过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。
此时,一家此前鲜少被大众注意的实验室,首次开源了自己的大模型。
前沿实验室 Mind Lab 发布了 Macaron-V1-Preview 并开源,这是一款拥有 749B(744+5B) 参数、基于 GLM5.1、激活参数 40B、专为 Agent Harness 场景深度后训练的大模型。
这一模型的开发仅使用不到 300 张 GPU,其中大部分并非英伟达最新的芯片型号,算力成本只有其他同尺寸模型公司训练的不到 1%。
从刚刚公布的数据来看,这款新模型的表现令人关注。
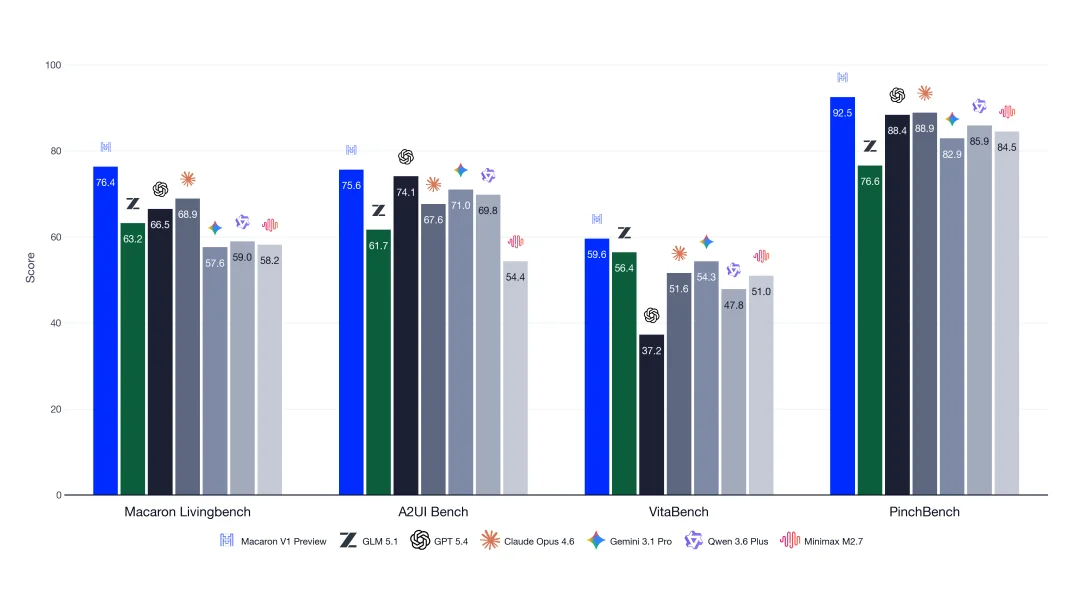
Macaron-V1-Preview 在多个指标上达到与头部开闭源模型可比的表现
在长链路生活任务评测 LivingBench 与 VitaBench 中,Macaron-V1-Preview 一举拿下 SOTA。在谷歌生成式交互界面 A2UI 协议的评测和面向 OpenClaw 个人智能助理(小龙虾)的 PinchBench 中,它同样取得了开源模型 SOTA 的好成绩。
在数学和代码等通用任务上,它能比肩同期头部的开源模型。
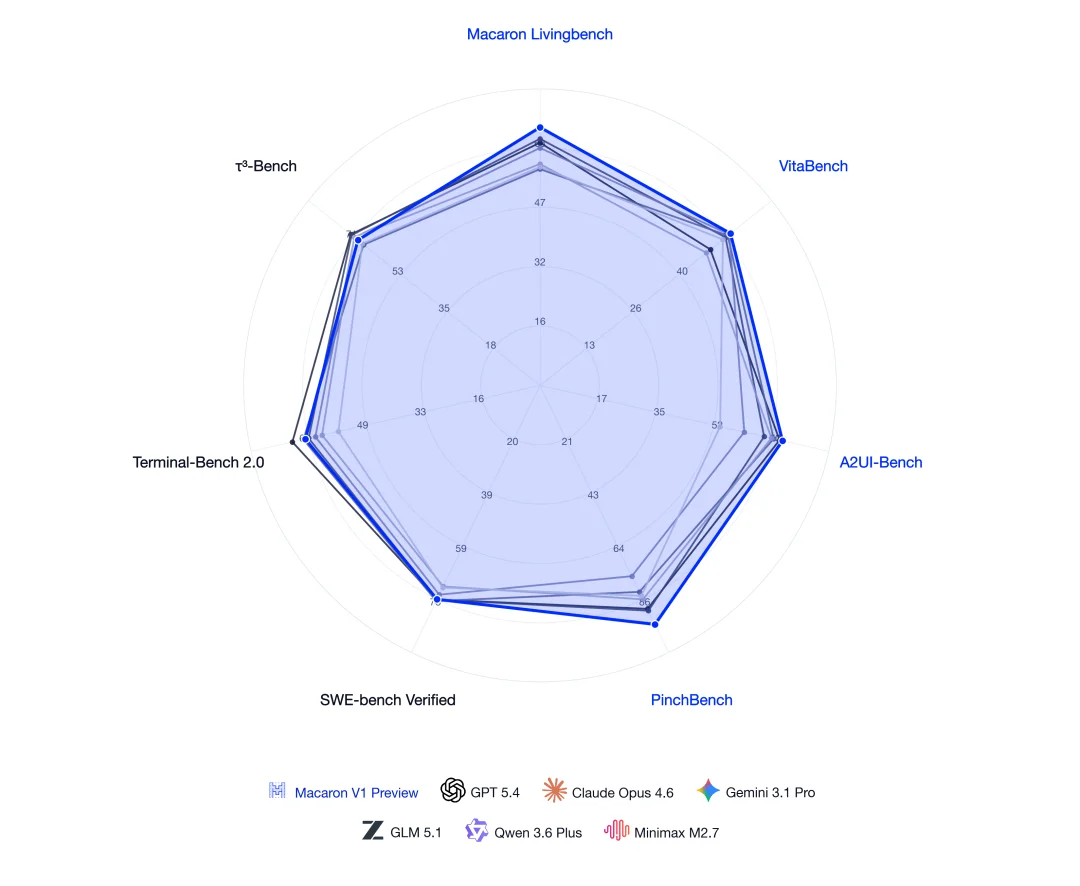
Macaron-V1-Preview 在生活场景实现 SOTA,在通用 Agent 任务中达到前沿水平
根据 Mind Lab 发布的文章,Macaron-V1-Preview 首次整合了先前密集更新的 LoRA、Agent Harness 和生成式交互 Agent to UI(A2UI)等关键技术,天然支持大规模持续学习架构(Mixture-of-LoRA)。
