奇点灵智做了一款支持 Vibe Coding 的儿童硬件。
产品叫多奇 AI 小外教机器人,面向 3-8 岁孩子。今年 1 月在京东首发,首发期间产品进入京东榜单 Top 2,目前全平台订单超过 2 万单。
过去的儿童 AI 硬件,可以聊天,可以讲故事,可以生成图片、音乐和视频,大多停留在 Chatbot 或 AIGC 层面。奇点灵智的团队想往前走一步。通过底层的软硬件解耦,把摄像头、屏幕、按钮、陀螺仪这些硬件器官,变成 AI Coding 可以调用的 tools;不管是家长对于读绘本场景的个性化需求,还是用孩子喜欢的游戏方式练习加减法,多奇机器人的 Coding Agent 能力,都可以实时生成可体验的新应用。
「过去 AI 生成的是内容,现在我们希望它生成能力。」
在团队看来,这种能力不仅来自于底座模型的进化,更来自于团队在儿童垂直场景下的剧本沉淀,以及由此构建的独特 Context Layer(上下文层)的深度积累。

团队创始团队来自网易有道创始班底、字节教育智能硬件,算是互联网创业老兵了。
我们很好奇,这个团队如何理解少儿硬件,如何在 AI 能力快速变化的周期里做硬件。更重要的是,他们如何在工程上克制地收敛 AI 的不确定性,让机器人既能稳稳地守住边界,又能真正「长出新能力」去覆盖长尾需求。
以下是 Founder Park 与奇点灵智创始人兼 CEO 包塔的对话,经编辑整理。
01
软硬倒置,
用做软件的方式做硬件
Founder Park:为什么选择儿童硬件这个赛道?
包塔:我一直喜欢做 AI,从清华人工智能实验室开始,当时导师是朱小燕,师兄是黄民烈,一路都在做 AI 相关的事。之前做有道,后来在美团金融做 CTO,都是在用 AI 解决大规模用户应用落地的问题。23 年过春节以后,我决定离开美团,全心投入到这波大模型浪潮中。
最后回到低幼儿童赛道,是因为这个领域原来没有特别好的产品。它不像 K12 那么卷,但上一代产品很碎片化,故事机、点读笔都像功能机,只能做某一个单点能力。这个市场体量很大,但过去机器没有办法真正和小朋友交互起来。AI 大模型叠加多模态视觉能力之后,让机器有机会真正以「生命体」的形态进入孩子的生活世界。 我觉得这里有一个巨大的供给侧升级机会。
当然还有一个更个人和感性的原因。我小时候身边一直有一个小毛绒玩具,会想象它是活的,可以交流,希望它有一天像机器猫一样什么都能做。后来我自己的孩子也在这个年龄段,我会和他一起编故事。我发现这种互动方式对孩子的表达能力和想象力非常有效。
大模型出现以后,它天然适合小朋友的天马行空。孩子的问题经常很跳脱,但 AI 有耐心,也能接住很多奇怪的想法。所以技术、市场空间和我自己的教育理念,最后在这个方向上合到一起了。
从核心团队每个人的创业经历来讲,因为过往的创业,其实对孩子都是有愧疚的。如果能有一个机器猫把原来没做好的事情弥补一下,加上这帮清华爸爸们有这个技术能力,也蛮好。
倒不是很理性推导出要冲着某个人群去做,根上还是我们自己的成长经历:兴趣驱动使得我们变成今天的自己。我们希望让新一代 AI 的能力,能把兴趣驱动这个事给下一代做得更好。
Founder Park:从 2023 年开始做,到今年年初正式销售,中间都在做什么?
包塔:我们不是躲在屋里把硬件做完再面向用户,而是从 23 年租下办公室第一周就开始测试。
大部分硬件创业的挑战是,等你做完硬件,开模之后钱已经花了,才发现方向不对,那就很危险。我们自己研究了一个方法,叫「软硬倒置的多目标解耦验证」,把「外观结构设计」和「核心交互逻辑验证」这两件事完全拆开。
在 24 年春节前,我们手工缝制了一批「草稿版」原型机:买来市面上普通的毛绒玩具熊,把肚子掏空,塞进摄像头骨架、麦克风和屏幕,把 Mini PC 缝在背包上,导线从熊的脊椎穿过去,代码直接在 PC 端跑。 孩子们面对这只长相甚至略显丑陋的原型熊,依然能在整个春节假期里每天狂玩 1 个多小时,我们才在 2024 年秋天笃定地启动工厂正式开模。

这意味着,我们在没有花一分钱去工厂开模的前提下,提前 10 个月拿到了最真实的用户留存信号和交互反馈。所以我们真正进场比一些同时开始的团队晚。但我们先用这套方法,把很多错的东西去掉了。
Founder Park:像软件产品的小版本迭代。
包塔:对。我们以前都是做软件产品的,就想能不能把软件的一些方法搬到硬件里。
硬件产品常说众筹,但我们更像众创。用户从最开始就在产品里。不是躲起来想一个 APP,发布之后静等下载结果,才发现自己错了。对硬件来说,那样成本太高。
Founder Park:这一年你们主要试出了什么?
