统一多模态生成编辑模型,正在走向“重器化”
模型动辄数十B参数,普通团队望而却步,个人本地部署也限制颇多。
近日,来自上海创智学院、复旦大学和中国科大等机构的研究团队联合发布了统一多模态生成编辑模型DeepGen 1.0。
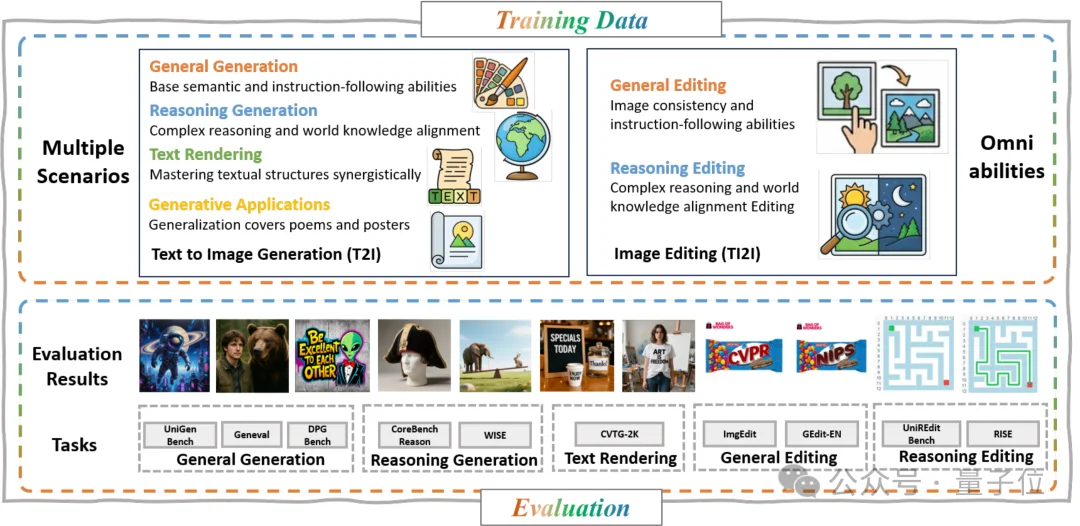
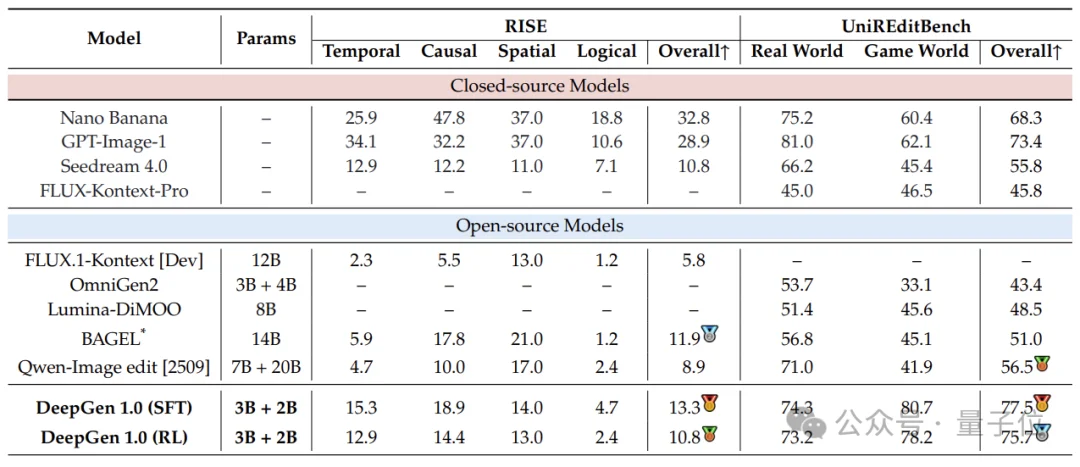
5B参数(3B VLM + 2B DiT)同时集成图像生成、图像编辑、推理生成、推理编辑和文字渲染五大能力。
社区实测4060ti 16G上仅需10s出图,多项质量指标超越大4倍的工业级生成模型。
团队还开源了预训练+SFT+强化学习全流程代码以及对应的高质量训练数据,可以从零复现模型结果或进行进一步探索。不同阶段的模型权重也一并发布,助力社区对统一多模态生成编辑模型的研究。作为轻量级模型的DeepGen 1.0可以以极低成本进行部署,在家用硬件上实时生成图片。
技术要点一览:
- 堆叠通道桥接(SCB)与隐式”Think Token”:将VLM的理解和DiT的生成进行跨层高效深度融合,Think Token提升推理能力。
- 多阶段训练:分为预对齐、联合微调、RL对齐人类偏好并提升文本渲染能力3个阶段。
- MR-GRPO:辅助SFT Loss与KL正则化双重约束,让RL稳定Scaling到1500 steps。
开源统一多模态生成编辑模型的痛点
