当 AI 开始参与训练 AI
过去,AI 研发基本是一条由人主导的流水线。
人类收集数据、清洗数据、写训练代码、设计实验,再把整理好的数据交给模型学习。但现在,这条流程正在发生变化。
AI 开始进入 AI 研发流程本身:它会写代码,会修 bug,会调用工具,会跑实验,也能围绕一个目标持续试错,把失败结果变成下一轮改进的线索。
过去几年,这个趋势最先出现在代码和实验侧。编码智能体让软件开发的一部分流程变得自动化,科研智能体也开始尝试在长程任务中不断探索、验证和修正方向。
但如果 AI 真的要参与训练 AI,还有一个更底层的问题绕不开。
数据。
在真实机器学习开发里,模型和训练流程往往不是每天都能动的。基础模型已经选好,训练方法已经跑通,大改一次就意味着更高成本、更长验证周期和新的工程风险。
相比之下,真正被反复调整的,常常是数据:找哪些样本、过滤哪些噪声、怎样清洗转换、如何组合不同来源,训练效果不好时下一轮该改规模、质量还是分布。
换句话说,当模型和训练方法越来越标准化,数据就成了最现实、也最关键的优化空间。
这篇来自上海交通大学、卡内基梅隆大学、浙江大学、北京航空航天大学等机构的工作,提出一个新的角色:AI 数据工程师。

- 论文标题:DataMaster: Data-Centric Autonomous AI Research
- 项目地址:https://github.com/sjtu-sai-agents/DataMaster
- 论文地址:https://arxiv.org/abs/2605.10906
它让智能体围绕一个给定任务,自动寻找外部数据、筛选数据源、清洗和转换数据、构建训练输入,并根据下游模型反馈继续迭代。
更关键的是,整个过程中,模型不变,训练算法也不变。
换句话说,DataMaster 问的不是“怎样设计一个更强的模型”,而是:当模型和训练流程都固定时,AI 能不能通过自己准备更好的数据,把模型继续训强?
为什么数据工程不能只靠一次生成
数据工程看起来像是在 “调数据”,但它并不是一条直线。
首先,它有很多分支。同一个任务可以先找新数据,也可以先清洗旧数据;可以扩大数据规模,也可以提高数据质量;可以改变样本比例,也可以改变输入格式。每一步选择,都会打开新的可能路径。
其次,它高度依赖前面的选择。前面选了什么数据,会影响后面哪些清洗方法有效;前面做了什么特征,也会影响模型最终能学到什么。数据工程不是孤立操作,而是一连串相互影响的决策。
最后,它的效果很难提前判断。一份数据看起来相关,不代表训练后一定有用;一次清洗看起来合理,也不代表模型分数一定提升。很多时候,只有真正跑完训练和评估,才能知道这次数据改动有没有价值。
所以,DataMaster 没有把数据工程当成一次性生成任务,而是把它变成了一场可以分叉、可以回看、可以持续优化的搜索。
一棵数据树,一个数据池,一段全局记忆
为了完成这件事,DataMaster 设计了三个核心部件:一棵数据树、一个数据池,以及一段全局记忆。
数据树负责探索不同的数据改造路径。树上的每个节点,都是一次数据工程尝试。红色节点负责向外寻找潜在有用的数据源,黑色节点负责把数据清洗、转换、组合成可以真正训练的版本。
这两个角色很像一个数据团队里的分工:红色节点是 “侦察兵”,负责扩大搜索范围;黑色节点是 “工程兵”,负责把找到的数据真正变成模型能吃的训练输入。
数据池负责保存所有已经发现的数据源。一个分支找到的数据,不会只服务于当前尝试,而是会变成整个系统都能复用的数据资产。后续节点可以继续从这里读取、组合和改造候选数据。
全局记忆则负责记录每一次尝试的结果:用了什么数据,做了什么处理,训练分数有没有提升,失败原因是什么,哪些处理策略值得复用。下一次系统再做决策时,就不必从零开始。
三者合在一起,让 DataMaster 不再像一个一次性脚本,而更像一个会积累经验的数据工程团队。
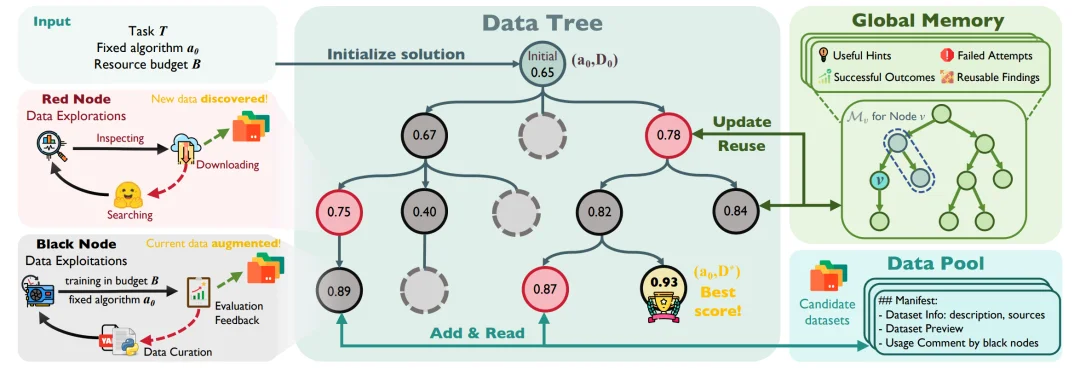
图 1:DataMaster 框架图。数据树负责分叉探索,数据池负责共享候选数据,全局记忆负责沉淀成功和失败经验。
只动数据,能涨多少?
