推理效率和质量是大模型领域永恒的命题。
主流推理模型的共同选择是:生成更多的中间 token,用链式思维(CoT)把推理过程写出来。推理越深,生成的 token 越多,延迟越高,成本越大。
就在几天前,LeCun 在最新播客中再次旗帜鲜明地表态:大语言模型的自回归生成并非通向 AGI 的正确路径,真正的智能应当在潜在空间中通过规划和推理来实现。
现在,图灵奖得主 Yoshua Bengio 给出了一份全新的并行方案。
他们提出了 GRAM(Generative Recursive reAsoning Models,生成式递归推理模型),把确定性的递归潜在推理变成了概率性的多轨迹计算。模型在潜在空间中进行随机递归推理,每一步都可以采样不同的方向,最终形成对解空间的多路径探索。
实验结果令人印象深刻:GRAM 在仅用 16 步递归 + 20 条并行采样的情况下,就超越了所有确定性基线在 320 步串行递归时的表现。

- 论文标题:Generative Recursive Reasoning
- 论文链接:https://arxiv.org/abs/2605.19376
- 项目主页:https://ahn-ml.github.io/gram-website
从「单轨确定」到「多轨概率」
要理解 GRAM,首先需要了解它要解决什么问题。
当前的递归推理模型(Recursive Reasoning Models, RRMs)已经展现出一种有前景的计算范式:通过共享参数的转移函数,对持久潜在状态进行迭代精炼。这种方式将推理深度与参数规模解耦,一个紧凑的模型通过反复应用相同的转移函数,就能执行多步内部计算。
然而,现有的 RRMs 存在一个根本性问题:它们是确定性的。给定相同的输入和初始化,模型只能沿着一条固定的潜在轨迹前进,最终收敛到一个唯一的预测结果。当问题存在多个有效解(如 N-Queens 问题),或者单条推理路径容易陷入局部最优时,确定性递归就会力不从心。
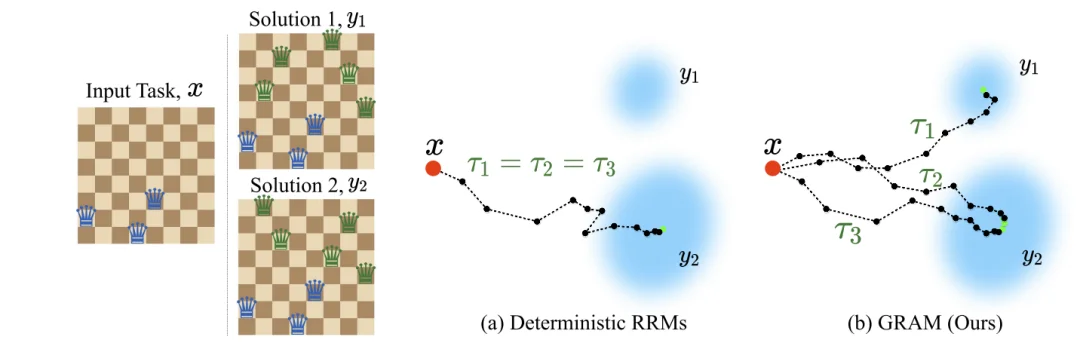
