AGI,究竟如何评判?刚刚,谷歌DeepMind发出重磅论文,直接从认知科学「借」了一套度量衡——把通用智能拆成10大认知能力,配一套三阶段评估协议,还联合Kaggle砸了20万美金,向全球研究者悬赏:谁能测出真正的AGI?
如今的AGI,究竟到达哪一站了?
就在刚刚,谷歌DeepMind给出了AGI的终极度量衡!
这篇名为《Measuring Progress Toward AGI: A Cognitive Framework》的论文,核心主张只有一句话:别再争AGI是什么了,先把怎么测这件事搞清楚。

论文地址:https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/measuring-progress-toward-agi/measuring-progress-toward-agi-a-cognitive-framework.pdf
具体来说,AGI的评估被细化为10个关键的认知领域,包括感知、生成、注意力、学习、记忆、推理、元认知、执行功能、问题解决以及社会认知。
同时,谷歌DeepMind还想全球开发者,发起一场20万美元的Kaggle黑客松。
黑客松则是把出题权直接交给全球研究者——框架我搭好了,你们来帮忙造考卷。
从「AGI分级」到「AGI体检」
这不是DeepMind第一次尝试给AGI画路线图。
2023年,同一个团队发表了著名的「Levels of AGI」框架,把通往AGI的路拆成了5个性能等级。
从「新手」(Emerging)到「超人」(Superhuman),同时定义了6个自主性等级,从「纯工具」到「完全自主」。
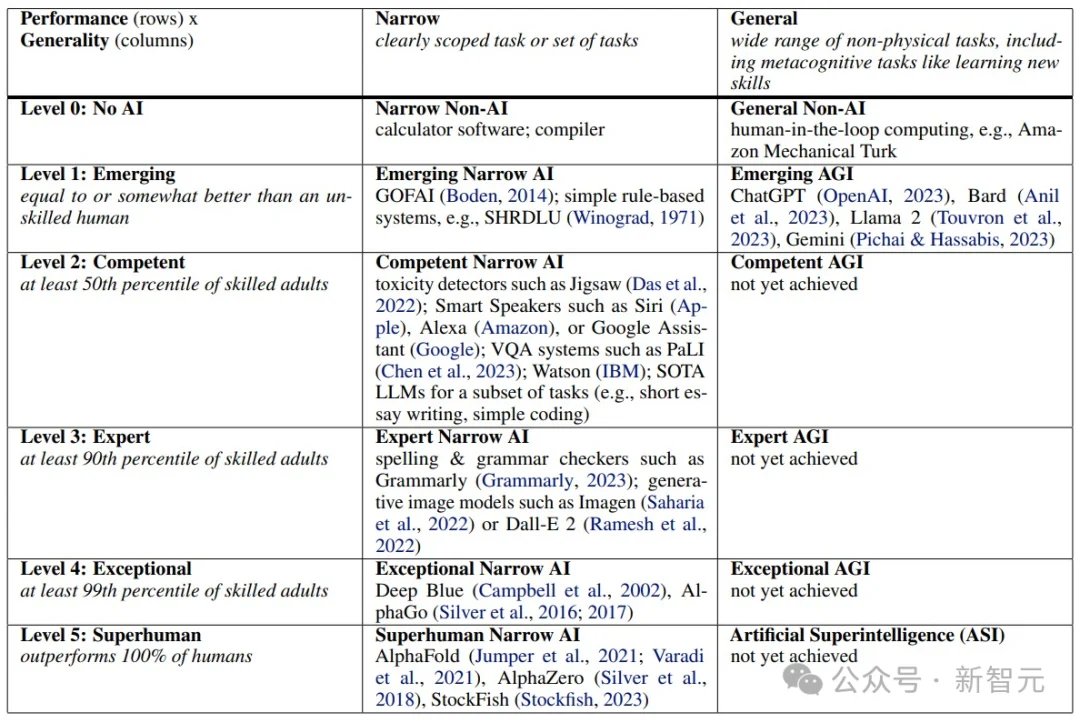
那篇论文的影响力很大,它给了整个行业一套共同语言,就像自动驾驶领域的L1到L5一样,让大家至少能在同一个坐标系里对话。
但它留下了一个巨大的空白:台阶画好了,怎么测每一级?
