如何仅从一张图片中生成可用的3D资产?这个问题正成为3D生成、机器人感知和空间计算的基础能力。
过去单图3D重建更多地还是停留在“能生成一个物体”,SAM3D的出现则把问题推进到更复杂的开放场景:
给定一张图像和目标mask,不仅能重建任意物体,还能恢复纹理和空间布局。
然而走向真实应用时,推理效率很快成了新瓶颈。高质量3D重建时间过长,难以支撑复杂场景,所以能不能更快、更稳定、更便宜地重建?

为应对这一挑战,来自中国科学院计算技术研究所、ETH Zurich等机构的研究者提出了Fast-SAM3D。
该方法直接面向SAM3D的推理链路做训练无关加速,在最大程度保持重建质量的同时,将单对象生成提速最高2.67倍,场景生成提速最高2.01倍。
以下是更多详细内容。
SAM3D如何被加速?
SAM3D采用“粗到精”的两阶段流程:先预测物体的粗结构和空间布局,再进一步细化几何、纹理,最后通过解码器输出显式3D结果。
作者对其推理过程做了系统profiling后发现,耗时主要集中在三个环节:Sparse Structure生成器、Sparse Latent生成器,以及Mesh解码器。
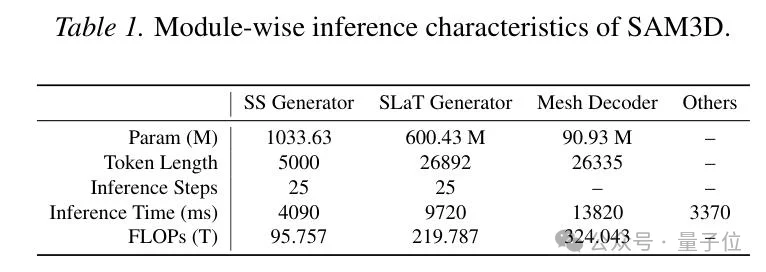
△迭代式生成器和Mesh解码器是主要计算瓶颈
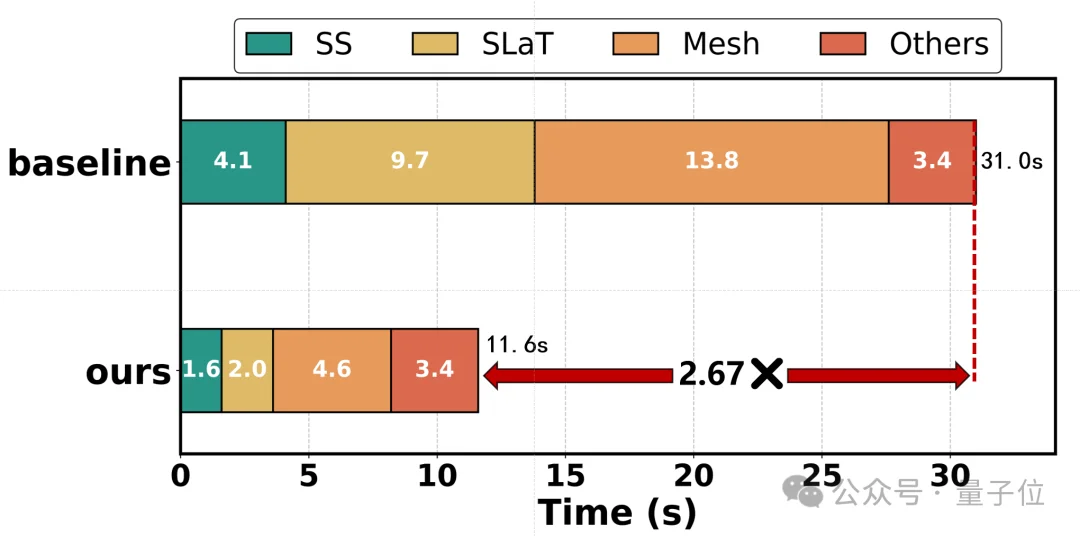
△各模块上均实现大幅度推理加速
但SAM3D的“慢”并不是均匀发生的。
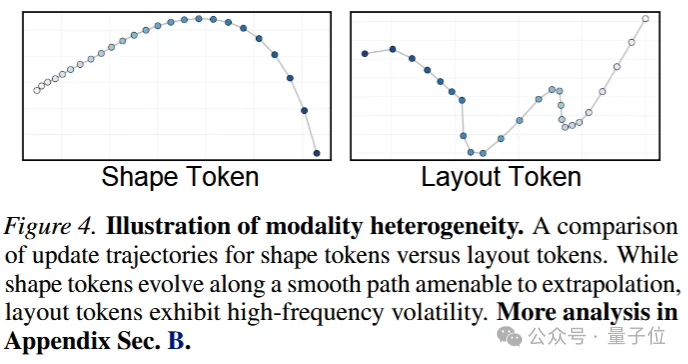
形状token的变化往往比较平滑,可以被更简单地预测;布局token控制姿态、旋转和尺度,小误差就可能造成整体漂移;纹理和细节更新也不是处处发生,真正需要反复计算的通常是边缘、接缝、薄结构等高熵区域。此外,杯子和龙雕这类物体在几何复杂度上差异巨大,也不应使用同样密度的解码预算。
这就解释了为什么简单的通用加速策略在SAM3D上容易失效。统一跳步可能带来位姿漂移,随机token剪枝可能导致结构坍塌,统一下采样又会抹掉复杂物体的细节。
Fast-SAM3D的核心思路因此很明确:不是粗暴少算,而是把计算花在真正需要的地方。

计算资源与模块复杂度相匹配
Fast-SAM3D的框架由三个模块组成,分别对应结构生成、细节生成和网格解码三个关键阶段。
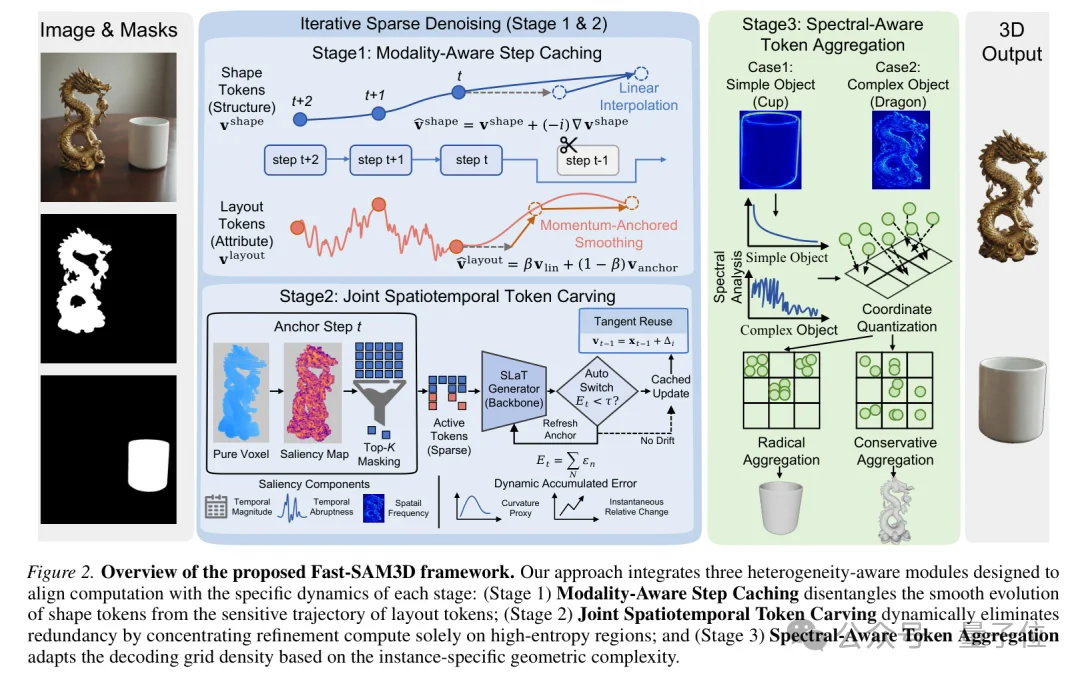
△Fast-SAM3D三部分组成
首先是Modality-Aware Step Caching。
在结构生成阶段,Fast-SAM3D将形状token和布局token区分处理:对演化平滑的形状 token 进行预测和复用,对更敏感的布局 token 则用锚点约束来抑制抖动。
这样既减少了主干网络调用,又避免了物体姿态在加速过程中“跑偏”。
其次是Joint Spatiotemporal Token Carving。
在细节生成阶段,Fast-SAM3D不再让所有token平均参与计算,而是根据时间变化、突变程度和空间频率找出最值得更新的区域。
平滑表面可以少算,边缘、尖角、纹理突变等区域则获得更多计算资源。
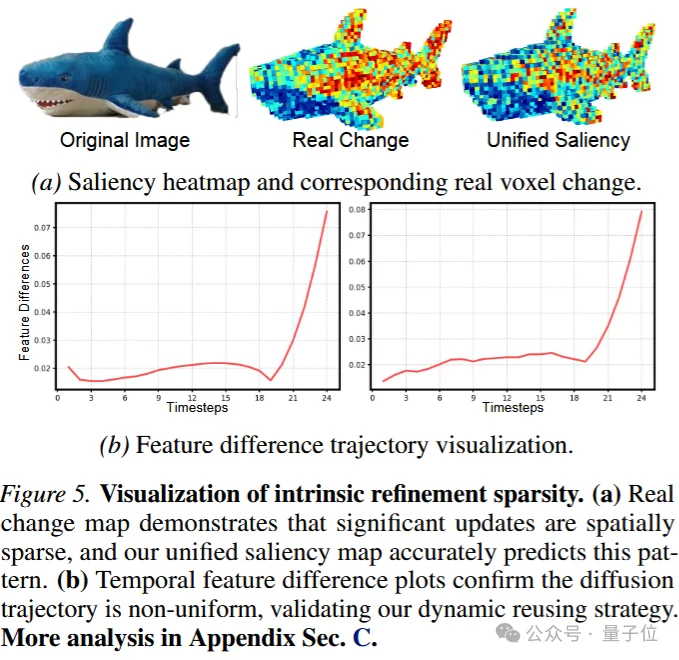
第三是Spectral-Aware Token Aggregation。
在Mesh解码阶段,方法通过2D mask和3D粗结构的频谱信息估计物体复杂度:简单物体更激进地聚合token,复杂物体则保留更多高频细节。
这使得系统可以针对不同物体自适应分配解码预算。

速度提升,质量基本不掉
在SAM3D基准上,Fast-SAM3D将场景级生成时间从462.3秒降至229.7秒,实现2.01×加速;单对象生成达到2.67×加速。
与此同时,几何质量并未明显下降,F1@0.05从92.34提升到92.59,vIoU也从0.543提升到0.552。
