视觉生成正在进入一个新的能力错位阶段:
模型已经能生成高质量、连贯、逼真的视频,但一遇到需要严格遵守规则的推理任务,仍然容易翻车。
- 让小球在迷宫中到达终点,同时不能穿墙、不能消失;
- 让物体移动到对应目标框,同时保持颜色、形状和数量不变;
- 让椅子精确逆时针旋转90度,同时周围环境保持不变。
这类任务不只要求最后一帧“看起来对”,还要求中间过程也合法。
这正是“Reasoning with Video”关注的问题:
把视频生成模型(VGM)看作可视化推理器,让它通过生成一段时间连续的视觉轨迹来完成任务。
两条旧路线:一个不动模型,一个只写文字
怎么让VGM学会按规则推理?过去主要有两条路。
两条路,一个不动模型,一个只写文字,都没真正解决“执行”问题。
为此,城大×快手可灵提出了第三条路:VLM-as-Teacher。
不是让VLM先写答案,而是让VLM在测试时当“老师”,把过程约束和最终目标变成可优化的监督信号。
下图为Naïve Scaling、VLM-as-Solver与VLM-as-Teacher三种范式的核心差异。
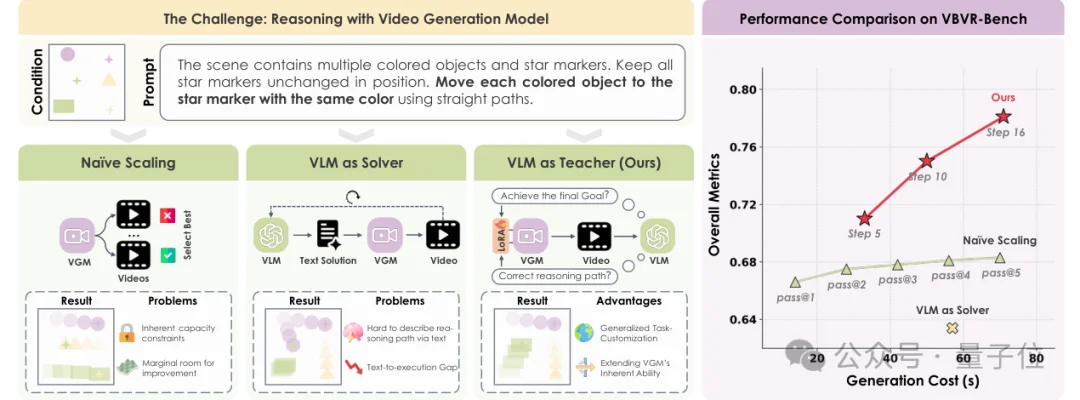
第一类是Naïve Scaling,也就是在固定VGM上多采样、多搜索、再选最好结果。
它能降低随机错误,但模型参数始终不变,候选空间仍受限于VGM的固有生成能力。
因此,面对穿墙、跳步、物体状态不一致等系统性错误,多试几次往往提升有限。
第二类是VLM-as-Solver,让VLM先分析任务、生成更详细的文本规划或prompt,再交给VGM执行。
问题在于,文字规划不等于视觉执行。
复杂的时空细节、几何约束和过程一致性,很难仅靠语言精确描述,更难保证VGM忠实落实。
因此,VLM-as-Teacher要解决的不是“VLM能不能想出答案”,而是“VGM能不能把规则真正执行出来”。
新范式:VLM-as-Teacher,让VLM当测试时老师
这项研究的核心洞察是:VLM未必是最好的“视频推理解题人”,但它很适合当“老师”。
换句话说,VLM不一定能给出一条完美的可执行视频生成方案,但它往往能判断一个生成结果是否满足要求:
球有没有到终点?有没有穿墙?手最终是不是五根手指?椅子有没有旋转90度?中间过程中周围物体有没有保持不变?
