以往模型在SWE-Bench跑80分,实际干活十次通不过三次。榜单与现实的落差,是Agent开发者长期踩的坑。
6月4日,Arena.ai发布Agent Arena排行榜,用373,431次真实会话的数据,给18个主流模型的Agent能力排了个座次。
战力榜首:GPT-5.5 High,前五被OpenAI和Anthropic包揽
先看总榜。Agent Arena的排名依据是“净改进”(Net Improvement),用因果推断方法算出每个模型相对于随机基线的性能提升幅度。正值代表比随机选择更好,负值说明不如随机。
GPT-5.5High以+10.66%的净改进排在第一,Claude Opus 4.7 Thinking紧跟其后,+9.47%。GPT-5.4High排在第三,+8.92%。Claude Opus 4.6第四,+8.14%。GPT-5.5标准版第五,+7.47%。前五全是OpenAI和Anthropic的模型,这两家在Agent能力上的领先优势相当明显。
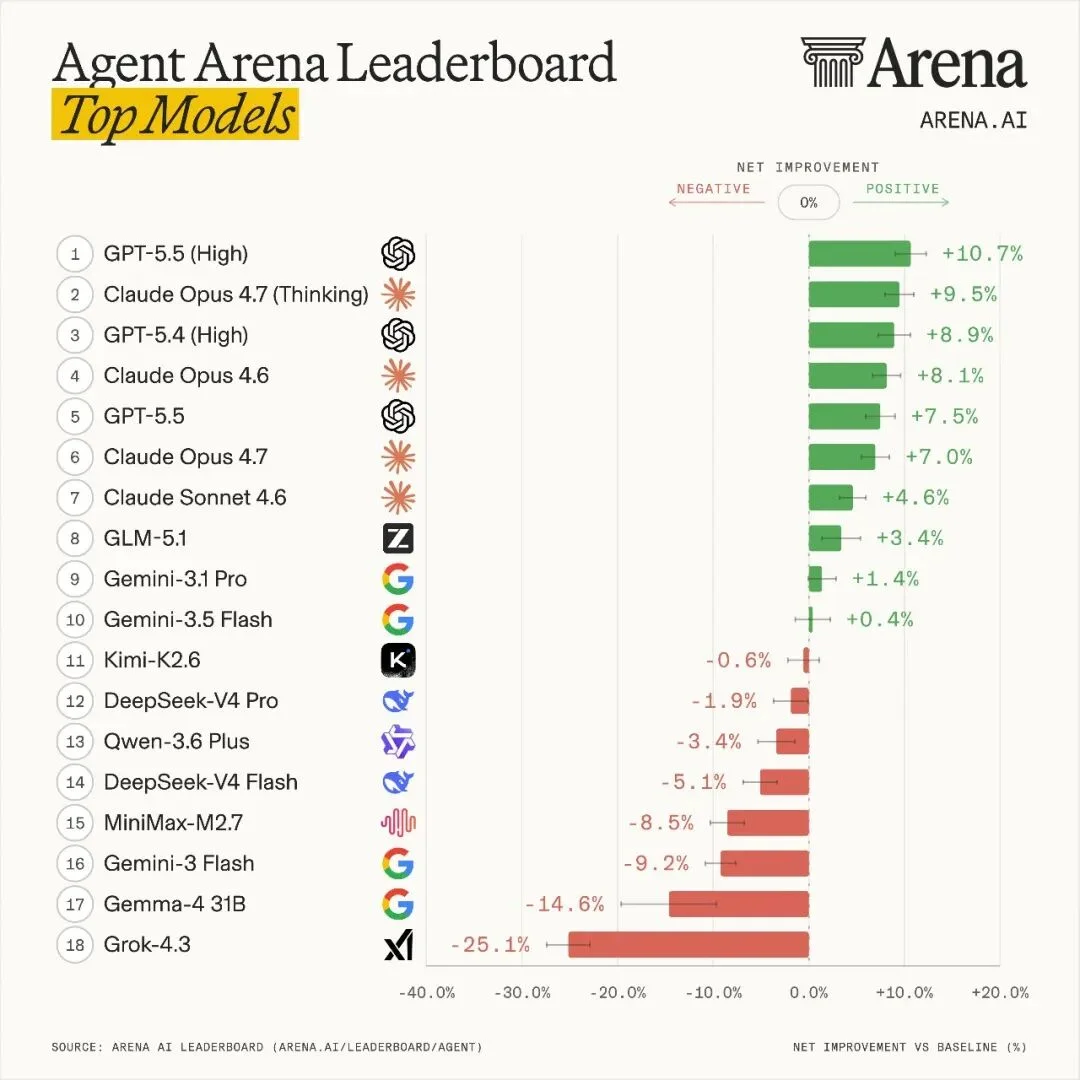
国产模型方面,GLM-5.1(智谱)以+3.38%排在第八,在Bash恢复上表现亮眼,达到10.37%,接近第一梯队的水平。
Kimi K2.6和DeepSeek V4 Pro也在总榜单上,不过在分项指标排名上各有短板。整体看,国产模型在工具稳定性上还有提升空间,但在任务恢复能力上已经不算弱了。
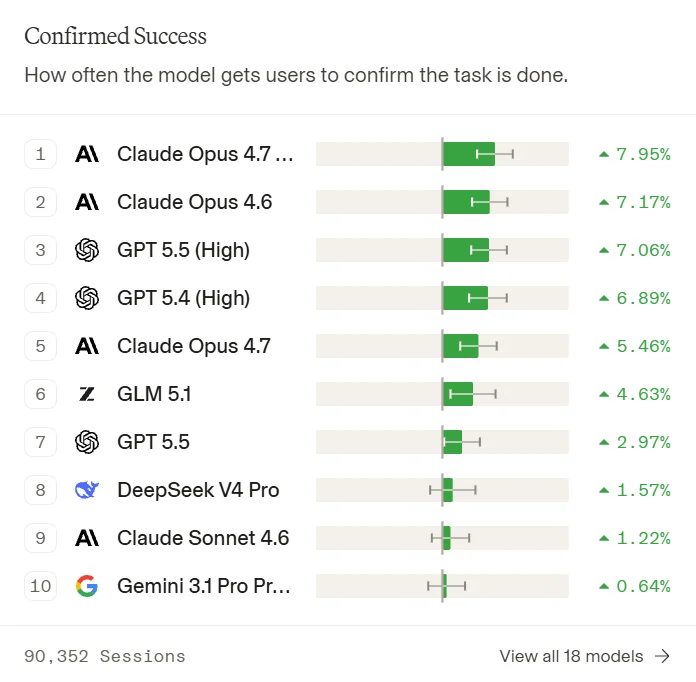
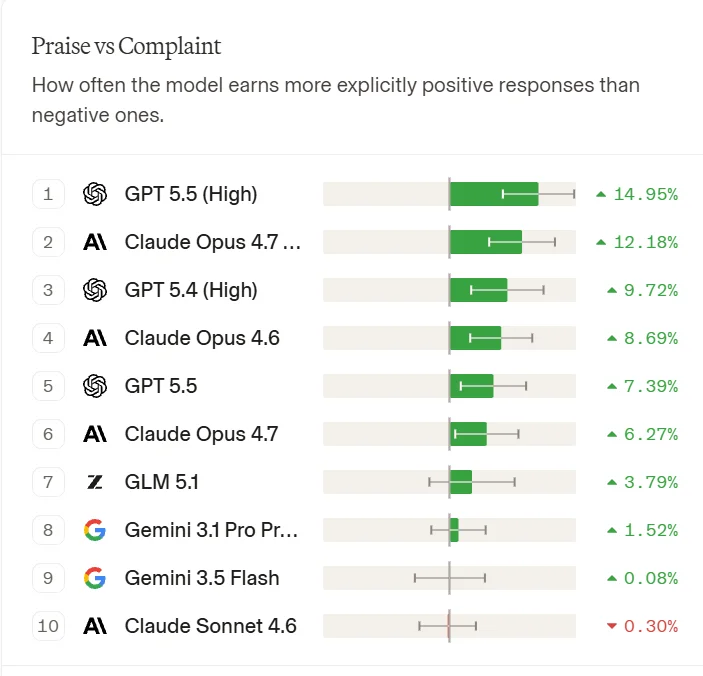
分项指标上的差异比总榜更有意思。Claude Opus 4.7 Thinking在“确认成功”上的净改进达到7.95%,是所有模型里最高的,说明它在把任务真正做完这件事上最稳。GPT-5.5 High在“表扬与抱怨”上的净改进以14.95%大幅领先,比Opus 4.7 Thinking的12.18%高出一截。
Agent Arena:让模型离开考场,回到真实世界
传统基准(SWE-Bench、MMLU等)测的是标准化题目,一次问答、一次打分。
但到了实际工作中,Agent要面对多轮交互、工具调用失败、shell报错、用户中途改需求等不同任务,传统基准覆盖不了这些维度,分数自然也说明不了什么。
Agent Arena的做法不同。它没有预设题目,而是记录真实用户在平台上使用Agent干活的完整会话。每次会话包含多轮,用户在过程中可以批准、纠正、表达不满,Agent则要应对shell报错、工具调用失败等真实环境反馈。
一个会话记录的不只是最终结果,还有每一轮的工具调用链、bash命令的退出码以及用户对结果的现实评价。
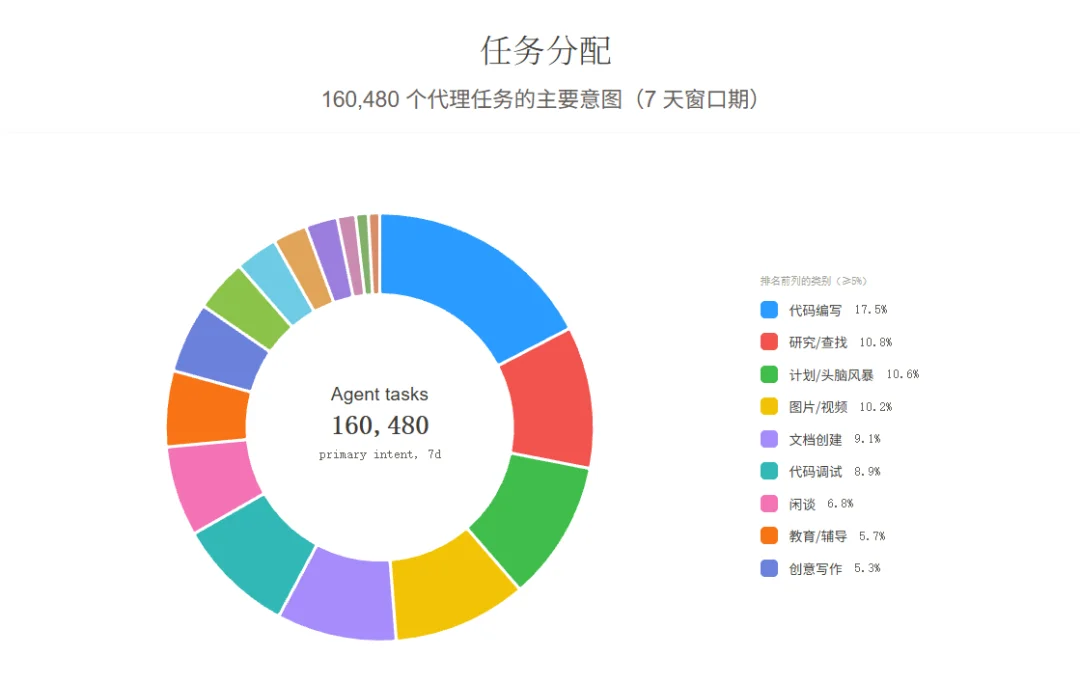
这次Agent Arena排行榜,共记录了373,431次会话,有18个模型参与评估。仅最近一周就记录了160,480个任务、206万次工具调用,Agent生成的代码共4,030万行。任务类型覆盖了开发者日常的绝大部分场景,代码编写占17.5%、研究查找占10.8%、规划头脑风暴占10.6%、图片视频处理占10.2%、文档创建占9.1%、代码调试占8.9%,基本上覆盖了开发者日常会使用的所有场景。