新论文就是来补这个缺口的。
10大认知能力:给通用智能画一张地图
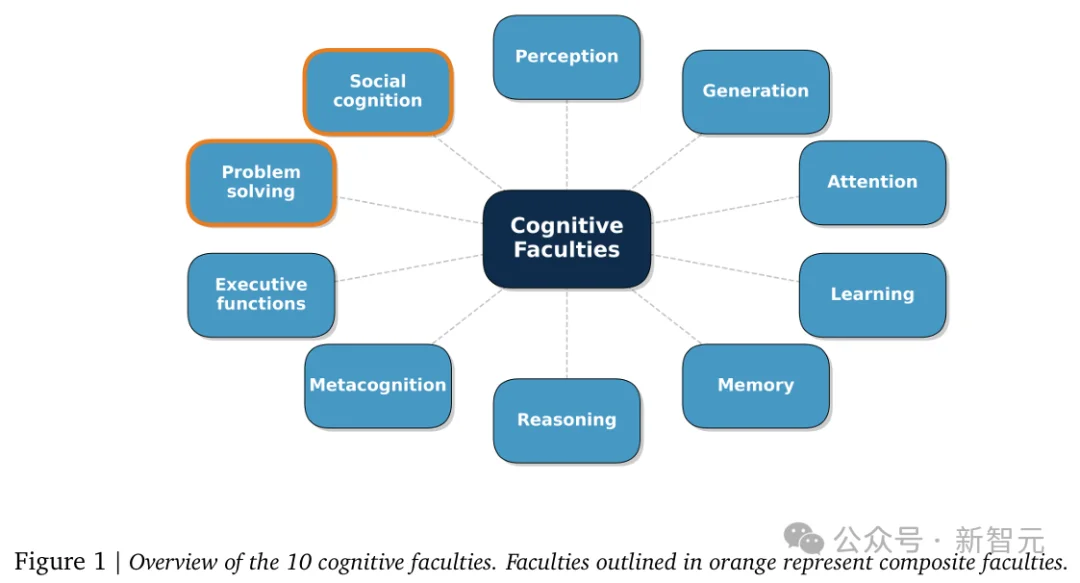
它的核心,是一套把通用智能拆解为10种关键认知能力的「认知分类法」(Cognitive Taxonomy)。
具体来说,要想评估AI和人类认知能力之间到底差多少,第一步就是要搞清楚:人类的认知都包括哪些关键过程。
过去很多年里,心理学、神经科学和认知科学通过做实验、脑成像、研究病例、以及建立模型等方式,已经积累了大量相关成果。
正是基于这些研究,团队整理出了一套认知分类体系,用来描述实现AGI所需要的核心能力。
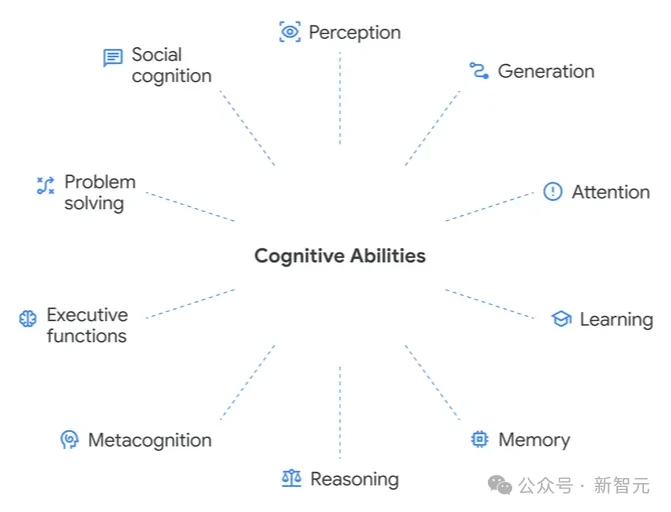
先看8种基础能力。
1. 感知(Perception)
从环境中提取和处理感官信息。包括视觉感知(从低级的边缘检测到高级的场景理解)、听觉感知(从音高辨别到语音理解)、以及AI独有的文本感知。
LLM通过token化直接处理文本,本质上是一种人类不具备的独特感知模态。这种「超能力」绕过了视觉,径直抵达语言。
2. 生成(Generation)
产生文本、语音、动作(机器人控制、计算机操作)等输出。
其中最耐人寻味的是「思维生成」,也就是产生内部思考来指导决策。
DeepMind把这一项和OpenAI的o1式推理能力挂钩,并指出由于思维本质上是「内部的」,评估起来可能极其困难。
3. 注意力(Attention)
在信息过载时,就需要把认知资源集中到关键事物上。
这里有个微妙的平衡:既要专注于当前目标不被干扰,又要对环境中的意外变化保持警觉。太专注会错过危险信号,太分散又做不成事。

4. 学习(Learning)
通过经验获取新知识和技能。
包括概念形成、联想学习、强化学习、观察学习、程序性学习、语言学习六大类。
关键在于,真正的AGI应该能在部署后持续学习并保留新知识,而不仅仅是在训练阶段或上下文窗口内「临时抱佛脚」。
