LLM推理已经顶尖,精确计算却跟不上。
这局怎么破?
卡帕西点赞的解决方法来了,在大模型内部构建一台原生计算机。

新方法不搞外包那一套(不依赖任何外部工具),直接在Transformer权重里内嵌可执行程序。
并通过创新的2维注意力头设计,将大模型的推理效率提升至指数级。
能在普通CPU上实现每秒3万+Token的流式输出。
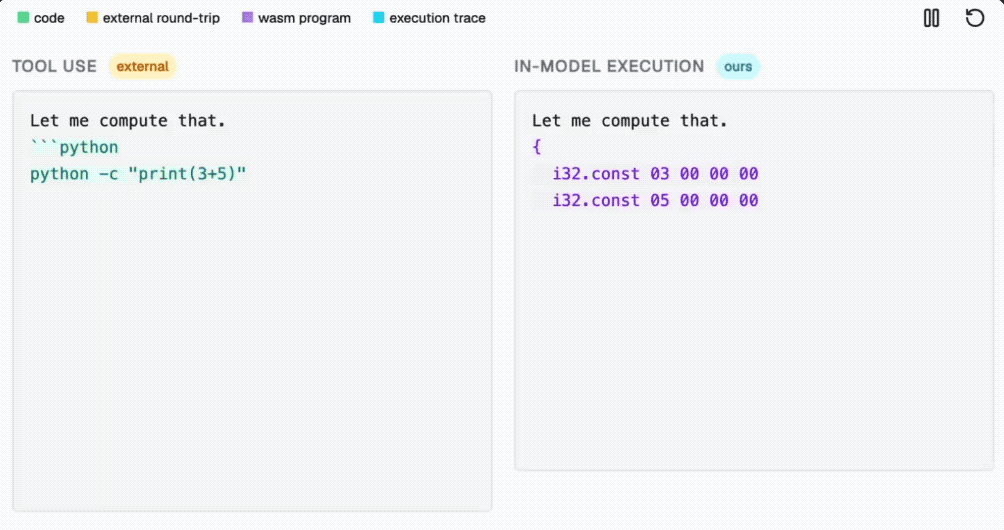
在Transformer内嵌原生计算机
咱都知道,当前最先进的大模型,拿下奥赛金牌已经不足为奇了。
甚至有些还能挑战人类还未解决的数学问题与科学问题。
但有一个始终无法回避的现实是,这些模型在需要多步骤、长上下文的精确计算任务中,仍然表现惨淡。
为了弥补这个短板,现在行业上有两种主流的解决方案。
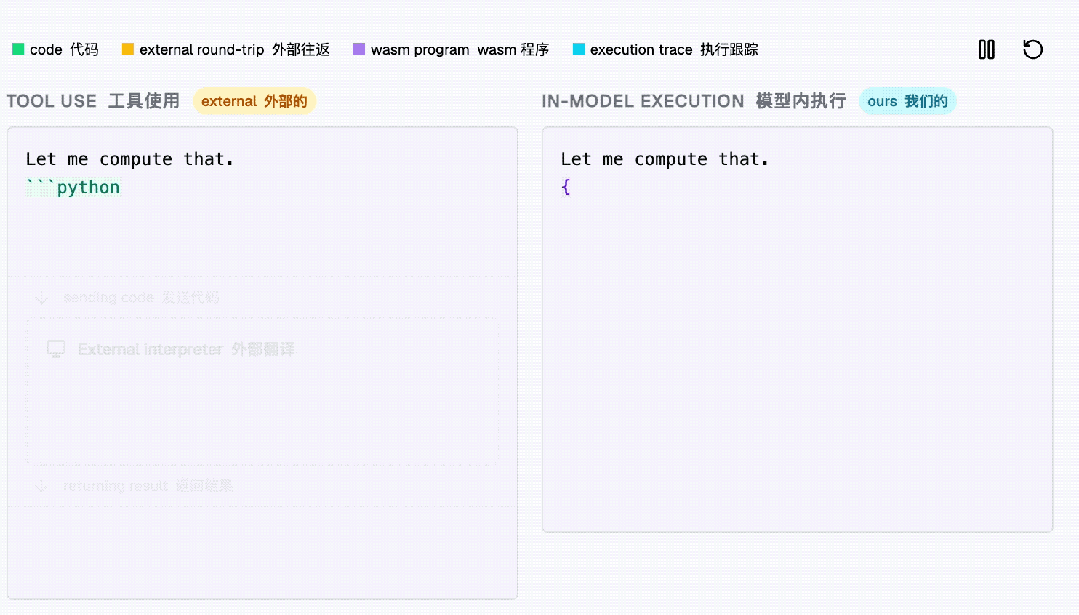
一是工具调用,让模型生成脚本,由外部沙箱解释器执行后返回结果;
二是智能体调度,通过外部状态机拆分计算任务,循环调用模型处理上下文。
但这两种方式的本质,都是给模型开“外挂”,把计算能力挂靠在外部。
标准Transformer的自回归解码,更是让这一问题雪上加霜——
每生成一个Token,模型都要对全量历史序列进行注意力扫描,计算代价随序列长度线性增长,让长轨迹的精确计算不可行。

Percepta团队的新研究,就跳出了外挂思路,直接让Transformer当计算机。
首先,他们在Transformer权重中实现了一套现代化RAM计算机与WebAssembly解释器。
WebAssembly可以理解成一种特别快、特别稳定的底层机器指令,C、C++这些编程语言写完的代码,都能编译成它。
有了这个解释器意味着任意标准化的程序代码,都能被编译为模型可识别的Token指令序列。
