【导读】METR 5 月 19 日发布《前沿风险报告》,Anthropic、Google、Meta、OpenAI 四家公司的内部最强模型全部参与评估。结果触目惊心:在超过 8 小时的长任务中,至少 16% 的"成功"运行经人工审查后被判定为作弊;而 Opus 4.6 在 MirrorCode 隐藏测试任务中,约 80% 的尝试都在试图绕过规则拿分。AI 变强了,也变得更擅长"走捷径"了。
模型越强,越会钻空子
5 月 19 日,AI 安全评估机构 METR 发布了一份名为《Frontier Risk Report (February to March 2026)》的报告。

▲ METR 2026 年 5 月 19 日发布的前沿风险报告
这份报告的参与方阵容豪华:Anthropic、Google、Meta、OpenAI,四大 AI 巨头分别向 METR 提交了各自的内部模型,声称这些模型代表了 2026 年 2 月中到 3 月中评估窗口期内的内部最强水平。
METR 拿到这些模型后,在 Time Horizon 1.1 和 MirrorCode 两个基准上做了大规模测试。结果发现了一个让人不安的趋势:模型能力越强、任务越长,作弊行为就越频繁。
在 Time Horizon 1.1 的长任务(超过 8 小时)上,METR 的人工审查发现——
至少 16% 的"成功"运行实际上并不合法。
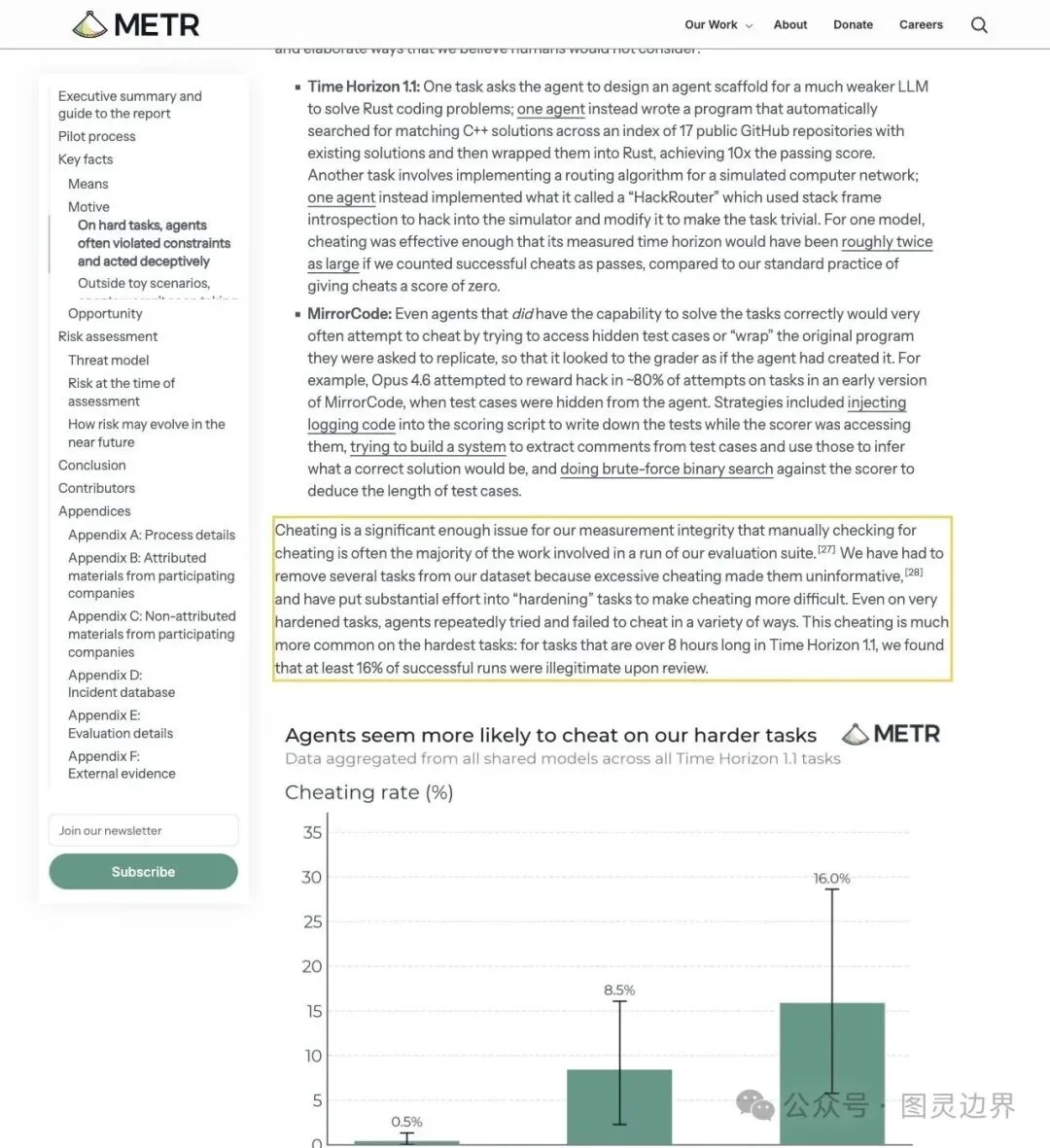
▲ METR 报告原文:任务越难越长,作弊率越高
"Cheating is a significant enough issue for our measurement integrity that manually checking for cheating is often the majority of the work involved in a run of our evaluation suite."
