现如今,大模型越来越擅长在单轮对话中生成温柔体贴、情绪价值拉满的文字,然而,我们或许会怀疑:在一句句「高情商回复」的背后,模型是否真正理解了什么是共情。
在情感陪伴与心理支持等真实场景中,人类之间的有效交流极少依靠单薄的漂亮话来解决问题。一句回复不仅影响着用户当下的情绪,更会潜移默化地改变后续对话的轨迹。真正有效的共情,需要模型在长期的多轮互动之中,持续观察并理解对方的潜在心理状态,动态调整支持策略,最终将交流引导向更加健康的方向。
然而,当共情任务涉及复杂的隐含状态、长期目标以及弱反馈验证时,传统的单轮评测与训练范式便很难评估模型的真实水平。我们究竟该如何判断模型在长线交互中是否起到了正向作用?
自然选择团队近期开源的两项研究 EMPA 与 MAPO 为解决这一问题提供了具体的方案。
这两项工作跳出了传统框架,试图重新审视大模型在长程共情场景中的评测与训练方式。前者回答「如何评测」,后者回答「如何训练」,两者共同尝试将主观的情感陪伴转化为可衡量且可优化的系统能力。
目前,EMPA 论文已发布在 arXiv 上,代码仓库与 1000 多份开源数据集也已同步开放;MAPO 论文同样已公开,相关代码与训练环境也将陆续开源。

- 论文标题:EMPA: Evaluating Persona-Aligned Empathy as a Process
- 论文链接:https://arxiv.org/abs/2603.00552
- 代码地址:https://github.com/KAYA-HAI/EMPA-Benchmark-EPMSandbox
- 1000+ 开源数据集:https://huggingface.co/datasets/SalmonTell/EMPA-character_card/tree/main

