为解决科研中对单篇文献深度解析的需求,佐治亚大学团队提出IntrAgent,专注单篇内容,避免大模型幻觉。通过段落排序与迭代阅读机制,精准提取实验细节与元数据。
在AI4Science不断推进的背景下,大语言模型(LLM)利用文献检索来回答科研问题已成为常态。
然而,现有的AI工具(如传统RAG或PaperQA系统)往往依赖于「广泛跨文献检索」——即在大规模本地知识库或开放互联网中,跨越数十篇甚至上百篇文献提取零散的文本片段,进而通过大模型进行信息拼接。
这种模式虽然擅长生成宏观、宽泛的综述性摘要,但在面对特定研究驱动的硬核问答时,却极难满足科研人员对单篇文献内部精准实验细节和严谨元数据的极致要求。
为解决这一问题,佐治亚大学(UGA)多学科团队提出了IntrAgent。该工作标志着科研AI工具从「广泛跨文献检索」向「单篇文献深度解析」的范式演进。

论文链接: https://arxiv.org/abs/2604.22861
项目主页: https://intragent.github.io/
该研究不仅跨学科定义了贴合真实科研工作流的新任务IntraView及基准测试IntraBench,还为IntrAgent设计了「段落排序 + 迭代阅读」的创新机制,专注于单篇文献的绝对内容忠实(Content-Grounded),有效抑制大模型的「幻觉」。
在7款主流大语言模型上,IntrAgent在专家级测试中的准确率相较于当前最优基线平均提升了13.2%,该成果已被自然语言处理领域顶级会议ACL 2026主会录用。
研究背景
在当前的科研实践和学术讨论中,现有的文献智能体、RAG(检索增强生成)系统以及诸如PaperQA等工具,多被视作高级搜索引擎或跨文献的信息聚合器。
其常规工作模式是在一个庞大的本地库或开放互联网中,跨越数十篇甚至上百篇文献提取相关的碎片化文本片段,进而通过大语言模型重构、拼接为结构完整的综述性回答。
这种模式固然在宏观视角的文献调研、研究现状追踪中能够发挥作用,但在实际的科学研究和严谨的科研论证中,它是否真正触及了一线科研人员的核心痛点?答案或许是否定的。
结合团队中来自物理、材料、地球科学等多学科专家的亲身科研经历,我们深刻意识到一个残酷的现实:在实际的科研工作流中,诸如复现特定实验、推导公式边界条件、或是查阅新材料合成配方等关键决策节点,往往决定了后续数月实验乃至整个项目的成败。
在这些决定性的节点上,科研人员其实早就锁定了某一篇具有奠基意义的核心文献。此时,哪怕是一个微小温度参数的误读、或是一个前置假设的遗漏,都会在现实实验室中转化为高昂的沉没成本。
在这种对「内容忠实度」有着极致要求的真实场景下,任何跨文献的模糊总结或信息拼凑带来的偏差都是不可接受的。
科研人员需要的绝不是多篇文章浮于表面的宏观概括,而是针对这篇特定核心文献毫无幻觉的深度挖掘——即精准提取其特定的实验设置、多变量控制参数、上下文假设以及隐藏在复杂图文逻辑中的元数据。这种对单篇文献逐字逐句的精准「榨取」,是传统跨文献搜索聚合方法完全无法满足的。
从「广泛跨文献检索」向「单篇文献深度解析」的范式演进,正是为了回应这一严谨的科研常态。