于是,作者把VLM的角色从solver变成teacher。
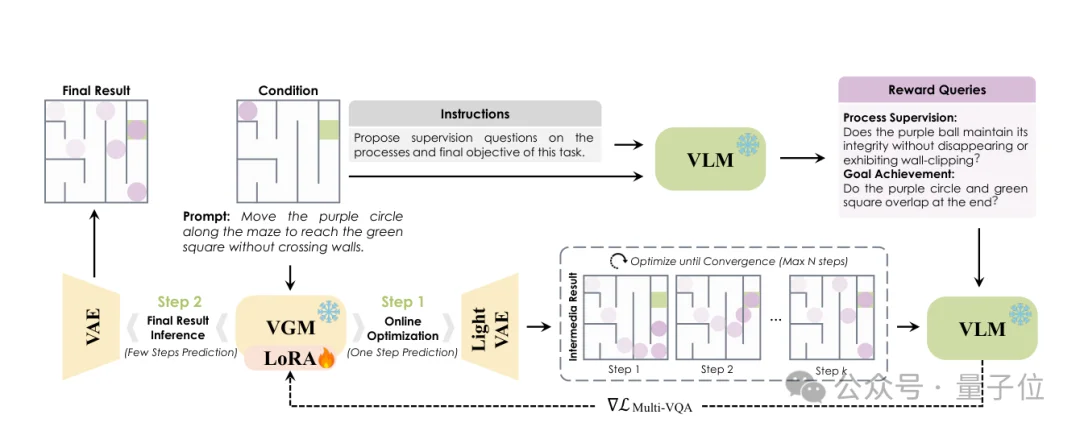
VLM Teacher不再只输出一段文本规划,而是根据任务自动生成一组监督问题:
一个final-goal query检查最终目标是否达成,若干process query检查中间过程是否满足规则。
所有问题都被设计成正向问法,模型希望VLM回答“Yes”。
这样,VLM对“Yes”的概率就可以转化为一个可微的VQA reward。
随后,系统通过在线测试时优化(online test-time optimization),只更新VGM Reasoner中的轻量LoRA模块,而冻结VGM主干和VLM Teacher。
这一步非常关键:它不是在prompt空间里继续改写文字,也不是在固定模型里反复抽样,而是在每个测试样本上,根据VLM Teacher的反馈,对VGM Reasoner进行实例级优化,让生成轨迹朝着满足规则和目标的方向移动。
下图为VLM-as-Teacher的框架。VLM先合成过程监督和目标监督问题,再通过可微反馈优化VGM Reasoner的LoRA模块。
从“是否成功”到“如何成功”:过程监督和目标监督缺一不可
视频推理任务并不只看最后一帧。
一个球最终出现在终点,但中途穿墙了,不算真正成功;一只蜗牛最后出现在潮湿区域,但如果过程中突然换成了另一只蜗牛,也不算成功。
因此,论文把任务成功定义为两个条件同时满足:
final-goal achievement和process-constraint satisfaction。
前者保证最终目标达成,后者保证中间轨迹合法、自然、连续。
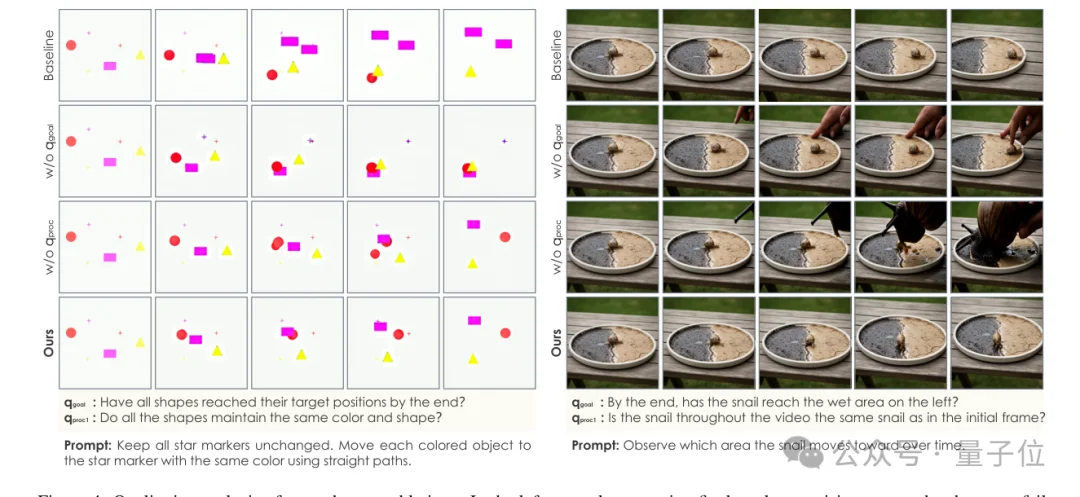
Reward ablation进一步说明了这一点。
去掉final-goal reward,模型可能在过程中保持形状稳定,却无法完成目标状态;去掉process reward,模型可能通过“作弊路径”达成表面目标,例如引入另一只蜗牛覆盖过去。
只有两类监督同时存在,模型才更可能生成真正合法的推理视频。
如图所示,左图显示去掉final-goal supervision会导致目标状态失败;右图显示去掉process supervision会允许shortcut轨迹。
为了让在线优化可用,作者还做了三层加速
如果直接把VLM反馈接到视频生成模型上反复优化,代价会非常高。