过去一年,统一多模态生成编辑模型取得了飞速进展,但行业仍面临几个棘手问题。首先,工业级模型动辄数十B参数,生成速度慢、训练成本高,普通团队难以复现;其次,生成和编辑能力往往由不同模型分别承担,部署和维护都很复杂;更关键的是,社区缺乏完整的开源训推流程和高质量训练数据,想要达到工业级效果困难重重。
为了解决这些问题,DeepGen 1.0应运而生。
DeepGen 1.0架构和训练范式
采用VLM-DiT架构(3B VLM + 2B DiT)。
VLM作为理解分支负责处理文本和图像输入,提供丰富的语义理解与世界知识;DiT作为生成分支,在VLM提供的多模态条件引导下生成高质量图像。两者之间通过一个精简的encoder based connector模块进行特征对齐。
在此基础上,使用堆叠通道桥接(SCB)将两个分支进行高效的深度融合,可学习的Think Tokens充当隐式思维链,不增加大量参数,缓解信息丢失,表示偏移等问题,同时提升模型面对复杂指令的推理能力。
最终,通过多阶段训练策略:先训练connector模块进行预对齐;再将VLM和DiT进行高质量多任务联合微调;最后通过强化学习进一步提升视觉效果,并与人类偏好对齐。
训练数据融合了真实世界数据、合成数据以及精心筛选的开源数据集,覆盖了广泛的任务类型,包括通用生成与编辑、基于推理的生成与编辑、文本渲染,以及面向应用场景的任务(比如海报创作、人像生成等)。
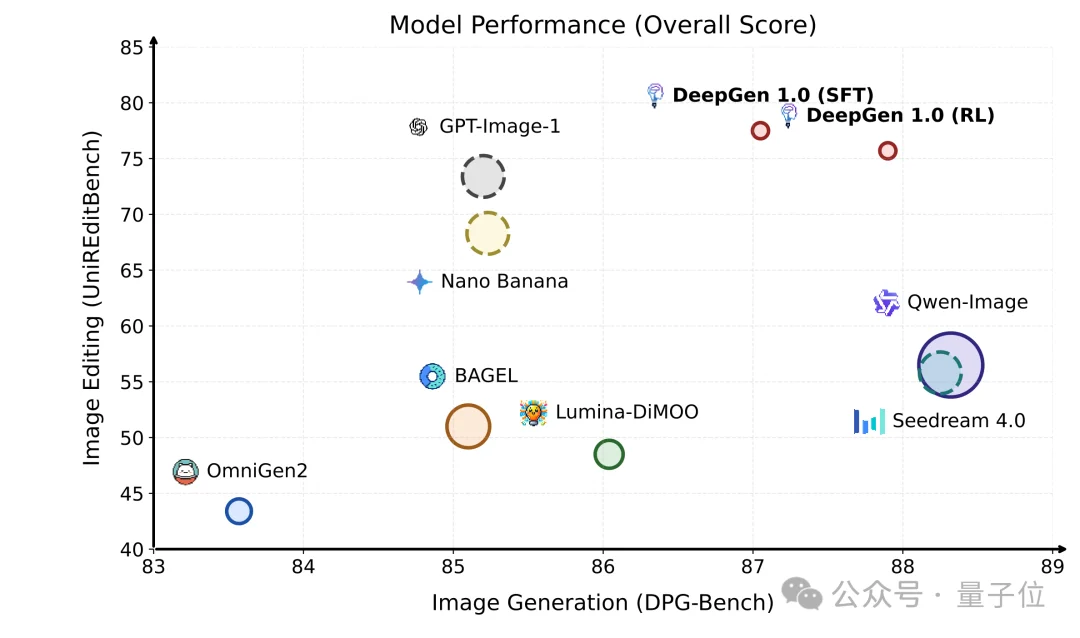
模型效果
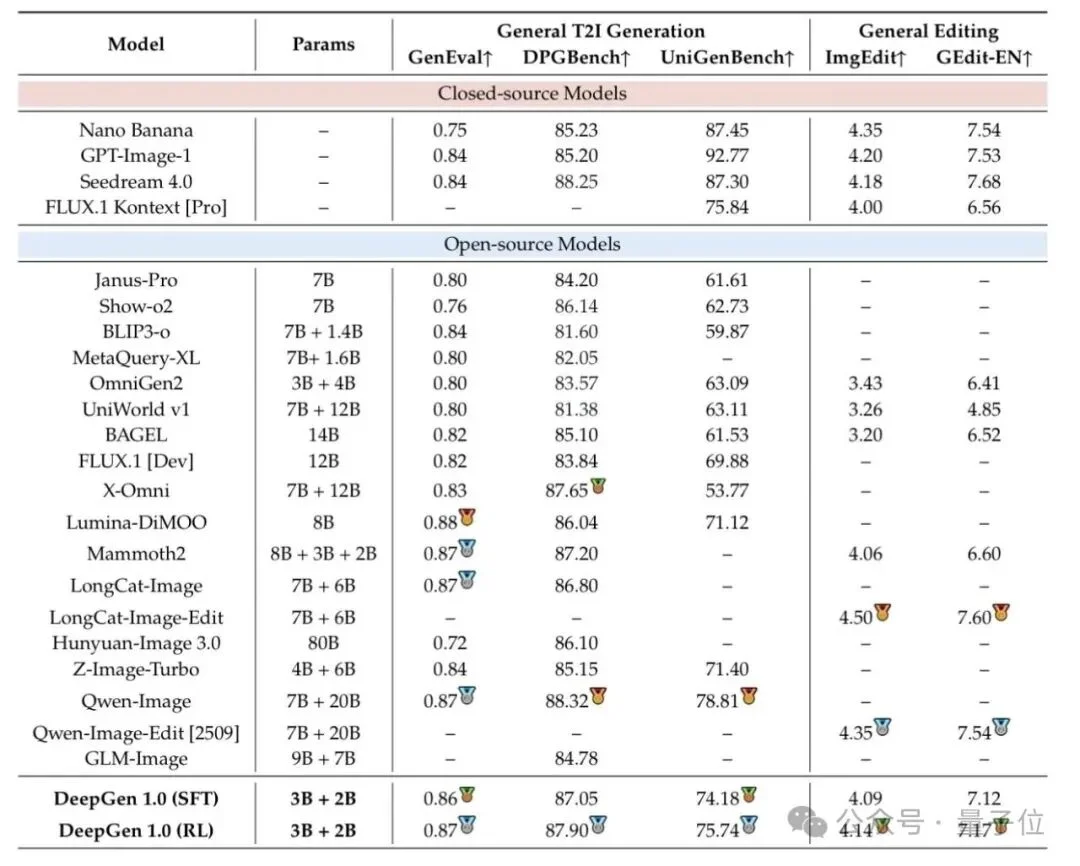
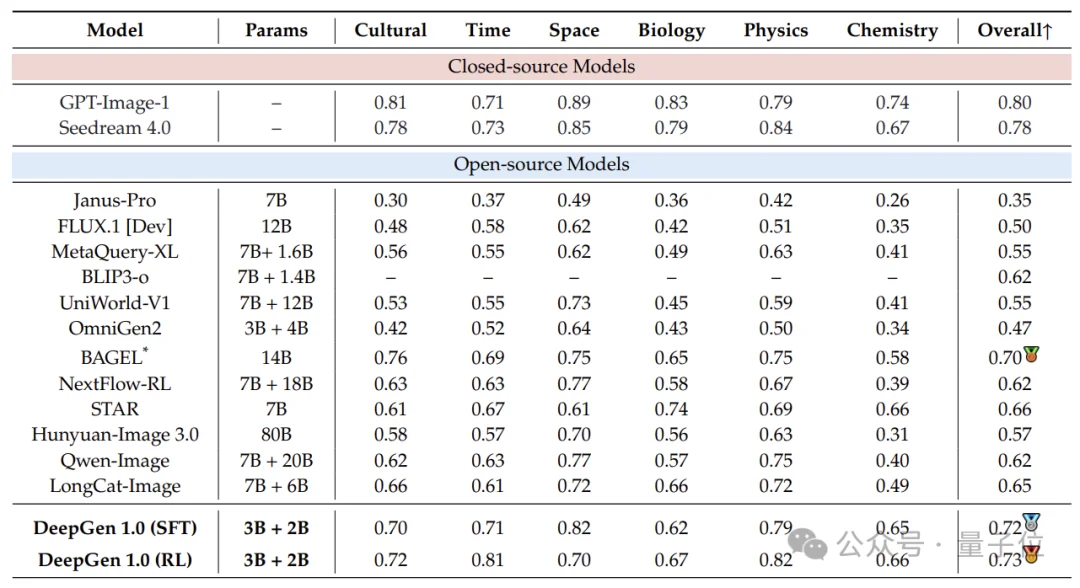
