近年来,大语言模型(Large Language Model,LLM)在个性化智能助手任务上取得了快速进展,通用 AI 助手的愿景也变得越来越可实现。然而,现有针对个性化助手的评测基准,仍然与真实世界中的用户-助手交互存在明显脱节,其局限性主要体现在两个方面:
- 复杂外部环境:真实用户需求并不是脱离环境独立产生的,而是会受到时间、地点、天气、生活事件等复杂外部情境的共同影响;
- 动态用户认知:用户意图往往受到长期偏好、个性特征、近期经历和当前心理状态的共同塑造。
由于真实长期用户交互数据受到隐私与伦理限制,长时间、跨场景的公开数据极为稀缺,这也使得现有评测难以真正逼近现实中的个性化助手使用场景。
针对这些挑战,来自复旦大学、上海创智学院的研究人员提出 LifeSim,一个面向个性化助手评测的长程用户生活模拟框架。LifeSim 同时建模用户内部认知过程与外部物理环境,生成连贯的生活轨迹、事件序列与多轮交互行为;在此基础上,研究团队进一步构建了 LifeSim-Eval,用于系统评测模型在长期个性化交互中的能力边界。
- 论文标题:LifeSim: Long-Horizon User Life Simulator for Personalized Assistant Evaluation
- 论文地址:https://arxiv.org/abs/2603.12152
- GitHub 地址:https://github.com/dfy37/lifesim
- Demo 链接:http://fudan-disc.com/lifesim/
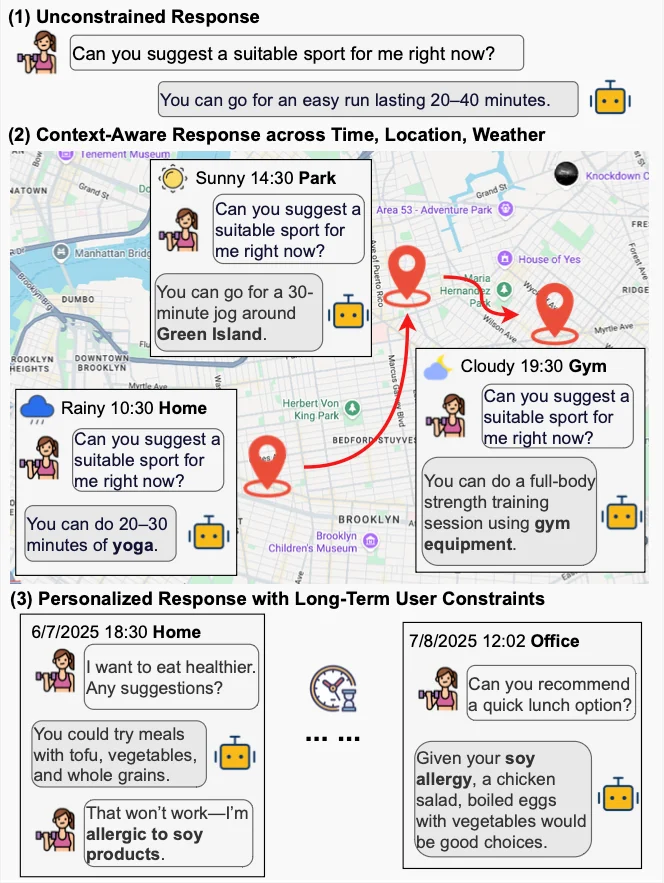