潜在推理轨迹对比。左图:N 皇后问题示例,存在两个有效解。右图:给定潜在推理的三次独立运行轨迹(τ1、τ2、τ3):(a)以往的递归推理模型(RRMs,例如 HRM、TRM)是确定性的,所有运行都会坍缩到同一条轨迹,最终收敛到单一解,因此无法探索其他可能解。(b)GRAM 则能够探索多样化的轨迹,生成不同的推理路径,并到达多个有效解 y1 和 y2,同时自然支持推理时的并行扩展。
GRAM 的解决方案很直观:在递归推理的每一步引入可学习的随机性。
具体来说,GRAM 在每一步递归中,先由确定性模块计算一个「提议更新」u_t,然后从一个状态相关的高斯分布中采样一个「随机引导信号」ε_t,将两者相加得到新的潜在状态:
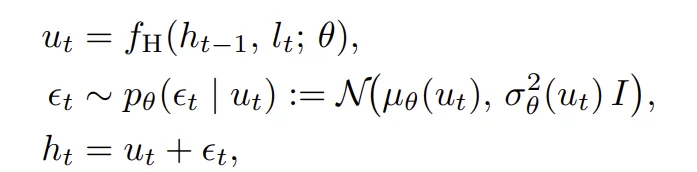
其中,均值 μθ 编码了一个状态相关的引导方向,方差 σ²θ 控制探索的幅度。这个设计让模型在保留确定性精炼能力的同时,能够捕获不确定性、避免局部最优,并支持对解空间的充分探索。
层次化架构设计
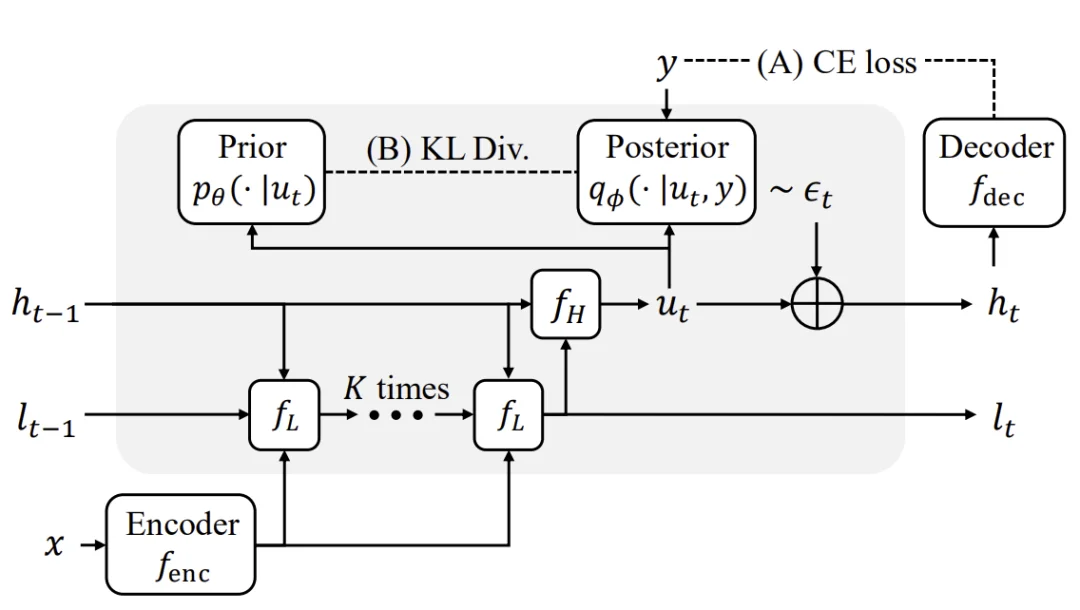
GRAM 架构图
GRAM 采用了层次化的潜在状态结构,将状态分为高层 h 和低层 l 两个组件:
- 低层组件 l 在每次转移内部被快速更新 K 次,承担细粒度的中间计算;
- 高层组件 h 每次转移只更新一次,承载抽象的推理状态。
随机性只注入到高层组件中。这意味着随机引导作用在更慢、更抽象的推理层面,引导整体推理轨迹的方向,而不干扰低层的精细计算。
训练方法
作为一个概率模型,GRAM 通过变分推断进行训练。模型定义了先验分布 pθ(τ|x)(推理时使用)和变分后验 qφ(τ|x,y)(训练时使用,可以看到正确答案 y)。训练目标是最大化证据下界(ELBO):
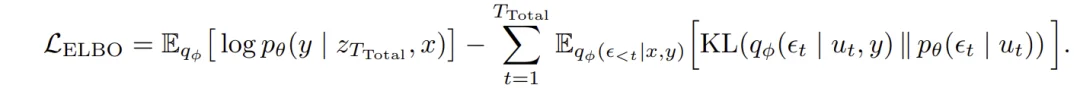
- 重构项:鼓励模型从采样的轨迹中得到正确预测
- KL 散度项:约束后验与先验之间的距离
训练时,后验能够「看到」正确答案,从而学习到哪些随机引导方向能够通向正确解。推理时,模型只使用先验来采样轨迹,而先验已经通过训练习得了有效的探索策略。