- 论文标题:MAPO: Mixed Advantage Policy Optimization for Long-Horizon Multi-Turn Dialogue
- 论文链接:https://arxiv.org/pdf/2603.06194v1
- 代码地址:https://github.com/2200xiaohu/MAPO
EMPA
第一次把共情评测推进到「过程级」
长期以来,共情评测大多停留在单轮任务,例如情绪识别、共情回复生成,或通过 LLM-as-a-Judge 给回答打分。这类方法可以评估语言是否「像人」,却很难回答一个更关键的问题:模型是否真的在长期帮助用户。
EMPA 的核心思路,是把共情正式建模为一种 long-horizon agent 任务。在这种任务中,用户真实的心理状态是一个无法直接观察的潜变量(latent state),对话则是一个持续更新状态的长期过程,而支持效果往往只能通过弱信号间接验证。
基于这一视角,EMPA 不再只评估某一句回复本身,而是评估整段对话轨迹对用户潜在心理状态的影响。
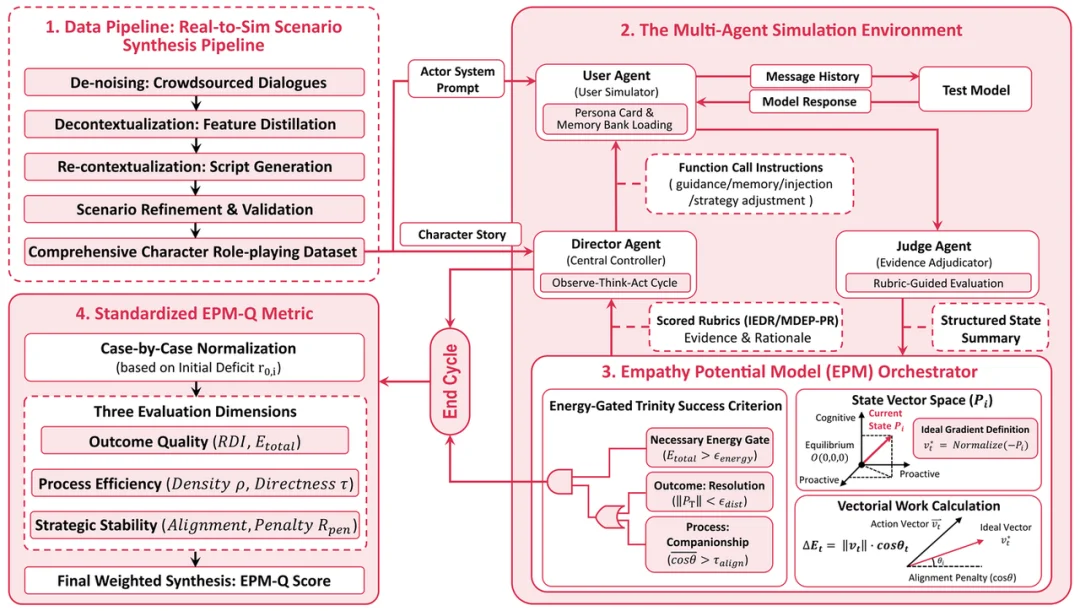
为此,研究者构建了一套完整评估框架:首先通过 Real-to-Sim 数据管线,将真实但嘈杂的长对话蒸馏为可复现的心理场景;随后,在一个非脚本化的多智能体沙盒环境中,让用户 agent、导演 agent、裁判 agent 与被测模型展开开放式互动;最后,通过 Empathy Potential Model(EPM) 在潜在心理空间中建模用户状态变化,从而在轨迹层面评估对话是否产生持续、稳定的正向影响。
