
刚刚,一篇阿里联合中山大学的研究在 X 上爆火了!
今天一早,一位微软产品故事讲述者、前谷歌负责人级布道师 Priyanka Vergadia 分享了一则 X 帖子迅速走火,短短一天内获8700+点赞、170万+浏览。
这篇高赞帖子描述了一项来自阿里巴巴团队的研究,它是一场 233 天、总消耗达 100 亿 token ,在真实生产环境中对主流的 8 家模型厂商提供的 18 个智能体的“耐力”实验,最终证明了 AI 不会抢走人类开发者的饭碗!
Priyanka 总结说:AI 只是编写了一些遗留代码,未来十年你都得忙着修复它们!

而一位业内人士对此表示,该项真正的重点在于:阿里团队做了一个真正有意义的评分体系!
小编这就带大家看下这篇研究。

戳破泡沫:一次性修复不叫“编程”,那叫“撞大运”
该篇论文的名称是《SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration》,由阿里巴巴集团与中山大学联合完成。
论文抛出了一个业内都有明显体感,但没人着手思考解决的“长期软件评估”问题:
现在的AI Agent,在 HumanEval 或 SWE-bench 这种“单向考试”里刷分刷得飞起。只要给它一个明确的Bug,它就能咔嚓一下修好。
但现实开发的现状是: 代码是“活”的。今天你修了一个Bug,明天产品经理改了需求,后天底层依赖库升了级。
这一过程并不能被静态、一次性的修复范式所刻画。
阿里和中山大学的研究团队提出来一种新的性能标准: 衡量一个 AI 牛不牛,不看它能不能修好眼前的Bug,而要看它在长达半年的项目演进中,能不能不把代码库搞崩。
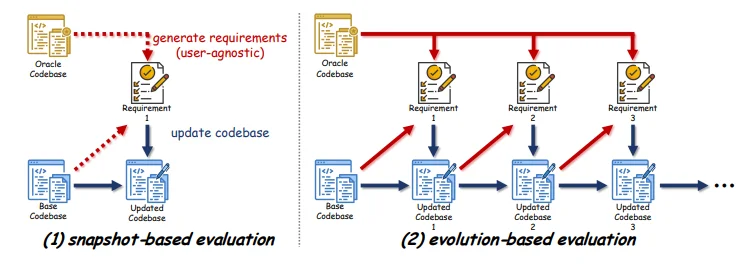
SWE-CI:233天、耗费百亿token的“极限耐力赛”
因此,为了测试AI的真实“抗压能力”,研究团队祭出了一种基于持续集成(Continuous Integration)流程构建的仓库级基准:SWE-CI,首次将软件工程评估从“一次性快照”转向“长期演化”。
该基准包含 100 个真实代码库任务,每个任务平均对应一个真实代码仓库中长达233天、包含71次连续提交的演进历史。
简单理解,SWE-CL 就是对是一场极为残酷的“智能体耐力赛”!
- 真实战场: 选取的任务跨度平均达 233天,涵盖 71次连续提交。