现有的各类通用科研智能体习惯了发散式的外部资源探索,在面对必须严格受限于单篇文献内容的细粒度检索任务时,往往因缺乏对长文本内部复杂组织结构的深度感知而失效。
同时,由于缺乏严格的内容约束机制,它们极易调用大模型自身的参数化预训练知识,从而产生看似合理实则致命的「幻觉」。这种「幻觉」和信息拼凑,不仅会误导科研决策,更会直接导致实验复现失败。
因此,科学界迫切需要一种能够专注于单篇文献内部,具备极致高保真度、无幻觉的细粒度内容检索新范式。
研究方法
新任务IntraView
为了填补上述技术鸿沟,佐治亚大学的计算机科学研究团队采取了深度的跨学科协同创新模式。
他们没有将研究局限于计算机科学的单一视角,而是联合了校内物理、地球科学、公共卫生、工程和材料科学等五个代表性STEM学科的专家学者,共同定义了由实际科研痛点驱动的新任务——INformation reTRieval through literAture reVIEW(IntraView,文献内部信息检索)。
新基准测试集IntraBench
在这一新任务的基础上,团队协同构建了专家级基准测试集IntraBench。在设计这一基准测试时,团队明确摒弃了传统测试盲目追求文献数量「覆盖度」的倾向。
这是因为,单纯追求广泛覆盖度的测试往往可以通过简单的表面语义匹配或关键词检索来获得高分,这掩盖了大模型在深度研读、长文本长程依赖理解上的真实技术缺陷。
与之相反,IntraBench 更加关注文献解析的「深度」。
这五个入选的学科具有高度的代表性:物理和工程学涉及复杂的公式推导和严苛的边界约束;地球科学和公共卫生学依赖于庞大而精确的模拟参数与统计元数据;材料科学则包含了多步骤、高灵敏度的实验配方与工艺条件。
在这些领域中,一个参数的微小差错就会导致整项科学研究的失效。
为了确保基准测试的实用性并消除语义模糊性,IntraBench的315个专家级测试实例均由各学科专家依据实际科研场景中的痛点亲自设计。问题的构建不仅要求模型具备多步骤的逻辑推理能力,还需要其在复杂论文中,跨越不同章节进行信息比对。
为了解决文本检索中常见的歧义性与多义性问题,专家在标注过程中进行了严格的可用性筛选,过滤掉了一切流于表面的、可以通过模糊语义检索直接获取答案的浅层问题,使得每一个问题都必须依赖对文献上下文逻辑链条的完整掌握才能准确作答。
这使得 IntraBench 成为了检验 AI 智能体是否具备真正专家级精读能力的「试金石」。
新智能体框架IntrAgent
为了攻克这一高难度的IntraView任务,团队开发了核心智能体框架IntrAgent。该框架摒弃了传统大模型的发散式外部探索,其核心设计理念在于完全「模仿人类专家的真实文献阅读与研读行为」。IntrAgent 的工作流水线被巧妙地设计为两大核心阶段:
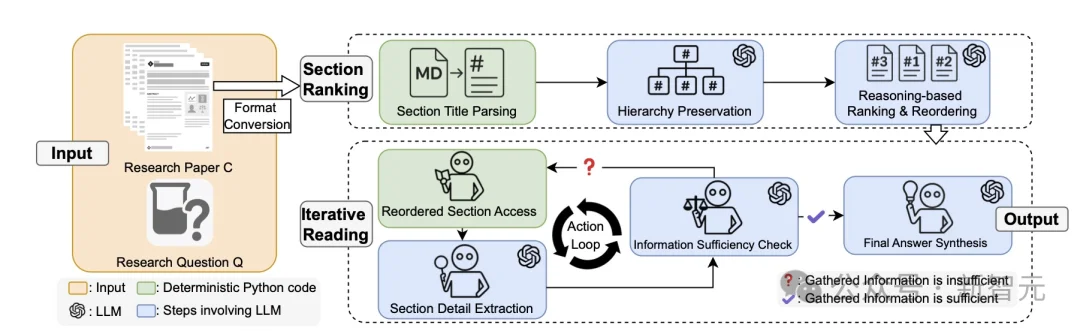
图1:IntrAgent 核心架构与工作流水线
1. 段落排序(Section Ranking)阶段:
人类专家在寻找文献中的特定细节时,绝不会盲目地从头读到尾,而是会首先根据文章的目录、小标题以及层级结构进行宏观推理。IntrAgent同样利用了文献固有的层级结构知识。