包塔:最核心是让小朋友真的能持续玩。让小朋友一次性玩得嗨很容易,但让他持续玩很难。
最早的硬件假设,就是围绕「能不能长期互动」倒推出来的。孩子需要摄像头、屏幕、按钮、道具,需要能在桌面空间里玩。后来到了今天,AI coding 能生成更多功能,反而把这些硬件能力更充分用起来。
还有一个关键是收敛方向。我们一开始是通用能力设计,但从 2024 年春天到夏天一直在做方向收敛。
孩子只要你陪他玩,他都开心。但妈妈不买单,孩子再喜欢也没用。我们测试过数学、语文、百科等方向,最后发现中国妈妈的痛点排序大概是:英语大于数学,大于语文,大于百科。
数学她觉得现有 APP 学起来挺不错;语文和百科她觉得可以用其他内容解决。但英语开口是更痛的点。所以我们把它收敛成:用游戏化方式让孩子英语开口。
英语开口是妈妈想要的,游戏化方式是孩子想要的。
Founder Park:从有样机到量产,中间是怎么逐步验证 PMF 的?
包塔:从 2025 年 1 月开始,我们一共做了 7 个 Alpha 版本。基本上每个月一个 Alpha,每次让用户拿回家三周,再回来一周复盘改进,所以我们有 7 组对照。
为什么是三周?因为当时内容还没完全做完,时间再长就穿帮了,孩子会把内容玩完。但三周已经足够验证一件事:我们能不能跨过过去两年很多 AI 玩具的「7 天斩杀线」。很多产品孩子玩几天就吃灰,我们必须先确认自己能撑过三周,才敢量产。
7 组 Alpha 之后,我们又做了 Beta 1 和 Beta 2,到秋天才进入量产。工厂会觉得我们 24 年秋立项,一年后才量产,真是「赶了个晚集」,很多同期团队的产品更早上市了。但我们因为先拿到了正向信号,倒也不慌,觉得足够 ready 才往外推。
02
只有语音交互不够,
少儿硬件必须进入实体空间
Founder Park:多奇今年 1 月正式发布后,现在的情况怎么样?
包塔:我们大概从 1 月份开始正式销售。这个产品本质上是一个硬件新品类,是用 AI/AGI、大模型去和小朋友陪伴玩乐。一开始挑战很大。因为这是一个新形态,用户需要被教育,也需要真实上手体验。
虽然 1 月份在京东首发时三个家庭机器人相关的榜单都冲到 Top 2,但我们知道这是新品的关注红利,还是要自己下苦功夫。过去一个多季度的时间里,主要在做双轨建设:线上把用户从认知、兴趣到转化的链路铺起来;线下则下沉做更深的体验触点。现在全国 40 多家机场里都能看到这个产品,也进了 230 多家线下体验店。
这个产品一定要被上手体验。如果把它摆在货架上,很多用户第一眼是猜不到 AI 怎么在里面发挥作用的。所以我们甚至为线下场景开发了「卖场模式」,多奇可以自己卖自己,看到客人主动吆喝并展示自己的各项特色能力。一旦让孩子真实玩起来,妈妈很快就理解了,沟通效率会高很多。
目前,我们全平台订单已经超过 2 万单。电商上能看到的用户好评率大概是 99%。
Founder Park:为什么强调一定要体验?
包塔:因为低龄小朋友不是 chatbot 用户。成年人可以坐在那里和 AI 聊天,但 3 到 8 岁的小朋友不太会这样。他们很多时候是具象思维,纯语音对他们来说太抽象,也太累。
我们最早做测试时,很快就否定了纯语音产品。
那时候我们用毛绒熊做了一个原型,里面塞了蓝牙音箱,人躲在隔壁房间,用腾讯会议和变声器跟孩子互动。孩子当时会玩得很嗨,半小时到一小时都没问题。但你问他还想不想继续玩,他说不想,有点太累。原因就是,低龄孩子平常不是用这种方式互动的。声音只占一部分,他更多依赖视觉、实体、操作、动作和反馈。纯语音的多轮对话缺乏物理空间的上下文,对低龄儿童来说很容易变成一种「认知压迫」。
所以我们很早就判断:少儿 AI 硬件不能只靠语音,必须进入实体空间。
Founder Park:这个判断是怎么影响产品形态的?
