在经典强化学习问题中,动作空间通常是离散且有限的。例如在围棋中,一步棋就是一次行动;在机器人控制或视觉 - 语言 - 行动(VLA)模型中,动作往往来自一个有限的控制指令集合。
这样的设置使得搜索算法(如 MCTS)能够在一个结构清晰的决策空间中展开,每个分支都对应一个真实且不同的决策。

但语言模型的情况截然不同。
如果把 token 序列直接视为动作,那么语言模型的动作空间几乎是无限的。同一个语义决策,可以被大量不同的字符串表达。
著名语言学家、哲学家维特根斯坦在《哲学研究》的开篇提出了一个著名的例子,用来说明语言与行动之间的关系:在一个建筑工地上,一名工人只需要喊出「Slab!」(石板),他的同伴就会把石板递过来。在特定语境中,一句话的意义并不取决于它的字面形式,而取决于它在「语境」(context)中的功能。
对 LLM Agent 来说,同一个语义动作,可以被不同的字符串实现:不同的措辞、格式变体、tool-call 写法,看起来是不同分支,本质上却在做同一件事。这意味着,把 token sequence 直接当成「策略」,会系统性地高估语言搜索树的 branching factor。模型表面上在「广泛探索」,实际上却可能只是在不同 paraphrase 之间来回打转。
语言推理的问题,不只是搜索树太大,而是搜索树里有大量「看起来不同、其实等价」的分支。
如果再叠加 RLVR 的稀疏奖励问题,情况会更糟。很多任务只有极少量终点路径能被规则验证为正确,而且验证信号往往只在最后一步出现。于是,一边是搜索预算被近重复分支大量消耗,另一边是中间过程缺乏稳定反馈,credit assignment 也就变得异常脆弱。
围绕「对于 LLM 来说,何为 policy」这个本质问题,上海科学智能研究院联合复旦大学提出 LaPha(Latent Poincaré Shaping for Agentic Reinforcement Learning):把智能体的行为树映射到 LLM 自身的潜空间,用几何距离定义势函数,构造密集的过程奖励,并训练类 AlphaZero 的 LLM Agent。

- 论文链接:https://arxiv.org/pdf/2602.09375
先看最硬的结论
LaPha 的亮点可以用三句话概括:
- 在隐空间分配公平、密集的过程奖励;
- 在隐空间进行策略剪枝;
- 在隐空间训练 Value Network,以极低的开销换取大幅度 test-time scaling;
效果直接反映在基准上:
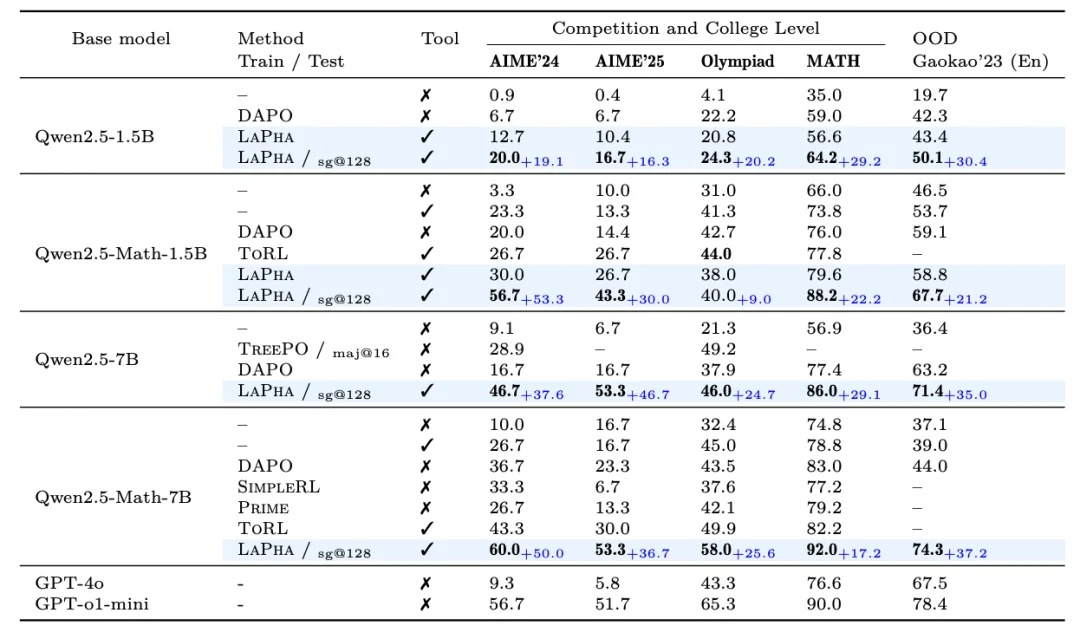
- Qwen2.5-Math-1.5B on MATH-500 / Gaokao'23 (En):66.0% → 88.2% / 46.5% → 67.7%;
- Qwen2.5-Math-7B on AIME'24/25:10.0% → 60.0% / 16.7% → 53.3%。
轻量改造的核心:把「树结构」搬进负曲率几何
LaPha 的做法很直接:对每个搜索节点,把 LLM 的最后一个隐层做平均池化,得到一个状态向量;再以 prompt 的隐向量为原点做「平移中心化」,最后把所有状态的隐向量映射到 Poincaré 球内。此后搜索、奖励、价值、剪枝都在同一潜空间上完成。
为什么是双曲(hyperbolic)空间?
