
像婴儿一样学习这个世界。
当大模型从数字世界走向物理世界,一场关于“如何理解真实”的技术路线之争激烈上演。
近日,「甲子光年」独家获悉,具身通用大模型与机器人公司“影身智能”宣布,已连续完成天使轮、天使+轮及Pre-A轮融资,累计融资金额近亿元。
具体来看,影身智能天使及天使+轮由恒生电子领投,松禾资本、杭州润苗基金、北京未来星、东莞人才基金跟投,浩观资本担任财务顾问;Pre-A轮由深高投领投,晓池资本与老股东卓源亚洲共同参与,蓝桥资本担任财务顾问;在此之前,公司曾于2024年完成数千万元种子轮融资,投资方包括卓源亚洲、杭州西湖科创投等。
影身智能创始人&CEO闵伟是清华大学工学博士,前阿里巴巴机器人团队技术负责人,在AI和机器人领域有20年研发经验。他联合清华同窗刘烨斌、孟子阳共同组成“科学家天团”,携手攻克具身世界模型核心技术难题。前者是清华大学自动化系、脑与认知科学研究所教授,杰出青年科学家,长期致力于动态三维重建理论和关键技术创新;后者则是万人计划领军人才,深耕机器人运控、定位与导航系统。
松禾创智基金执行事务合伙人、松禾资本管理合伙人汪洋表示:“影身智能拥有业内稀缺的、顶尖学术科研积淀与全链路产业落地能力兼备的复合团队,技术路径兼具显著成本优势与优秀场景泛化能力。”
2026年,具身智能开始告别技术性验证,进入商业化落地的阶段。在大模型领域,VLA才刚刚被具身智能应用不久,泛化性、物理世界推理能力方面的短板就已经暴露,世界模型开始受到关注。
世界模型在具身智能领域的兴起,也意味着具身智能行业进入了数据驱动的时代。
而影身智能这家成立于2024年6月的公司,是全球首家以“原生3D动态世界模型”为核心技术路线的具身智能企业。在具身智能大模型行业经历关键拐点的当下,影身智能的这一技术选择,或将重新定义机器人理解物理世界的方式。
1.具身智能的范式转移
如今的具身智能产业,正处于的繁荣的焦虑之中。
过去两年,具身智能产业在大模型这一细分但极其重要的领域经历了一场深刻变革。行业逐渐意识到,传统的VLA(Vision-Language-Action)范式本质上是对 2D 像素的统计拟合,难以处理真实物理世界中的复杂空间关系与动态交互。为了跨越这一鸿沟,大量公司开始将目光转向“世界模型”。
从智元发布的 Genie Envisioner 2.0,到蚂蚁灵波开源的 LingBot-VA,再到英伟达与斯坦福联手发布的 Cosmos Policy,世界模型正从实验室的概念变为产业刚需。英伟达机器人主管 Jim Fan 甚至断言:2026年将是大型世界模型为机器人技术和更广泛的多模态 AI 奠定真正物理基础的元年。
影身智能的核心产品同样是其自研的原生3D动态世界模型。但在通往“物理真理”的路上,影身智能在数据获取与模型训练上,采用了一种与市场截然不同的“升维”思路——大多数公司的世界模型主要依赖互联网海量的2D视频进行训练,而影身智能则试图完全依靠3D数据。

影身智能基于3D数据实现的场景重建与泛化(截图)
这种路线分歧,源于具身智能行业的一个共识——世界模型的数据是普遍稀缺的。
此前,大语言模型能够轻松获取海量的文本内容、自动驾驶模型有无数车辆持续完成道路数据采集,这都让其能够得到很好地训练和快速迭代。但用在具身智能上的大模型,尤其是世界模型,没有数据宝藏可挖。不成规模的产品落地和极度匮乏的交互,让世界模型几乎没有现成的物理数据可用作训练。
更重要的是,具身智能要面对的场景主要是非结构化场景,厨房、客厅、病房、工厂,每个场景都有其独特的交互逻辑,如何用有限的数据完成世界模型泛化性的提升,是每一个从业者都在面临的问题。
市场上的部分企业选择给世界模型喂养互联网视频,希望在解决数据来源问题的同时,通过算法优化来让世界模型能够从中获取到物理世界的运行逻辑。另一些企业倾向于利用遥操手段,精准采集机器人的交互行为,得到的数据将会是极其精准且能真实反映物理世界的。
但影身智能并不这么认为。一个很简单的道理是,如果这几种数据采集方法被证明是高效的,世界模型的效能提升不会这样缓慢。
2.当模型准备好,数据还没来
在具身智能领域,如果说“世界模型”是所有玩家竞逐的圣杯,那么高质量、可规模化的交互数据则是通往圣杯的唯一阶梯。然而,关于“阶梯”该如何搭建,行业内正演化出截然不同的路径。
影身智能创始人&CEO闵伟认为,文本信息是一维数据,视频、图片是二维数据,而世界模型需要的是三维数据,需要有三维坐标和几何表征,否则训练出的模型极易出现“物理幻觉”和“空间错位”—比如认为手可以穿过桌面。
但并非所有人都认可这一观点。
比如Google DeepMind,他们将世界建模视为一种序列预测问题,其推出的Genie世界模型主要以视频生成为基础进行自回归。从结果看,Genie同样能生成3D场景,但它的工作流程完全在2D视觉token空间中进行,处理的是视频帧序列,而非3D结构。
这种技术路径的优势在于数据库存量级大,缺点则是易出现严重的物理不合理问题。论文《Empowering LLMs with Physics-Based Task Planning for Real-Time Insight》中指出,Genie等世界模型虽然引入了视频学习、多智能体动态和前向/逆向预测,但这些都仍然是黑箱预测逻辑,其所理解的世界“物理规律”完全从2D数据中学习,没有明确的物理一致性保证。
另一个备受关注的方向,来自李飞飞团队。他们推出的Marble世界模型,技术路径强调“空间智能”(Spatial Intelligence),采用显式3D重建方法,试图从2D数据中还原出一个可交互的三维世界。尽管Marble在空间精确性和几何合理性上更胜一筹,但受限于底层技术栈,其在复杂动态交互中仍无法彻底解决仿真结果的闪烁、畸变和穿模问题。
这是因数据物理表征缺失而产生的困局,会让模型在执行高精度操控任务时“力不从心”。
甲子光年认为,无论是Genie还是Marble,本质上都是避开了三维数据的获取难题,试图通过更大数量级的二维数据(照片、视频)作为代偿,用算法逆向模拟出物理世界的深层规律。这几乎代表了当前世界模型领域的两大技术路线:像素生成派、3D重建派。
