在音乐术语中,Legato(连音)意味着音符之间平滑过渡、毫无间断,演奏出流畅优美的旋律。钢琴家的手指在琴键上滑动,小提琴家的弓在琴弦上连贯运行 —— 这种 "连音" 技巧让音乐充满生命力。一位真正掌握连音技巧的演奏者,不需要靠后期剪辑来弥补断点,而是能够知道如何让每一个音符自然地流向下一个。
机器人领域同样在追求这样的 "连音" 效果:让机器人的动作像音乐一样流畅自然,没有犹豫和停顿。然而,要让一台机器人真正做到这一点,远比想象中困难。
近日,千寻智能高阳团队的研究成果 《Learning Native Continuation for Action Chunking Flow Policies》 被机器人顶会 RSS 2026 接收!这项工作从训练机制出发,让机器人动作天然具有连续性,实现了 "连音" 般的流畅执行,在五个真实世界操作任务上超越了现有方法,为具身智能领域的动作生成研究提供了新的思路。

- 论文标题:Learning Native Continuation for Action Chunking Flow Policies
- 论文链接:https://arxiv.org/pdf/2602.12978
- 项目主页:https://lyfeng001.github.io/Legato/

1. 机器人为什么会 "犹豫"?
想象一下,你让机器人倒水、叠碗或折毛巾,它却在执行过程中频繁停顿、犹豫不决,甚至突然改变主意 —— 比如原本计划用左手抓取物体,执行到一半却又想换成右手,结果两只手都没抓到,白白浪费了时间。这种 "犹豫" 不仅让动作看起来别扭,还会直接拖慢任务完成的速度,在需要精准配合的场景下甚至会导致任务失败。
这背后的根源,要从当前主流的机器人基础模型的动作建模方式说起。
1.1 动作分块:一把双刃剑
目前,主流的 Vision Language Action(VLA)模型普遍采用一种叫做 "动作分块"(Action Chunking)的技术:机器人不是每次只规划下一个动作,而是一口气规划出未来一段时间(比如接下来 1 秒)的完整动作序列,然后依次执行。这样做有两个明显的好处:
- 动作更连贯,因为模型能看到更长时间范围内的规划;
- 推理效率更高,不需要每个单独的时间步的动作都调用一次模型。
但问题也随之而来:每当一段动作序列执行完毕、下一段序列接上来的时候,两段序列之间往往存在明显的不连续性。就像两段录音硬拼在一起,接缝处总会有一个突兀的 "断点"—— 机器人会在这个瞬间出现停顿、抖动,甚至方向突变。这个问题在需要高频控制的精细操作任务中尤为明显。
