世界模型火,火到都有点乱了。
单单一个定义,就越来越众说纷纭:视频生成模型可以是世界模型,能生成游戏的语言模型也被叫世界模型,还有人把物理引擎也塞进这个筐里……
乱,乱得李飞飞本人都有点看不下去了。刚刚,她亲自撰文,给世界模型来了个清晰的功能分类。
用词毫不客气:世界模型是当今人工智能领域最重要也最被滥用的术语之一。
古希腊人无法就世界的构成达成共识,因为“世界”从来不是一个单一的实体。人工智能也继承了同样的问题,而此时,这个领域恰恰最需要的就是精准性。
至少,要先分清三件事:
渲染、模拟、规划。
话不多说,赶紧一起来做笔记。
世界模型的三大功能
李飞飞首先拆析了世界模型的技术意义。
智能体(人、机器人或系统)会采取行动,这些行动会影响世界的状态。
所谓“状态”,是对某一特定时刻世界所发生的一切的完整描述,包括每一个物体、每一个位置、每一个速度和每一个属性。
观察是主体对这种世界的客观实在的局部感知。行动是主体对这种实在的回应。
主体→行动→状态→观察→返回,赋予了“世界模型”以技术意义。现在被称为世界模型的各种事物,实际上是同一个循环的不同投射。
具体到功能上,李飞飞认为,世界模型具有渲染、模拟、规划三大功能。
其中,模拟器获得关注最少,但最关键,是连接渲染和规划的桥。
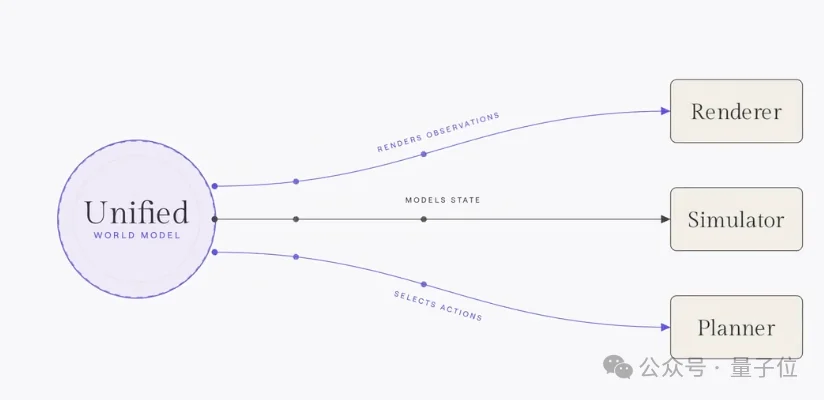
渲染器
渲染器输出给人看的观察结果,核心指标是视觉保真度。
谷歌的Genie 3,以及李飞飞自家World Labs的RTFM,都属于渲染器。
这些模型本身并不具备对三维结构的明确理解。它生成的是观众看到的画面,而不是实际存在的画面。
比如,AI生成的无人机航拍镜头中,建筑物从空中俯瞰可能完美无瑕,但如果你开车穿过下面的城市,就会发现它们摇摇欲坠。
李飞飞认为,渲染器是目前商业上最成熟的技术。比如Nano Banana,就是风靡全球的代表。
局限性在于,渲染器优化的是视觉上的逼真度,而非物理上的精确度。其输出结果非常吸睛,但无法用于建筑设计或机器人训练这样与现实世界结合更紧密的场景。
规划器
规划器输入观察和目标,输出下一步动作。
VLA模型和新一代世界动作模型都属于规划器,这些系统决定了机器人在非结构化世界中应该做什么。
规划器最吸引人,也最具发展潜力。具身智能就与此紧密相关,而大量热钱也正在涌入这一环节。
但李飞飞指出,近年来很多令人印象深刻的机器人演示,都局限于高度受限的实验室环境,目标对象范围狭窄,任务周期短,无法在真实世界部署所需的复杂性、可变性和持续时间下进行验证。
模拟器
模拟器输出可计算、可交互的状态,强调几何、物理、动态一致性。
模拟器要求几何结构经得起检验,在物理上符合物理定律,其动力学行为符合世界运行的方式。
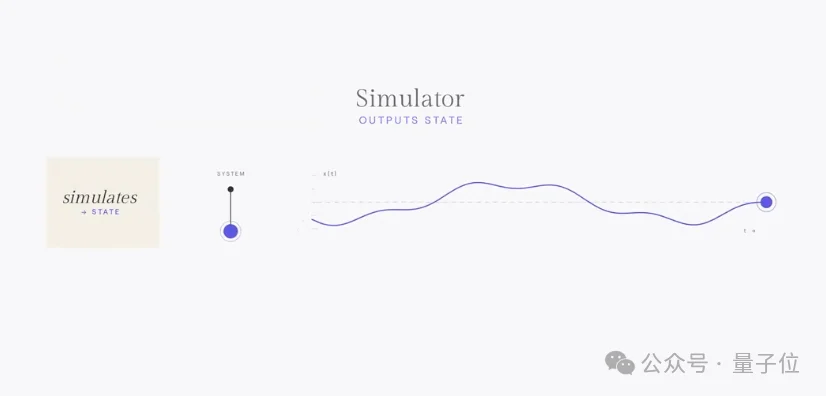
模拟器同时服务于两个用户群体:
建筑师、设计师、电影制作人和游戏开发者等专业人士需要超越视觉逼真性的精确度。
强化学习智能体、机器人控制器和自动驾驶等领域则将模拟器作为训练场,以大规模地与世界交互,测试那些在现实中危险、昂贵或不可能运行的场景。
李飞飞认为,模拟是连接渲染和规划的桥梁。
如果说语言是对世界的抽象,像素是对世界的投影,那么几何、物理和动力学就是世界本身。