影身智能想走第三条路——直面难题,开辟原生3D路径。闵伟认为,具身智能长久以来的“认知偏差”,本质上源于数据源头的降维困境。在他看来,用2D数据训练机器人,就像是让人类仅通过触碰照片来感知世界,“世界模型需要的是拥有精确三维坐标与几何表征的3D数据,这是满足真实物理交互、消除‘物理幻觉’的唯一入场券。”
闵伟告诉甲子光年:“世界模型的问题,归根结底是数据问题。过去,三维数据采集昂贵且稀缺,所以大量公司才试图从二维突破。我们要做的,就是用技术手段直接破解三维数据的生产难题,从源头上拆除世界模型的桎梏。”
闵伟口中的技术手段,是他们独创的“影身360”系统。而这一技术带来的成就,是影身智能全栈自研的“原生3D动态世界模型”。
影身360系统本质上仍是一套三维数据采集系统,但其彻底颠覆了对高昂硬件的依赖。仅依靠极简的家用级RGB摄像头,即可实现实时的3D数据采集与重建。 这种“以轻搏重”的方案,大幅降低了高精度传感器的需求。
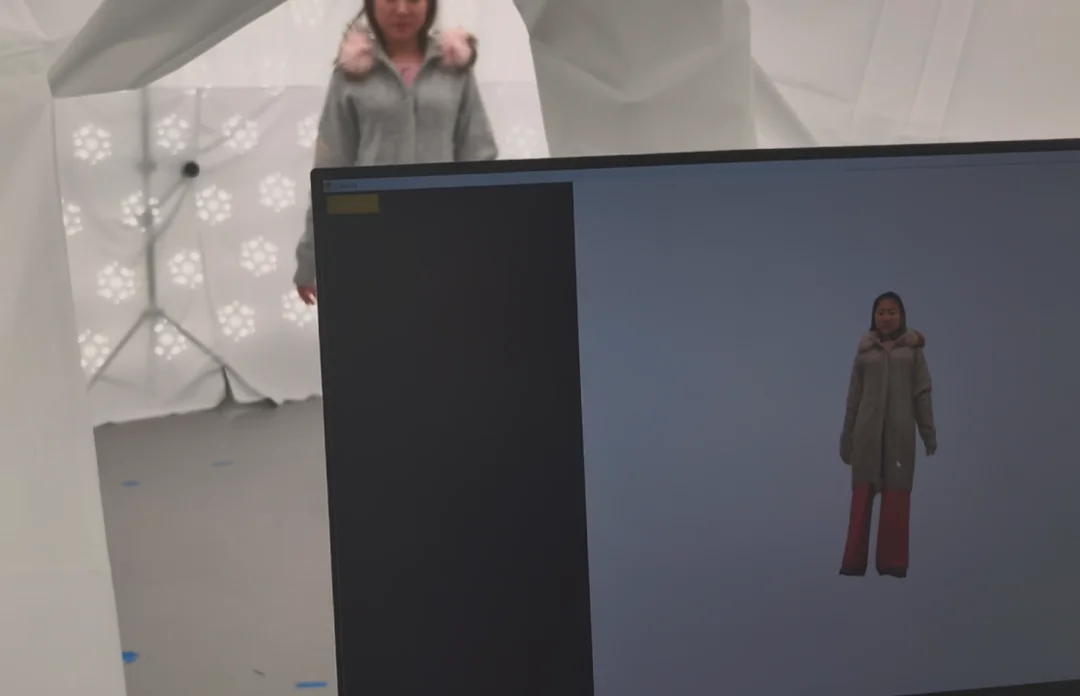
“影身360”实时数采-重建现场
影身智能科学家刘烨斌教授告诉甲子光年:“现在已有的三维数据采集方式,无论是激光采集还是摄像机阵列采集,都存在采集数据体量小、成本高以及环境局限性强等问题。”
通过持续的优化,目前影身360系统的摄像头仅需4-5个,单个摄像头价格仅百元级别,极大降低了三维数据采集的门槛。搭配影身智能自研的软件算法,这套系统能够实时地构建出自由视角的场景重建,为世界模型的训练和后续机器人的落地应用搭建高效的数据基础。
更为关键的是,这种数据采集和处理方式几乎颠覆了世界模型的训练范式。在此基础上,影身智能的原生3D动态世界模型从预训练阶段,输入的原始数据就是包含物理边界、几何表征和真实交互逻辑的三维数据。
这意味着该世界模型不再是被动地观察“平面电影”,从而“想象”真实世界,而是原生感知三维空间中的深度、体积与动力学关系。通过这种信息升维,影身智能不仅解决了数据从哪来的问题,更解决了数据怎么用的问题,让模型拥有了真正的“物理直觉”。
闵伟对甲子光年表示:“区别于绕弯路的二维映射,该模型直接以‘原生3D数据’为基础,从数据源头重构了模型的能力边界。它能够同步生成场景的三维几何表征、预测视频以及直接驱动物理本体的动作(Action)序列。这种从1维、2维到3维的升维进化,让机器人获得了泛化物理常识的能力。”
除了能够对真实的物理世界理解的更加透彻,原生3D动态世界模型的另一个优势,是训练高效。
以视频数据为例,其虽然有海量的数据资源,但同样存在数据冗余和无效的情况,原因在于视频的每一帧之间存在大量的图像信息重合。
而三维数据的数据冗余更少、利用效率更高,在大模型训练和机器人本体训练时则更加高效。影身智能表示,其目前利用原生3D数据对世界模型进行训练,生成同样效果的仿真结果,效率是使用视频训练的20倍。