- 模拟人类: AI不再是修完就跑,而是要像真正的开发者一样,在 CI(持续集成) 的死循环里,应对一轮又一轮的需求变更。
- 残酷规则: 这是一场总消耗超过 100亿 Token 的极限耐力赛。
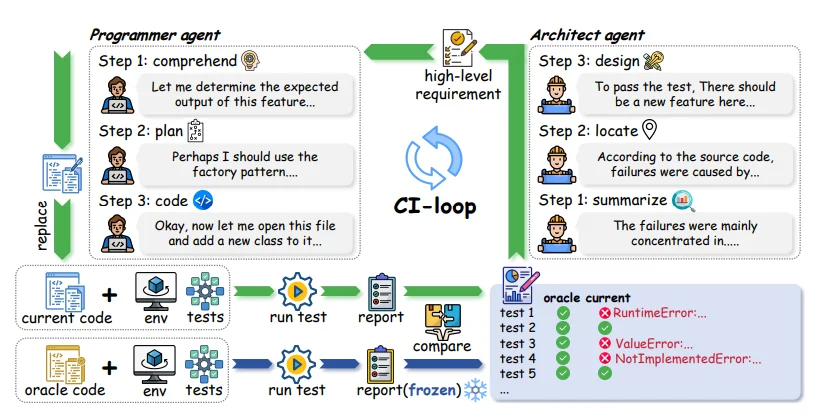
这里列出一些更详细设置:
每个SWE-CI任务都来自GitHub上68个真实Python仓库(维护≥3年、≥500星、含单元测试和依赖配置文件)。
任务定义为:从“基线提交”(base commit)演化到“目标提交”(oracle commit),平均跨越233天、71次提交、至少500行源码变更(不含测试)。代理必须在 Docker 隔离环境中,通过最多20轮迭代,逐步完成需求变更。
值得注意的是,双Agent架构:
架构师Agent:分析失败测试、定位根因,输出1-5条高层次增量需求文档。
程序员Agent:遵循TDD(测试驱动开发)流程,实际修改代码。
整个过程模拟真实CI/CD流水线,每一次变更都会影响后续状态,前期决策的后果会逐步累积。这正是传统基准无法模拟的“长期记忆”与“技术债务放大器”。
因此,评估指标也从单一通过率升级为两个核心维度:
1、零回归率(Zero-Regression Rate):在任务演化过程中,最初通过的测试在后续变更后仍保持通过的比例。
2、lEvoScore:一种加权平均指标,公式为 EvoScore = Σ(i=1 to N) γ^i × a(ci) / Σ(i=1 to N) γ^i,其中γ>1对后期迭代赋予更高权重,强调长期稳定性。当γ=1时退化为普通平均归一化变更得分。
战况惨烈:75% AI正在疯狂制造“技术债”
实验结果让所有人脊背发凉。即便是在2026年这样一个 Vibe Coding 都显得落伍的时间点,主流智能体的表现依然像个“只会打补丁的实习生”。
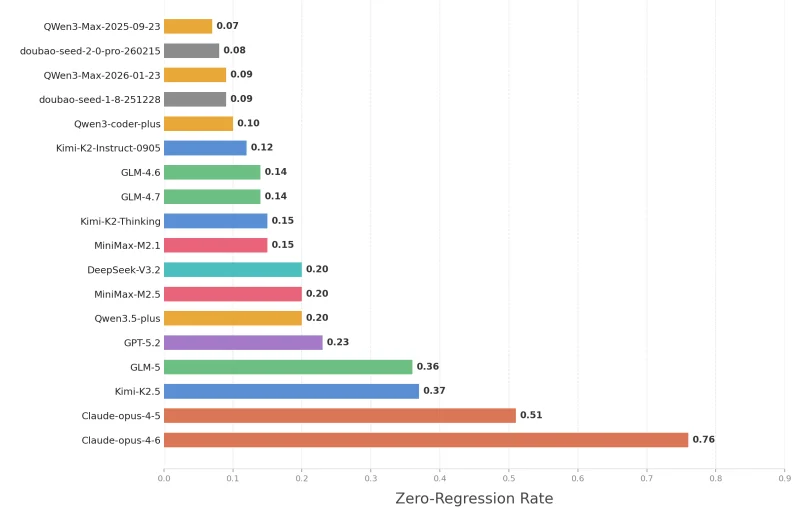
第一,“零回归率”之痛:在模拟真实开发的长期测试中,绝大多数大模型的“零回归率”竟然不到 25%。这意味着它们每改四次代码,至少有三次会搞坏原本正常的功能。
第二,代码库雪崩: 随着项目演进,大多数模型产生的技术债呈指数级增长。前期看似高效,后期改动一下,整个系统直接原地爆炸。
那么,这场耐力赛中,谁是最后赢家呢?