更深层的原因在于,基于流匹配(Flow Matching)的 VLA 模型本身具有多模态性 —— 面对同一个场景,模型可能规划出多种合理的动作方案(比如用左手或右手抓取)。当两段动作序列独立生成时,前一段选择了方案 A,后一段却可能选择了方案 B,两者在接缝处发生 "模态切换",导致机器人的动作出现突兀的跳变。
这种现象在任务中途尤为危险:机器人已经伸出了左手,却在下一个动作块里突然决定改用右手,不仅动作难看,还可能直接碰倒目标物体。
1.2 RTC 的修补
为了解决这个问题,研究者们提出了 Real-Time Chunking(RTC)方法。它的思路是:在生成新的动作序列时,把上一段序列末尾还没执行完的部分 "借" 过来,用来引导下一个序列的生成,通过让下一个序列的前半部分和上一个序列没有执行的部分比较像,来保证两段序列之间的平滑过渡。
这个方法具有非常好的效果,也因此得到了广泛应用。可以把它理解为一种 "接力棒传递" 的机制:新的动作序列不是凭空开始,而是从上一段序列的后半部分 "接棒" 继续。
然而,这个方法实际上存在一些不可避免的缺陷:
- 推理阶段 RTC:连续性机制只在推理时临时 "打补丁",模型在训练时从未见过这种情况。训练和推理的条件不一致,就像一个学生平时练习的题型和考试题型完全不同 —— 模型在推理时面对 "部分已知的前缀" 时,并不知道该如何正确利用这些信息,容易产生 "虚假的多模态切换",也就是机器人在执行过程中突然 "改变主意"。
- 训练阶段 RTC:虽然在训练时也引入了这种拼接机制,但做法是直接把前缀片段硬拼接到执行部分的前面,并将这部分固定、不再更新。这样一来,前缀和后续动作之间依然缺乏有机联系:模型只是被告知 "前面这段是固定的,你只需要生成后面的部分"。
两种方式都没有从根本上解决问题:连续性是从外部强加给模型的,而不是模型自己学会的。这就好比一个演奏者不是真正掌握了连音技巧,而是靠后期剪辑把两段录音拼在一起 —— 听起来勉强过得去,但终究缺少那种浑然天成的流畅感。
2. Legato 的解决方案
让连续性成为模型的 "天赋"
Legato 的核心思想可以用一句话概括:与其在推理时给模型 "打补丁",不如在训练时就让模型学会如何天然地生成连续的动作。
这个思路的转变看似简单,实现起来却需要解决两个关键问题:
- 第一,如何在训练时让模型真正 "看到" 并学会利用已知的前缀信息;
- 第二,如何确保训练时学到的行为和推理时实际执行的行为完全一致,不出现 "双重标准"。
Legato 通过四个精心设计的机制,系统性地解决了这两个问题。一个直觉上的类比是:我们希望机器人就像一位经验丰富的接力跑运动员:不仅知道自己该跑哪一段,还清楚地知道上一棒跑到了哪里、速度是多少,并据此调整自己起跑的节奏,而不是每次都从静止状态重新出发。
