OpenAI 刚开源了一个 1.5B 参数的隐私过滤模型,却只用 50M 活跃参数就能精准标记姓名、电话、密码这些敏感信息。
你有没有过这样的经历:把聊天记录、用户反馈或内部文档丢给大模型时,总担心里面夹杂着真实姓名、手机号、邮箱甚至 API key,最后只能手动一条条删?或者团队在处理海量数据时,规则写的正则永远漏掉那些“藏在句子里的隐私”。现在 OpenAI 把这个痛点直接甩给了一个小模型——Privacy Filter。模型本身不删内容,只负责标记,开发者再接规则或另一个模型去清理,最后把干净文本喂给大模型。
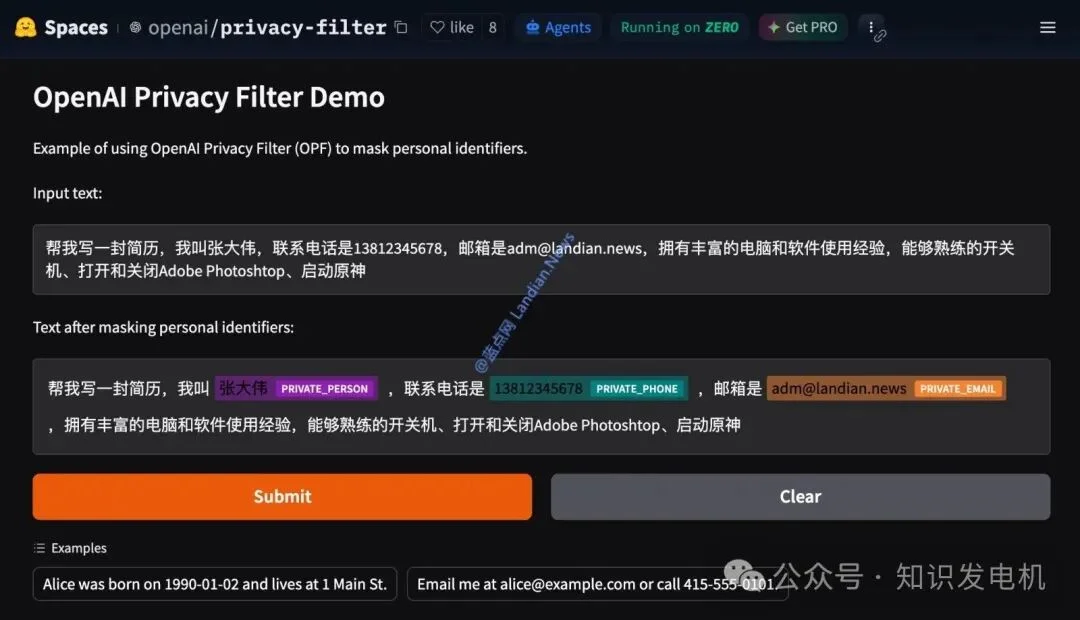
这东西的核心结论是:它让本地隐私清洗变得可行,而不是每次都把原始数据甩到云端。 以前靠正则的方案,在复杂语境下经常漏网;现在用上下文理解的模型,准确率上了一个台阶,而且体积小到能在浏览器或普通笔记本上跑。
想象一下你用微信发消息给客服,客服系统先过一遍这个过滤器,把你的真实手机号和姓名遮掉,再把净化后的描述丢给 GPT 处理回复。用户隐私没泄露,AI 还能正常工作。或者企业内部知识库,用户上传的工单里可能带了银行卡号,系统自动标记后替换成占位符,剩下的数据才进训练流程。普通人用不到直接调用,但开发者把这层加在前端,后台就少了很多合规焦虑。
为什么这个模型重要?因为大模型时代,数据清洗成了新瓶颈。云端处理意味着你的原始输入可能被日志记录、用于对齐或意外泄露;本地跑一个小模型,就能先把隐私剥离。OpenAI 自己说这是为了“支持整个生态更强的隐私保护”,听起来官方,但实际落地后,意味着浏览器插件、移动 App、内部工具链都能多一层防护,而不用每次都依赖云 API。理论上,它把“隐私-by-design”从口号变成了可执行代码。
技术上看,这个 Privacy Filter 是双向 token 分类模型,带 span decoding,架构类似 GPT-OSS 但规模小得多。总参数 1.5B,推理时只有约 50M 活跃参数(用了 Sparse Mixture-of-Experts),这让它在单次前向传播里非常轻量。支持最高 128K 上下文窗口,能一次性吃下长文本,不用分 chunk,吞吐量高,准确率也更有保障。它能识别八类实体:姓名、地址、电话号码、邮箱、日期、账号、银行账号、URL、密码、API 凭证等。通过上下文判断,而不是死板的正则,所以“张三的手机号是 138xxxxxxxx”这种自然句子也能准确定位。
我之前一直觉得小模型在隐私任务上会牺牲太多召回率,结果看到 1.5B + 50M 活跃的配置,还带 128K 上下文,认知被修正了。 原来 MoE 架构在这里把效率和能力拆得这么开,活跃参数少但总容量够用,适合高吞吐隐私流水线。模型还能通过少量数据高效微调,适应你自己的数据分布——这点对企业特别实用。
不过它不是万能的。模型只输出标记(spans),不会直接生成脱敏后的干净文本,开发者必须自己接规则批量删除或替换。边界条件也很清楚:对对抗性格式(故意变形隐私信息)可能失效,多语言支持目前较弱,基准测试里也用了 OpenAI 自己的模型来评测自家东西,社区有人指出这点有争议。实际部署时,你得测试自己的数据集,不能全信官方 F1 分数。
模型已经在 Hugging Face 上开源(Apache 2.0),带 CLI 和评估工具,开发者可以直接拉下来试。集成方式简单:先跑模型标记用户提交的内容,识别出隐私 spans,再用规则或另一个轻量模型清除,最后把干净文本喂给下游大模型。整个流程本地就能完成,不用把原始数据传出去。
# 示例伪代码,目的:先用 Privacy Filter 标记,再清理
from privacy_filter import detect_pii # 假设加载方式
text = "我的名字是李四,手机号 13800138000,邮箱 lisi@example.com。"
spans = detect_pii(text) # 返回需要遮蔽的 span 列表
# 后续用规则替换
clean_text = redact_spans(text, spans) # 自定义函数,把识别到的替换成 [REDACTED]
# 再喂给大模型
response = big_model.generate(clean_text)
跑完后你会看到,隐私部分被标记或替换,剩下的文本安全多了。这步容易出错的地方是 spans 的边界处理——上下文模型有时会多吃或少吃几个 token,得加后处理规则对齐。
我自己以前在项目里处理用户日志时,纯正则方案漏了 20% 左右的变体隐私,换成类似上下文模型后,漏网率明显下降,但多了一层延迟和微调成本。不知道有没有人把这个 Privacy Filter 直接塞进浏览器扩展里,实时过滤表单输入?或者和本地 LLM 链在一起,形成端到端隐私管道。
这个小模型把隐私过滤从“麻烦的规则工程”变成了“可本地部署的智能一步”,但最终效果还是看你怎么接下游清洗逻辑。 你在实际产品里会怎么用它,是直接浏览器端跑,还是只在后端服务器加一层?💬
文章来自于"知识发电机",作者 "知识姬Mina"。
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