包塔:它彻底倒逼了我们对底层硬件和芯片平台的架构设计。比如小朋友需要看到屏幕上的反馈,需要把道具放在桌面上,需要用按钮做选择,需要让机器人看见绘本、玩具、积木。过家家、读绘本、陪伴他一起做事情,对低龄儿童非常有效。小朋友和机器人玩得越多,反而越愿意和它聊天,机器人会慢慢变成他的朋友。
很多人看 AI 硬件,会先问模型能力。但在少儿场景里,模型不是全部。孩子不会因为你模型参数更大,就多陪你玩半小时。他要的是一个能一起玩的对象。
这也是我们为什么没有只做一个 App。对于具象思维优先的低龄孩子来说,硬件不是可有可无的壳,而是建立情感链接的实体。他会抱着多奇睡觉,会带它去超市,会让它胸口的摄像头看外面的世界。如果只是一个 Pad,孩子不会抱着 Pad 睡觉。
从可迭代角度来看,如果不为硬件底座的算力和控制权留足战略冗余,你的硬件就只是一具冰冷的「功能机死体」,根本不具备支撑操作系统持续进化的可能,端侧连最起码的视觉算法都跑不动。
多奇配备了两个摄像头,就像长了一双能「看见」物理桌面的眼睛。孩子不需要凭空去迎合机器,他只需把家里的实体玩具或绘本随手摆在桌上,进入他本能喜欢的「过家家」状态。多奇在孩子开口前就能看懂场景,并主动、平等地融入孩子的游戏世界发起对话,把单向枯燥的说话练习,变成了手脑并用的沉浸式互动。
Founder Park:感觉少儿场景是一个很高难度的 AI 硬件验证场。
包塔:对。少儿场景不是 AI 硬件的低配场景,反而很复杂。
它有几个硬性要求:第一,孩子必须愿意持续玩;第二,妈妈必须相信它有用;第三,它要安全、可控、适合低龄表达;第四,它还要能在家庭真实环境里处理各种边缘情况。
这不是「做一个可爱的壳,里面接一个大模型」就能解决的事情。你必须真的理解小朋友怎么玩,也理解妈妈怎么决策。1000 块钱以上的儿童产品,决策者往往是妈妈。1000 块钱以下,爸爸可能顺手就买了;妈妈会非常理性,会货比三家,会反复比较。她最后要相信这个东西真的有道理,判断能拿到实打实的有用交付,才会下单。
所以少儿硬件不是只让孩子喜欢就可以。孩子看到的是游戏、绘本、角色扮演;妈妈看到的是英语开口、学习报告、单词熟练度。
这也是儿童产品和普通消费硬件很不一样的地方。它有两个用户:孩子和妈妈。孩子要玩,妈妈要学。你只满足孩子,妈妈不买单;你只满足妈妈,孩子不玩,很快吃灰。我们必须让机器同时通过这两方的信任投票,两个逻辑必须同时成立。
03
孩子觉得自己在玩,
家长看到的是交付
Founder Park:会怎么向家长介绍你们的产品?
包塔:如果简单一句话表达家长的痛点,就是:孩子光听不说怎么办?多奇 AI 小外教,让他玩着玩着大量开口。
「小外教」这个名字代表最核心的价值:它像一个孩子喜欢的小伙伴,能陪他玩,同时让他愿意开口学英语。但「小」字很重要。如果叫「外教机器人」,家长期待就完全不一样了,可能会要求你做到真正外教一样的交付。
坦白讲,现在 AI 产品还不可能完全替代真人。叫「小外教」更亲切一些,压力没有那么大。它像一个和孩子一起在长大的小机器人,能陪伴、启蒙、激发开口。
外教既是价值对标,也是价格对标。最便宜的线上外教一年也要几千到上万,北京线下一堂真人外教课可能要 300 块。几节外教课换来三到五年全天候的陪伴。绘本也能读,单词也能学,也能和孩子进行双语对话聊天,如果后面加入新的 AI 能力,还能做一点生活习惯管理,比如打卡、提醒、任务记录,变成住家小老师的一部分。
但我们一直很克制,没有把它定义成什么都能做的启蒙机器人。大模型确实有通用能力,但用户不会为模糊的「通用」买单。如果你说我什么都能做,家长会拿你和每一个垂直领域的成熟解决方案比较,结果就是你好像什么都能做,但什么都不深。
所以还是要先扎到英语这个头号刚需里,把它做深,产品体验做到足够差异化。进到家庭以后,用户发现它还有更多能力,再逐步扩展。这既是用户需求分析的结论,也是我们自己产品战略仔细思考后的路径。
Founder Park:怎么证明孩子真的在学?怎么验证结果?
包塔:最容易感知的是开口。孩子以前不愿意说英语,用了一两周以后,开始说 3 到 4 个词的短语,或者小句子的频率明显变多,这对家长是非常外化的。
我们也会给家长提供孩子的学情报告。不是简单说孩子今天玩了多久,而是今天开口多少次、说了哪些英文词、每个词熟练度怎么样。根据孩子英语水平定级,而在不同场景中学习到不同的新词,比如 avocado(牛油果),最开始说得不准可能是一星,后面越来越熟练,慢慢到七星。
这个很像教育产品给妈妈的安全感。孩子觉得自己在玩,妈妈需要看到的是交付。

Founder Park:学和玩之间会不会矛盾?
包塔:K12 阶段可能会矛盾,因为核心目标是应试体系下的分数,多玩一小时就少复习一小时。但学龄前不一样,启蒙阶段大量学习本来就是在玩中发生的。
孩子学中文不是从认字开始的,而是在过家家、出去玩、和大人交流中慢慢学会的。英语启蒙也可以这样,我们很认可的一个教育理论是 Interest Based Learning,只要他对某个东西感兴趣,你就能把词汇、句子、表达自然地揉进去。
当然,每个家长都会有自己的焦虑。所以我们也给家长很多「控制杆」,比如绘本阅读可以选择自适应双语讲解、只读原文、全英挑战模式。理想情况下多奇会像 AI 一样自动驾驶,但如果妈妈一定要自己掌控节奏和方向,也要给她方向盘。
有的产品经理可能会说,家长这种方案不科学,应该跟着我们的教学理念来。但妈妈不买单也没用。她会说,我的孩子我知道。你要理解她的焦虑,把选择权给她。
Founder Park:你们怎么把游戏和学习融合在一起的?
包塔:这方面我们确实做过非常多的尝试,也踩过很多坑。我们曾经做过一个「小熊餐厅」的纯游戏玩法,孩子能站在实验室里玩将近两个小时,但妈妈并不高兴,她觉得孩子今天只是在玩游戏浪费时间。
后来我们把它改成:你想过关,就要大声说出英文单词。比如你要做菜,切牛排就要喊出牛排的英文单词 steak。孩子视角里,我是在为了好玩在过关;妈妈视角里,她真实地听到孩子在持续高频地开口说英语。这才是游戏和学习的交集。
这类细节在多奇里还有很多,我们不想把 AI 做成一个被动等指令的聊天框。AI 的能力是被我们完全消化了,直接嵌在孩子日常玩耍的每个环节里的。只有把技术完全藏在后面,这才是 AI 原生硬件该有的样子。
04
绘本阅读是一个复杂的硬件工程问题
Founder Park:你们是怎么拿下绘本阅读这个场景的?
包塔:绘本阅读是小朋友在家里最核心的场景之一。我们一开始就研究了小朋友在家里最核心的那些场景——读绘本、玩玩具、画画、过家家,大概 5 到 8 类,占他时间很长。绘本是一大类,我们很早就想做。但 24 年秋天尝试过用 GPT-4V 跑 Demo,速度太慢、价格太贵,在工程上根本搞不定。
所以当时我们就先做了画册,在基座能力还做不到绘本阅读时,用自有内容完成了用户场景闭环。画册上面的角标都是预置的,用的是传统视觉模型,不是多模态。我们相信技术未来的发展,但当时做不到,就用更简单的方式先解决它。
后来基座模型能力上来,我们重新尝试,发现它可以满足需求了。多奇可以读有文字的绘本,也可以读只有图没有文字的绘本。它会结合书名、图片和上下文,把故事讲出来。这对家长的价值很直接:很多妈妈英文能力和表达不够自信,有了机器人,她就不用自己硬着头皮编故事、读绘本了。
而且这个市场不用我们重新教育,上一代产品已经让妈妈理解并相信「读绘本」的必要性,我们要做的是给她们提供一个互动更自然、孩子更愿意玩下去的体验升级版。
Founder Park:看起来就是识别一页图,然后读出来,实际难点在哪里?
包塔:真正放到小朋友场景里,非常不容易。
比如孩子把书放歪了、放反了、横过来、压住一角,或者翻页翻到一半,手还压在上面。这些都需要判断。
你还要给 3 岁、4 岁的小朋友一个听得懂的反馈。不能说「图像识别失败」,要说「请把绘本放到我前面」「让我先看看封面」。所以我们做了大量小模型:书本摆放检测、翻页检测、页面稳定判断、取哪个画面、什么时候该提醒孩子。这些不是一个技术 demo 能解决的。
从技术可行性到产品化,中间路特别远。很多创业者有一个 demo,就会觉得能扫出来,能认出来。但真正到家庭里,根本不是那么回事。孩子会把碗压在书上,会侧着玩,会把书放在沙发上,corner case 非常多。
用户最后觉得「好像本来就该这样」,但背后研发要思考和处理的工作很多。
Founder Park:你们是本地模型和云端模型结合?
包塔:对。本地有一个 AIoT 芯片,算力约 1T。像翻页检测、位置判断这种需要毫秒级快速反馈的事情,很多在本地做。内容理解、故事生成、英语表达,就调用云端去解决智商上限的问题。
如果全部等云端传回,体验会很慢。尤其游戏和绘本里,孩子的动作很快,动作发出了却得不到即时响应,耐心两分钟就消磨光了。
这也是硬件冗余的价值。当我有本地小模型时,它不只帮助游戏响应,也帮助这些日常交互判断。什么事本地做,什么事云端做,这个架构分层是 AI 硬件产品化的关键。
Founder Park:你们自己的内容包和开放绘本之间是什么关系?
包塔:最早基座能力不够时,我们用自有图册和道具完成闭环。那套内容相当于冷启动:孩子什么都不用想,翻开就能玩。它可以保证体验稳定,也能让孩子很快进入状态。
但当模型能力越来越强,机器人就应该像人一样,能基于孩子家里已有的东西来玩:书、玩具、积木、绘本、纸笔。这才是未来机器人真正的形态。它不应该只消耗我们预制的内容,而应该能理解家庭真实环境里的内容。
我们图册大概一个季度更新一次,后面也计划做主题分册,比如太空主题、城市主题、世界地图、数理场景等。有了 AI 能力后,图像生产成本下降;今年 coding 能力又让后台互动生产提速了。
如果家长连册子都不想等,希望在机器人上直接定制一个交互,那就可以用 AI coding 的方式现场生成。但实体图册和道具仍然有价值,因为低龄孩子需要 context,需要看得见摸得着的东西。家长也更容易理解实体内容包。
Founder Park:绘本和游戏,哪个对产品带动更大?
包塔:两个都是 Top 级功能。孩子自己玩的时候,游戏感更强;妈妈会更看重绘本,因为她觉得有了它,孩子会比以前更爱读绘本。
妈妈的逻辑是,绘本这个事我原本就知道重要,但我没时间、英文能力也未必够好。如果多奇能帮我读,还能互动、问答、加入英语,那她就很容易理解价值。
游戏则需要被翻译成学习交付。如果只是游戏,妈妈会担心孩子是不是在玩。但如果过关需要孩子大声说出英文单词,妈妈就会觉得这不是单纯游戏,而是把英语开口嵌进了游戏。
这就是儿童产品的微妙之处:孩子看到的是乐趣,妈妈看到的是交付。
05
生成能力比生成内容更重要
Founder Park:为什么今年会把 AI Coding 能力放进儿童机器人里?
包塔:一方面是技术窗口到了,整个行业从单纯的 Chat 走向了 Agentic OS 的能力自动编排;但更核心的,是我们看到了少儿场景里的客观事实:启蒙教育和陪伴,天然是一个极度碎片化的长尾市场。
目前的用户反馈里我们发现,新需求的涌现速度,永远快于团队排期发版的更新节奏。每个家庭的教育诉求都不完全一样:有的妈妈希望读完绘本后能自动问三个问题,有的家长希望练加减法,有的孩子迷恋恐龙,有的孩子只爱太空。
如果按照传统的开发范式——产品经理提需求、写死代码(Hardcoding)、再走长达数周的固件发版,团队会直接陷入排期的死胡同,被无边无际的长尾需求拖垮。
所以,我们必须换一种解法。我们不让 AI 只是停留在帮孩子生成故事或者图片,让 AI 针对每个家庭的个性化场景,现场实时写代码,直接生成可运行的轻应用。以前我们现场只能生成内容,但不能稳定生成能力。现在不一样了。比如孩子现在想玩恐龙积木,同时学几个水果相关的英文单词。过去你得提前在后台写死这个特定功能,现在我们希望机器人能根据此时此地的场景,几分钟内现场实时生成一个能力,而不只是给你放一段新内容。
Founder Park:那你们现在的 Agentic OS 具体是怎么跑的?
包塔:我们在软件底座上做了一个面向儿童的 Agentic OS,叫多奇 OS(Duoki OS)。它做了比较强的面向小朋友场景的封装,下半球是硬件和大模型 AI 能力接口,上半球里有两个核心 Agent:一个是教育专家 Agent,负责解决妈妈的问题;一个是伙伴 Agent 专门陪小朋友玩的,两个共同决定和小朋友的互动方式。
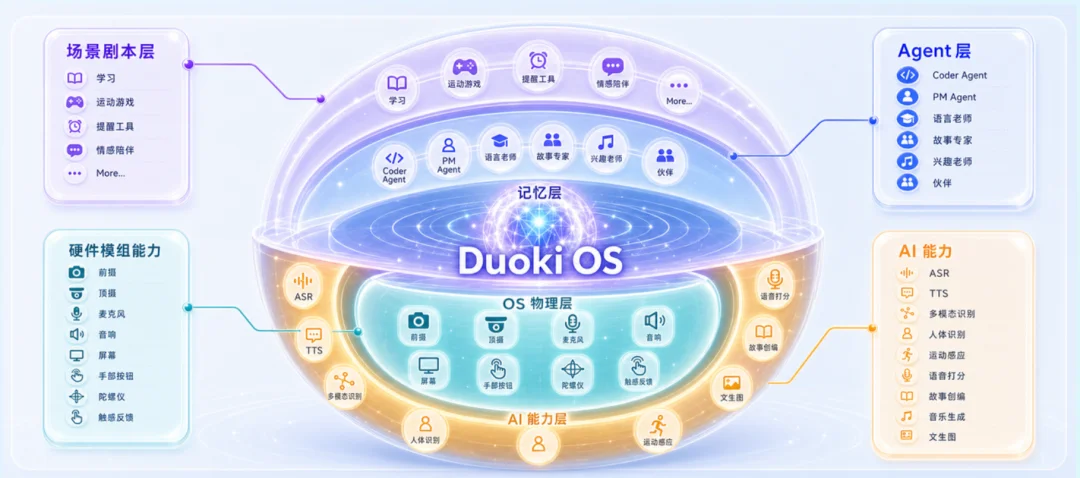
外面还有辅助的 Agent:PM Agent、Coding Agent、语言老师、兴趣老师等。去年的很多产品是把语言、兴趣这些作为孩子教学对象的 Agent。我们今年加了两个比较特别的,PM Agent 和 Coding Agent。这两个不是服务小朋友的,是对妈妈的。它在跟妈妈做互动,来理解妈妈想让这个机器人做什么事情。
最外层是场景剧本,这一套东西是长期可积累的部分,相当于在不同场景下用什么样的交互方式和编排来跟小朋友玩。我们把孩子日常学习、运动游戏、情感陪伴、生活习惯管理等各种常见场景的规则都做了抽取和沉淀,来确保做出来的大概率是小朋友喜欢玩的,同时还要思考怎么把家长希望的东西揉进去,互动方式适合这个年龄的孩子……等等,这些是从开始到现在两年 know-how 的沉淀。
Founder Park:但普通妈妈不是产品经理,也不懂 coding。
包塔:所以我们不会让她直接做 coding。很多妈妈说不清楚产品逻辑,她只能说出痛点:我想让孩子练 10 以内加减法,我想读完绘本后问孩子几个问题,我想把一个游戏换成像素风。
这个时候我们的 PM Agent 就是一个产品经理,会反问、拆解、给选项。
比如妈妈说:我家孩子最近正在学 10 以内加减法,但他很坐不住,能不能编一个他能玩进去的游戏?
多奇会给三个玩法:实时挑战、小小收银员、救援小队。家长只需要选一个。
如果她选实时挑战,又说孩子喜欢太空主题,Coding Agent 就会在几分钟内现场写出全套连接代码、调取本地音频与 UI 资源,直接在云端的独立隔离沙盒中编译并部署出一个全新的轻应用:孩子听到一道加减法题,说出答案或者按左右键选择,答对飞船就发出子弹击碎陨石。
如果家长觉得节奏太快,还可以继续用自然语言输入「魔改」指令:「让背景的星星动起来」。传统的软硬件功能开发需要两周,现在变成了妈妈和 AI 之间一两分钟的对话。
Founder Park:所以你们不是让用户学会 vibe coding?
包塔:不是。我们把用户创作分成四层。
第一层是我们预制好的内容和应用,像预制菜。
第二层是轻量修改,比如把单词消消乐改成像素风,把视觉主题换成孩子喜欢的风格。
第三层是家长或教育达人提出一个教学想法,由 PM Agent 转译并和 Coding Agent 配合编写成应用。
第四层是全自动:用户什么都不用做,多奇根据白天对孩子的观察,在夜里反思,第二天自动生成更适合他的内容。
我们确实用了 AI coding 的能力,但用户感知不到 coding,用户只是在点菜。
Founder Park:夜间反思具体是什么?
包塔:我们希望它不是只在小朋友主动使用时才工作。白天,它陪小朋友读绘本、玩游戏、做口语练习,过程中会感知孩子喜欢什么主题、哪些词汇掌握得好、哪些地方容易卡住。
到了晚上,孩子睡觉以后,机器人可以把白天的记录重新拿出来做反思。比如它发现孩子今天读了恐龙绘本,对恐龙很感兴趣,但几个英文词一直没有说好。它就可以在夜里规划一个新的小应用,第二天早上给孩子生成一个「营救小恐龙」的任务,把那几个词重新揉进去。

这和刚才家长点菜不一样。家长点菜是人提出需求,机器人拆解和生成;夜间反思更接近全自动,它自己根据上下文判断孩子需要什么,再生成新的东西。
这里面还有一个时间差。现场生成一个应用,等一分钟小朋友可能会着急。但如果放到夜里,孩子本来就在睡觉,第二天早上妈妈看到「多奇给孩子准备了一个新任务」,反而会觉得很自然。
我们不是只把白天的交互时间利用起来,而是把白天、夜晚、清晨都串起来。白天陪玩,晚上反思,早上给出新东西。它从一个开箱即用的 AI 小陪教,变成一个 24 小时持续自我进化的机器人。
Founder Park:这种「生成能力」会怎么改变现有的用户体验?
包塔:以前孩子可能只是孤立地读一本绘本。现在我们想把它串成一条完整的闭环链路。
首先,孩子读绘本时,机器人在旁边理解他喜欢的主题、出现了哪些词汇、哪些词孩子说得好、哪些词没说出来。读完以后,它可以围绕这些词和孩子对话,把词汇放进新的语境里。
同时,在对话发生的时候,后台其实已经实时生成了一个小游戏。比如孩子读了月球探险主题绘本,又对某几个单词不熟,机器人就可以生成一个飞行月球主题的小游戏,把火箭、月球这些词揉进去。孩子感觉是在继续玩登月飞船的故事,妈妈看到的是孩子在复习词汇。最后,机器人还会把学习情况反馈给家长。这样就从单纯的「读一本绘本」,变成了「阅读—理解—对话—游戏巩固—家长反馈」的整条链路。
这就是 AI Coding 对我们真正的价值。它不是让用户看到代码,而是让原来割裂的功能串起来,让机器人可以围绕一个孩子当下的兴趣和短板,现场生成新的交互。
这也是我们说「能力生成」比「内容生成」更重要的原因。内容生成只是给你讲一个新故事,但能力生成是说,我知道你现在需要一个「看书打卡」或者「读完问三个问题」的流程,系统就能把这个由代码驱动的流程现场做出来。对家庭来说,他们感受到的是机器人越来越懂我家孩子,而不是某个功能又发了一个版本。
这不是为了展示 AI Coding,而是为了让产品跟上家庭的长尾需求,彻底打破传统智能硬件「开箱即巅峰、越用越过时」的宿命,让机器人变成一个真正越用越懂你、越用越聪明的自进化智能体。
06
把硬件器官做成 AI 可以调用的外挂 Tools
Founder Park:你们做硬件的时候有为后来这些 Agent 能力预埋东西吗?
包塔:我们当时最核心的思考是,怎么做一款能和小朋友长期互动的硬件产品,并以此倒推它应该具有什么样的器件。比如在屏幕这个考虑上,很多小朋友原来的设备是没有屏幕的,但有两个问题要回答:家长会觉得有屏幕是不是伤眼睛?没有屏幕的话能不能让小朋友很好地交互?
我们做了非常多的思考和实验,最后很明确:有屏幕以后交互能力上升非常多。特别是低龄小朋友,如果没有屏幕,很多时候你要给它一个概念,或者 AI Coding 里的很多东西,没有屏幕根本没法做。
屏幕相当于是多奇的表达器官和白板。多奇现在还没有手可以指指画画,如果只靠语音嘴巴是不够的,有了屏幕,很多 AI Coding 现场实时生成的轻交互才能跑得通。这是一个非常关键的判断。

其实这很像任天堂 Switch 的那种软硬件解耦逻辑。Switch 之所以能做出《健身环大冒险》这样的专属体感游戏,并不是因为任天堂出厂时就预置了健身功能,而是因为他们把 Joy-Con 的陀螺仪、红外动作相机、实体按键等硬件原子能力,做到了极其彻底的模块化拆解。这就是一个顶级的垂直深度打样,证明了底层的原子能力只要拆得足够彻底,在长尾和跨界场景下就能被重新编排成任何东西。
Founder Park:那伤眼睛的问题怎么解决的?
包塔:关键在于产品的定义和交互距离。多奇的正常场景是在实体桌面空间里,比如玩玩具、读绘本、画画。屏幕不是让孩子一直去戳戳点点的设备,它只是一个辅助表达。小朋友的大部分注意力其实都在实体桌面上。
我们在去年做入户调研时发现,家长往往会拿它去类比手机和 Pad,孩子拿手机会越看越近。但多奇是坐在孩子对面,小朋友和它一块看桌上的东西,彼此间隔大约有 40 到 50 厘米远,这在物理上就拉开了安全距离。
Founder Park:摄像头为什么是两个?
包塔:我们在所有硬件选择上都做了一定的冗余和储备。比如头部的摄像头,底线是能看清桌面印刷品上的仿宋体 5 号字,这其实提前储备了未来的作业学习场景。后来我们在胸口又开了一个摄像头,是为了能看到孩子所在的环境和表情,自然也就预埋了未来的视频通话能力。双摄各司其职:一个看内容,一个看人的动作,这在 2023 年 10 月份就定下来了。
Founder Park:手上的按钮呢?
包塔:左右手掌心的确认按钮,也是提前预埋的,类似于游戏机的确认键。刚开始做纯英语内容时,这个按钮还没有被彻底用好;现在到了 AI Coding 这一代新的动态场景里,这两个物理确认键变得非常有用。
Founder Park:这些器官在 Coding 的时候怎么被调用的?
包塔:传统智能硬件在开箱时,硬件和固件是一套写死的嵌入式系统,功能出厂即固化。但多奇 OS 允许把所有硬件模组像打通 API 一样全面解耦开放。
我们把每一个模组的能力封装起来,交给云端的 AI :如果你能用到身体里的 8 个模组,你会怎么调用它?AI 就可以根据当前的场景,自己去自主判断。当要做一件事时,它自己决定什么时候需要摄像头去追踪卡片、什么时候需要陀螺仪把机器人本身变成方向盘、什么时候让屏幕去表达。它不再是出厂时死板的应用,玩法就变得非常灵活了。
Founder Park:外观为什么不是一个标准机器人,而是现在这种形态?
包塔:外观首先要承载硬件,这是硬条件。双摄、屏幕、按钮、传感器都要放进去,不能只从可爱出发。其次,3-8 岁孩子需要它有亲和力,但父母又希望它有科技感,不能只是一个容易弄脏、不好打理的毛绒玩具。所以我们选了目前这种外观,并做了表面特殊工艺处理,保持一种微弱的皮肤触感。
我们也试过小熊猫等各种动物形象,但具体动物的颜色和设定天然会被限制。最后我们通过和小朋友投票测试,把它抽象成一个大耳朵的小精灵。有些孩子觉得像兔子,有些觉得像羊,我们不会把它锁死定义成某一种动物。因为要考虑更多长尾场景下的适配性。如果它被定义成兔子,在动物园门口介绍别的动物,逻辑上反而会有点奇怪。抽象一点,它才更像一个无界面的陪伴角色。
07
儿童市场很大,
现阶段还谈不上竞争
Founder Park:现阶段真正的竞品是谁?
包塔:很难说有一个硬件产品和我们完全一样。它又是英语,又有屏幕,又有实体互动,又有过家家道具,又有绘本阅读。真正的竞争不是某一个特定的 AI 新硬件,而是妈妈历史上的传统选项。
低龄妈妈过去熟悉的是点读笔、故事机、熏听机、绘本课;大龄孩子家长熟悉的是学习机。我们要切的是她原来的认知和习惯:她为什么要把孩子的时间交给你,为什么相信你比原来的解决方案更有效。
AI 陪伴硬件整体还很早期。现在所有玩家加起来的货量,放在 3 到 8 岁这个巨大的少儿人口大盘里,渗透率连 1% 都不到。所以这个阶段与其说是互相竞争,不如说是一起教育市场。
Founder Park:做儿童 AI 硬件,你们觉得壁垒在哪里?
包塔:仅从这次讲的自进化能力来看,我觉得有两个核心。
第一是长期记忆,就是多奇和小朋友长期交流之后沉淀下来的上下文数据,它更了解这个孩子,才能更容易和他高频互动;第二是场景剧本,也就是在真实家庭场景下怎样持续交互,既满足孩子好玩,又满足父母的教育和习惯培养诉求。
这些剧本里沉淀的是我们过去两年踩过的坑。比如怎么和小朋友读一本书,什么时候纠正,什么时候不纠正,什么时候让他选择,什么时候给他正反馈。这些 Know-how 不是基座模型能力提升就自动带来的,必须长期扎在用户场景里去磨。过去这些东西是我们自己闭门沉淀,速度还不够快。现在有了多奇 OS 下的 PM Agent 和技能市场,再引入用户和达人参与,整个场景剧本的沉淀速度会呈指数级加快。
纯看算法参数,大模型懂万物,但它们天然缺乏特定场景里的 Context Layer,它们不可能天然地知道一个中国三岁半的孩子,在桌面玩游戏时的真实意图、品味倾向和高频错误打标是什么。
多奇真正的差异化,来自于我们团队过去两年来在真实家庭环境里,高频做交互验证所沉淀下来的「场景剧本层」。从 2024 年我们用最粗糙的原型小熊做入户测试、再到去年每个月的「三周漂流计划」,这种深入真实家庭环境、做高频数据清洗和打标的过程,已经成为我们产研迭代中自洽闭环的肌肉记忆。
Founder Park:所以这本质上是一个数据飞轮?