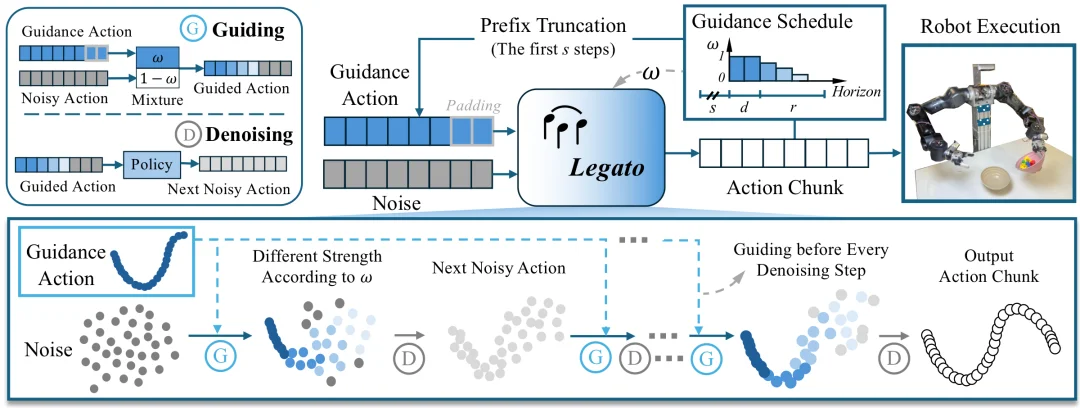
2.1 噪声-真实值混合机制
在标准的流匹配(Flow Matching)训练中,模型每次都是从完全随机的噪声出发,通过多步去噪,最终生成完整的动作序列。这就好比让一个学生每次都从一张白纸开始作答 —— 他永远不知道 "如果已经写了一半,接下来该怎么写"。长此以往,模型只会从零开始规划,一旦推理时被要求 "接着已有的动作继续",就会手足无措。
Legato 改变了这一点,它引入了引导向量 ω∈[0,1]^H,用来控制每个时间步的初始状态,将训练时的起点从 "纯噪声" 变成 "噪声与真实动作的混合":
- 对于已经执行过的前缀部分(ω=1):初始状态直接就是真实动作,模型知道 "这里已经发生了什么",需要在此基础上继续规划
- 对于需要自由预测的未来部分(ω=0):初始状态是纯噪声,模型需要完全自主规划
- 对于中间的过渡区域(0<ω<1):初始状态是真实动作和噪声的混合,引导强度从强到弱逐渐减弱,形成平滑的过渡
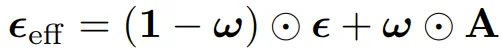
用公式表达就是:
其中 A 是真实动作,ε 是噪声,⊙ 表示逐元素相乘。通过这种设计,模型在训练时就能反复练习 "如何从部分已知的状态出发,生成流畅的后续动作",而不是每次都从零开始。久而久之,模型自然就学会了如何利用已知的前缀信息:这种能力是从训练中内化的,而不是推理时临时拼凑的。
2.2 逐步引导的去噪动力学
仅仅改变初始状态还不够。研究团队发现了一个重要现象:如果只在初始化时引入引导,随着去噪步骤的推进,模型会逐渐 "忘记" 已知的前缀信息。就像一个人在嘈杂的环境中试图记住一段旋律,时间越长,记忆就越模糊,最终生成的动作仍然可能偏离预期。
研究团队通过实验验证了这一点:单次引导(one-shot guidance)在去噪过程中确实无法维持对前缀的约束,前缀区域的动作会随着去噪步骤的推进逐渐漂移。
为了解决这个问题,Legato 在每一步去噪前都进行混合,而不是只在初始化时:
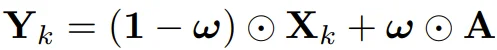
这就像给模型装了一个 "记忆锚":无论去噪进行到哪一步,模型都会被不断提醒 "前缀是什么样的",并围绕这个约束来规划后续动作。这种逐步引导的机制,使得前缀区、过渡区和自由生成区形成一个统一、连贯的动力学系统,而不是三段割裂的拼接。
2.3 训练-推理一致性
问题在于:推理时,模型在每一步去噪前都会进行真实值和噪声的混合(即上面的逐步引导);但训练时,标准流匹配的优化目标是针对 "从纯噪声出发的去噪过程" 设计的,并没有考虑这种逐步引导的存在。所以如果不针对训练目标进行调整,训练的目标即标准流匹配与实际执行的动力学实际上是不一致的。