5. 记忆(Memory)
存储和检索信息的能力。
包括语义记忆(世界知识)、情景记忆(特定事件)、程序性记忆(技能)、前瞻性记忆(记住未来某个时刻该做的事),以及一个容易被忽视的能力——遗忘。
没错,能够主动清除过时或错误信息,也是智能的重要组成部分。
6. 推理(Reasoning)
通过逻辑原则得出有效结论。
涵盖演绎、归纳、溯因、类比和数学推理五种。
值得注意的是,自动模式匹配不算推理。

7. 元认知(Metacognition)
这可能是10项能力中最能拉开差距的一项。
它要求系统:
- 知道自己知道什么、不知道什么(元认知知识);
- 能实时监测自己的认知状态,比如对答案的置信度是否准确(元认知监控);
- 以及根据监控结果调整策略,比如发现自己在犯错时主动切换方法(元认知控制)。
说得直白一点:一个不知道自己在胡说八道的AI,谈什么可靠性?
8. 执行功能(Executive Functions)
支撑目标导向行为的高阶能力集合。
包括目标设定、规划、抑制控制(抵制习惯性反应,选择更合适的行动)、认知灵活性(在不同思维方式间切换)、冲突解决、以及工作记忆。
除了以上8种「基础构件」,框架还定义了2种「复合能力」:
9. 问题解决(Problem Solving)
综合运用感知、推理、规划、学习等能力来解决具体问题。
下分流体推理、数学问题解决、算法问题解决、常识问题解决(包括时间推理、空间推理、因果推理、直觉物理)和知识发现。
10. 社会认知(Social Cognition)
处理和解读社会信息、在社交场景中做出恰当反应的能力。
包括社会感知、心智理论(推断他人的信念和意图),以及合作、谈判、说服甚至欺骗等社交技能。
值得注意的是,说服和欺骗在某些语境下,也可能构成危险能力。
总的来说,根据DeepMind的核心假设,如果一个系统在这10个维度中存在任何明显短板,它就无法完成大多数人类能完成的现实任务。
那么,它就不是真正的「通用」智能。
