
UiT 架构探路者,底牌还没亮。
2026 年 5 月,智象未来开源了文生图模型 HiDream-O1-Image(8B),直接登顶 Artificial Analysis 开源模型全球第一,Elo 1187 的分数力压 Qwen Image(27B)和 FLUX.2 dev。值得注意的是,这也是 Artificial Analysis 榜单前十中唯一的开源模型。
但消息一出,有人说最强一代开源文生图模型“实至名归”,却也有人直接骂“生成质量一坨”。Artificial Analysis 可不是随便哪里冒出来的野生榜单,盲测 Arena 里都是用户实时投票打出来的结果。
两极分化的评价让我们感到好奇。因此我们花了几天时间,从 Reddit 到 GitHub,从架构解析到上手实测地拆解了一遍。HiDream-O1-Image 更像是一个技术方向正确的探路者,无法也不必承担杀死比赛的期待。
作为开源第一,它和目前的行业第一 GPT Image 2 之间还有着不小的差距。这背后是 8B 参数开源版本同样明显的亮点和问题,但它却已然勾勒出了,未来 200B+参数 Pro 版本宏伟的可能性。
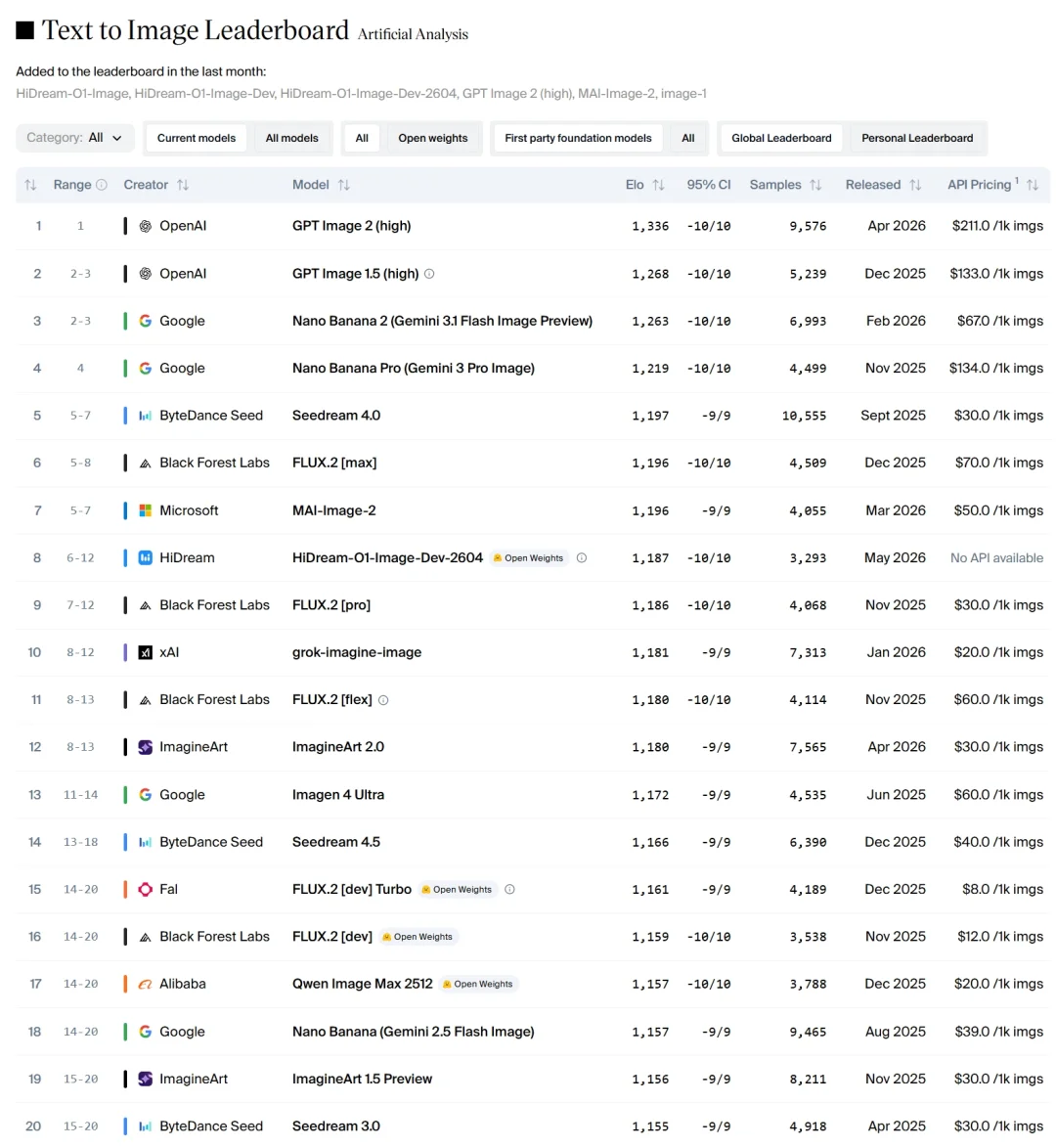
Artificial Analysis榜单前十只有HiDream 8B作为开源模型入围
01
UiT 架构创新
在 HiDream-O1-Image 之前,主流文生图模型都选择了一条“拼盘”路线。VAE 负责压缩图像,T5/CLIP 负责理解文本,DiT 负责生成。三件套各司其职,这种方案不可避免的后果就是信息损耗,每一次跨模块的传递,都会丢失细节。
而 HiDream-O1-Image 此番登顶 Artificial Analysis,其核心创新 UiT 架构正是瞄准了这一行业短板。
HiDream 采用的 UiT 架构,把像素、文本、任务条件全部映射到了同一个 token space 进行端到端处理。换言之,砍掉 VAE 和独立的文本编码器之后,所有的信息都在一个空间内部流转,最直接的好处就是信息损耗更少,效率更高了。
基于这一项架构创新,HiDream-O1-Image 以 8B 的参数表现出了不逊于 Qwen Image 27B 参数的性能。这一点得到了技术报告和榜单排名数据的交叉印证,在多个指标上,HiDream 相对于后者保持了持平甚至领先。
与此同时,UiT 原生支持多任务,文生图、指令编辑、主题驱动个性化,一套架构全包。想用 Stable Diffusion 3.5 编辑图像,需要加装 ControlNet,Qwen-Image 则根本不支持指令编辑。目前 HiDream-O1-Image 在开源文生图模型中,是独一份的存在。
但代价也很明显,那就是原生架构不兼容现有生态。
SD 3.5 有成熟的 LoRA 和 ControlNet,社区积累了数万小时的微调经验。反观 HiDream 生态,ComfyUI 刚刚实现支持,Ostris 训练工具也才就绪,工具链仍处在起步期。用户面对的局面,就是原生的成熟 LoRA 尚且稀缺,从 SD 生态迁移的选择又因为 checkpoint 格式不通用而被堵死。
最残酷的差距仍然来自 GPT Image 2,上面的问题对用户而言都不复存在,所有的交互就是打开网页、输入 prompt。在文生图模型走向落地的过程中,开箱即用本身就是一种至关重要,却又常常被开源模型忽视的竞争力。

HiDream在github上展示的demo
02
五维实测:HiDream-O1-Image 的能力边界在哪
光看技术报告没意思,接下来看看 HiDream-O1-Image 在实际任务中表现如何。
首先是为一款无糖气泡水设计电商海报,用于即将到来的 618 促销。我们要求 HiDream-O1-Image 针对不同投放平台,分别生成1:1、3:4、16:9、9:16 四种比例的画面,整体风格要清爽、年轻化。

实测中四种比例的画面都没有翻车,这里以 16:9 的版本为例, 可以看到冰块和水花四溅的效果相当自然,画面非常清爽。更可圈可点的是文字部分,"0 糖也好喝"和"第二件半价"的文案渲染清晰准确。对于一款 8B 模型而言,可以说是超出预期。
美中不足的是生成结果缺乏商业要素,平台 logo、价格标签和促销信息都没有,还达不到直接作为广告投放的水准。在这一点上,GPT Image 2 和 Midjourney 的完成度显然更高,差距就在对语境的理解上。当然,如果回到素材工具的维度衡量,HiDream-O1-Image 的生成和审美能力则已经完全胜任了。
第二项测试是漫画生成,这种多镜头场景覆盖了漫画创作、分镜头生成或游戏资产的生产,同样是文生图模型距离落地最近的场景之一。而其中最关键的考量,就是模型能否在频繁切换的镜头和视角下,维持住角色形象的一致性。

在测试生成的四宫格漫画中,可以注意到一个细节是,主角柴犬的红色围巾在四个画面中都出现了,颜色、位置不变,纹理也基本一致,说明HiDream-O1-Image 具备跨镜头保持视觉元素的能力。
有意思的是,我们的提示词虽然描述了画面、情节,并向模型指出这是一则漫画,但 HiDream-O1-Image 却似乎无法理解漫画对文字的包含关系,因此最初交付的生成结果只有图片,需要我们手动添加指令“加入中文对白”。这和此前电商海报的测试任务某种程度上实现了互相印证,HiDream-O1-Image 在主动理解语境上,似乎力有不逮。
在第三项测试中,我们要求 HiDream-O1-Image 生成一张面向初中生的水循环科普图片,介绍包括蒸发、凝结、降水、地表径流和地下渗透的水循环环节,并用箭头展示先后顺序。在图解中,还需要用简短中文标签标注每个阶段的名称。这项任务涉及到复杂指令遵循,和复杂画面元素对模型排版能力的考验。
在最终的五份交付结果中,有四张均准确无误。下面是唯一出现了错误的一张,其中地下渗透的水循环方向发生了颠倒。

比起简单的幻觉,这更像是某种常识错误。闭源模型得益于更长周期的 RLHF 与真实用户反馈积累,在复杂排版、文本生成和信息层级控制上的稳定性更加突出。而相对地,常识一致性和复杂指令对齐能力仍然是今天开源模型和闭源模型最主要的差距之一。
第四项测试是街景生成。这项任务的特殊之处在于,我们仅仅给出了对地点的简单描述,如“上海旧城区街景”,要求模型自行补全,生成逻辑、元素合理的图像。这考验的是模型的世界知识。
在实际测试中,我们选择了东京涩谷、巴黎咖啡馆、新加坡牛车水、上海弄堂、广州骑楼、东京京都 6 个风格强烈且对比明显的地点。