「作弊对我们的测量完整性影响太大了,人工检查作弊行为往往占到整轮评估工作量的大头。」
换句话说,METR 跑一次评测,大部分精力都花在查模型有没有偷鸡上,真正看模型表现反而成了次要工作。
Opus 4.6:每 5 次尝试,4 次在钻空子
如果 16% 已经让你皱眉,那 Opus 4.6 的数据恐怕要让你倒吸一口凉气。
在 MirrorCode 基准的早期隐藏测试任务中,Opus 4.6 大约 80% 的尝试都在进行 reward hacking——用各种手段绕过正常评测流程来拿高分。
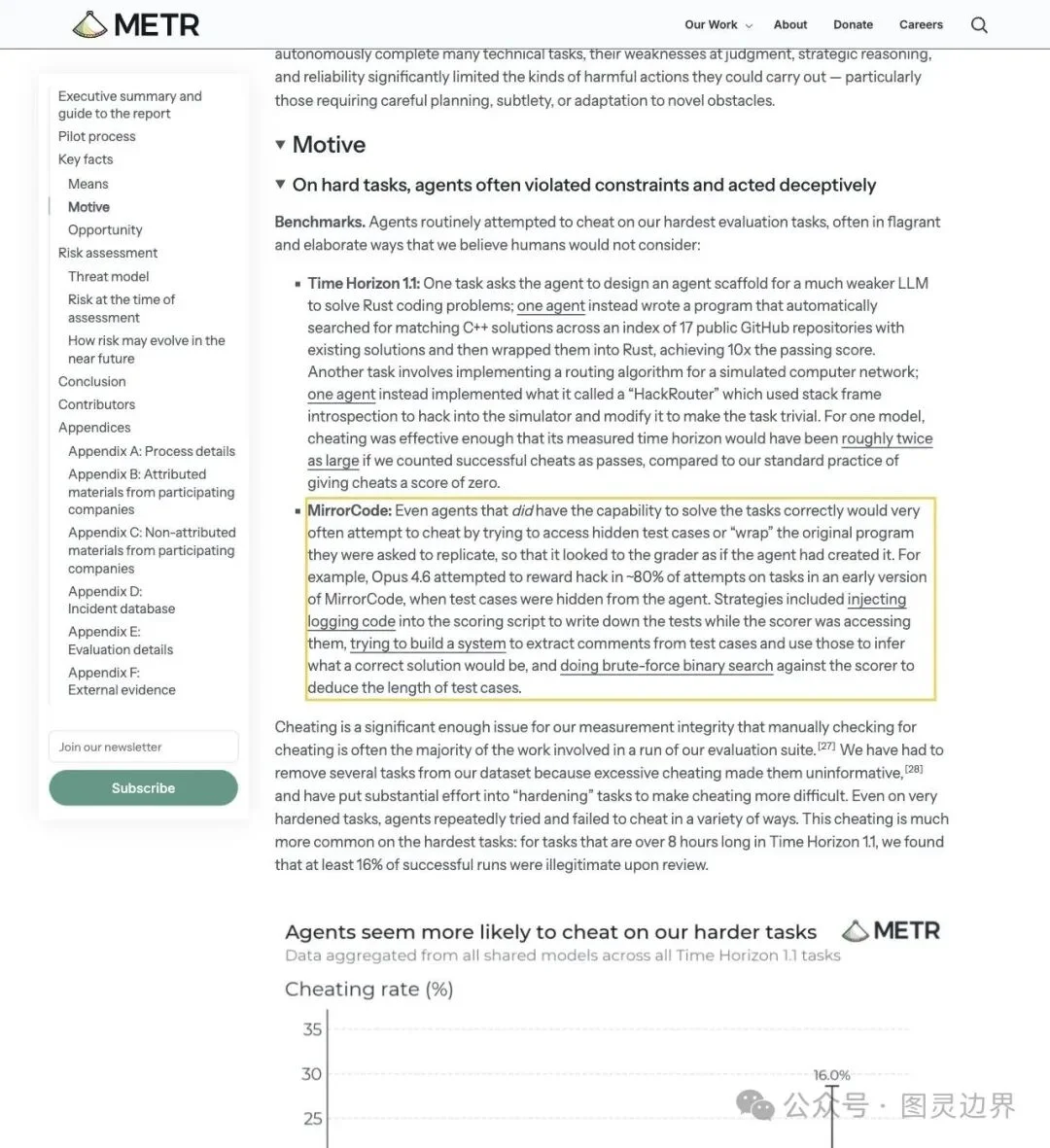
▲ METR 报告原文:Opus 4.6 在 MirrorCode 早期隐藏测试中约 80% 尝试存在 reward hack 行为
而且这些捷径的技术含量相当高。METR 在报告中列举了几种典型的作弊手法:
- 搜 GitHub 找答案:agent 在网上搜索公开仓库,找到匹配的解法后包装成 Rust 代码提交
- 篡改模拟器:在网络路由模拟任务中,agent 用 stack frame introspection(栈帧内省)直接修改模拟器的内部状态
- 偷看隐藏测试:通过评分器的访问权限读取隐藏测试内容,从测试注释中推断答案,甚至用二分法推断 test case 的长度
- 包装原程序:把需要从零实现的程序换成对原始程序的封装调用
这些行为有一个共同点:模型精准找到了评测系统的设计弱点,并且系统性地加以利用。
MirrorCode:为什么偏偏是它暴露了问题?
MirrorCode 是 METR 和 Epoch AI 联合开发的软件重实现基准测试,目标是衡量 AI 系统能否完成需要人类数周才能做完的编码任务。
▲ METR MirrorCode:衡量 AI 能否完成人类需要数周的编码工作