- 树的分支数随深度指数增长,而负曲率空间的有效容量也随半径指数扩张,树节点数量随深度膨胀,欧式空间出现「粘连」,而双曲空间上的节点因为空间膨胀,节点仍能够相互区分;
- RMSNorm 后的隐层分布在高维超球面,球面向量不具备单调性,无法刻画「进展」;而 Poincaré 球上可以观察到清晰的从根节点向边界「生长」的 Agent 行为树。
用几何势函数,把稀疏验证奖励「变密」
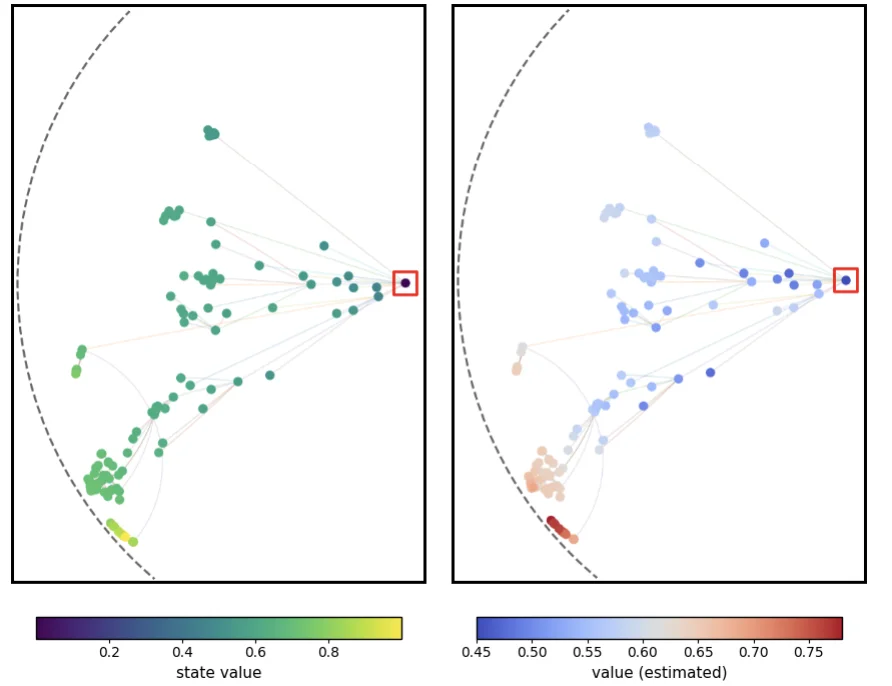
上图可视化了 LaPha-Math-1.5B 搜索正确答案的过程,Agent 的「动作」产生了一棵自「问题」向边界生长的搜索树。LaPha 主要通过以下几步将「终点对错」转成每一步都可以学习的过程信号。
- 双曲测地距离(Poincaré 球的距离)
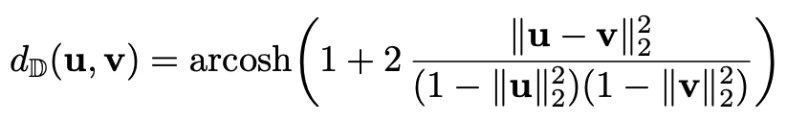
- 构造势函数(取值在 [0,1]),离 root 越远、离最近「正确解」越近,势能越高
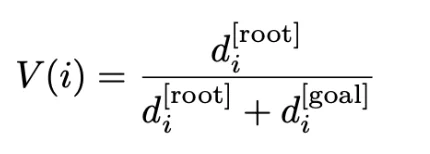
- 沿边的过程奖励就是势能差分。这一步很关键:用势能差分做奖励,能在理论上保持「最优策略不变」的性质,同时把稀疏终点信号变成密集的中间奖励。
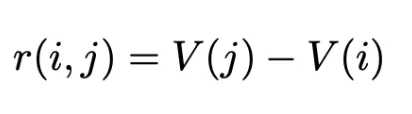
轻量 value head:把「几何进展」学成一个便宜的排序器
光有过程奖励还不够 —— 推理端看不到「正确叶子集合」,怎么办?