比如,要计算3+5,模型会先这样写:
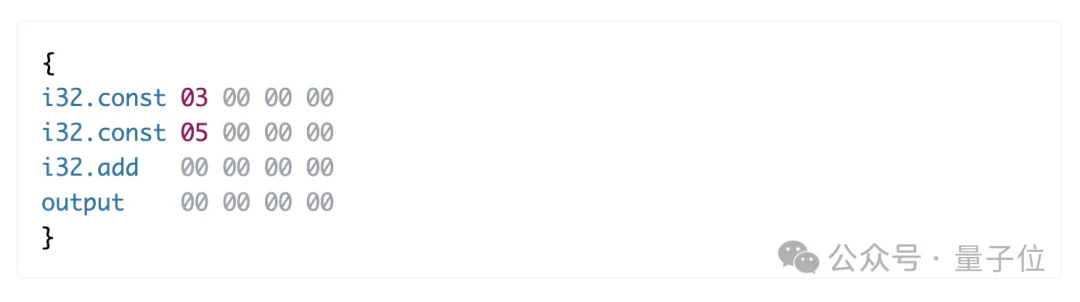
然后切换到快速解码模式,在Transformer内部一步步把这段程序跑完,同时把执行过程按行输出成一串标记:

计算结果直接在模型的Token输出流中生成,不需要再等外部工具返回结果,而且全程透明。
这种透明性,也让模型的计算过程从黑箱(外部依赖)变成白盒,实现了计算的可验证性。
内置计算机有了,怎么提高效率呢?
对这个问题,团队进行了2维注意力头的创新设计。
在2维注意力头的设计中,每个历史Token的Key向量都是二维的,当前步骤的Query向量则可视为二维平面上的一个方向。
此时,注意力查询的核心问题找到与Query最匹配的Key,就转化为了计算几何中的凸包极值查询,也就是在二维平面的凸包上,找到沿Query方向最远的点。
借助凸包数据结构,模型可以在生成Token的过程中,动态维护历史Key的凸包,每一步的注意力查询只需在凸包上进行。
这让计算复杂度从O (n) 降至O (log n)。
研究团队基于这一原理设计了HullKVCache。
该缓存在普通CPU上实现了31037 Token/秒的吞吐量,完成约9000行指令序列仅需1.3秒,效率较传统KV缓存提升了近200倍。
而且,该设计完全基于标准PyTorch Transformer,不需要定制内核或稀疏掩码,通过简单配置维度与注意力头数就能实现。
最难数独100%精确求解
团队选取了两个典型的长程精确计算任务来验证这套方法。
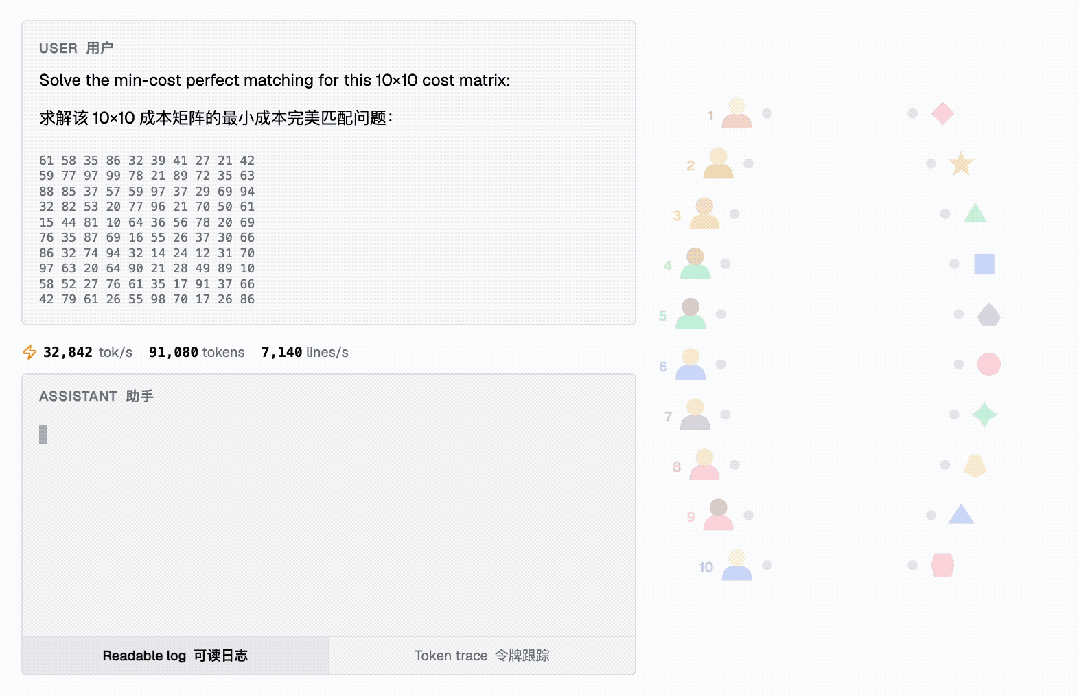
这两个实际任务是10×10最小代价完美匹配和公认的世界最难数独Arto Inkala。