论文中加入了三项效率设计。
第一,在线优化阶段不使用标准视频VAE,而是用LightX2V的轻量surrogate decoder,降低可微解码的显存和计算成本。
最终生成视频时,再回到标准VAE解码,以保证输出质量。
第二,将VGM Reasoner蒸馏成四步生成器,并只优化第一步clean-latent prediction。
作者观察到,少步Reasoner的第一步预测已经能呈现出可感知的高层推理轨迹,足以供VLM Teacher进行评价。
第三,使用loss-based early stopping。
当VLM Teacher对所有reward query的“Yes”回答具有足够高置信度时,优化提前终止。
论文中最大优化步数设置为40,但实际在VBVR-Bench上平均约16步即可达到较好效果。
实验:平均提升16.7分,明显超过多采样和文本规划
论文在两个互补benchmark上评估:
VBVR-Bench关注符号视觉推理,RULER-Bench覆盖更通用的视频推理场景。
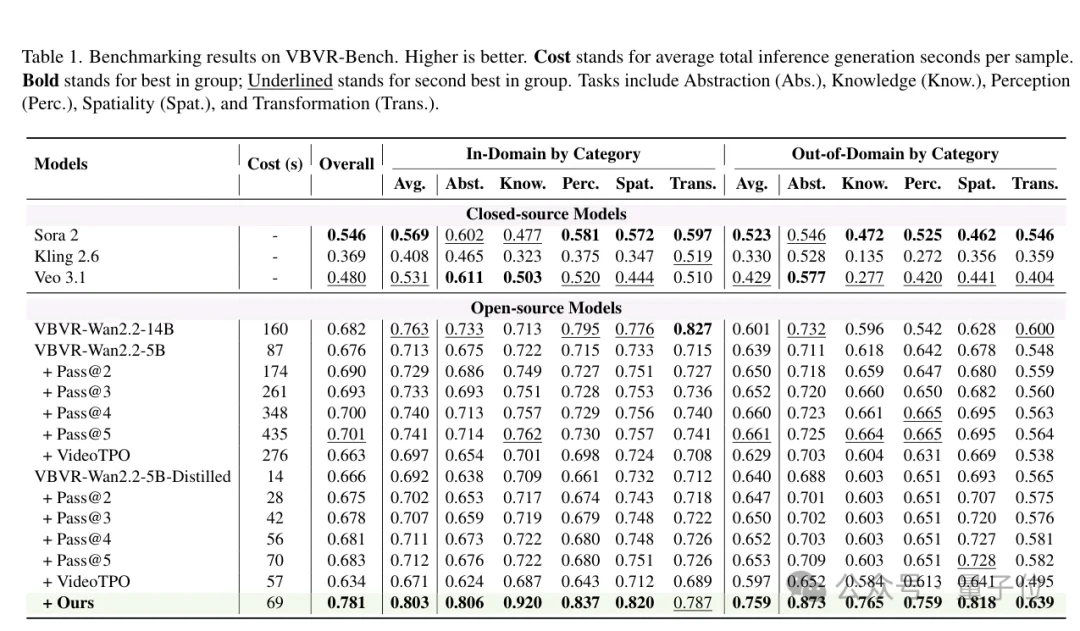
整体上,本文方法取得16.7-point平均性能增益,而VLM-as-Solver平均仅提升+0.4 points,Best-of-N scaling仅提升+2.2 points。
在VBVR-Bench上,step-distilled Reasoner从0.666提升到0.781;
相近测试时成本下,Pass@5只到0.683,VideoTPO反而降到0.634。
下图对应论文原文Table 1。VBVR-Bench上,本文方法在相近成本下明显优于Pass@N和VideoTPO。
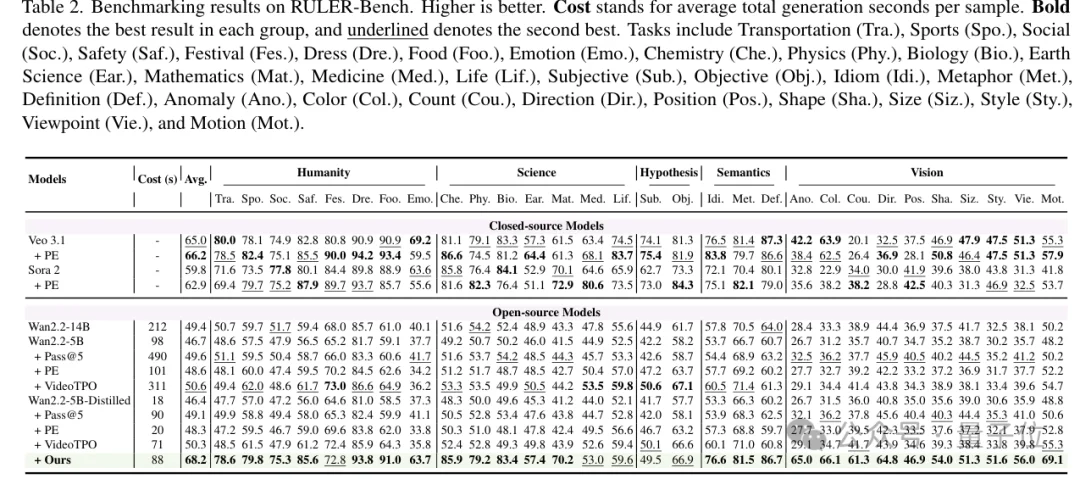
在RULER-Bench上,本文方法从46.4提升到68.2,带来21.8分增益;
相比之下,PE、VideoTPO、Pass@5的提升分别只有1.9、3.9、2.7分。
下图对应论文原文Table 2。RULER-Bench上,本文方法在通用视频推理任务中获得大幅提升。
视觉结果:不只是“看起来合理”,而是过程和结果都对
定性结果进一步说明了差异。
在物体移动和迷宫任务中,竞争方法可能看起来合理,却无法同时满足位置、路径、数量和一致性约束;
本文方法能在保持中间过程合法的同时完成最终目标。