DataMaster 最关键的实验,不是证明它 “能自动跑流程”,而是证明数据侧自动迭代本身就能带来真实收益。
论文在两个场景中验证了这一点。
第一个是 MLE-Bench Lite。这个场景更接近传统机器学习工程:任务本身给定了数据和初始训练方案,智能体不能随意改训练代码,只能围绕数据做选择、清洗、特征构造和格式适配。
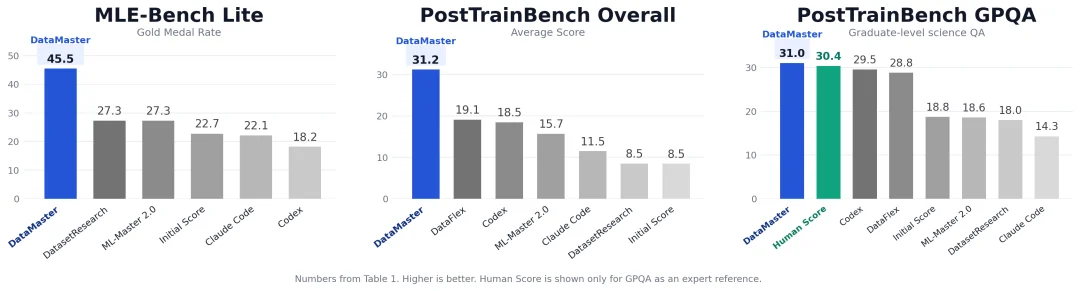
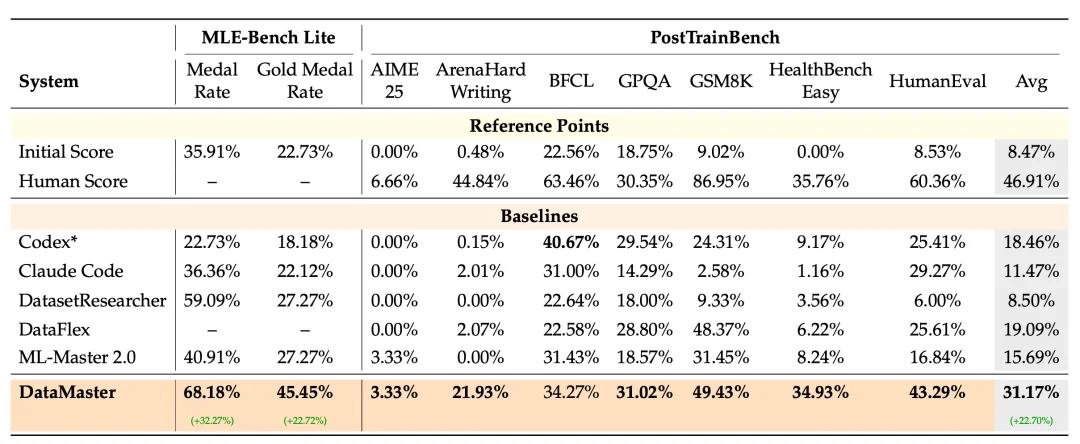
结果很直接:初始方案的奖牌率是 35.91%,DataMaster 提升到 68.18%,提高 32.27 个百分点;金牌率也从 22.73% 提升到 45.45%。
第二个是 PostTrainBench。这个场景更接近大模型后训练:基础模型固定,训练流程固定,而且没有现成训练数据,智能体必须自己发现和整理后训练数据。
在这里,DataMaster 把平均分从基础模型的 8.47% 提升到 31.17%,提高 22.70 个百分点。和其他基线相比,它也取得了最高平均分。
实验结果速览:
更值得注意的是 GPQA 结果。
GPQA 是 PostTrainBench 中最能体现高难专业能力的任务之一。它考察的是研究生级别的科学知识和推理能力,覆盖物理、化学、生物等领域,并不只是简单的常识问答。
在这个任务下,DataMaster 的 GPQA 分数从基础模型的 18.75% 一路提升到 31.02%。论文里的测试时扩展分析显示,这个提升不是一次性发生的,而是随着搜索预算增加逐步出现:DataMaster 在迭代过程中不断发现并整合更相关的科学数据、推理数据和 MedQA 数据,最终形成了更适合 GPQA 的训练数据配置。