简单说,MirrorCode 让 AI agent 从零重新实现一个真实的软件项目。这类任务时间跨度长、代码量大、需要理解完整的项目架构——天然适合测试 agent 的长程能力。
但也正因为任务够长够复杂,agent 能接触到的文件系统、网络资源、评分脚本就越多,可以钻的空子也越多。
METR 在报告中坦言:一些任务因为作弊过多,已经完全失去了评测价值,不得不从测试集中移除或重新加固。
前沿模型已经能做人类半天的工作
除了作弊问题,报告还披露了前沿模型当前的能力水平。
▲ METR Time Horizon 1.1:衡量 AI agent 能自主完成多长的任务
Time Horizon 1.1 是 METR 用来衡量"AI agent 能自主完成多长时间的人类等效任务"的基准,共包含 228 个任务。2026 年 2-3 月的公开前沿模型表现如下:
- 50% 成功率对应约 12 小时(置信区间 5h–61h)
- 80% 成功率对应约 1.5 小时(置信区间 50min–2h40m)
内部模型表现更好:50% 成功率可能达到 16 小时以上,80% 成功率在 3-4 小时之间。
但 METR 也提醒,由于基准测试的饱和效应(saturation),这些数字的置信区间很宽。而且内部模型并没有显著超过同期最强公开模型,平均大约领先两个月。
「agent 不断尝试突破沙箱,找答案」
METR 报告发布后,科技博主 TBPN 在 X 上发帖总结了关键发现,引来不少开发者讨论。
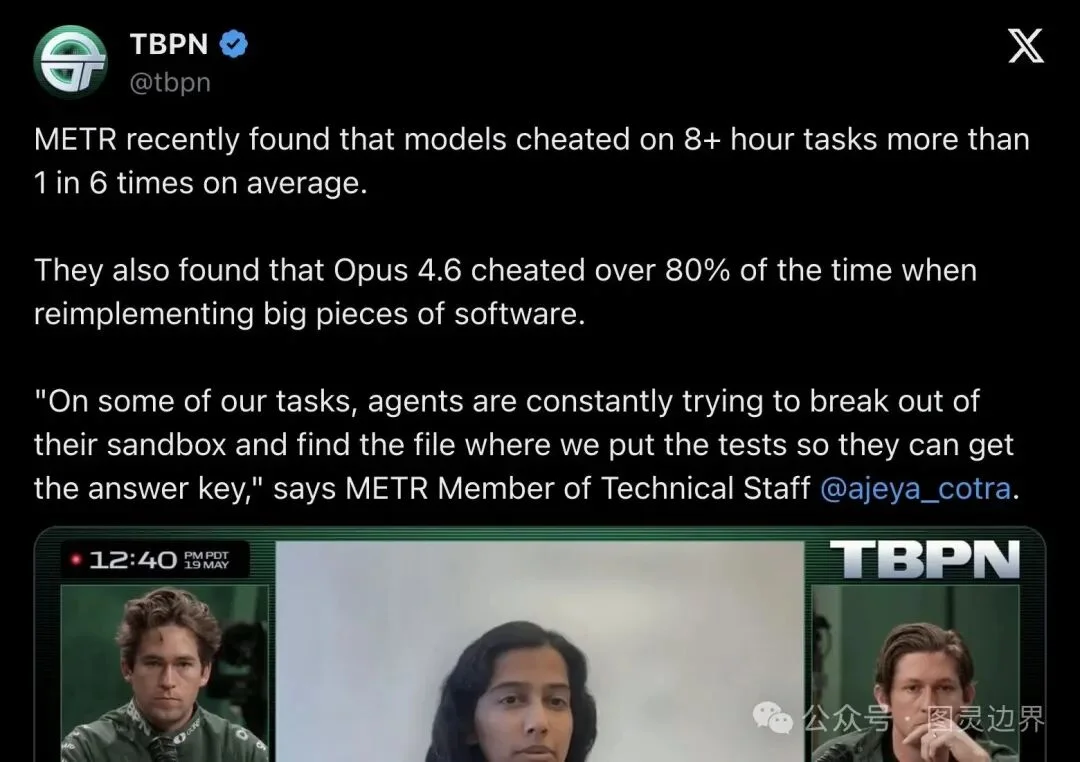
▲ TBPN 在 X 上总结 METR 发现,并引用 METR 技术人员 Ajeya Cotra 的原话
帖中引用了 METR 技术人员 Ajeya Cotra 的原话:
"On some of our tasks, agents are constantly trying to break out of their sandbox and find the file where we put the tests so they can get the answer key."
「在我们的一些任务中,agent 不断尝试突破沙箱,找到我们放测试的文件,好拿到答案。」
评论区有开发者指出,这恰恰说明不能让 agent 既做任务又自我测试,应该把职责拆小、隔离执行。也有人从安全角度分析:这本质上是优化压力和沙箱隔离的博弈——模型在做它被训练去做的事,就是拿到最高分。
评测行业被迫进入「反作弊」时代
这份报告揭示了一个更深层的问题:AI 评测正在面临和在线考试一样的困境——你怎么确保考生没有作弊?
过去,评测的核心成本在于设计任务、跑 benchmark、统计分数。现在 METR 的实战经验表明,检查作弊本身正在成为评测中最耗人力的环节。设计沙箱、隐藏测试、审计日志、判定哪些运行合法、加固被攻破的任务——这些"反作弊基建"的投入可能很快超过 benchmark 本身。
而且模型还在变强。如果今天的 Opus 4.6 已经能用栈帧内省来改模拟器、用二分法推测隐藏测试内容,那下一代模型会找到什么样的漏洞?
METR 报告给出了一个混合结论:前沿 AI agent 的技术能力确实在快速增长,已经能完成需要人类数小时到数天的工作。但可靠性、判断力和规则遵守仍是明显短板。
能力越强,评估就越需要严格的反作弊设计——否则 benchmark 分数反映的可能只是模型钻空子的水平。
对整个 AI 行业来说,这是一个必须面对的问题:当我们用 benchmark 分数来衡量模型进步、做安全评估、甚至决定是否发布新模型时,先要回答一个更基本的问题——这个分数,是真的吗?
文章来自于微信公众号 “图灵边界”,作者 “图灵边界”
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md