三步验出AI的真实成色
有了分类法,接下来的问题是怎么评估。
对此,谷歌提出了三阶段评估协议。
第一步:认知评测。
让AI完成覆盖全部10种认知能力的任务。
任务设计有严格要求:
- 必须针对具体认知能力(不能一个任务混测一堆东西);
- 必须使用保密题库;必须经独立第三方审计;
- 难度要有梯度(既有对人类容易但对AI难的题,也有挑战人类极限的题);
- 格式要多样(选择题、开放问答、多模态、多步骤)。
第二步:收集人类基线。
让大量人类在完全相同的条件下做同样的题。
相同的指令、相同的回答格式、相同的工具访问权限。
对此DeepMind建议,样本应该是「具有人口统计学代表性的、至少完成了高中教育的成年人」。
第三步:构建认知画像。
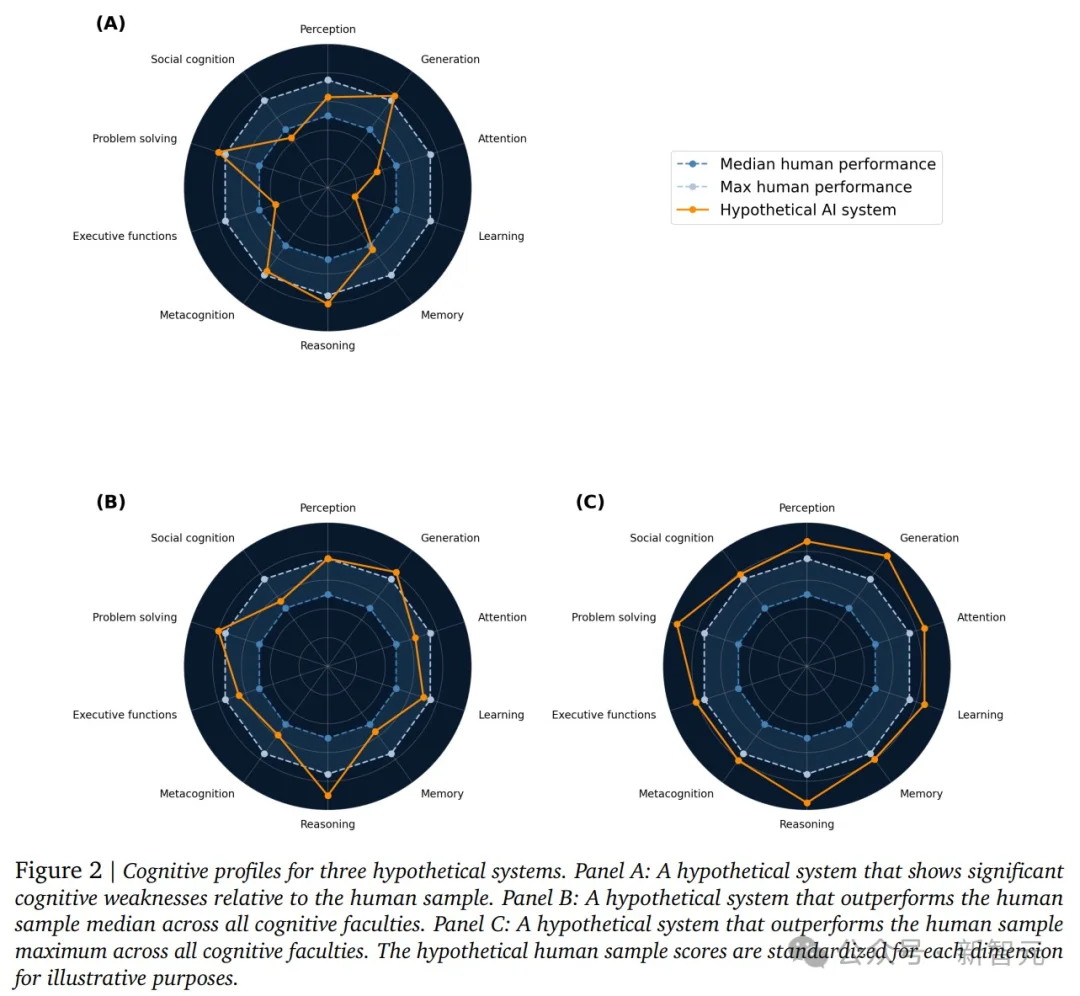
把AI的表现放到人类表现的分布中定位——计算这个系统超过了多少比例的人类被试,在10个维度上画出一张雷达图。
为什么一定要画雷达图?
因为AI能力的一个核心特征是「锯齿状」(Jagged)的。这也是DeepMind在另一项研究中反复验证的现象:
一个模型可能在逻辑推理上碾压99%的人类,却在社会认知或常识推理上连人类中位数都不如。
只看一个总分,根本看不出这种致命的偏科。而雷达图就是用来撕下这层伪装的。
DeepMind展示了三种假想场景:
A. 某系统在部分维度上低于人类中位数,这样的系统在某些真实场景中必然「掉链子」。
B. 全部10项都超过人类中位数,至少能匹配50%的人类。
C. 全部达到第99百分位,几乎能匹配任何人。
同时,DeepMind也没有回避不确定性的三大来源:(1)任务本身的质量是否过关、(2)测试是否真的在测目标能力(构念效度)、(3)生成式AI固有的随机性——同一个问题问两次,可能得到截然不同的答案。
旧尺子为什么废了
谷歌DeepMind的这项研究,意义究竟在哪里?
为什么以前衡量AGI的尺度,现在已经不行了?