定量结果分析
- 通用生成与编辑
- 推理生成
- 推理编辑
生图效果展示

MR-GRPO

DeepGen引入了MR-GRPO(Multi-Reward Group Relative Policy Optimization)做强化学习阶段,相比于传统的Flow-GRPO,MR-GRPO混合使用pointwise和pairwise奖励模型来评估生成图像,使用三种互补的奖励函数:VLM pairwise偏好奖励(评估图文对齐和视觉质量)、OCR奖励(优化文字渲染准确度)、CLIP相似度(衡量整体语义一致性)。
同时为了缓解RL训练中通用能力退化和图像网格化问题,团队提出了辅助SFT Loss作为结果引导,提供高质量生成的监督信号,锚定模型输出,防止长程训练中能力漂移和坍塌;并辅以KL正则化作为过程引导,约束模型在去噪轨迹上不要偏离参考模型太远。两者协同作用,使RL训练稳定scaling到1500 steps,文本渲染能力提升+10%,综合能力提升+1.5%。
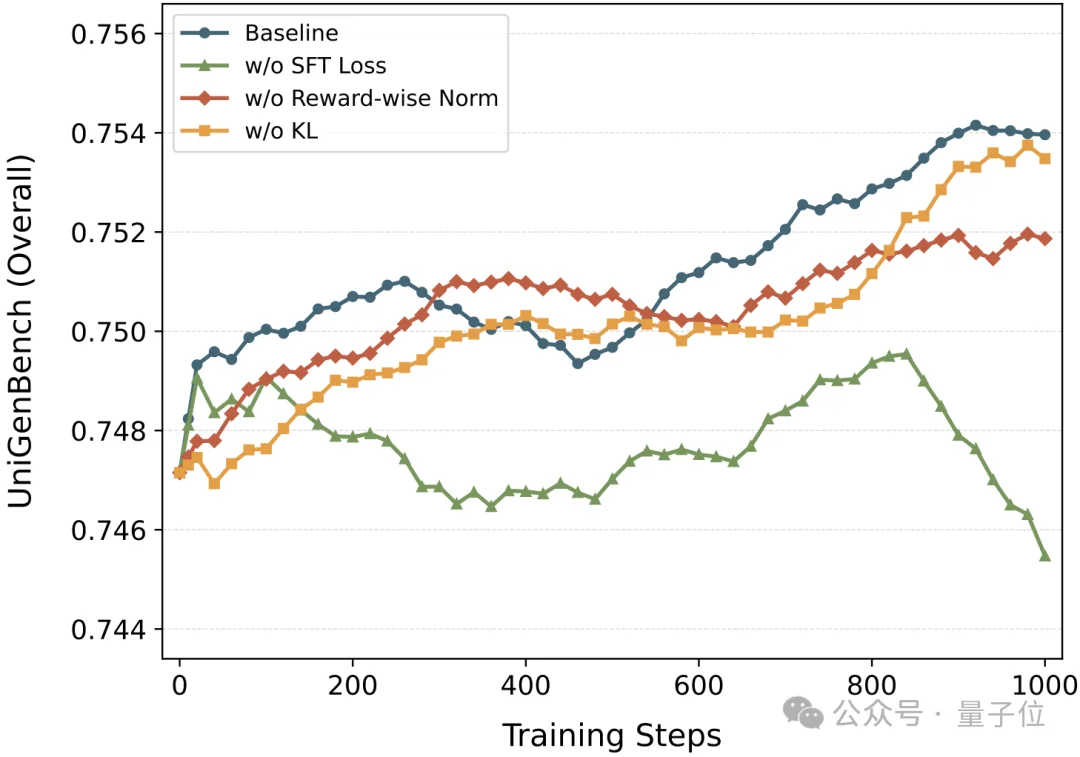
去掉辅助SFT Loss后,模型在大约300步后性能开始崩塌,最终性能大幅退化,甚至不如RL训练前的基线水平。辅助SFT Loss和KL正则化协同提供了互补的约束,两者缺一不可。
构建高效的全开源链路
在当前统一多模态生成编辑模型普遍走向闭源的大环境下,上海创智学院团队选择了全面开源——训练代码、推理代码、模型权重以及高质量训练数据全部公开。这意味着研究者不需要动辄数百GPU的集群,也能基于这套完整的框架从零复现模型结果,或在此基础上构建垂直领域的专用模型。
更值得关注的是DeepGen 1.0的轻量化优势。仅5B参数的模型在一张家用级4060ti 16G上就能在10秒内完成出图,填补了”小模型、强能力”的空白,让高质量图像生成不再是GPU集群的专属。这种极低的部署门槛,为端侧设备的轻量部署和实时生成打开了可能。
DeepGen 1.0的开源,补全了统一多模态生成编辑模型的开源版图,未来团队还将持续迭代,推动这一领域走向开源共创。
论文标题:
DeepGen 1.0: A Lightweight Unified Multimodal Model for Advancing Image Generation and Editing
论文链接:
https://arxiv.org/abs/2602.12205
代码地址:
https://github.com/deepgenteam/deepgen
模型权重:
https://huggingface.co/deepgenteam/DeepGen-1.0
模型权重(diffusers):
https://huggingface.co/deepgenteam/DeepGen-1.0-diffusers
训练数据:
https://huggingface.co/datasets/deepgenteam/DeepGen-1.0
文章来自于“量子位”,作者 “DeepGen团队”。
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