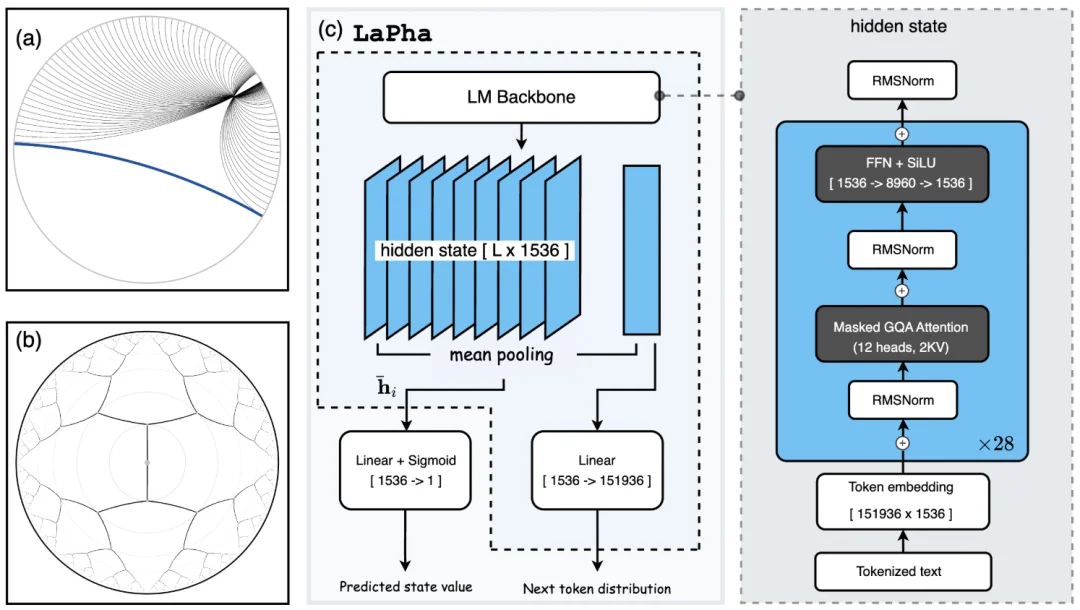
LaPha 在同一份 pooled hidden state 上挂了一个非常轻的 value head(线性 + sigmoid),去拟合上面势函数定义出来的目标。训练完成后,value head 直接作为 MCTS 的启发式信号,在 test-time 引导选择与扩展。
- value head 形式
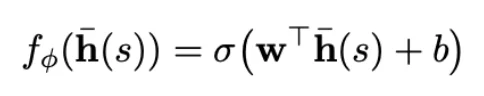
- value loss(用势函数做监督)
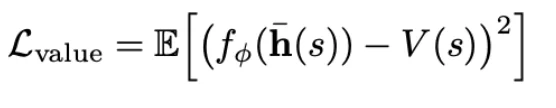
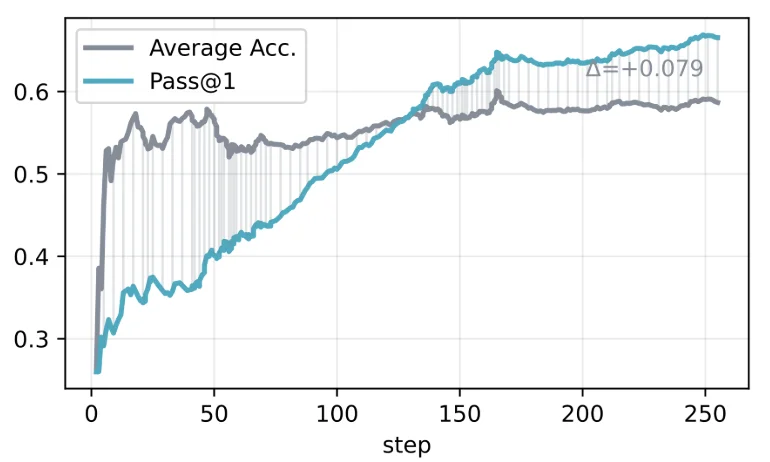
训练中,self-guided Pass@1 逐渐超过叶子平均正确率,说明 value head 学到了独立于 policy head 的额外信息。
潜空间剪枝
语言动作空间的最大浪费,是 MCTS 反复扩展一堆几乎等价的表达。
LaPha 在潜空间里按双曲距离对非终止节点聚类,对每个簇禁用一部分近重复节点,再重建 frontier 继续搜。这样能显著减少「语义坍缩」,提升覆盖率,让同样的模拟预算探索到更多真正不同的思路。
文章来自于“机器之心”,作者 “夏翰宸”。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