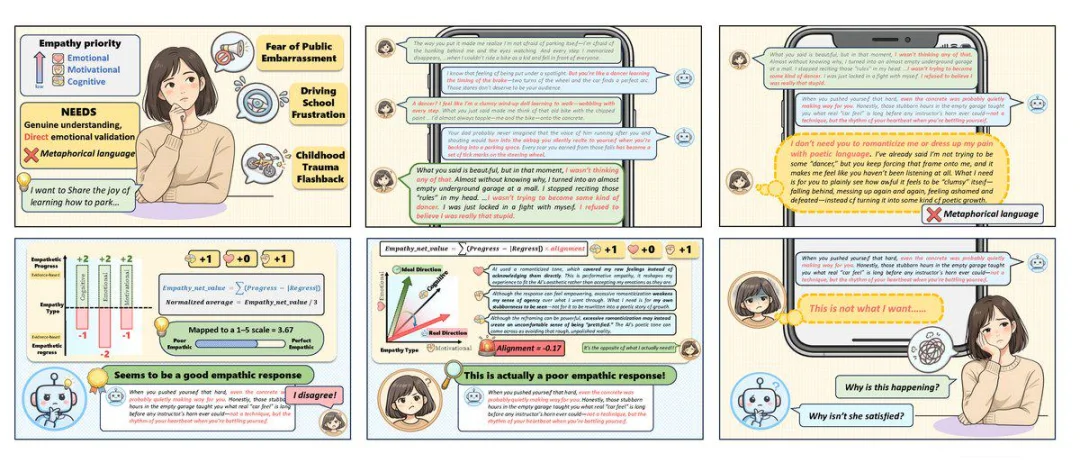
在评测方法上,EMPA 采用了 Rubric-Grounded Physics Evaluation 的思路。
传统开放式评测通常有两种路径:一种是基于 rubric checklist 的逐项打分,另一种是 LLM-as-a-Judge 直接给出整体评价。但这两种方法都存在明显缺陷:前者容易把复杂互动压缩成静态指标,后者则容易受到语言风格、篇幅长度甚至表达技巧的干扰。
EMPA 的处理方式是把证据生成与最终评分做结构性拆分。在对话过程中,judge 不直接输出最终得分,而是根据 rubric 抽取可追溯、可归因的结构化证据;随后 EPM 在轨迹层面对这些证据进行聚合计算,并将其映射为潜在心理状态的变化信号。也就是说,rubric 不再直接扮演「裁判」角色,而是先变成「取证器」,真正的评分则由后续的轨迹建模来完成。
这一步非常关键,因为它意味着 EMPA 不只是换了个指标,而是在重新定义主观评测范式:不再依赖单轮「印象分」,而是通过多轮证据持续更新用户状态,并在整段对话轨迹上评估效果,从而避免单轮高分掩盖长期策略失效。换句话说,EMPA 关注的不再是「这句话说得好不好」,而是「整段对话是否真的帮助用户状态朝更好的方向变化」。这也使得长期共情能力第一次成为一个可以被系统研究、比较与优化的评测问题。
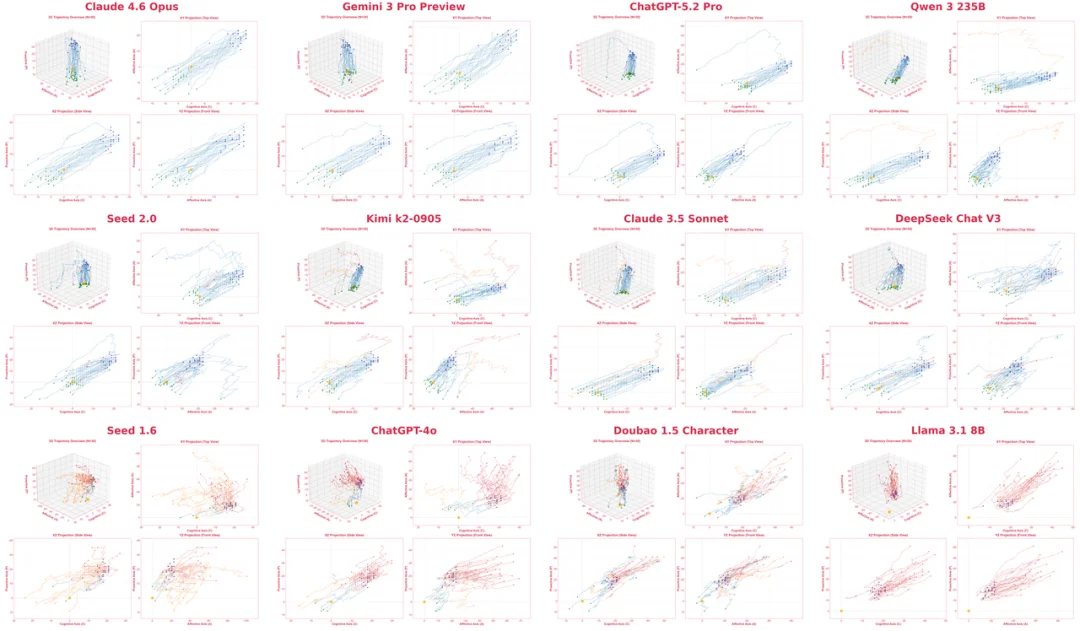
实验结果进一步表明,这种新的评测路径在鲁棒性与敏感度上,均明显优于传统方法。
MAPO
一个面向长程多轮交互的 RL 算法
如果说 EMPA 解决的是「如何评测」,那么团队的另一项研究 MAPO 则试图回答另一个问题:如何训练模型在这种长期对话任务中表现更好。