Legato 的解决方案:重新推导训练目标,使其与逐步引导的推理动力学完全对齐。具体来说,研究团队从逐步引导的动力学方程出发,反推出了一个新的速度场训练目标:
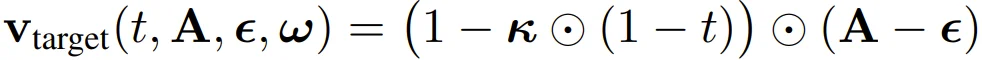
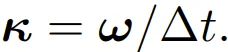
这个公式的妙处在于:它保留了标准流匹配的几何方向(即 "朝着真实动作运动" 的大方向不变),只是根据引导强度 κ 调整了速度的大小。换句话说,Legato 并没有颠覆流匹配的基本框架,而是在其基础上做了一个精准的 "校准"—— 让训练时学到的速度场,与推理时逐步引导所产生的有效速度场完全吻合。
这样一来,训练和推理之间的 "双重标准" 被彻底消除,模型在推理时的行为完全符合它训练时学到的规律。

2.4 随机化混合参数
在真实部署中,不同的硬件平台推理速度不同(高端 GPU 和边缘计算设备的延迟可能相差数倍),不同的任务对动作流畅度的要求也不同(精细操作需要更强的连续性,而快速移动任务则更注重响应速度)。如果每换一个场景就要重新训练一个模型,代价太高,也不现实。
Legato 的解决方案是:在训练时对混合参数 (d,r) 进行随机化,让模型在训练阶段就见识各种不同的引导向量:
- d(推理延迟):控制前缀的长度,对应不同硬件平台的计算速度。d 越大,说明推理延迟越高,需要 "借用" 的前缀越长
- r(过渡区长度):控制从强引导到弱引导的过渡速度,决定动作的流畅程度。r 越大,过渡越平缓,动作越流畅;r 越小,过渡越陡峭,模型响应越灵敏
通过在训练时让模型见识各种不同的 (d, r) 组合,同一个模型在推理时只需要调整这两个参数,就能适配不同的硬件延迟和流畅度需求,无需重新训练。这大大降低了 Legato 在实际部署中的门槛。同时,由于模型在训练时已经见过各种调度情况,推理时的行为也更加稳定鲁棒,不会因为参数的细微变化而出现大幅波动。
3. 实验结果
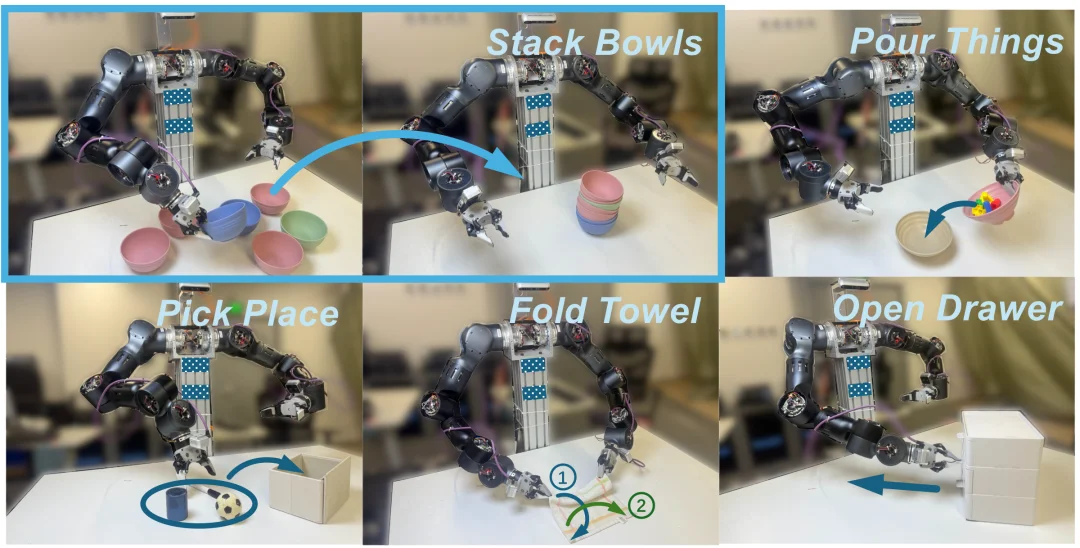
研究团队在双臂机器人上进行了广泛的真实世界实验,涵盖五个操作任务:叠碗、倒东西、拾取放置、叠毛巾、开抽屉。这些任务的选取颇具代表性:它们不仅覆盖了旋转主导、平移主导等多样的运动模式,还包含了大量需要在多个选项中做出选择的场景 —— 比如叠碗时选择抓哪个碗、拾取放置时决定用左手还是右手。
这类多模态选择场景,正是最容易触发 "虚假多模态切换" 的地方,也是检验连续性方法的最佳试金石。
3.1 基本实验结果
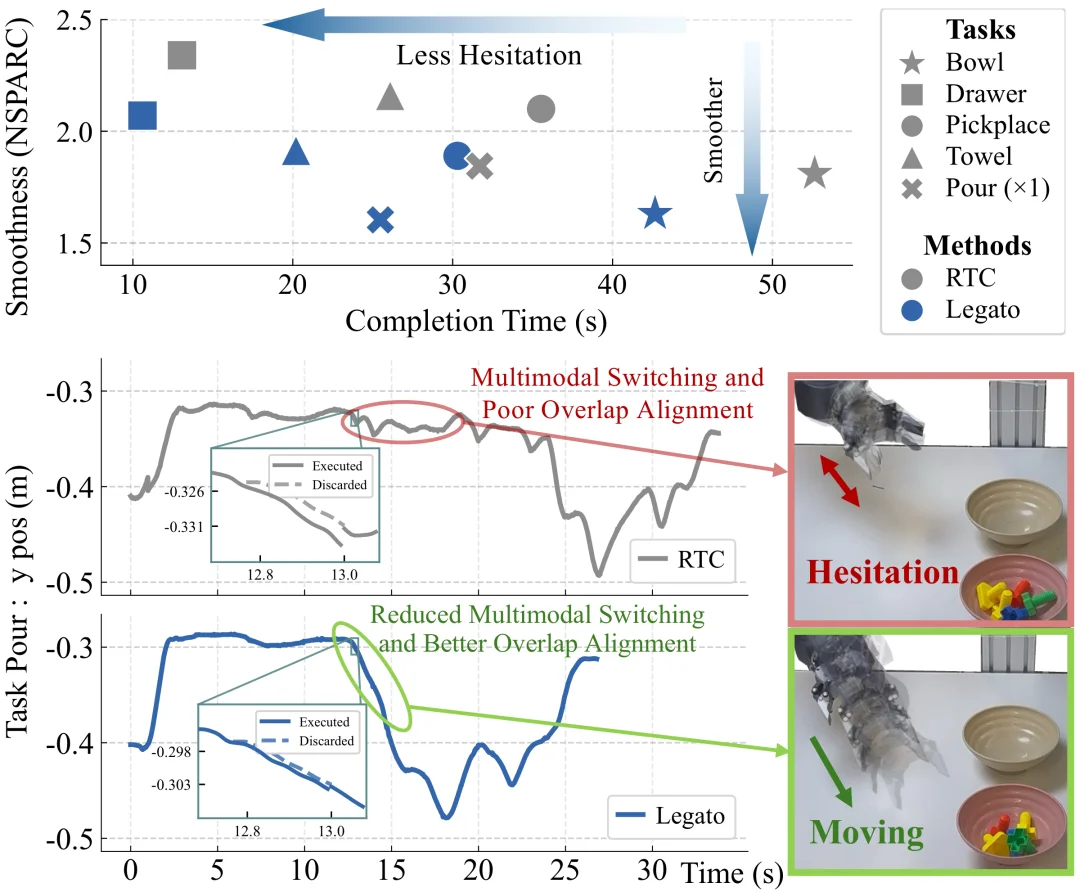