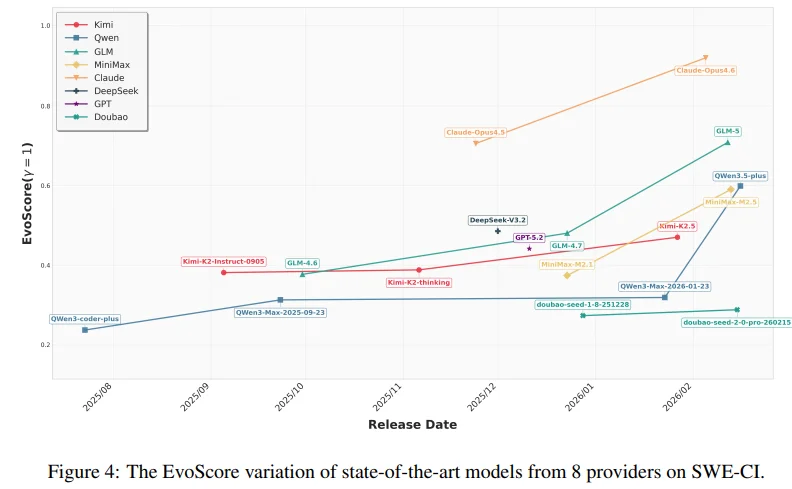
如果你对编程Agent有关注,相信你已经猜到了,自然是 Claude 4.5/4.6。它是唯一能在长周期维护中保持 50%以上零回归率的选手,展现出了极强的“架构师思维”。
GLM-5: 作为国产大模型的代表,在应对长期代码演进时表现抢眼,稳居第一梯队。
惊喜发现:
GLM、Kimi是救火队长,DeepSeek、Minimax是架构大师
值得注意的是,论文中还发现了智能体也存在明显的“AI人格”现象。
不同模型厂商之间的偏好差异显著,而同一厂商旗下的编程智能体往往表现出一致的倾向。具体而言:
- “走一步看一步”型(Kimi, GLM): 这些模型在修改代码时更激进,追求立刻解决当下的 Bug 或需求,但在长远看来,它们可能较快地耗尽了代码库的演进空间。
- “长线规划”型(GPT, DeepSeek, MiniMax): 这些模型在修改时可能更谨慎,会考虑到代码结构对未来的影响,更具有“架构师”潜质。
- “全能稳健”型(Claude, Doubao,Qwen): 无论你更看重眼前还是长远,它们的表现都非常均衡。尤其是 Claude,结合之前的排名看,它是在保持稳定的同时,水平上限也最高的选手。
具体怎么做的呢?
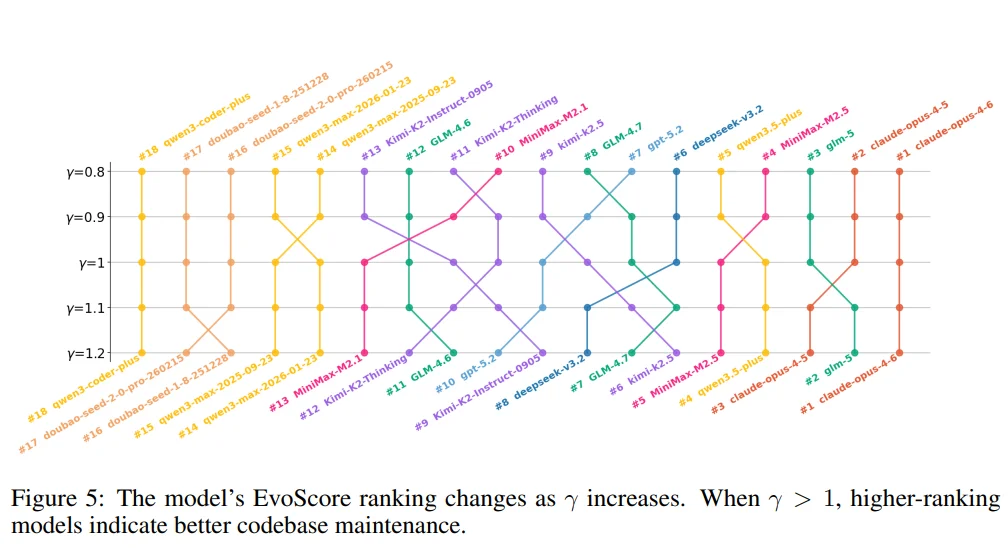
团队通过调整参数 γ 的值,来观察模型排名随之产生的变化。
当 γ<1 时,EvoScore 会给早期迭代分配更高的权重,这有利于那些优先考虑代码修改“即时收益”的模型。
相反,当 γ>1 时,后期迭代会获得更多奖励,从而让那些为“长期改进”而优化(即优先考虑代码可维护性)的模型占据优势。
对于这个现象,研究人员推测,这反映了不同厂商在训练策略上的差异;而各厂商内部模型的一致性则表明,其内部训练流水线(Pipelines)在大体上保持了稳定。
为什么智能体如此容易积累技术债务?