而模拟器,正是视觉外观(对于渲染器而言)和动作后果(对于规划器而言)得以生成的结构骨架。
仿真模型可以将自身的理解转化为像素图像供人类使用,并预测实体智能体的行为。机器人训练、自动驾驶测试、建筑可视化、工程设计和药物研发等都依赖于某种仿真技术。
其商业应用前景极其广阔,比如英伟达的Omniverse平台,就瞄准了这一超万亿美元的潜在市场。

问题在于,能用来训练模型器的数据太少了:具有明确几何形状、材料属性和物理标注的三维数据比渲染器训练所用的互联网视频少几个数量级。
模拟本身就与现实存在差异,而生成式模拟器还引入了新的风险:AI生成的东西可能看起来正确,但细究起来又有很多不符合物理的地方。
大规模多物理场模拟(刚体、可变形物体、流体、布料相互作用……)的成本更是比单域模拟高出几个数量级。
World Labs自家产品Marble旨在突破模拟环节的瓶颈:它支持文本、图像、视频或空间草图等多模态输入,生成可探索3D环境,并输出Gaussian splats和可供物理引擎操作的碰撞网格。
但李飞飞也强调:Marble仅仅是这一领域漫长发展历程的开端。
边界正在消融
李飞飞在这篇文章中的另一个关键观点是:三类模型正在相互融合。
渲染一个世界、模拟一个世界、在一个世界中行动,所需要的知识,在很大程度上是同一套知识。
举个例子:
如果一个模型真正理解一个杯子是如何放在桌子上的,包括其几何结构、材料属性、受力反应等等,那么它就应该能够从任意角度渲染这个杯子,模拟杯子被推动时发生什么,并规划一只手如何把它拿起来。
这三类能力,其实是对同一种底层理解的三种投影。
近期研究已经证明,至少在概念上,一个预训练视频渲染器可以作为联合世界预测和行动预测的骨干网络。
这暗示了渲染器和规划器之间的一座桥梁:
让同一个模型既想象接下来会发生什么,也想象接下来应该做什么。
Marble从单个模型中同时输出Gaussian splats和碰撞网格,就是渲染器和模拟器之间边界消融的一个体现。
每一个层级都在从被动输出,走向交互系统。渲染器正在变得以行动为条件。模拟器正在生成更可控、更可编辑的世界。规划器则正在从单纯反应,走向真正的审慎思考。
这个逻辑终点,是一个统一的世界模型——
一个基础模型,既能够渲染照片级真实的视图,也能生成物理准确的结构,并规划行动序列。
核心的挑战仍然是数据。
渲染器拥有海量互联网视频,但模拟器和规划器却严重缺乏3D资产和机器人演示数据。
追求视觉美感,可能会牺牲机器人或高保真模拟所需要的精度。如何在单一架构中调和这些矛盾,是今天世界模型研究最核心的开放问题。
但李飞飞乐观地表示:方向已经很清楚了。
三条本来相互独立的研究线索,如今各自已经驱动并塑造了数十亿美元级别的产业。而现在,它们开始表现得像同一件事。
当它们的边界共同塌缩,这种变化将重塑一个更大的问题:机器智能,和它所处的物理世界之间的关系。
这就是空间智能的漫长弧线。语言给了机器一种谈论世界的方式,而世界模型,将是机器最终理解、想象、推理并与世界互动的方式。
原文链接:
https://x.com/drfeifei/status/2062247238143996275
文章来自于"量子位",作者 "鱼羊"。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md