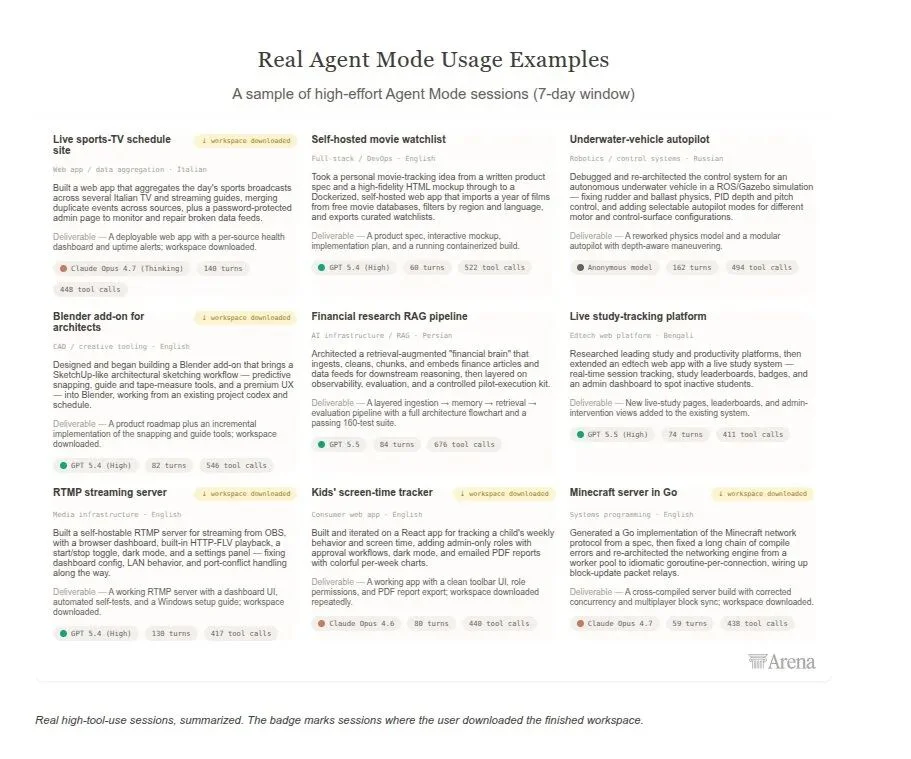
排行榜用五个独立分项指标来拆解Agent表现,每个指标对应真实工作中的一项核心能力:
确认成功:用户最终有没有点下“批准”(Approve)按钮。最直接的成败指标,统计的是每次会话中用户对最终结果的判定。Claude Opus 4.7 Thinking在这个信号上以+7.95%领先。
表扬与抱怨:系统自动识别用户消息中的正面和负面表达。表扬多于抱怨则任务记为成功。GPT-5.5 High以+14.95%排第一,说明它产出的结果最让用户满意。
可控性:Agent被用户纠正后能不能改对。现实中错误难免,能不能被顺利纠回来才是硬功夫。GPT-5.5 High以+12.03%领先,GLM-5.1这项是-3.41%,被纠正后容易回不来。
Bash恢复:统计Agent执行bash报错后需要多少轮才能恢复正常,放弃恢复会额外扣分。GPT-5.5 High(+17.73%)和Claude Sonnet 4.6(+17.23%)最强。
Grok 4.3这项是-89.43%,几乎不具备恢复能力。Gemma 4 31B也是-21.86%。
工具幻觉:Agent是否调用不存在的工具、编造工具名、或把内部标记泄露到工具字段。一旦出现直接标记失败。
这个信号上各模型分化严重:GPT-5.5和Kimi K2.6都控制在+1.52%,DeepSeek V4 Pro是-5.48%,Gemma 4 31B达到-32.64%。
Agent Arena测试的方法论核心是因果推断:
把"用哪个模型"当成一个随机变量——用户被随机分配模型,然后对比不同模型在相同类型任务上的表现差异。