双轴推理扩展:深度 × 宽度
GRAM 的一个重要贡献是提出了推理时计算的「双轴扩展」策略。
深度扩展(串行): 增加递归步数。与之前的递归推理模型一样,GRAM 支持自适应计算时间(ACT),允许每条轨迹在学习到的停止深度处终止。
宽度扩展(并行): 从先验中采样多条独立的推理轨迹,每条轨迹解码出一个候选答案,然后通过选择机制挑出最佳结果。
对于候选答案的选择,GRAM 提供了两种策略:
- 多数投票(Majority Voting): 选择出现频率最高的预测结果;
- 潜在过程奖励模型(LPRM): 训练一个值函数 v_ψ(z_t),直接从潜在状态预测轨迹最终质量,选择得分最高的候选。
这种「宽度扩展」的意义在于:并行采样可以绕过深度扩展的延迟瓶颈。多条轨迹可以同时计算,在相同的壁钟时间内覆盖更大的解空间。
实验结果
研究团队在多类任务上对 GRAM 进行了评估,包括结构化推理、多解约束满足和无条件生成。
结构化推理:Sudoku-Extreme 和 ARC-AGI
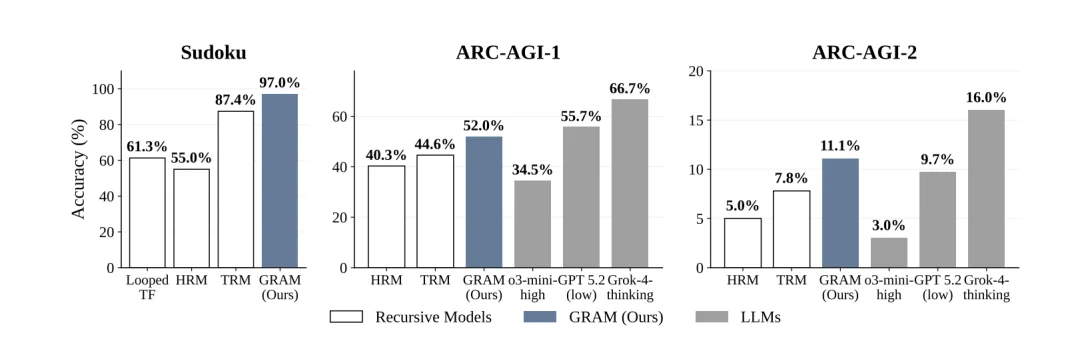
基准测试上的性能表现。在 Sudoku-Extreme 和 ARC-AGI 两个基准上,GRAM 都持续优于所有确定性递归基线模型(Looped TF、HRM、TRM)。这表明,在递归推理范式中,引入随机性的潜在状态转移能够带来显著性能提升。
在 Sudoku-Extreme(包含极少线索的 9×9 数独)上,所有递归模型在 16 个监督步进行评测。GRAM 取得了 97.0% 的准确率,大幅超越 TRM(87.4%)和 HRM(55.0%)等确定性递归基线。
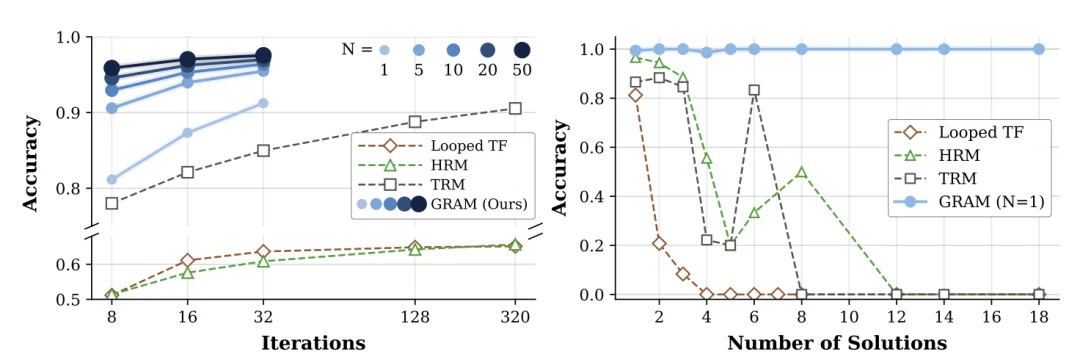