在椅子旋转和手部修复等通用任务上,本文方法也更能同时控制目标变化和背景不变:
椅子旋转角度更准,植物和墙面不乱变;手部异常被逐步修复,最终生成自然五指手。
下图为论文定性结果截图。本文方法在符号任务和通用任务上都更好地同时满足最终目标和过程约束。

更强的老师会带来更强的学生,但框架不依赖单一模型
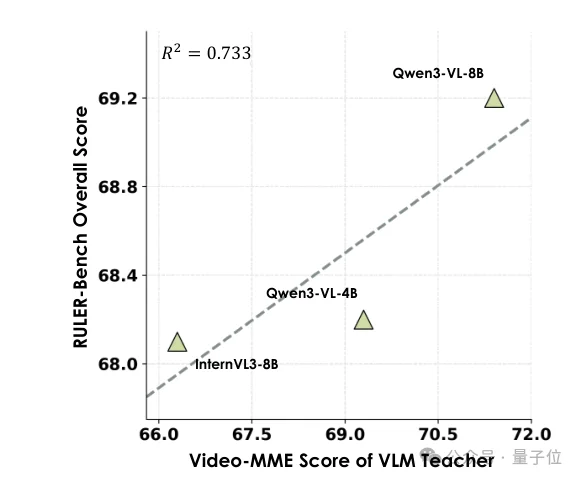
论文还分析了不同VLM Teacher和VGM Backbone的泛化能力。
结果显示,更强的视频理解能力通常对应更有效的监督信号。
作者在RULER-Bench上比较了InternVL3-8B、Qwen3-VL-4B和Qwen3-VL-8B等Teacher,并观察到Teacher的VideoMME分数与最终性能存在正相关。
同时,该方法也能迁移到不同VGM Backbone。
比如在HunyuanVideo-1.5B上,本文方法将RULER-Bench分数从35.8提升到44.5;
在Wan2.2-5B上,从46.4提升到68.2。
这说明VLM-as-Teacher不是绑定某个特定生成模型的技巧,而是更通用的测试时监督框架。
下图表明,VLM Teacher视频理解能力与最终RULER-Bench表现之间呈正相关。
从“先规划、后生成”到“边生成、边被监督”
从更长远的角度看,这项工作给视频生成推理提供了一条新的路线。
过去的很多方法,要么在固定生成器上多采样,要么让VLM先写好文字规划,再交给VGM执行。
前者受限于模型自身能力,后者受限于文字到视觉的执行鸿沟。
VLM-as-Teacher则把问题换了一个角度:不要让VLM直接替VGM解题,而是让VLM提供可优化的反馈信号。
它像一位测试时老师,持续检查“过程是否合规、终点是否达成”,并把检查结果转化为梯度,推动VGM Reasoner针对当前任务进行自适应优化。
这也意味着,视觉生成模型的推理能力不一定只来自更大规模的预训练或更复杂的prompt。
通过在测试时引入高质量的监督信号,模型可以在保持主体冻结的情况下,针对每个任务补上规则执行能力。
项目主页:https://VLM-as-Teacher.github.io/
论文:https://arxiv.org/pdf/2606.02564
文章来自于微信公众号 "量子位",作者 "量子位"
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0