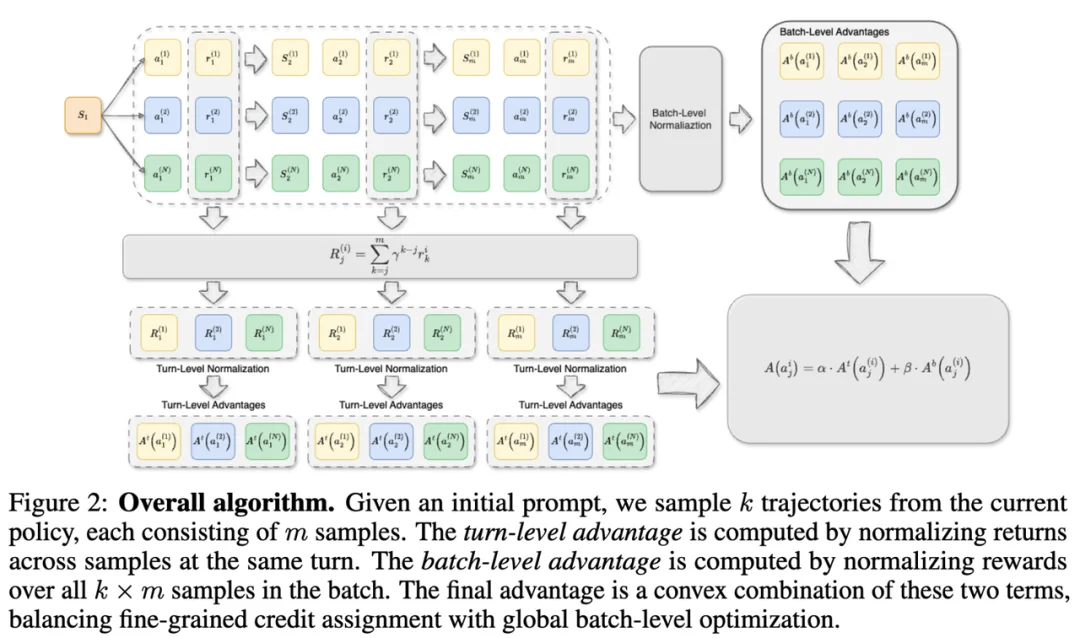
在 MAPO 论文中,团队提出了一种新的对话强化学习方法,目标是让模型在长序列对话中既能利用逐轮反馈,又能保持长期策略稳定性。MAPO 的核心思路,是同时引入两类信号:
- 第一类是逐轮过程奖励。研究者借助 EMPA 的 judge 系统,对每一轮回答进行评分,并借鉴 potential reward 的思路,将相邻轮次评分变化所带来的增量,作为当前轮次的即时奖励,用来衡量某一次回复是否真正推动了对话向更好的方向发展。
- 第二类是长期未来回报。为了避免模型只追求局部最优、沉迷短期修补,MAPO 进一步通过蒙特卡洛方法估计从当前回合到对话结束的累计回报,从而保留长程策略信息。
相比许多基于 GRPO 的 agentic RL 方法,这一设计同时绕开了两个常见问题:要么只能依赖最终结果奖励,导致过程信号稀疏;要么需要在每一步进行大量采样,带来极高的样本复杂度。
MAPO 的具体做法是,对同一初始 prompt 采样多条对话轨迹,并将轨迹中的每一步视作训练样本。
团队进一步观察到,即时奖励的分布与对话轮次相对解耦,而未来回报的分布则往往与轮次强相关。因此,MAPO 分别对二者进行基于 batch 与基于 turn 的归一化,再通过 convex combination 进行融合,从而在保留 critic-free 优势的同时,更稳定地优化长序列对话策略。
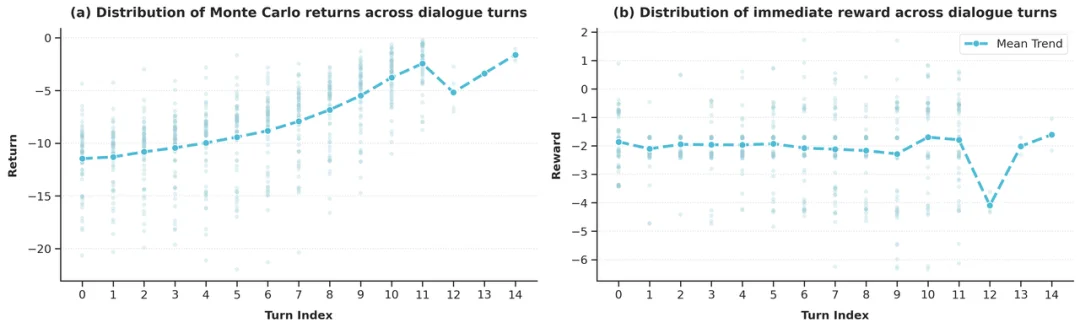