排行榜上的"净改进"就是这个差值。这个方法的好处是模型没法靠背题刷分,每次任务都是真实用户随机分配的,跟考试一样公平。
榜单背后,藏着几个容易被忽略的信号
看分项指标能发现明显的风格分化。
简单的结论:Claude偏稳,GPT偏“让人开心”。
用户行为数据也揭示了一些有意思的现象。Agent Arena的统计显示,45%的用户开场就把整个任务直接丢给Agent(“交付完整成果”模式),只有28%是来找建议的。
但Agent第一次回复后,用户收回控制权的频率是再次授权的2.3倍。也就是说,用户一开始很愿意放手,看到初步结果后反而更谨慎了。信任没有想象中容易建立。
被纠正后的Agent还有一个普遍现象:虚张声势。
数据显示,Agent被纠正后有26%的情况听起来自信满满,但真正拒绝修改的只有2.7%,敢说用户错了的只有1.4%。大部分Agent的应对策略是嘴上应着“好的我改”,实际改没改对另说。开发者在调试Agent行为时这个现象值得留意。
成本也是一个容易被忽略的维度。Agent Arena统计了每次会话的实际花费,发现有些模型理论定价低但实际成本更高。行为模式差异导致:有的模型每轮调用工具更多、跑的步骤更长,或者让用户反复操作才能满意,最终账单比预期高。选模型单看Token单价容易掉坑。
排名≠生产力,选模型要看功能需求
排行榜是参考。不同场景下各信号的权重完全不同。
写代码和调bug的场景,Bash恢复和确认成功应该优先看。shell报错是家常便饭,恢复能力直接决定体验。
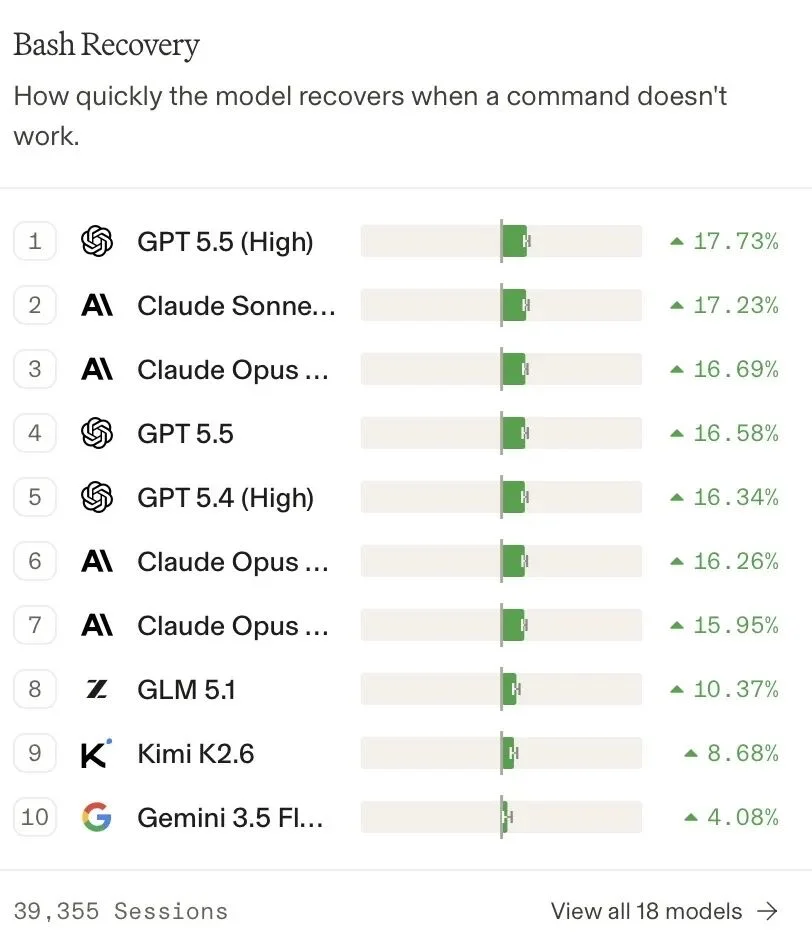