左图:Sudoku-Extreme 上的推理时扩展表现。TRM 和 GRAM 都能从更长的递归过程(横轴)中获益,但 GRAM 还可以通过并行采样进一步扩展性能,其中 N 表示采样数量。每一次迭代对应一个监督步骤,同时也意味着在 Looped TF 中需要 K 倍更多的扁平迭代次数。右图:N 皇后问题(8×8)中,模型在不同解数量下的准确率。传统的确定性递归模型会随着可能解数量的增加而出现明显性能下降,而 GRAM 则能够保持稳定表现。
更值得关注的是推理时扩展曲线:GRAM 在 16 步递归 + 20 条并行采样(N=20)时,达到了 97.0% 的准确率,超过了 TRM 在 320 步纯深度递归时的 90.5%。这意味着在计算预算相当的情况下,「深度 + 宽度」的组合策略远优于单纯增加深度。
在 ARC-AGI 抽象推理挑战上,GRAM 同样一致性地超越了所有确定性递归基线。
多解任务:N-Queens 和 Graph Coloring
多解任务最能体现 GRAM 的优势。在 8×8 N-Queens 问题中:
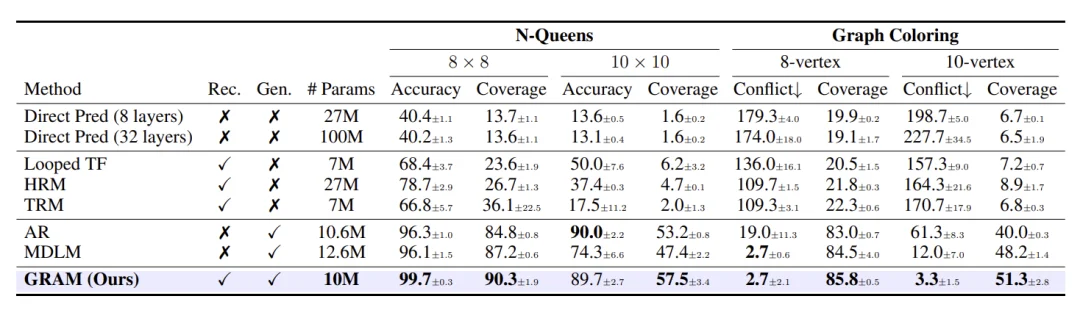
N 皇后和图着色基准上的评估结果。Rec. 和 Gen. 分别表示模型是否使用递归计算和生成式采样。表中数值为多次运行的平均值 ± 标准差。Accuracy:单次采样准确率(%)。Conflict:违反约束的边数,数值越低越好(↓)。Coverage:在 20 次采样中发现的不同有效解占比(%)。
确定性递归模型的覆盖率最高只有 36.1%,因为它们在相同输入下只能收敛到一个解。自回归生成模型(AR、MDLM)覆盖率较高,但在约束满足的准确率上逊于 GRAM。GRAM 同时实现了最高的准确率和接近最优的覆盖率,兼具递归精炼的约束满足能力和生成模型的多样性。
在 Graph Coloring 任务上同样如此:GRAM 的冲突边数仅为 2.7(8 顶点)和 3.3(10 顶点),而自回归模型分别为 19.0 和 61.3。
无条件生成:Sudoku 和 MNIST
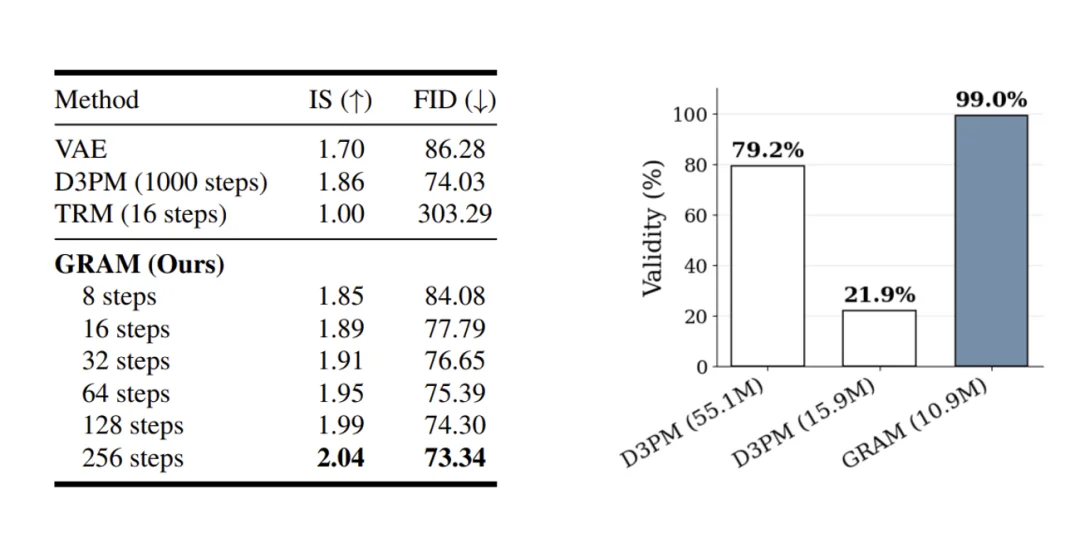
左:二值化 MNIST 上的无条件生成结果。右:无条件数独生成。