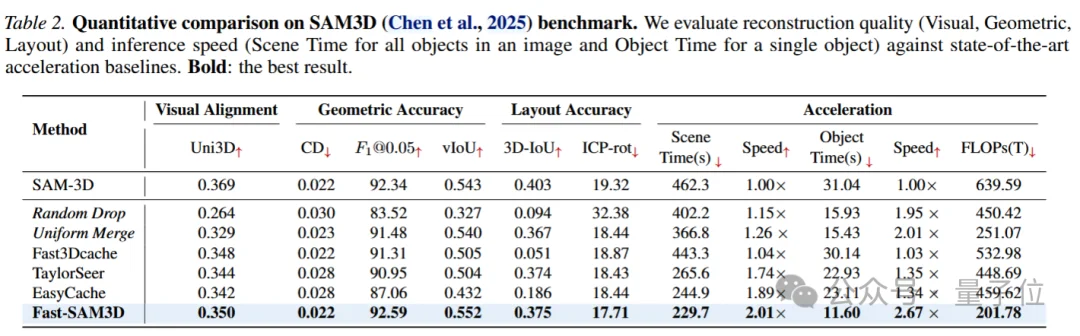
定性结果同样说明了这一点。
随机剪枝容易造成结构坍塌,通用缓存方法可能出现语义或布局漂移,而Fast-SAM3D的结果与原始SAM3D更接近。
这说明3D重建中的加速不能照搬2D扩散模型经验,而需要理解3D数据自身的结构、位姿和频谱差异。

总的来说,Fast-SAM3D的价值不只在于刷新速度指标:
- 内容生产:更快的单图3D重建意味着设计师可以更频繁地试错,把图片素材快速变成可编辑资产;
- 电商和展示业务:商品图转3D的成本下降后,批量3D化才有可能成为常规流程;
- 机器人和具身智能:系统若能更快从现场图像中恢复可操作物体,将直接影响在线感知与规划效率;
- AR/VR应用:低延迟重建则决定了交互体验是否自然。
更实际的一点是,Fast-SAM3D是训练无关框架,不需要重新收集数据或重训基础模型,因而更容易接入已有SAM3D流程。
它给出的启发也很清晰:当3D生成能力逐渐从“能做”走向“可用”,系统级效率优化会变得和模型能力本身一样重要。
下一阶段,单图3D重建的竞争点将不只是生成效果,而是能否在真实业务中稳定、快速、低成本地运行。
Fast-SAM3D正是在这个方向上迈出的一步。
本文共同第一作者为中国科学院计算所博士生冯伟伦、硕士生伍明强。通讯作者为中国科学院计算所杨传广和安竹林副研究员。核心成员来自计算所智能算法安全全国重点实验室智能优化课题组,隶属于徐勇军研究员团队,课题组长期从事高效人工智能的研究,重点关注视觉、多模态等领域的理解与生成高效性方面的研究。
论文链接:https://arxiv.org/abs/2602.05293
代码链接:https://github.com/wlfeng0509/Fast-SAM3D
文章来自于微信公众号 "量子位",作者 "量子位"