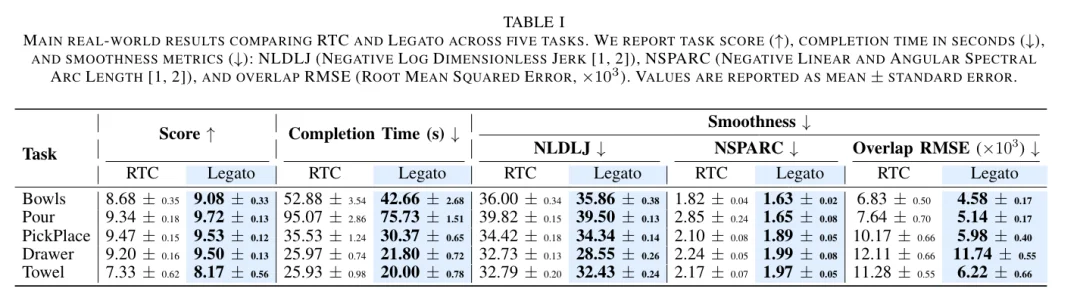
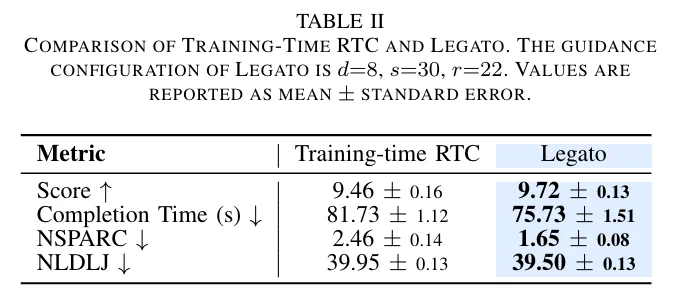
实验结果表明,Legato 相对于 RTC 以及 Training-Time RTC 均有一定的优势:
- 犹豫明显减少:机器人在执行过程中的停顿和 "改变主意" 现象大幅降低,动作轨迹更加干净利落。从轨迹图上可以直观地看到,Legato 的执行曲线更加平滑,而 RTC 的曲线则呈现出明显的锯齿状波动,这些波动正是机器人在两种动作方案之间反复横跳的痕迹
- 任务完成时间缩短:在五个任务上平均缩短约 10%,在倒东西等高度依赖连续性的任务上提升尤为突出,最高提升幅度超过 20%
- 轨迹平滑性显著提升:以 NSPARC 指标衡量,平均提升约 10%,部分任务(如倒东西)提升幅度超过 40%
更多的消融实验、仿真测试以及详细分析可参考原文。
3.2 实际部署使用指南
研究发现,在 d=delay, s=0.5H, r=H-d-s 的参数设置下,模型的表现较好。其中 H 是动作序列的总长度,d 对应实际的推理延迟,s 是每个序列执行的步数,r 则是过渡区的长度。这个参数设置在大多数任务和硬件平台上都能取得不错的效果,可以作为部署时的默认配置。
与此同时,该研究推荐在一个标准 flow matching 训练至较好的 base model 基础上进行 Legato 的 finetune,会获得更好的模型表现。
4. 总结
Legato 提出了一种让流匹配策略天然具备连续性的训练方法,从根本上解决了动作分块策略中长期存在的连续性问题。它的核心贡献在于:
- 原生连续性:让模型从训练阶段就学会如何从 "部分已知的动作" 出发生成后续动作,连续性是模型内化的能力,而不是推理时外部修补的结果
- 训练-推理一致性:通过重塑速度场,从数学上保证训练和推理的动力学完全对齐,从根本上消除虚假多模态切换,而不是用更强的约束去压制它
- 灵活可控:通过随机化混合参数,一个模型即可适配不同硬件延迟和流畅度需求,大幅降低实际部署的门槛
Legato 让机器人的动作真正像音乐中的连音一样:不是两段录音的生硬拼接,而是演奏者发自内心、浑然天成的流畅表达。随着具身智能走向更广泛的真实世界应用,这种 "天然流畅" 的能力,将成为机器人部署时流畅执行运动不可或缺的条件。
希望 Legato 这篇工作能够为具身智能社区带来新的启发,推动机器人操作技术迈向更高的水平。
文章来自于微信公众号 "机器之心",作者 "机器之心"
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI

