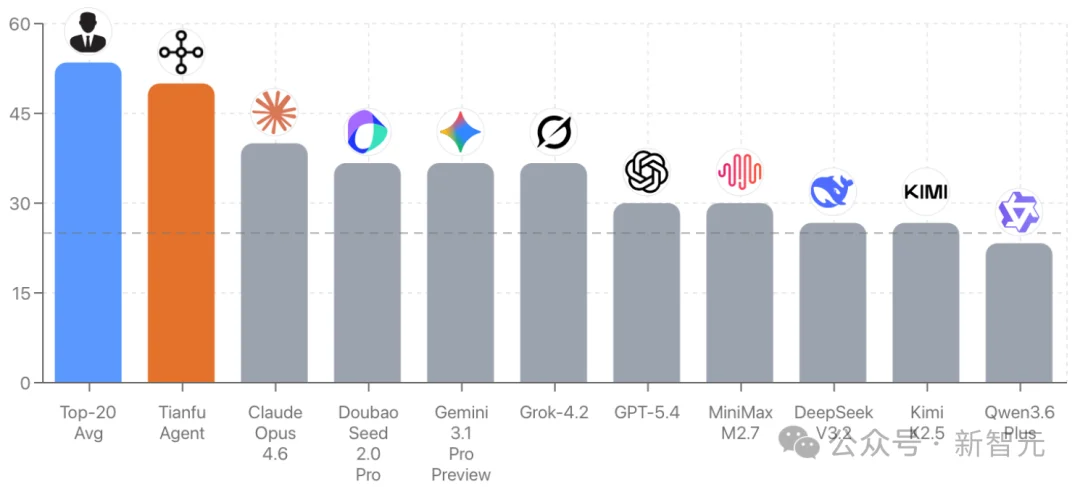
没有信息泄漏的专业术数题库面前,Claude、GPT等主流模型集体「翻车」。但一个叫Tianfu Agent的系统,却一举将准确率提升至50%,逼近本届术数大赛人类Top20选手的53.5%平均水平。
把当前最先进的通用大模型,放在中国传统术数专业选择题(四选一)面前,会发生什么?
需要说明的是,评测对通用模型已经做了「让步」:所有基线模型的Prompt中都提供了预计算的盘面数据,避免引入计算幻觉,而是直接考察推理能力。
DestinyLinker研究团队基于术数大赛(HKJFMA主办,3069名选手参与)的官方题库的评测集基准Mingli-Bench,测试了当下主流大模型,技术报告和测试结果在x上获得了百万关注。

MingLi-Bench开源仓库:https://github.com/DestinyLinker/MingLi-
Bench Tianfu Agent技术报告:https://destinylinker.github.io/MingLi-Bench/
结果有点意外,这些模型在这套几乎没有信息泄漏的最新比赛选择题上,准确率清一色徘徊在23%到40%之间。
注意,四选一选择题的随机猜测线就是25%。
为了验证模型能力能否支撑专业术数推理,该团队研发了Tianfu Agent的系统,实现一整套针对中国传统术数领域harness工程系统——
200多个原子工具、3大流派规则函数库、多Sub-Agent协作,以及一套贯穿全链路的置信度量化机制,一举达到了50%的截尾准确率,逼近本届赛事人类Top 20选手的平均水平53.5%。

Harness之路
编码智能体的经验还远远不够
本测试案例使用了马斯克命盘,测试中的1971/12/30并非其真实生日,因为他出生于南半球,需对其生辰进行节气转换
Claude Code、Cursor这些工具在复杂工程任务中表现良好,不是因为模型本身变强了,而是它被放进了一个领域专用的工具环境里,有文件I/O,有终端,有测试反馈。
Tianfu Agent把同样的逻辑搬进了中国传统术数领域,在推理链路上,采用多Sub-Agent协作的渐进式发现策略:多个Sub-Agent各自维护独立的工具集和上下文,并根据环境反馈逐步展开推理。
然而,仅依靠Coding Agent的成功经验还是远远不够的,例如:
- 除了常见的刑冲查询、飞宫路径等,术数领域还涉及大量数据逻辑运算,此部分由大模型生成并不可靠,但一次性交给模型调用又会污染上下文;
- 规则需要经验选择,并非使用越多越好,且每一条规则的使用后都可能出现矛盾的结论;
- 缺乏「单元测试」等辅助验证手段,在长链路推理下,很容易积累偏差。
其他垂直领域应用,如医疗、法律等很可能也面临着类似的困境
200多个工具如何管理?
四级可见性控制
通用Agent用十几个工具就够了,200+工具带来的第一个工程问题不是「能不能写出来」,而是模型选不对。
该研究团队按「LLM可理解性」和「可穷举性」两个维度,将工具分成四级:
- 自动注入型(可理解+可穷举):十神、星耀、宫位等零歧义概念,自动加载到上下文中,不需要模型选择。
- 按需调用型(可理解+不可穷举):生克关系、飞宫计算等,模型能理解语义并自行判断参数。
- 转译调用型(不可理解+可穷举):模型容易产生歧义或非市面常见的专业术语,通过预设翻译层转换工具名称后调用。
- 触发注入型(不可理解+不可穷举):仅特定Sub-Agent可调用,并配备专属背景知识和校验方法。
这套机制的核心是动态控制工具的可见范围——不同推理阶段、不同Sub-Agent看到的工具集不同,避免选项过载导致的选择退化。
这个思路对其他垂直领域的Agent开发有一定参考价值:当工具数量超过模型的可靠选择阈值后,工具管理本身就成了一个独立的工程问题。
繁杂规则怎么用?
也封装成可调用函数
通用Agent经常把规则写进System Prompt或Few-shot,本质是让模型「记住并遵循」。
术数领域规则繁杂(仅子平母法就超过百条)、适用条件互相耦合、流派之间还会互相矛盾,靠记忆遵循的直接后果就是选择性忽略、推理路径不可控。
Tianfu Agent的做法,是把每一条复杂规则封装成一个带元数据的可调用函数。
人类专家预先标注适用场景、时间跨度、事件类型、优先级;函数内部可以再调LLM;输入盘面状态,返回结论和置信度;只在满足验证时才注入上下文。
这一步等于把LLM从「记规则的考生」变成「调规则的工程师」——规则不再是Prompt里一段需要模型自觉遵守的文字,而是一个有明确签名和触发条件的工程构件。
没有单元测试?
三层不确定性量化
编码Agent的一个天然优势是有「测试」作为验证手段。
代码写完跑测试,通过就是正反馈,失败就有明确的报错信息。
术数领域,或者说绝大多数专业领域,都没有这个条件实现所谓的「单元测试」。
Tianfu Agent的方案是引入不确定性量化,在三个层面给出置信度评估:
- 工具输出层:非确定性工具(如强弱判断、多象吉凶)由内置算法提供置信度,直接由算法层面进行确定性评估。
- Sub-Agent层:每个子智能体在单一理论体系下完成推理后,由LLM自评本次推理结论中每个观点的显著性。
- 多流派合参层:不同流派的结论可能相互矛盾,通过人工经验置信度加权调和,再次进行判断。
这不是一个能替代“自动验证”的方案——在报告中也坦承了这一点。但在缺乏验证手段的领域,「知道自己有多不确定」本身就是有价值的信息,至少给上层决策提供了量化参考,而非将所有结论等权堆砌。
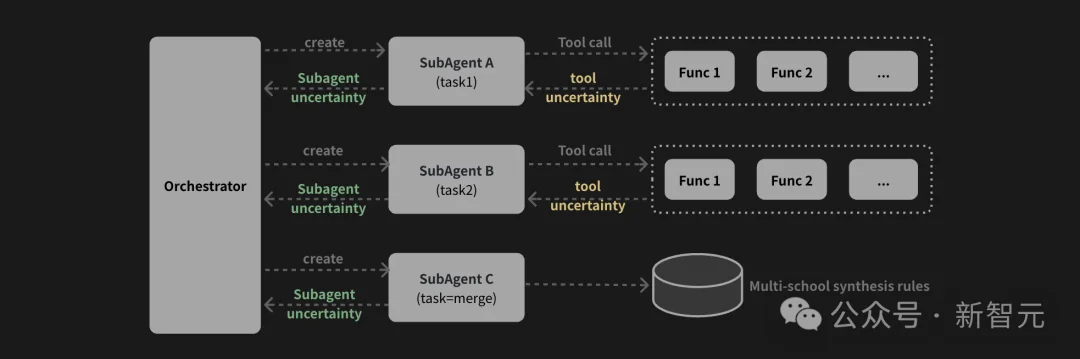
如果用一句话总结这套harness的设计哲学:在Tianfu Agent里,工具不仅是计算函数,它还包括规则、子推理流程,乃至Sub-Agent本身。
对垂直领域Agent落地的启示
抛开领域特殊性本身不谈,这个项目提供了一些对垂直领域Agent开发有参考价值的工程经验:
- 工具化范式,在「规则密集+语料稀缺」的领域收益最大。通用领域的模型已经从海量语料中内化了规则,工具环境是锦上添花。但在训练数据极少的垂直领域,工具环境直接弥补了模型的知识盲区,Tianfu Agent比最强通用模型高出10个百分点即为例证。
- 工具数量膨胀后,工具管理本身成为独立的工程问题。四级分类加动态注入的思路,对其他需要大量专业工具的垂直Agent有直接借鉴意义。
- 在缺乏自动验证的领域,不确定性量化是务实的次优方案。编码Agent有测试,医疗Agent有循证指南,但很多领域没有——虽然术数是一个极端案例,但这种情况下置信度机制的作用值得关注。
- 「知识即接口」,在规则密度高的场景比「知识即提示词」更可靠。把规则从Prompt搬进函数,是解决模型长上下文「选择性失忆」的一种直接手段。
Coding Agent的Harness时代已经到来。Tianfu Agent某种程度上证明了,这条路不只属于编程——在足够结构化的垂直领域,该范式可能同样成立。
参考资料:
MingLi-Bench开源仓库:https://github.com/DestinyLinker/MingLi-Bench Tianfu Agent技术报告:https://destinylinker.github.io/MingLi-Bench/
文章来自于"新智元",作者 "新智元"。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