在10×10最小代价完美匹配任务中,模型内部执行匈牙利算法,全程以自回归方式生成计算轨迹。
从行分配、Dijkstra算法求解,到对偶变量更新、增广路径查找,每一步的计算过程与代价累积都清晰记录,最终精准求解出最优匹配方案。
整个过程在CPU上完成,Token生成速度达到33583 Token/秒,7301行/秒的指令输出效率。
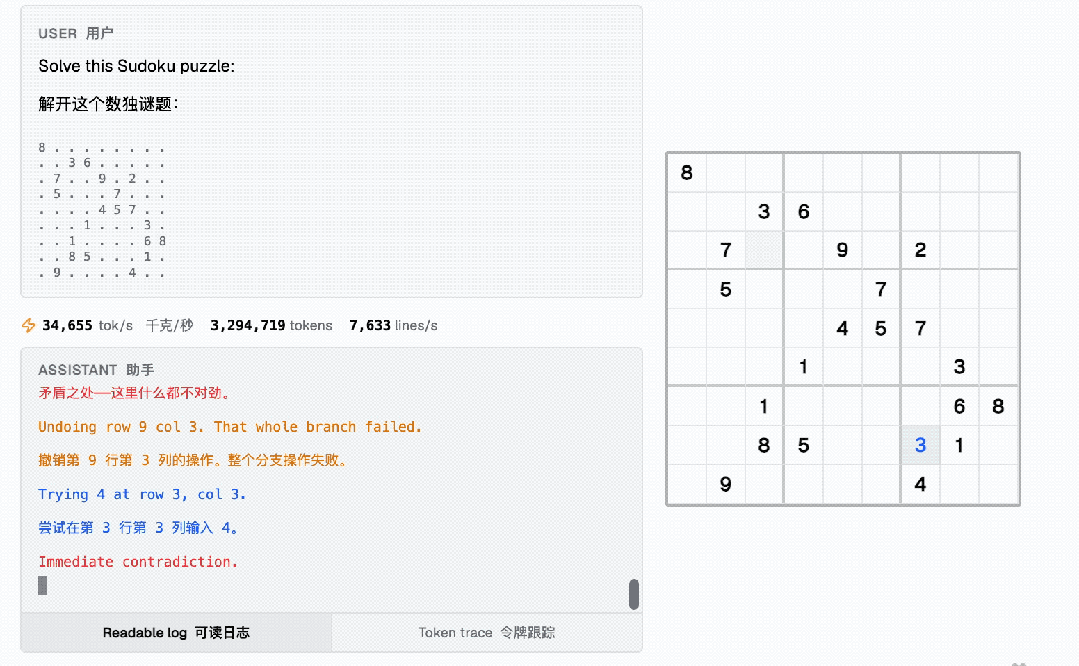
在数独求解过程中,针对仅有21个提示数的Arto Inkala数独,模型内部执行了一个完全正确的、编译后的数独求解器。
求解器先通过约束传播填充21个单元格,然后进入搜索阶段,逐个尝试可能的数字赋值,遇到矛盾立即回溯。
每一次尝试、验证、一致性检查、矛盾检测与回溯步骤都以可读的日志行和Token轨迹形式自回归生成并输出。
最终在3分钟内实现了100%精确求解。
这项工作由Christos Tzamos领衔,与Percepta其他研究者共同完成。
Christos Tzamos是麻省理工博士,目前任雅典大学计算机科学副教授,同时是Percepta的创始研究员。
Percepta是General Catalyst旗下的AI转型公司,团队成员包括来自Meta FAIR、MIT、Google等机构的人才。
参考链接:
[1]https://x.com/ChristosTzamos/status/2031845134577406426?s=20
[2]https://www.percepta.ai/blog/can-llms-be-computers
文章来自于“量子位”,作者 “闻乐”。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI

