这是第一次,机器人学会了用手「盘」:

在有人和它博弈的情况下,能稳稳拿住东西:
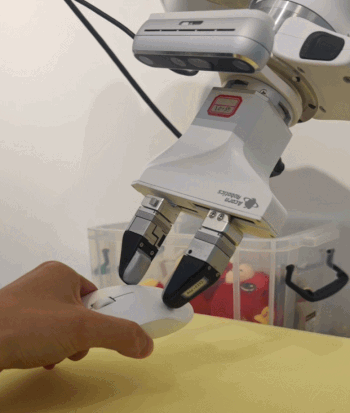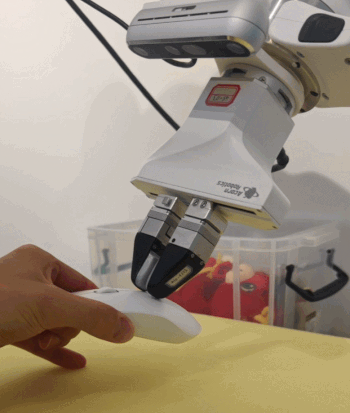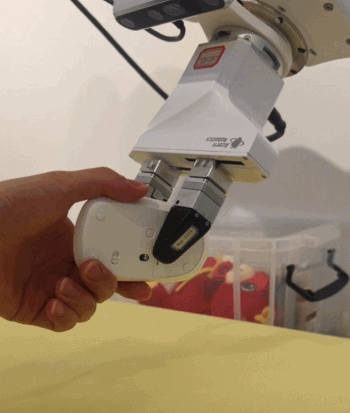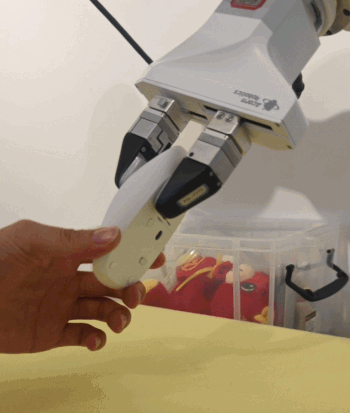
更让人想不到的是,这是通过「本能」来实现的:机器人完全没有经过对应的训练,上手就能做到。
一家清华大学背景的团队,在探索 8 年后,走出了一条与主流 VLA 截然相反的路线:自下而上,本能驱动。
当全行业都在教机器人「用眼睛看、用脑子想」时,橡木果(Acorn Robot)决定先给机器人装上「具身本能」,达成了前所未有的实用性。
在这背后,不仅有独一无二的技术,还有对于当前具身智能技术路线的独特思考。
VLA 路线,有必然「走不通」的地方
当前火热的具身智能领域,VLA(视觉 - 语言 - 动作)模型几乎成了唯一的范式。
VLA 的底层逻辑是「模仿学习」—— 人类操作员采集海量数据,再让机器人去拟合人类的动作。训练后的机器人,你只需要用语言告诉它做什么,它就能直接执行,不需要人工编程的介入。
外界普遍乐观地认为,只要数据足够多,机器人就能像 ChatGPT 改变软件世界一样重塑物理世界。但随着技术从概念走向工程,这种「自上而下」的路径正在遭遇无形的壁垒。
最近,国内外具身智能团队都在卷真实环境中的稳定性,不是单纯的看成功率,而是在看现实世界遇到突发情况能够正确应对的概率。毕竟我们说机器人进工厂打螺丝,是真的要去打螺丝。
具体到技术上,前沿方向上甚至已经出现了 VLA 向 VTLA 演进的趋势:新增的 T(触觉)意味着机器人需要在精细物理交互的场景里不仅要能看,还要能摸,作出更精准的力量控制操作。
一开始抓细节,瓶颈就出现了。
真实世界的物理交互场景 —— 物体被机械手抓住时的手感、力矩变化,手与接触面滑动时的摩擦反馈,这些数据是无法依靠仿真环境来完全模拟的。而在 VLA 范式中,任务与硬件耦合在黑箱中,泛化数据量呈指数级增长,远超自然语言 Scaling Laws 的范畴。
目前的具身智能距离真正的商用化仍有距离,究其原因,是因为工厂里的每一个工位、所有动作都需要让机器人进行单独的适配。在实践过程中,即使外观一模一样的两个夹爪,因导轨松紧不同,也需要不同的模型参数。
此外,VLA 依赖的仅有视觉这一个单一的信息维度,机器人无法感知重心偏移、滑移趋势、物体软硬等触觉信息维度,导致「眼睛学会了,上手却不行」。因此,视觉无法感知操作接触交互过程,也就没有资格给操作结果打标签,真正参与操作、能够定义「成功」操作的触觉探索却还几乎是一片空白。
那么,给出了问题,如何来解决?
解法:自下而上重构通用操作
VLA 注定「学不好」打螺丝,一部分原因在于模型的底层原理。
作为一种端到端大模型,VLA 会融合多模态的信息,通过注意力机制将视觉特征和语言指令在共享的嵌入空间内进行深度对齐与交互,从而让大模型底座发挥推理能力决定下一步的策略。这就意味着 VLA 的智慧基于的是大语言模型智能涌现的机理。
然而一个长期被忽略的事实是:语言并非先天本能。
我们知道,一个人类小孩出生后若不接触语言,一辈子都不会说话。而「动作」与操作恰恰相反,人类抓取物体的方式是高度一致的,无论文化与环境,从未有人教过我们如何抓取,这是出生即有的、由触觉刺激直接触发的本能。既然人类的操作源于本能,那为什么非要让机器人通过看视频,揣摩语义的方式去「盲人摸象」?
基于对黑箱模型的反思,橡木果提出了一套完全不同的技术架构:将任务规划(大脑)与操作执行(小脑)彻底解耦,各自独立演进,通过标准化接口协同起来。
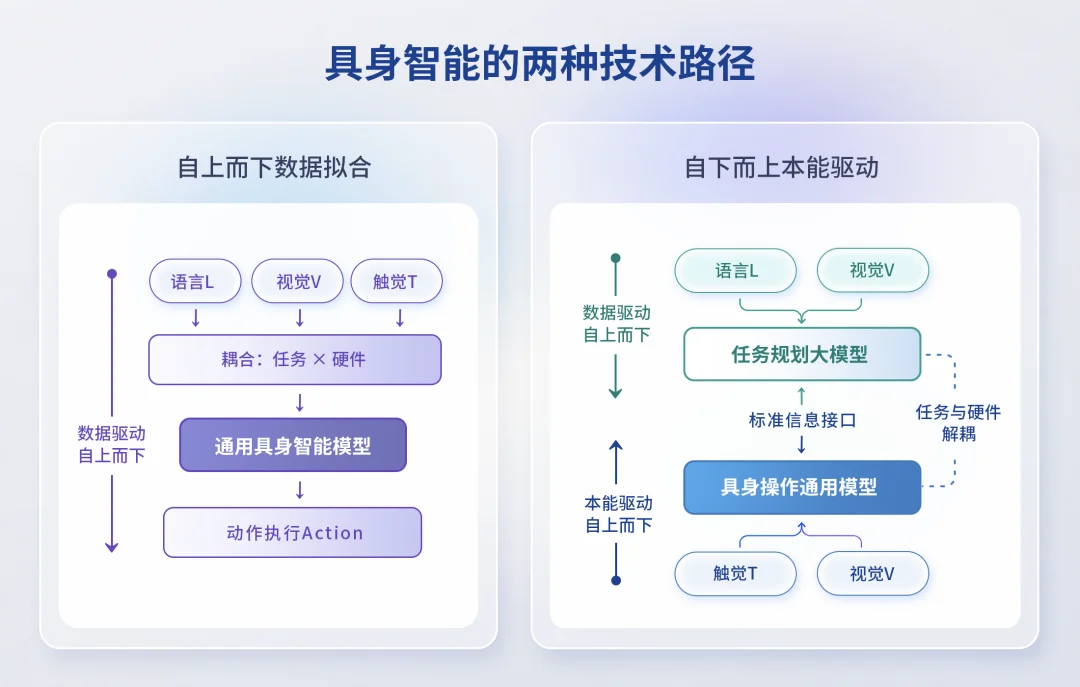
在这个架构中,橡木果不做上层的任务规划,而是把精力集中在攻克底层的操作执行上,再去接入行业头部生态。
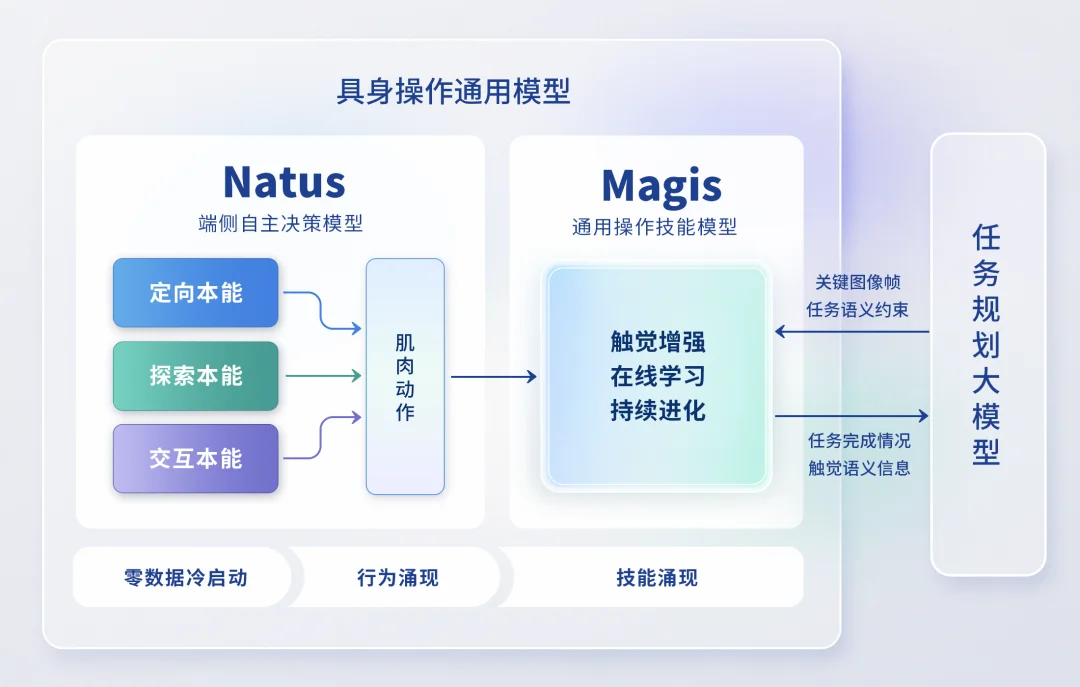
在操作执行层上,端侧的自主决策模型 Natus 是一个完全嵌在灵巧手等末端执行器中的底层模型,由「触觉刺激的本能反射」与「自主学习的肌肉记忆」构建。
它包含三大类本能反射,首先是定向本能。用于构建接触关系,与视觉协同,通过找到 / 发现 / 定向 / 识别,指引末端向目标物体移动,类似婴儿看到移动物体时头部的追随。
其次是探索本能,用于构建约束关系。这是最复杂、也最体现智能涌现的地方。当手接触物体后,它会自动沿物体表面探索,寻找稳定的接触构型,不是通过预设程序,也不是通过模仿学习,而是由「建立稳定接触」这一本能规律催生出的自主行为。
基于 Natus 模型,机器人可以构建出一种执行本能,以「滑移最小化」或「阻抗匹配」为目标,实时调节电机电流(肌肉张力),抓豆腐时增益调低(松),抓锤子时增益调高(紧),装配时则可以根据环境阻抗等触觉信息自适应判别并完成接插任务。所有调控依据均来自触觉信息的实时反馈,无需任何训练数据,频率高达 200Hz。
在测试中团队发现,机器人从未见过卡片型的物体,却能通过自主探索把卡片翘起一角,成功抓取起来:

面对半瓶水的饮料,它会反复试探重心,逐步调整抓力,最后稳稳拿起:

这些行为不是编程预设,数据集中也不存在这样的数据(甚至夹爪设计时并不是做这些动作的),都是由本能催生出的操作智能涌现。这种自下而上的行为涌现从基本的「规律」出发,让动作自行产生。与数据喂养的路径截然不同 —— 不会附带任何多余的小动作,而是始终持续地项目表状态收敛。
这种设计哲学不规定具体动作,却支配了操作的底层逻辑,实现了零数据冷启动、毫秒级响应和硬件自适应。
橡木果发起人姜峣表示,本能的范式决定了两个重要的性质:能力不由数据驱动,不受后天影响,它能让硬件具备泛化性,像人类小孩一样拿起各种各样的物体,涌现出很有意思的行为。模型的探索是持续进行的,不会有其他范式经常会出现的停顿。
构建触觉信息基础
要让「本能路线」跑通,高精度的触觉输入是硬前提。目前很多具身智能团队对触觉的理解还停留在粗浅的测力 / 测压阶段,而在橡木果看来,完整的操作触觉必须包含三个维度的信息:
- 界面信息:包含每个接触点力矢量的分布力,弹性体的应变场,界面的微动趋势(滑移)。其中滑移趋势最为关键,有了滑移感知,机器人就能够不需要任何训练数据,冷启动调节抓力。
- 物体信息:包括软硬度、摩擦系数、材质纹理、质量、质心分布等视觉无法获取的力学属性。
- 环境信息:包括接触刚度、阻抗、扰动、接触位置等。装配、打磨、抛光等使用工具操作的高度依赖环境信息。
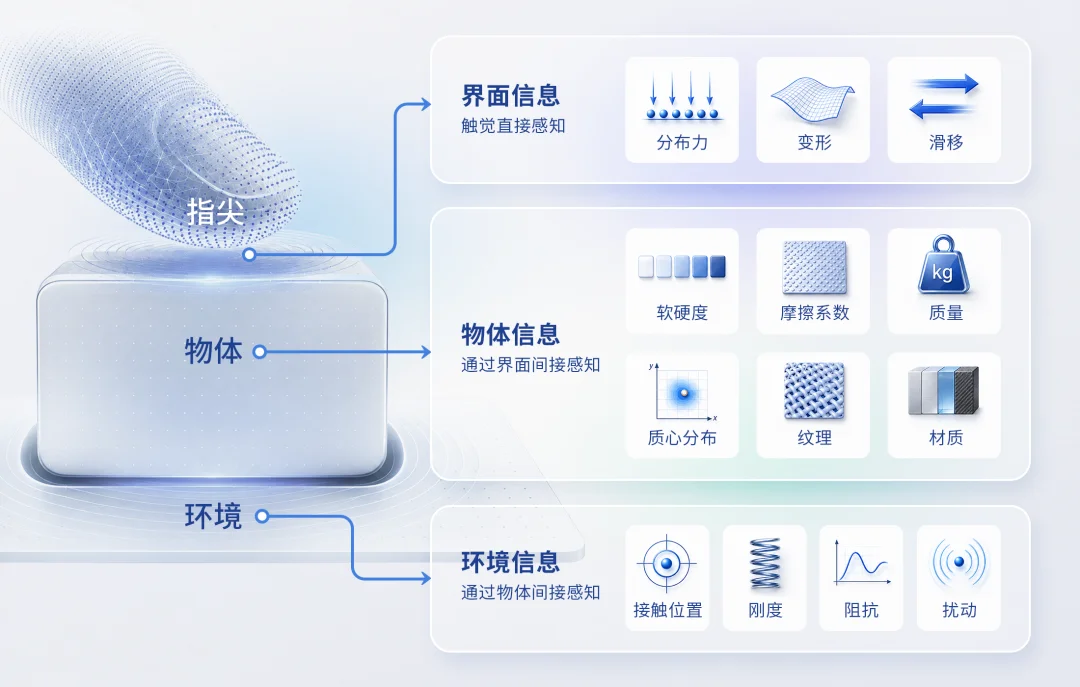
为此,该团队历时 7 年迭代,十余代原型机,已推出第三代视触觉传感器(Vision-based Tactile Sensor)。其采用弹性体(硅胶)加微型相机的方案,能通过图像表征与重构算法将弹性体的变形反演为物理量。
虽然「硅胶 + 相机」的视触觉原理样机的技术门槛并不高,但橡木果在其中构筑了工程壁垒:公司在 2020 年便首次提出了动态表征(特征追踪)技术,领先行业数年。同时,团队攻克了非线性、黏弹性逆问题的工程化标定。
更重要的是,他们将图像预处理算法压缩到指尖内的芯片,优化信息重构算法,可实时输出多模态、标准化的触觉信息,而非原始图像 —— 彻底避免了硬件差异导致模型失效的痛点。
下一步:上手即熟练
本能可以让机器人进行自主探索,而探索过程中产生的大量行为数据,则需要机器人通过本能进行自我理解和自主打标。在橡木果的路线图上,这些经过触觉语义增强的数据,进一步训练技能模型 Magis。
Magis 是一个通用的操作技能模型,旨在让机器人「一上手就能熟练」。在这一层面上,橡木果的做法不是从零采集海量操作视频,而是用触觉对现有视觉数据进行语义增强。
例如视觉上只看得到「香蕉」,触觉操作后,可以加上一些标注:香蕉重 120 克,质心偏左,表面粗糙,硬度中等。将这些力学语义叠加到视频帧上,再去训练技能模型。

这样做的好处是训练数据需求大幅降低,据说可以从百万小时级别降低到几千、几万小时。引入了触觉相关的数据后,AI 模型也可以理解物理世界的力学属性,从而大幅提升学习效率和鲁棒性。
Magis 模型打磨成熟后,届时将成为跨本体、跨任务泛化的关键,让不同品牌的机械手共享同一个熟练的技能库。
自主决策模型 Natus 与技能模型 Magis 能让机器人具备执行的本能与技能。在橡木果的构想中,未来的高阶任务规划模型只需要作为「包工头」去指挥底层模型「盖房子」,而自身并不需要会打地基、铺地板、砌墙。任务的规划只需要理解环境,把整个任务切分成关键帧。操作的执行是自下而上,以端侧小模型的方式去逐渐形成的。
只有这样,机器人才能实现丝滑的执行效果,以及真正的泛化能力。
回归物理世界
橡木果机器人核心团队源自清华大学与哈佛大学,拥有横跨机械工程、神经科学、机器人前沿交叉学科背景。

橡木果发起人姜峣
在具身智能大模型公司还在靠精美视频融资、讲故事的阶段,橡木果的「具身本能」已经靠着极低的数据依赖度,迅速在真实产业中完成了闭环。
该团队在去年全面启动技术落地,切入了新能源汽车、快消品、生物医药等领域的「工业柔性化场景」。这些场景长期被「换产频繁、物料多样、调参痛苦」所困扰,传统的刚性自动化束手无策,而需要百万小时训练的 VLA 模型又成本太高。
橡木果的解决方案瞄准最具挑战的抓放、旋拧、插拔任务,因为冷启动的特性部署很快,而且能在端侧不断自我学习优化,收到了很好的效果。
自今年初开始,仅用半年时间,该公司便在国内 TOP 1 的化妆品企业生产线上完成了 POC(概念验证)落地,并直接实现了营收,5 月已经开始进入产线。该团队提出的方法无需海量喂养数据,机器人依靠触觉本能,一上线就能自适应处理各种形态各异、材质不一的化妆品瓶罐与包装。
大模型、大数据、大算力的叙事固然宏大,但物理世界有其自身的运行规律。
橡木果的技术路线向行业传递了一个清晰的信号:回归物理世界的第一性原理 —— 触觉、本能、肌肉记忆,或许才是通往物理 AI 的正确途径。
文章来自于"机器之心",作者 "泽南"。