从数据看,GPT-5.5 High和Claude Sonnet 4.6在Bash恢复上表现最稳定,Grok 4.3和Gemma系列在这方面有明显短板。
做内容生成或需要频繁跟非技术人员协作的场景,可控性和表扬与抱怨更关键。需求来回调整多,模型能不能被顺利纠回来直接影响效率。GPT-5.5系列在可控性上大幅领先(+12.03%),Claude Opus 4.7 Thinking也不错(+9.04%)。GLM-5.1可控性是负值(-3.41%),这个场景下要慎重。
如果你在意成本,还需要结合Tool Hallucination和会话长度来算总账。工具幻觉高的模型会导致大量无效调用,实际花费远超理论定价。DeepSeek V4 Pro(-5.48%)和Gemma 4 31B(-32.64%)在这个维度上是明显短板。
模写在最后
Agent Arena榜单,说明了Agent评测正在过去的“考试模式”转向“工作考核模式”,榜单结果也更接近真实的用户体验。37.3万次真实会话数据评测出的结果,可以作为选型参考。但最终选择哪个模型更适合,还要回到自己的实际场景中才知道。
你目前的主力Agent模型是哪一款?它在Bash恢复和可控性上表现怎么样?如果已经在实际项目里踩过“榜单高分、干活掉链子”的坑,留言聊聊,看看大家踩的是不是同一款。
参考链接:
https://arena.ai/leaderboard/agent
文章来自于微信公众号 "51CTO技术栈",作者 "51CTO技术栈"
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md

