南洋理工大学MMLab团队推出Hand2World,让AI世界模型真正「伸手」互动。只需在空中比划手势,模型就能生成逼真第一人称交互视频,实时响应调整。它摒弃旧有遮挡误导,用3D手部结构与射线编码解耦手与头运动,首次实现闭环持续交互。基于单目视频全自动标注,为AR、机器人交互铺路。世界模型不再只是「 看」,而是能「触」。
Sora能生成逼真的视觉世界,Genie 3能让你在3D场景中自由探索——但你始终只能「看」,没法伸手进去抓一下桌上的杯子。
当下的世界模型已经拥有了「眼睛」和「腿」——能感知环境、能移动视角,却始终缺少一双「手」。
能看能动但不能交互,是世界模型从被动观察迈向主动操控的最后一道坎。而人类与物理世界交互的最原生接口,就是手势。
南洋理工大学MMLab团队提出了Hand2World[1]——给一张场景照片,用户只需在空中做出手势动作,AI 就能生成手伸进场景里抓杯子、翻书、开盒子的逼真第一人称视频。而且这不是一次性生成:用户可以边看生成结果边调整手势,模型实时跟进——形成真正的闭环交互。

论文地址:https://arxiv.org/abs/2602.09600
项目主页:https://hand2world.github.io
为什么现有方法搞不定?
想象你训练了一个 AI,让它看了上万段人手抓杯子的视频。现在给它一只在空气中挥舞的手——它就无所适从了。因为训练数据里手永远被杯子、书本挡着一半,AI 从没见过「完整的手」长什么样。结果面对完整手形,它反而凭空生出了不存在的遮挡物。
这就是所有基于 2D 手部 mask 方法的致命伤——训练时看到的是残缺的手,推理时却收到完整的手,分布直接错配。下图清楚地展示了这一点:上排训练场景中 mask 被物体截断,下排凭空手势中 mask 完整,现有方法(如 CosHand)因此产生严重伪影。

mask分布错配 vs Hand2World的遮挡不变条件信号
雪上加霜的是,第一人称视频中手部运动和佩戴者的头部转动在画面上完全纠缠——模型分不清「是手在动还是头在动」,背景就会跟着手一起漂移。
近期也有工作尝试推进第一人称世界模型——如PlayerOne[2]通过第一人称与第三人称相机同步配对来建模自我运动,取得了重要进展。
但这一路线既限制了数据的可扩展性,也使实际应用受限。能否仅从单目视频出发,同时解决上述所有问题? 这正是Hand2World的研究出发点。
Hand2World怎么做到的?
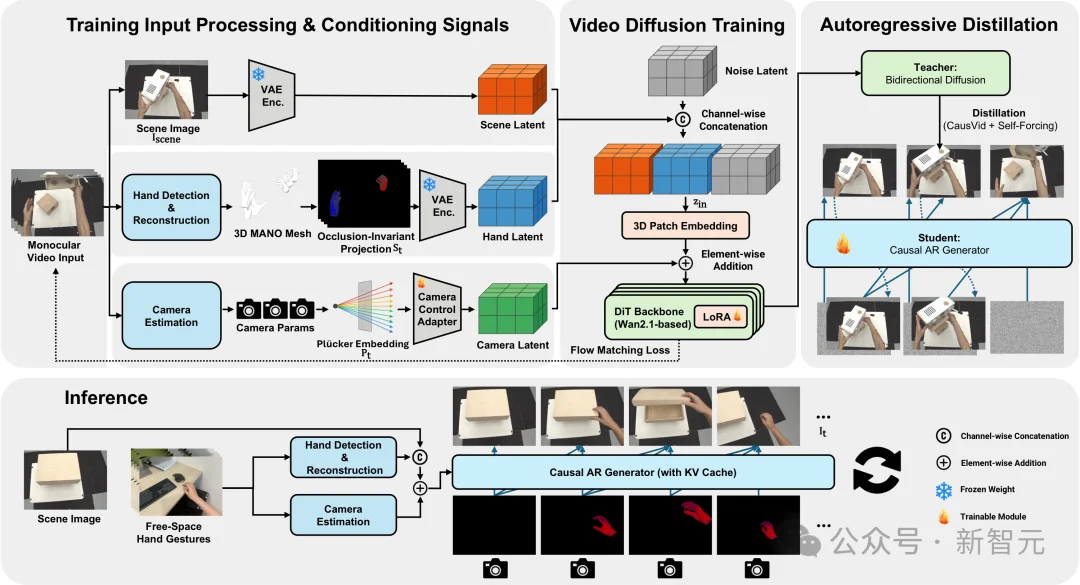
方法流程图
让模型「看见」完整的手
Hand2World彻底抛弃了2D mask。它从单目视频中恢复完整的 3D 手部 mesh(MANO 模型),投影到图像平面,渲染为「填充轮廓 + 线框叠层」的复合信号。无论手是否被物体遮挡,这个控制信号的格式始终一致。
关键 insight:遮挡关系不是硬编码在输入信号里的,而是交给生成模型根据场景上下文自行推断。 线框叠层还能在手掌朝向相机、手指相互遮挡时提供额外的关节结构信息——这是纯轮廓做不到的。
分清「手在动」还是「头在动」
移除相机建模模块后,FVD从218直接飙到815——背景开始跟着手一起漂移。
Hand2World 用逐像素的 Plücker 射线嵌入显式编码相机运动,通过一个轻量级adapter以加法方式注入扩散模型。这一招将手部关节运动和头部自运动彻底解耦。

相机控制消融对比。无相机条件时(上排)背景严重漂移,加入Plücker射线后(中排)与真实视频(下排)高度一致。
闭环交互,无限续写
Hand2World将双向扩散教师模型蒸馏为因果自回归生成器,通过 KV cache 维持时序连贯,支持流式输出。这使得整个系统形成闭环——用户边看边调整手势,模型持续响应,交互可以无限进行下去。
实验结果
三个数据集全面领先
在ARCTIC、HOT3D、HOI4D三个第一人称交互数据集上均取得最优结果。以 ARCTIC 为例:
- FVD:908 → 218(降幅 76%)
- 相机轨迹误差:0.13 → 0.07(降幅 42%)
- DINO 语义相似度:0.80 → 0.88
- 深度一致性:Depth-ERR 从 22.51 降至 16.14
蒸馏后的Hand2World-AR性能接近教师模型(FVD 232),单卡A100达 8.9FPS。
具身智能的数据飞轮:全自动单目标注
Hand2World 的训练数据从哪来?与 PlayerOne等依赖多目同步采集的方案不同,团队开发了一套全自动的单目标注流水线——不需要多目相机阵列,不需要人工标注,直接从普通的第一人称视频中自动提取手部 mesh、相机轨迹和训练数据对。这意味着任何一段现成的 egocentric 视频都可以被转化为训练信号——为具身智能的大规模数据收集提供了真正可扩展的方案。
从「看见世界」到「触碰世界」
作为将手势交互引入世界模型的一次初步尝试,Hand2World 构建了一套从数据标注到闭环生成的完整系统。在视频生成能力快速提升的当下,这套系统有望应用于 AR/MR 眼镜手势交互、机器人手-物交互数据合成、以及从单张照片构建可交互虚拟环境。
当世界模型不再只是被动地生成画面,而是能响应用户的每一个手势并持续演化——从「看见世界」到「触碰世界」的距离,或许比我们想象的更近。
参考资料:
[1] Wang et al., "Hand2World: Autoregressive Egocentric Interaction Generation via Free-Space Hand Gestures," arXiv:2602.09600, 2026.
[2] Tu et al., "PlayerOne: Egocentric World Simulator," Advances in Neural Information Processing Systems (NeurIPS), 2025.
文章来自于"新智元",作者 "LRST"。