它首先对输入的复杂长文献进行结构化解析,建立层次化的章节树,然后通过基于结构知识的推理,对文献的所有段落进行相关性排序,优先筛选并定位出最可能包含答案的特定章节。
这一机制通过排除无关章节的干扰,大幅降低了长文本处理时的信息噪音,使模型能够集中算力「精读」最有可能包含答案的核心段落。
2. 迭代阅读(Iterative Reading)阶段
在精准定位相关段落后,智能体进入微观的精读和挖掘过程。IntrAgent 在此阶段模仿了人类反复确认、带着线索追踪上下文的习惯。
在提取出初步的细节后,系统并不会直接输出答案,而是会触发一个核心的信息充足性检查(Sufficiency Check)机制。该机制会严密评估当前提取到的信息是否足够完整、是否满足回答问题的所有前置条件。
如果发现信息不足或存在逻辑链条的断裂,智能体不会进行主观推测或盲目拼接,而是会把当前已获得的线索作为新的搜索锚点,重新跳回文献的上下文树中进行迭代深挖。
这种「精准定位、层级推理、反复核对」的闭环机制,使 IntrAgent 能够将大模型牢牢锁定在原文的内容边界之内,从根源上阻断了外部幻觉的引入,确保提取出的每一个微观细节都具备绝对的、无可争议的内容忠实度。
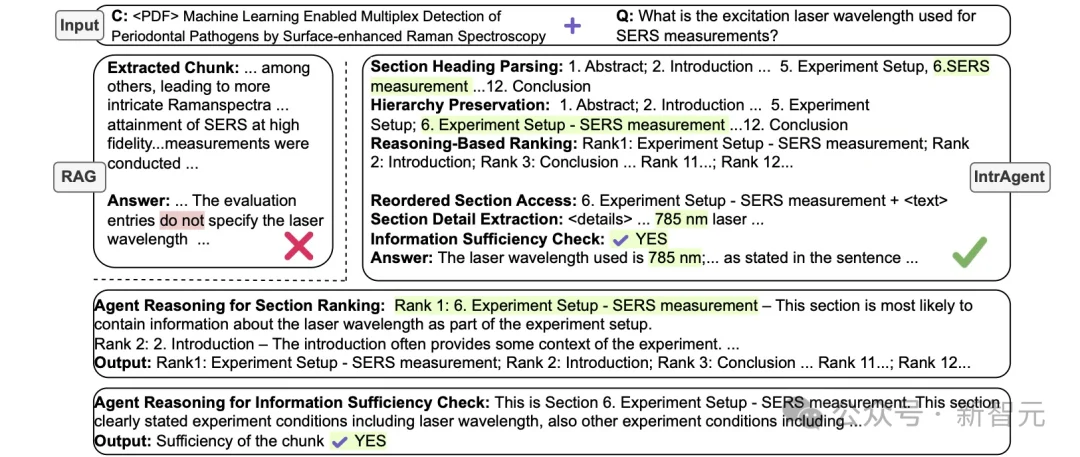
图2:IntrAgent与传统RAG系统在核心参数提取任务上的真实表现对比。
总结
在实验评估阶段,研究团队将IntrAgent部署在包括闭源前沿模型和主流开源模型在内的7款大语言模型上,并在涵盖五个STEM领域的IntraBench基准上进行了全面而严苛的测试。
实验数据表明,相较于当前在学术界和工业界领先的RAG(检索增强生成)系统,以及现有的各类通用科研智能体基线,IntrAgent展现出了压倒性的性能优势,其跨领域的平均准确率实现了13.2%的显著提升。这一成果不仅在统计学意义上表现显著,在实际应用层面也带来了质的飞跃。
无论是在复杂的地球科学气候模型中精准提取出特定的多维演化参数,还是在材料科学文献的多步反应中获取极其微量但关键的工艺温度,IntrAgent均表现出了极高的鲁棒性、准确性以及对原文献语境的绝对忠实。
从「广泛跨文献检索」向「单篇文献深度解析」的范式上演进,是AI4Science走向深水区的必然要求。IntrAgent的提出与成功验证,向科学界展示了一种全新的高精度、高保真长文献解析新范式。
它有力地证明了,未来的科研AI辅助工具不应仅停留在泛泛的、浮于表面信息的「搜索引擎」和「文本拼凑器」阶段,而应当向着能够深入科学底层肌理、像人类学者一样严谨专注的「深度精读智能体」方向发展。
随着这种具备高度内容约束力的智能体技术的不断完善与推广,它必将在加速科学实验复现、提高科研论证严谨性以及辅助重大科研决策的进程中,发挥出不可替代的破局作用。
参考资料:
https://arxiv.org/abs/2604.22861
文章来自于"新智元",作者 "LRST"。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/