这个结果最有意思的地方在于,DataMaster 没有更换基础模型,也没有重新设计训练算法。它做的只是围绕数据侧持续试错:找什么数据、怎么筛选、如何组合、如何适配训练。最终,它在 GPQA 上达到 31.02%,超过了专家训练的指令模型参考分数 30.35%,也超过了 Codex、DataFlex、ML-Master 2.0 等基线在该任务上的结果。
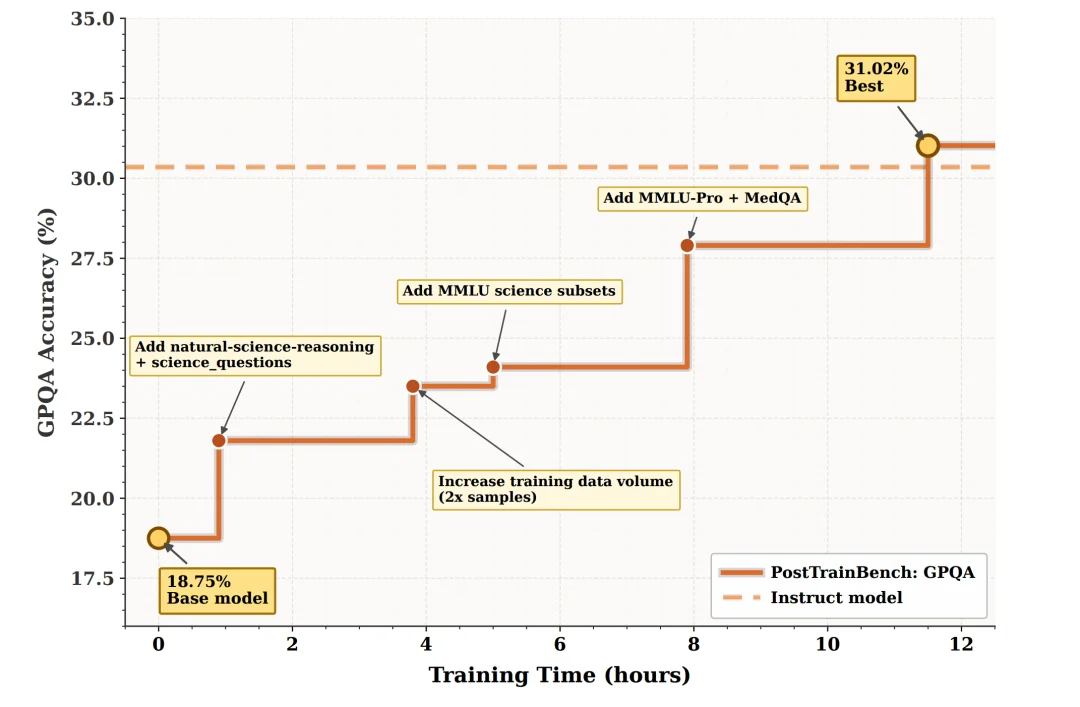
图 3:GPQA 上的测试时扩展曲线。随着数据搜索和训练预算增加,DataMaster 的最佳节点分数持续上升,并最终超过指令模型参考线。
当然,这不意味着 DataMaster 在所有能力上都超过人工后训练模型。PostTrainBench 的整体平均分上,专家指令模型仍然更高。更准确的理解是:在 GPQA 这样一个需要专业科学数据和复杂推理能力的任务上,自动化数据工程已经能够找到足够有效的数据配置,在单项能力上接近甚至超过人工设计的后训练数据参考。
为了避免这个结果被理解成 “训练到了测试集”,论文还专门做了 GPQA 的数据泄漏检查:包括屏蔽 benchmark 和 test-split 相关来源、基于测试集哈希去重、记录外部数据来源和内容哈希;在 7479 条发现的训练样本上,没有发现精确匹配或模糊匹配,3 到 5 元词组重叠率也保持在 0.08% 到 1.06% 的较低水平。
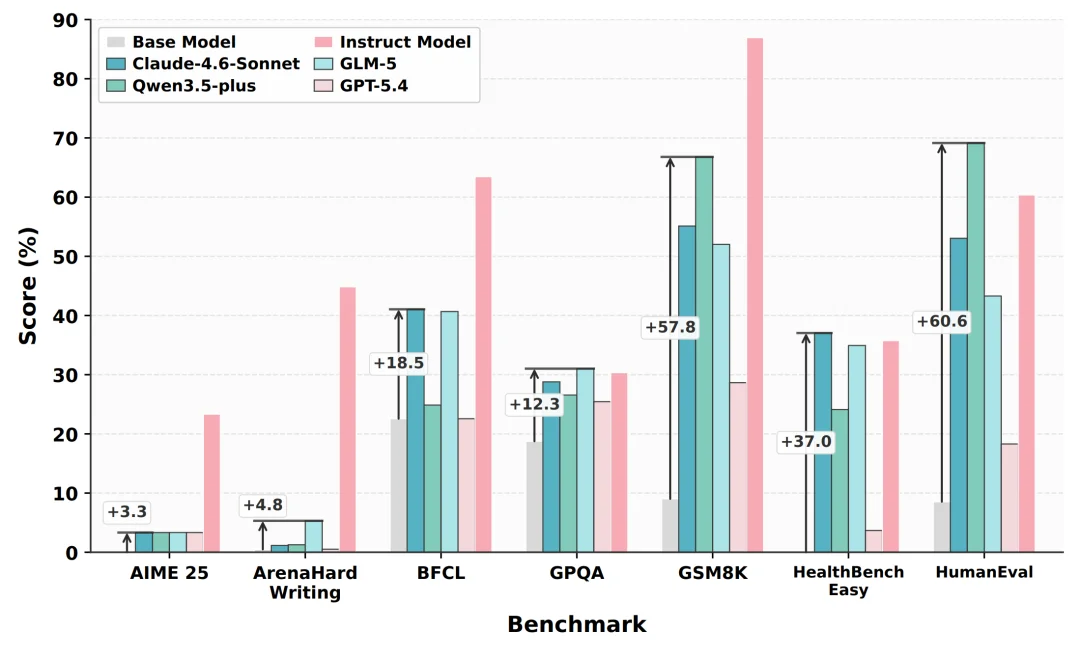
图 2:不同大模型作为智能体底座时,DataMaster 在 PostTrainBench 七项任务上的表现。
这也是 DataMaster 想传递的关键信号:数据工程不是训练前的辅助步骤,也不是简单把数据量堆大。对于特定能力来说,真正重要的可能是能不能找到更相关的数据,能不能把不同来源的数据组织成适合模型学习的形式,以及能不能根据训练反馈持续修正数据策略。