GRAM 还展示了无条件生成能力。在无条件数独生成中,GRAM 以 10.9M 参数和 16 个监督步就达到了 99.05% 的有效率,超过了使用 55.1M 参数和 1000 步去噪的 D3PM 扩散模型。
在 binarized MNIST 上,确定性基线 TRM 出现了模式坍塌(FID 303.29),而 GRAM 取得了与 D3PM 相当的生成质量(FID 73.34,IS 2.04)。此外,增加推理时的递归步数可以单调地提升生成质量(FID 从 8 步时的 84.08 降至 256 步时的 73.34),即使训练只用了 16 步。
消融实验:随机性和引导缺一不可
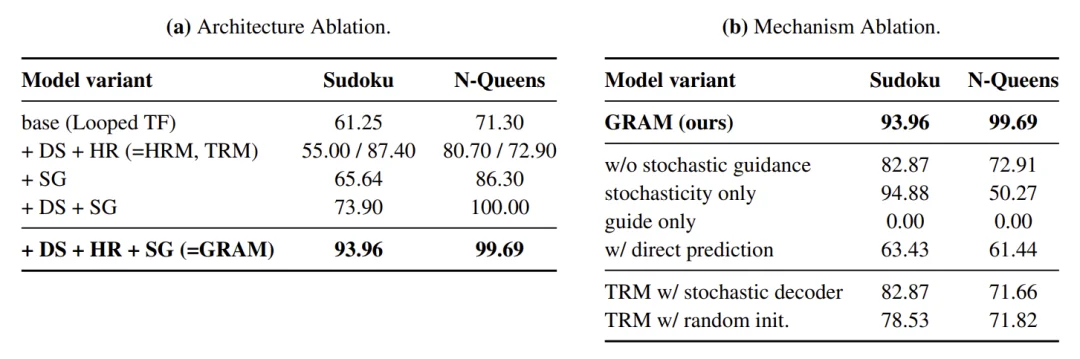
Sudoku-Extreme 和 N 皇后(8×8)上的消融实验。评估时使用 5 次采样。对于(a),各组件是在 Looped TF 基线之上逐步累加加入的。其中,DS 表示深度监督,HR 表示层级递归,SG 表示随机引导。对于(b),随机性和学习得到的引导机制都至关重要,移除其中任意一个都会显著降低性能。
消融实验揭示了 GRAM 设计的关键洞察:
- 去掉引导方向(仅保留随机性):数独任务保持 94.88%,但 N-Queens 暴跌至 50.27%
- 去掉随机性(仅保留引导):两个任务均为 0%
- 对 TRM 简单添加随机解码或随机初始化:无任何改善
这说明 GRAM 的增益来自变分框架本身,来自随机性与学习到的引导方向的协同作用,而非简单的随机扰动。
总结
GRAM 确立了「概率多轨迹递归」作为未来递归推理架构的设计原则。它的核心洞察是:推理系统不仅需要「深」,还需要「宽」。
从技术贡献看,GRAM 完成了三件事:将递归推理形式化为潜变量生成过程;引入基于宽度的推理时扩展机制;并在结构化推理、多解约束满足和无条件生成任务上验证了该框架的有效性。
在「推理该在什么空间发生、以什么方式扩展」这一核心问题上,GRAM 提供了一个明确且经过验证的答案:在潜在空间中,通过概率递归,同时沿深度和宽度两个方向扩展。
文章来自于微信公众号 “机器之心”,作者 “机器之心”