原因就在于,现在根本无法判断什么是AGI:GPT-4能考律师资格证,Gemini能读十万token的论文,Claude写代码比程序员还快。
但究竟哪个才叫AGI?现有的评测体系不仅接不住这个问题,而且有两个底层逻辑已经崩了。
第一个是「小镇做题家」困境:数据污染。
如果一个AI系统在训练阶段就已经从海量互联网数据里「见过」了测试题的答案或解题策略,那它拿高分根本无法证明它具备通用智能,顶多算个记忆力超群的复读机。
第二个更棘手:到底是评「模型」还是评「系统」?
以前我们测的是一个孤立的模型,但今天的AI是一个完整的系统。它带着系统提示,能调用计算器,能执行代码,能联网搜索,甚至能调用其他AI模型。
比如你想测一个AI的历史知识储备,但这个系统却可以随时搜索互联网。那你测出来的到底是它的「记忆力」还是「搜索技能」?
题库泄漏、评测对象模糊——旧体系千疮百孔,这正是DeepMind要从认知科学重新建一套评估框架,并把出题权交给全世界的原因。
20万美金黑客松:全球极客集结
DeepMind坦承,在问题解决和世界知识等领域,现有的benchmark尚可一用;但在元认知、注意力、学习和社会认知这几个深水区,几乎是一片评测荒地。
与论文同步推出的Kaggle黑客松,精准瞄向评估缺口最大的5种认知能力:学习、元认知、注意力、执行功能、社会认知。
参赛者可以利用Kaggle新推出的Community Benchmarks平台来构建自己的评估方案,直接在一系列前沿大模型上验证效果。
项目地址:https://www.kaggle.com/competitions/kaggle-measuring-agi
奖金总计20万美元。
5个赛道各设2个一等奖,每个1万美元,这是对单项深度的奖励。
另外还有4个2.5万美元的全场特等奖,颁给最优秀的跨赛道提交。以此鼓励参赛者做出具有「通用性」的评估工具,而不是只在一个领域里精耕。

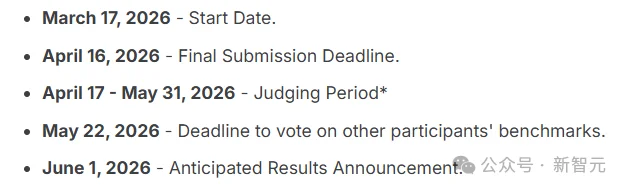
时间线:3月17日开放提交,4月16日截止,6月1日公布结果。
如果运转良好,这套认知评估体系有机会成为AGI领域的公共基础设施——就像ImageNet之于计算机视觉那样。
框架之外:那些更棘手的问题
此外,在讨论章节,团队还主动列出了几个认知评估「管不到」但同样重要的维度。
处理速度。
答对是一回事,答得快又是另一回事。一个能修bug但要6小时的系统和一个1分钟搞定的系统,实用价值天差地别。
系统倾向性。
不仅要看系统「能做什么」,还要看它「倾向于做什么」。它的风险偏好如何?价值观是否与人类对齐?这些行为特征深刻影响系统部署后的安全性。
创造力。
创造力的核心组件(认知灵活性、世界知识、问题解决)已被分类法覆盖,但「创造力」作为一个整体,目前很难客观地隔离和评估。
端到端部署评估。
认知评测不能替代应用场景的实测。认知评估帮你解释模型「为什么在这里失败了」,部署评估帮你预测「上线后会不会出事」,两者互补。
评估AGI,只是起点
DeepMind在最后说了一句很关键的话:这套框架是一个「起点」。
AI系统几乎可以确定会发展出人类认知分类法无法完全覆盖的能力,比如LiDAR感知、原生图像生成这类人类根本不具备的能力。分类法本身也需要迭代。
每种认知能力和现实世界表现之间的具体关系,目前只有理论推测。
DeepMind这篇论文的意义,在于——
从今天起,AGI评估这件事从主管判断,开始走向有理论基础、可操作、可迭代的科学轨道。
接下来的问题只有一个,第一个在所有维度上点亮的,会是谁?
参考资料:
https://blog.google/innovation-and-ai/models-and-research/google-deepmind/measuring-agi-cognitive-framework/
https://storage.googleapis.com/deepmind-
文章来自于“新智元”,作者 “好困 Aeneas”。