当数据也成为 AI 的决策对象
DataMaster 的意义,不只是提出了一个新的智能体系统。
更重要的是,它把一个长期被当作 “前置准备” 的环节,变成了 AI 可以主动搜索、比较、验证和复用的对象。
过去,数据通常被看作训练开始之前就已经准备好的东西。模型训练得好不好,当然和数据有关,但数据工程本身往往被放在模型研发流程之外:先由人类收集、清洗、整理,再交给训练算法使用。
DataMaster 改变的是这个位置关系。
在它的设定里,数据不再只是训练流程的输入,而是进入了智能体的决策循环:系统会决定找什么数据、如何处理数据、如何组合数据,并根据下游反馈继续调整数据策略。
这让 “以数据为中心” 的 AI 研发变得更加具体。它不只是说数据重要,而是进一步追问:数据能不能像代码、模型和实验一样,被智能体持续优化?
当然,一旦数据工程开始自动化,新的问题也会变得更重要。外部数据从哪里来,是否合规,是否污染测试集,是否能追踪来源,系统为什么选择这批数据而不是另一批数据,都需要被记录和审计。
也就是说,自主数据工程真正走向真实世界,不只是要让 AI 更会做数据,还要让 AI 的数据决策过程本身变得透明、可控、可复盘。
这可能是 DataMaster 留下的更大问题:当 AI 开始管理数据时,人类真正需要管理的,是 AI 管理数据的方式。
如果说过去的模型是在学习人类准备好的数据,那么 DataMaster 指向的是下一步:AI 开始参与决定自己应该学习什么数据。
这也是它最值得关注的地方。
文章来自于"机器之心",作者 "机器之心"。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md

