案。
未来方向:
文章来自于“机器之心”,作者 “杜思逸”。
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT