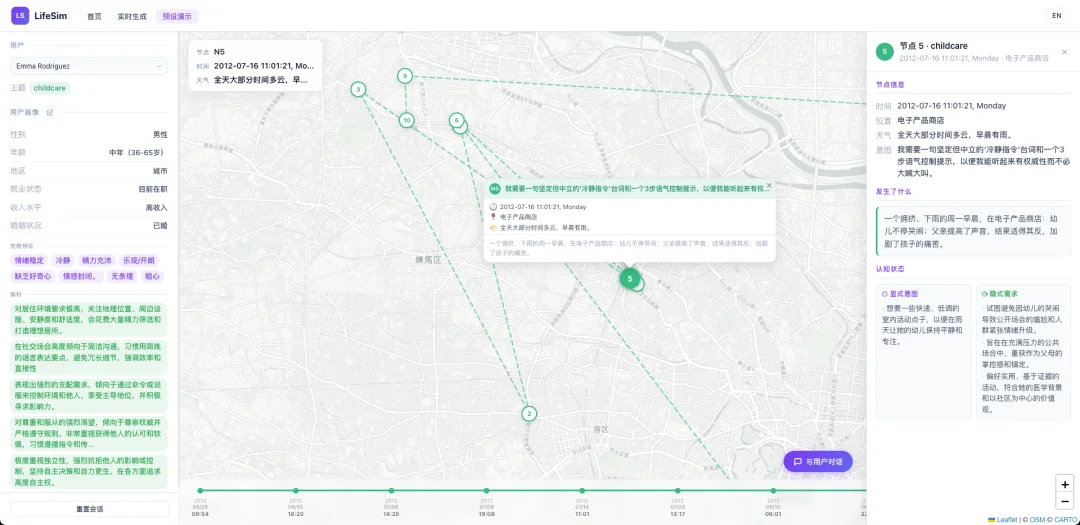
图 1:基于长程时空上下文的个人 AI 助手。用户行为会随外部环境动态演化,同时又体现出稳定的个人特质。要实现有效响应,模型需要在适配当前上下文的同时,利用交互历史推断用户状态,从而动态调整自身策略。
融合 BDI 理论的模拟框架:LifeSim
LifeSim 是面向长期个性化助手评测的用户生活模拟框架,核心由四部分组成:用户画像、基于信念-愿望-意图(Belief-Desire-Intention,BDI)的认知引擎、基于环境约束的事件引擎、用户行为引擎。
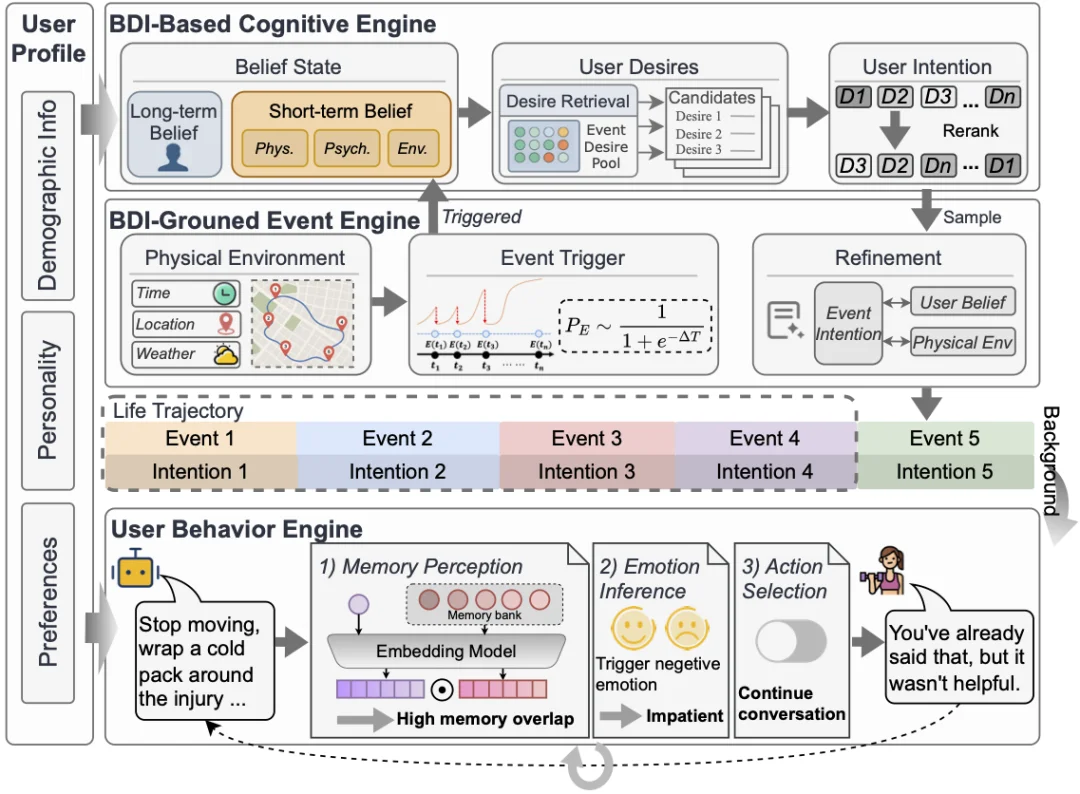
图 2:LifeSim 框架概览。针对每个目标用户,其用户画像包含人口统计学属性、人格特质与长期偏好,这些要素共同构成长期信念状态。基于 BDI 模型的认知引擎与事件引擎相结合,将主观信念状态与物理环境进行融合,共同生成用户意图。随后,用户行为引擎通过对记忆感知、情绪推理与行为选择进行建模,生成对话内容。
为支持用户多样性,LifeSim 构建百万级用户画像池,每个画像包含人口统计学属性、基于大五人格的特质及长期偏好。基于 BDI 模型的认知引擎用于模拟用户内部认知,其中:
- 信念:涵盖长期画像与短期情境认知;
- 欲望:是当前激发的需求,由真实用户需求库匹配而来;
- 意图:是最终形成的行动倾向,具体通过结合用户画像、近期经历及当前环境生成合理意图。
事件引擎以真实出行轨迹为基础,融入时间、地点等环境因素,根据用户状态生成连贯生活事件,让用户需求自然涌现。用户行为引擎则模拟多轮交互表现,综合考虑记忆、情绪与行为选择,生成的回复兼具画像一致性、上下文相关性与自然度。自动与人工评测验证了行为引擎的有效性。
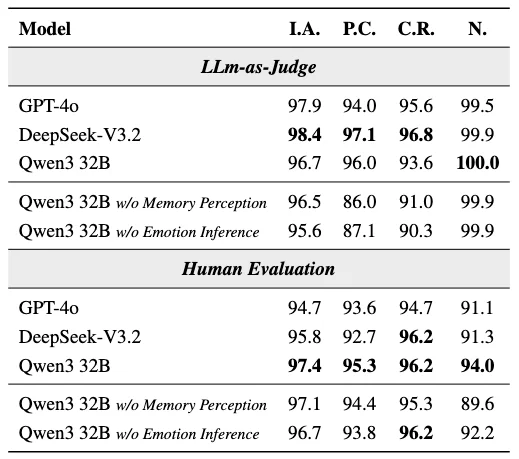
表 1:基于不同模型基座的用户行为引擎在四个维度上的性能表现。
更贴近真实世界的评测环境:LifeSim-Eval
基于 LifeSim,LifeSim-Eval 被提出用于评测长期个性化助手场景下的模型核心能力。区别于传统评测,其更关注三点:
- 模型能否识别并满足显隐性意图。其中显性意图为用户直接表达的需求,隐性意图需结合画像、场景与偏好推断;
- 能否重建用户画像;
- 回复是否符合用户画像并保持一致。
LifeSim-Eval 利用 LifeSim 构建 120 个用户、1200 个评测场景,覆盖 8 个常见生活领域,并设置两种评测模式:
- 单场景模式:仅基于当前场景,与 LifeSim 中的模拟用户完成多轮对话(最多 20 轮);
- 长时程模式:需结合历史交互响应当前场景。
核心评测指标包括意图识别、意图完成度、偏好重建、画像对齐,以及回复的自然度与连贯性。
实验结果与关键发现
论文在多类主流 LLM 上进行了系统评测,涵盖 GPT-5、GPT-4o、Claude Sonnet 4.5,以及 DeepSeek-V3.2、Qwen、Llama、gpt-oss 等多个开源 / 闭源模型。实验揭示出以下几个核心结论:
- 显性意图较强,隐性意图明显更难
在单场景设置中,大多数模型在显性意图识别上表现较好,但在隐性意图识别上普遍存在超过 20 分的性能差距。这说明当前模型已经较擅长处理用户直接表达的需求,但对于需要结合上下文和用户状态推断出的潜在需求,能力仍明显不足。
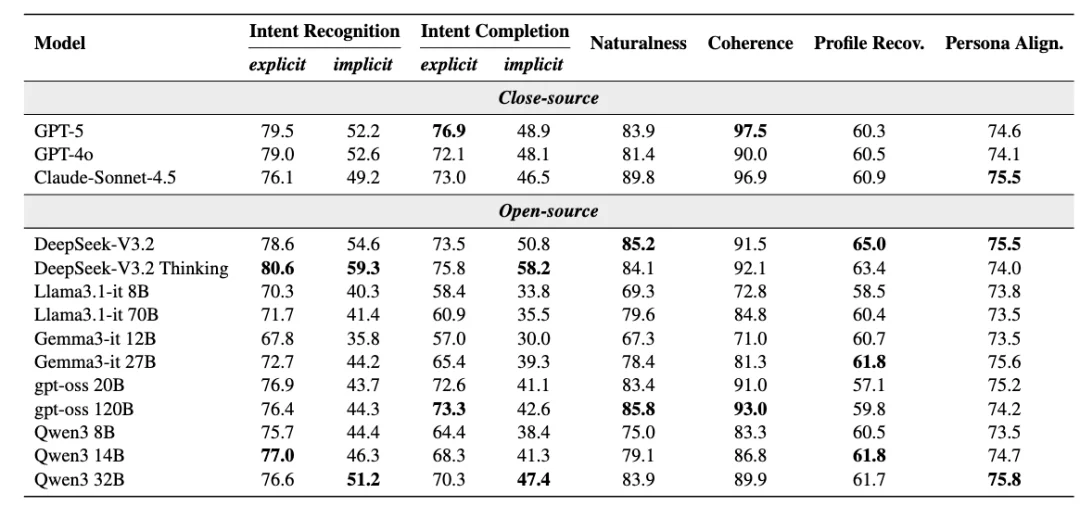
表 2:主流模型在 LifeSim-Eval 上的评测结果。
- 长程对话会进一步放大隐性意图处理难度
在长时程设置中,模型对显性意图的完成率相对稳定,但对隐性意图的完成能力明显更弱,且会随着历史长度增加而进一步下降。这表明现有模型虽然能够在长上下文中维持对表层任务的处理能力,但一旦需要基于长期证据进行用户状态与偏好推理,就会出现明显退化。
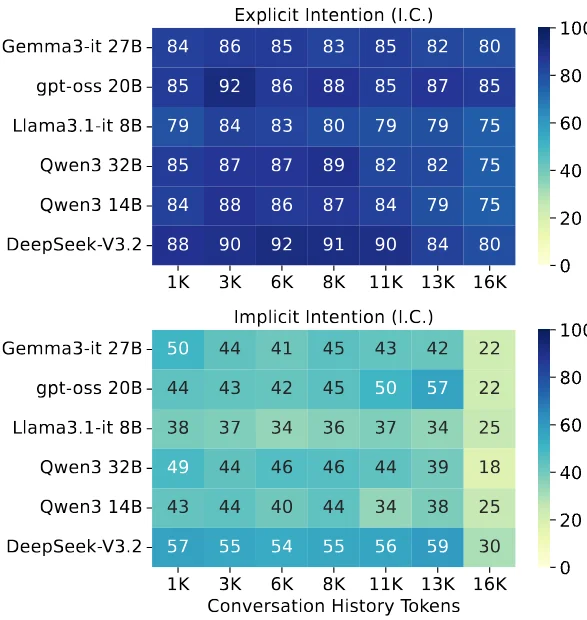
图 3:不同助手模型的长时序意图完成性能。热力图展示了意图完成度(I.C.)得分随对话长度的变化情况。
- 简单记忆机制收益有限
论文进一步测试了画像记忆机制:在每个场景后,让模型总结或更新用户偏好。结果显示,虽然这种做法对用户偏好的重建有一定帮助,但整体收益并不稳定,甚至有些模型几乎没有提升。这说明长期个性化能力的瓶颈并不只是「记不住」,更在于模型是否具备稳定的长期偏好推理能力。
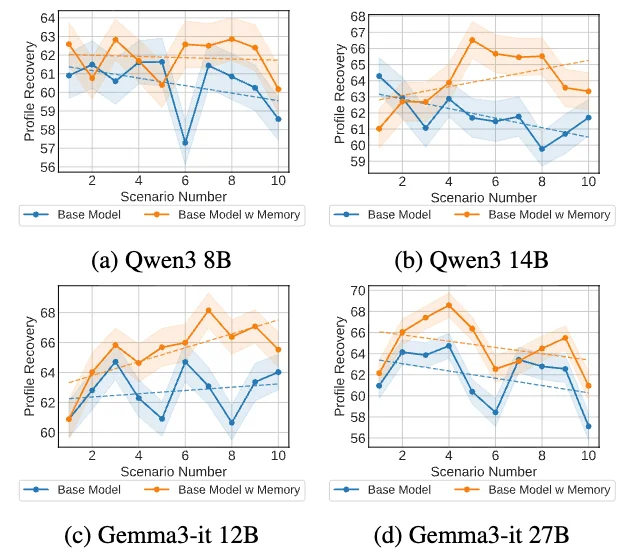
图 4:用户偏好还原性能随场景数量增长的变化。
不同意图类型和主题上的表现并不均衡
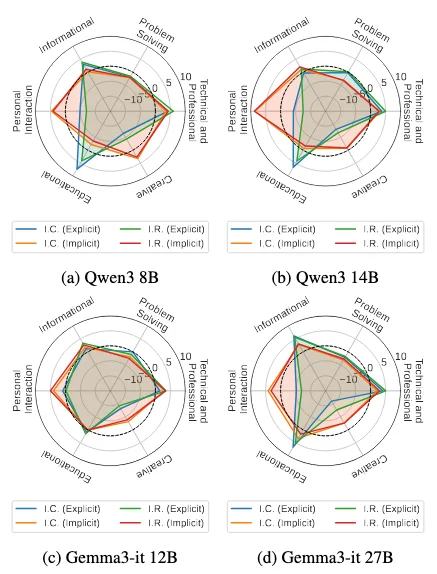
不同意图类型下的模型相对性能。
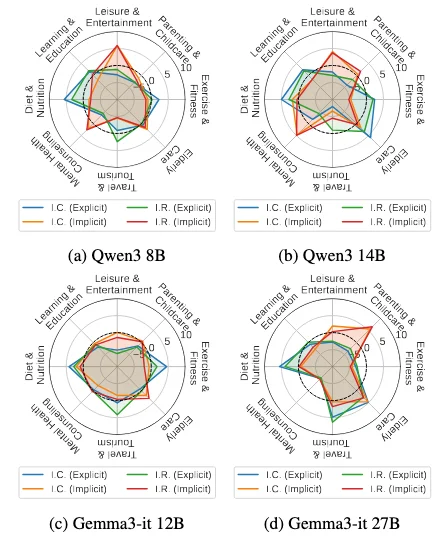
不同意图主题下的模型相对性能。
针对不同意图类别和主题的实验结果显示:在以显式、任务驱动需求为主的场景,与需要隐式、情感推理的场景之间,模型在显隐性意图任务的性能存在明显差异。这种异质性表明,当前模型在不同服务领域的鲁棒性参差不齐,需要我们在个性化助手设计中进行更细粒度的优化。
- 模型存在三类典型问题
通过案例分析,论文总结出当前模型在长期个性化助手任务中常见的三类问题:
- 推理僵化:模型容易固守最初的解决路径,面对用户新增约束时缺乏动态调整;
- 主动追问不足:即便关键信息尚不明确,模型也常直接给出建议,而不是主动澄清用户需求;
- 用户画像利用不足:虽然拥有正确的用户画像,但模型不能真正把它们融入回复策略中。
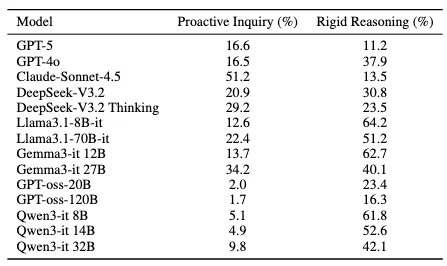
表 3:各模型的主动询问占比与僵化推理占比
总结
本研究提出了 LifeSim 与 LifeSim-Eval,系统性地将个性化助手评测从静态、短上下文任务扩展到面向长期用户生活轨迹的动态交互场景。与传统基准相比,LifeSim 不仅同时建模用户认知状态与物理环境,还进一步引入显性 / 隐性意图区分和长程交互设定,从而更真实地刻画个性化助手在现实生活中的使用挑战。
实验结果表明,当前主流 LLM 虽然已经能够较好地处理显性需求,但在隐性意图识别、用户偏好重建和长程用户理解方面仍然存在显著短板。此外,LifeSim 也提供了接近真实场景的个性化助手模拟环境,也为个性化数据合成提供新途径。
文章来自于微信公众号 "机器之心",作者 "机器之心"
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/