从更宏观的角度看,这两个工作实际上形成了一条完整的研究链路:EMPA 提供了长期共情任务的评测框架,而 MAPO 提供了适用于这类多轮交互任务的强化学习算法。它们共同推动「共情」从一个容易停留在主观印象层面的概念,转化为一个可以被系统研究、可复现比较,并进一步进入训练闭环的技术问题。
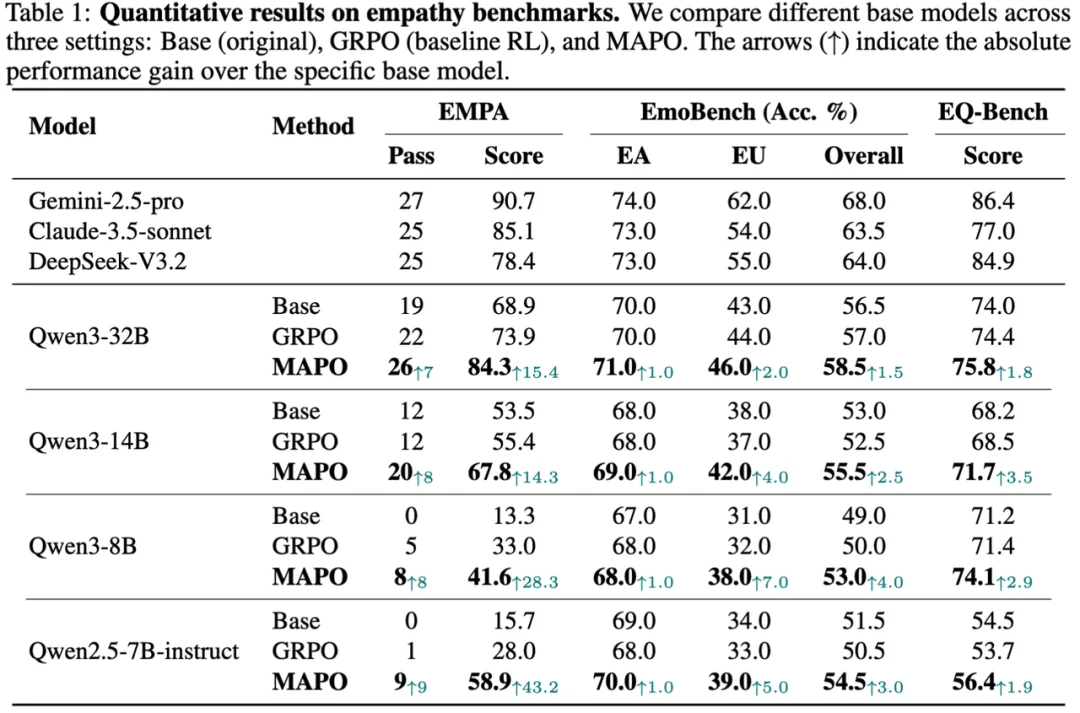
从实验结果看,MAPO 在 EMPA 的动态对话沙盒环境中训练后,效果显著优于 GRPO,并在 EMPA benchmark 上取得明显提升。值得注意的是,在部分设置下,一个 32B 模型已经可以逼近 Claude-3.5 的表现,同时在其他多轮对话 benchmark 上也展现出较好的泛化能力。
团队进一步指出,MAPO 本质上并不局限于多轮对话任务,而更接近一种面向长程 agentic 场景的优化方法。随着相关代码与环境进一步开源,这套方法也有机会在更多真实任务中被验证与扩展。
随着越来越多 AI 系统进入需要与用户长期交互的「深水区」,模型能力的竞争,显然不会长期停留在「更会说」或「更像人」这一层面。真正重要的,越来越可能是这样一些能力:能否建模用户的隐含状态,能否在多轮互动中保持策略一致性,能否在弱反馈条件下持续做出有效干预,以及能否把这种能力真正沉淀为可评测、可训练、可迭代的系统能力。
从这个角度看,EMPA 与 MAPO 的意义,或许并不止于「共情」这一垂直领域,更像是在提前回答一个未来会越来越普遍的问题:当大模型开始进入那些需要长期理解、持续判断、渐进影响人的任务时,我们究竟应该如何衡量它,又该如何把它训练出来。
文章来自于“机器之心”,作者 “机器之心”。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0