论文间接给出两点原因:
首先是短期最优决策:模型倾向于“最快通过当前测试”的方案,而非全局最优架构。上下文遗忘:即使多轮迭代,模型对早期变更的深层影响理解不足。
其次,模型有依赖与边界敏感性:真实仓库的外部依赖、配置漂移、边缘案例远超训练数据覆盖范围。
这意味着:现实中,一家公司若大规模采用AI生成代码,初期交付速度可能翻倍,但6~12个月后维护成本可能指数级上升——bug修复、重构、迁移难度都会放大。
未来方向:从“快修”到“可持续”
这篇论文可以说用一场真实大规模实验,验证了一点:
目前的绝大多数 AI Agent 都是“纸牌屋建筑师”。它们追求当下的测试通过率,却对代码的长期生命力一无所知。
而 SWE-CI 的意义在于,它把 AI 编程的门槛从“跑得通”拉高到了“可维护”的实用层面。
SWE-CI更多的意义在于提供“诊断工具”:企业可利用类似基准测试自家 AI 工作流,提前识别哪些模型适合“长期驻扎”。
他们给出了三个 SWE-CI 的优化方向:
其一,提高γ权重可鼓励模型追求长期稳定;
其二,双Agent架构可进一步优化(例如加入“回顾Agent”反思历史决策);
其三,与现有工具链结合(如自动生成维护文档、回归测试优先级排序)有望缓解问题。
智能体有希望在耐力上获得成功吗?
但研究者的本意,并不是祛魅智能体,“ SWE-CI 本身就是进步的催化剂”。
他们认为,智能体在耐力上是有望突破的。
首先,Claude 4.5/4.6的领先或许预示着,更强的推理能力(而非单纯生成)是突破关键。
其次,未来模型若能内置“架构意识”“债务评估模块”,或与静态分析工具深度融合,维护能力或将迎来质变。
项目已开源
目前,SWE-CI 开源仓库和 Hugging Face数据集都已上线,大家都可以自行复现、扩展。
这意味着,2026年之后,AI编码竞赛的赛道将从“谁写得快”转向“谁写得稳”。
SWE-CI 开源地址:
https://github.com/SKYLENAGE-AI/SWE-CI
https://huggingface.co/datasets/skylenage/SWE-CI
网友炸了:1000亿美元,就是为了自动化技术债务?
正如论文中所说:“Agent 的代码维护能力只有通过长期演化才能显现,过去决策的后果会在连续变更中累积。”
对此,不少网友表示无语了:AI Coding 的越快,积累债务的速度也就越快!
X 评论区也有人讽刺:“AI自动化了遗留代码的生产线”、“我们花1000亿美元算力,就是为了完美模拟一个‘快速出货、8个月后弃坑的初级开发’”。
HN 讨论区甚至有人提问:“当 SWE-CI 成为新标杆后,AI 编码工具的估值逻辑是否需要重写?”
所以,这么看,程序员的饭碗总算保住了。
但网友却调侃:“现在安全了?但能撑10年?10个月?还是10天?”
“写代码 ≠ 维护系统。” 一位名为 Stephen Collins 的 Medium 作者表示:
软件工程从来不只是“写代码”。它更关乎如何管理复杂性、演进系统架构,以及在成千上万次变更中保持关键不变量的稳定。
而 SWE-CI 这一基准表明,这些挑战对当前的AI智能体来说依然是难点。
这也意味着,下一代开发者工具的重心,很可能会从“生成代码”,转向“理解系统”。
而与此同时,真正高效的开发者,永远是那些能够清晰理解系统的人:知道哪些部分最关键,风险集中在哪里,以及注意力该放在哪。
论文地址:
https://arxiv.org/pdf/2603.03823
参考链接:
https://x.com/pvergadia/status/2033362617352556980
https://medium.com/@stephenc211/ai-agents-can-pass-tests-they-still-cant-maintain-systems-f58fca4b3014
文章来自于“51CTO技术栈”,作者 “云昭”。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md