包塔:可以说是能力飞轮和数据飞轮的结合。长期记忆更像数据飞轮,场景剧本更像能力飞轮。
用户和多奇相处得越久,这个私有的上下文层就越厚,模型也就越容易理解并现场生成出孩子喜欢、家长买单的轻应用。这种高壁垒的物理空间交互数据,大厂的广告分发引擎和手机操作系统是没有物理入口去高频采集的。把对场景和用户的理解持续滚动并转化为产品优势,这就是我们对壁垒的思考。
Founder Park:AI 的幻觉问题很严重,儿童场景上,你们是怎么做 harness,保证内容产出安全的?
包塔:坦率地讲,在软件和 AI 工程里,没有人敢轻言百分之百的安全,但少儿产品的特殊性决定了你必须把边界控制做到极致。
所以我们在多奇 OS 的底层,设计了一套严密的 Harness(安全约束框架)。我们利用了 AI coding 的能力,但我们对它现场能生成的程序权限,做了极大的克制和收敛。
例如,我们在系统里做了一套「技能定义规范」。每一个长尾场景(比如打卡、算术、故事游戏),对模型来说都不是一段天马行空的自由发挥,而是一本结构高度规范的说明书。主 Agent 去阅读这本说明书,明确自己能调用哪些硬件工具、只能在哪些边界内发挥智能。如果用户的诉求超出了这套规范的约束,系统会诚实地拒绝执行。
再比如夜间反思生成的新能力,在清晨推送到机器人之前,必须先在家长端的小程序报告里亮起。由妈妈一键点击确认后,沙盒里的新应用才会被真正激活。我们没有简单地把大模型接口直接裸露出来,而是把模型所有的不确定性,用代码级的安全网死死卡住。
Founder Park:未来这个产品的最终形态会是什么?
包塔:想象中,它就是小朋友身边的「叮当猫」。
未来它肯定会演进出移动能力,也可能会接入更多丰富的物理外设。但多奇现在先从「不能动」的桌面形态开始,因为小朋友身边一个能动的设备,在物理空间里的安全性要求极高。它会慢慢从小外教,变成一个更全能、更聪明、更会玩的陪伴形态的机器人。
08
技术范式变了,
最好的马车永远变不成汽车
Founder Park:你们目前最大的焦虑是什么?
包塔:不是儿童陪伴这个需求在不在。这个赛道肯定在,中国 3 到 8 岁小朋友有 8000 万到 1 亿,现在整个 AI 儿童硬件渗透还非常早期。
最大的变量还是技术演进的速度。AI 的供给侧变化太快,可能会带来新的形态。你现在很难断定哪一种软硬件组合能长期拥有生命力。
但这也是创业有意思的地方。与其焦虑,不如拥抱。我们要做的是一直站在用户那一侧,等技术浪潮拍过来,把它用到真实需求里。
Founder Park:你们会怎么定义「这件事成了」?
包塔:如果这个新品类在儿童赛道里真正被大规模使用起来,我觉得就算成了。但最终形态不一定就是今天这个样子。
这很像我以前在有道,最开始是从网页搜索起家的,后来率先跑通形成公众认知的是词典,并一步步衍生出了今天的教育和智能硬件生态。它当然算成功,只是换了一种更契合市场的形态。所以对多奇也是一样,只要它最后能服务足够多孩子和家庭,形态可以变化。
Founder Park:如果这件事最后没成,你们觉得原因会是什么?
包塔:痛点肯定一直都在,儿童陪伴、低龄启蒙、父母希望孩子能更好的学习和更快乐的玩。更大的风险是技术带来新的供给形态,如果行业出现了一种更高效、更好的形态,我们没有及时 pivot 过去,那就会有问题。
有点像最好的马车也不是汽车。你可以把马车做到非常好,但如果汽车这个新形态出现,你还在马车的逻辑里优化,就会被打懵。
所以我们内部一直强调「组织本身的 AI Native」。这绝不是表面上让员工用几个 AI 工具,而是整个团队的产研结构要能持续吸收技术变化。只有组织本身是流动的、能变的,当产品形态需要大调头的时候,你才有机会跟上。
这也是为什么我们会关注用户侧和技术侧。用户侧让我们知道真实需求在哪里,技术侧让我们能在供给变化时快速切换。只盯技术会变成自嗨炫技,只盯用户又可能错过技术代际带来的红利。两边都得在。
Founder Park:你们希望外界怎么理解奇点灵智?
包塔:它是一个拥抱 AI 浪潮,但始终扎根用户价值、扎根真实家庭场景的产品团队。
我们希望多奇对小朋友、对中国爸爸妈妈真的有用。哪怕有一天这个团队完成了历史使命,别人回忆起这个产品,会觉得它在 AGI 刚爆发的某个阶段,确实做出过一些有启发性的新东西。
我们对用户的理解,从开卖前怎么做,到量产后怎么做,再到多奇 OS 的迭代怎么做,逻辑是一脉相承的。
如果说过去我们对自己是不是百分百 AI Native 的团队还有一些自我审视和怀疑,今天我会觉得很有底气。多奇是一个能自进化的机器人,而奇点灵智也是一个能自进化的团队。我们做这个产品的方式,和产品本身想表达的东西,开始共振了。
文章来自于微信公众号 "Founder Park",作者 "Founder Park"
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md