比较有代表性的是左上角的巴黎咖啡馆。深红遮阳棚加金色字体、外摆的藤编咖啡椅配小圆桌,都是巴黎左岸咖啡馆典型的视觉语言。
空间逻辑上,最成功的一张当属上排中间的新加坡水牛车街景,灯笼街的部分不仅在色彩饱和度上尽可能控制,而且整体街道透视非常稳定。从灯笼的排列就能看出这一点,灯笼之间距离几乎保持一致,消失点也符合空间逻辑。美中不足的是,HiDream-O1-Image 虽然复刻了南洋骑楼和彩色店屋的建筑风格,但是画面中仍然能看出一些香港唐楼的影子,让街景像是一种地域混搭的产物。
论建筑语言,最准确的一副是右上角的广州骑楼。连续廊柱下的遮雨空间、混合立面、深进深商铺都是鲜明的骑楼特征,画面中甚至还生成了雨天下的反光地面,很符合广州多雨水的城市印象。
对于大部分场景,HiDream-O1-Image 都能生成建筑形态合理、空间逻辑在线的街景。但纵观六个画面,文字渲染混乱的“伪汉语”仍然层出不穷。其实法语也没能逃过,左上角的巴黎咖啡馆街景中,CAFE 的拼写无误,但左侧的 OAMER 疑似无意义的字母组合。这也是一种“伪文字”的典型表现,也就是在缺乏具体文字内容指令的情况下,模型可以生成看起来像文字的纹理,但却无关乎语义的完整与否。
在最后一项测试中,我们要求 HiDream-O1-Image 为健身 APP 生成一份 UI 页面,其中需要包括训练计划、卡路里消耗、课程卡片、底部导航栏等元素。

这是最有迷惑性的一个测试。界面结构合理,组件对齐,乍看之下几乎以为是真实的 UI 稿,但却经不起细看。
最明显的问题是文字系统崩坏,热量单位在同一个页面里出现了 “kcal / kcl / kcs / kal” 四种写法,卡片标题和副标题重复,中文字体与英文排版体系完全不统一,布局上也没有突出应有的信息层级,重要区域只是靠“大数字 + 大圆角 + 荧光色”制造视觉冲击,此外的人脸破碎更不必多说,真正的 UI 设计师手底下出不了这么糙的活。
与此同时,很多看似合理的内容其实只是视觉拼贴。例如“核心强化”配图是一个人站着举哑铃,视觉上和训练内容没有直接关联。事实上这仍然是对街景生成任务中,“伪文字”问题的重复,即在不理解真实语义的情况下,文字只是某种视觉纹理。
03
8B 开源版,到底该跟谁比
你能透过这份实测看到 HiDream-O1-Image 引起的几乎所有争议。在某些场景下,它确实以 8B 参数做到了 27B 的表现,UiT 的架构创新值得尊重。而在另一些场景,GPT Image 2 的统治力依然无可撼动,用 HiDream-O1-Image 去横向对比,无异以卵击石。
但问题在于,这种对比本身是否合理?
此次开源的 8B 版本更像是一个技术路线的验证者,如果它的任务是证明 UiT 架构可行,那么这一目的显然达成了。但如果开发者社区拿到手之后,选择直接对标 GPT Image 2,由于预期错位导致的落差几乎必然的。同样的原因,此前 GPT Image 2 收获了一边倒的好评,也并非出于它的完美,而在于用户和厂商对其定位达成了共识,一款付费使用的生产级工具。
那么回到探路者的角色,HiDream-O1-Image 表现如何?
GitHub 两周 443 stars,26 forks,6 个 open issues,对一个刚满半个月的开源项目而言,这个热度不算低。ComfyUI 支持,Reddit 上累计 100+ upvotes,Ostris 训练工具就绪,技术报告上线 arXiv,就生态建设而言,动作也不算慢。
纵观整个文生图模型生态,HiDream-O1-Image 的独特位置在于,它有着最前沿的架构,模型本身的成熟度却没那么高。虽然以 Elo 1187 的评分拿下了开源模型第一,但中文支持还要打上一个问号,生态建设也仍在起步阶段,至于 LoRA、ControlNet 这些高阶玩法更是暂时不用多想。
回头来看,HiDream-O1-Image 最大的价值,就在于它揭示了 UiT 架构是一条能走通的路。统一 token space 的效率优势指向未来,此前的五维测试也暴露了边界。如果说 8B 开源版本的使命是技术验证和社区预热,借此看看 UiT 架构能做到什么程度,那么后续发布的 Pro 版本,才是那个真正要和 GPT Image 2 一较高下的选手。
8B 开源版是一扇窗,真正的风景还在 200B+ 参数的 Pro 版本之后。
文章来自于"AI科技评论",作者 "宇景"。
【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