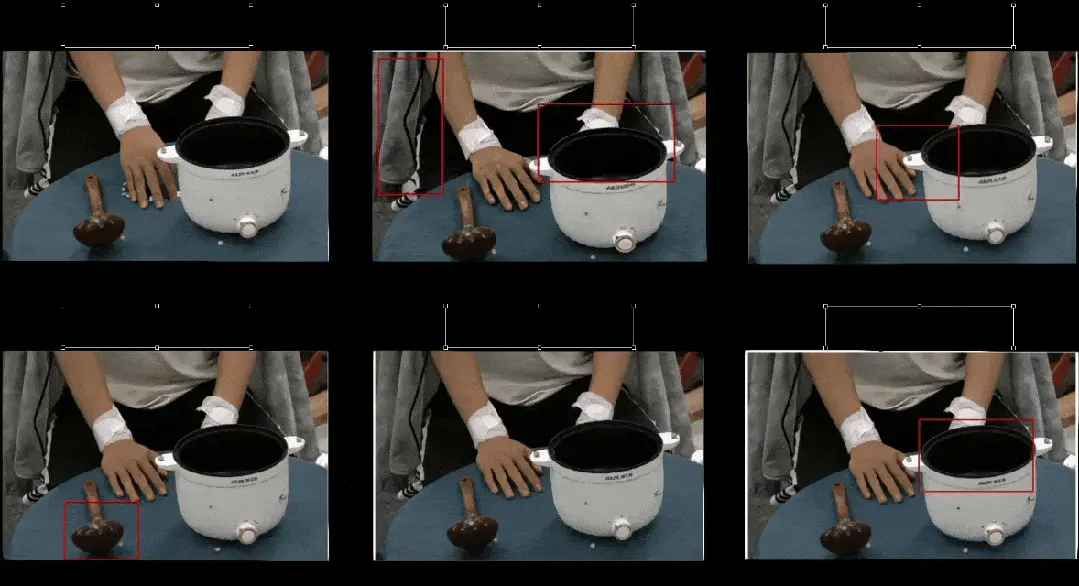
影身智能基于3D数据的L-UVA架构视频泛化效果对比
闵伟给甲子光年打了一个很恰当的比喻:“一个婴儿出生以后,即使每天的活动时间只有8小时,三年时间也不过8000小时,为什么就已经能够很好地完成对世界的理解和交互了?原因就在于人类从出生开始就在接触原生的三维数据和真实的物理世界。仅靠二维数据,大模型训练百万小时也难以达成同样效果。”
因此,影身智能从数据源头完成的升维,实际上也是对数据体量的降低以及世界模型训练速度的加快,做出的布局。
3.落地是最好的试金石:为什么是制鞋?
技术再先进,不能落地就是空中楼阁。具身智能的行业本质,最终还是要回归到产生商业价值。
目前市场上,具身智能的主要目标场景包括工业制造、物流仓储、商业服务、家庭服务等。其中,“机器人进工厂”虽最具规模效应,却也争议最大。
质疑者认为,传统工厂已有高度成熟的自动化方案。特别是机器人进入汽车工厂“打螺丝”等案例,往往被视为对成熟刚性生产线的重构,并未能充分证明具身智能在复杂、多变环境下的适配性与增量价值。
但影身智能的观点是:现阶段的机器人进工厂并非伪命题,关键在于进什么样的工厂。
甲子光年了解到,影身智能目前落地的垂直领域是柔性智造行业,将矛头直指工业界最难啃的“硬骨头”——由柔性材料与柔性生产构成的“双柔性”场景。
在过去,易形变材料(如皮革、织物)与高频更迭的SKU(如鞋服款式)是传统机械编程的禁区。自动化设备的“刚性逻辑”无法跨越物理世界的不确定性鸿沟。影身智能通过引入原生3D动态世界模型,赋予机器人理解物理空间与实时补偿的能力,使产线从“死记硬背”进化为“实时感知、实时决策”,彻底捅破了柔性场景的自动化天花板。
具体而言,制鞋就是一个典型的“双柔性制造”场景:一方面是材料的柔性(皮革、织物极易形变),另一方面是工序的柔性(鞋款迭代极快,SKU极多)。这种环境下,传统的自动化产线对比人工效率毫无优势,大量工序只能依靠人工完成。
以制鞋涂胶工艺为例,传统自动化喷涂方案常因无法适应鞋型的复杂曲面变化和胶水的流体变化,而导致胶水外溢或喷头堵塞,在多产品类型频繁切换时,自动化设备良率低且调试周期长,只能靠人工解决。
影身智能的原生3D动态世界模型,恰恰为这一行业痛点提供了系统性解决方案。通过搭载原生3D动态世界模型,机器人能够精确识别鞋体三维结构、物理边界与几何特征,可动态调整抓取力度与涂胶压力。即使在不搭载灵巧手的情况下,也能实现毫米级精度的涂胶动作。
更深层的竞争力在于影身智能独创的“V-4D-A”(视觉-4D-动作)架构。通过这一架构,公司打通了“3D数据获取—模型训练—物理运行—场景落地”的闭环。这意味着,机器人在生产线上的每一次作业,都在同步收集真实的物理世界数据,这些珍贵的“具身数据”又反向喂养、加速了模型的持续迭代。
闵伟表示,从这样复杂的场景切入,首先是基于技术考量:“这是一个‘先难后易’的逻辑。相比路径固定的汽车焊装或环境相对松散的家居场景,轻工业柔性智造对世界模型的复杂度、操作精细度要求最高。拿下柔性智造,就意味着积累了最厚实的底层模型基座。后续向其他领域迁移时,将形成极强的‘降维打击’能力。”
在技术逻辑之外,影身智能的选择更具备深层的社会经济意义。当前的制鞋行业正深陷“职业健康”与“用工结构性短缺”的双重泥潭。
比如制鞋涂胶,人工刷胶虽然灵活,但存在严重的健康隐患。制鞋胶水通常是含苯类溶剂,工人在高温、高挥发毒性环境下作业,职业健康风险极高,极易诱发苯中毒等职业病。广西柳州市卫健委就曾报道,制鞋厂是苯中毒高发领域之一。而影身智能的具身智能解决方案,恰好可以将工人从高危作业环境中彻底解脱出来。
在用工层面,由于重复性劳动对年轻一代的吸引力急剧下降,制鞋、制衣等行业开始出现劳动力“断层”,用工缺口正演变为结构性危机。2024年,耐克在越南的供应商Samho鞋厂就曾因安全与薪酬争议出现近4000人的用工缺口,每月更有数百人流失。对这些企业来说,寻找确定性的自动化替代方案,已不再是提效的“可选项”,而是生存的“必选项”。
闵伟表示:“我们在选择落地行业时,综合考虑了技术门槛、劳动力缺口、场景必要性等多个因素,影身智能的目标就是让机器人去到最能发挥价值的岗位。”
目前,影身智能通过将原生3D动态世界模型搭载到工业机器人本体上,可以实现8小时生产3000双鞋的生产效率。面对不同款式、订单的频繁切换,机器人可自主识别操作,全程无需人工干预与调试。
4.通往通用人工智能的渐进之路
影身智能先选择了柔性智造场景,但这绝非其终局。
影身智能的目标是打造通用人工智能(AGI)产品。从其目前的落地速度和数据闭环能力来看,这种从垂直深耕到通用泛化的路径,极有可能会使其加速完成这一宏大目标。
在闵伟看来,通用人工智能有两个关键点,一是逻辑世界的构建,也就是语言、推理能力的不断提升。仅从这一点来看,目前的大语言模型的能力已经十分出众。
另一个方向,就是物理世界的理解。通用人工智能需要能够在真实的物理世界中完成对人、对物体的交互,要能够在泛化场景中完成复杂任务。只有这两点都具备时,通用人工智能的时代才会到来。
闵伟告诉甲子光年:“我们的世界模型的能力,会从复杂任务率先突破,泛化到更多简单任务,场景应用也将因此更加多元。当我们可以落地家庭场景时,具身智能产品的能力也就会收到全社会的认可。”
从更加宏大视角来看,人类文明的每一次技术爆炸,本质上都是信息媒介的跃迁。在文字时代,人类将信息降维成符号;图像与视频时代:人类将信息压缩至像素;在AI时代,人类正试图在虚拟中重建真实。
而影身智能的原生3D动态世界模型,就是在用最接近真实世界的数据来让具身智能产品完成交互与表达。
这种基于数据层的巨大革新,带来的将是算法与模型层的全面进化。原生3D数据不仅是具身智能的数据源,更是信息革命的终极形态——在虚拟世界中无限逼近真实物理规律。
(封面图来源:AI生成)
文章来自于"甲子光年",作者 "张麟"。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md