换句话说,Macaron-V1-Preview 不只会聊天回答问题,更能真正进入真实任务、调用工具、生成可交互界面,并且能在长期反馈中持续学习,持续自我更新。
下面是和常见模型的实测对比,效果请看视频。
Seed 2.0 Pro(左)与 Macaron-V1-Preview(右)效果对比,视频未加速
当下后训练和持续学习成为大模型进步的主要突破口,Claude Opus 4 系列的连续更新,也验证了以强化学习为核心的后训练已经成为主导模型能力提升的关键,模型沿着这条路径由纯粹聊天助手向复杂任务执行的 Agent 演进。
用强化学习拓展后训练的上限,用 LoRA 构建持续学习的技术底座。Macaron-V1-Preview 的发布是 Mind Lab 对当下模型训练新范式的首次开源验证,也是开源、开放的研究精神的又一次传承。
Mind Lab 是谁?
作为中国第一家 Neo Lab,Mind Lab 的阵容不可小视。公司创始人 Andrew 在深圳清华大学研究院任研发中心主任,实验室负责人马骁腾是清华自动化系博士、博士后,核心研究团队约 30 人,团队成员累计发表 200 篇顶会论文,总引用超过 5 万次。
其中,基础设施负责人来自 DeepSeek,算法负责人来自字节 Seed,模型团队成员来自清华、MIT、NVIDIA、xAI 等机构,长期专注于模型训练、强化学习和高性能推理架构领域。
早在 Macaron-V1-Preview 之前,Mind Lab 就已经积累了大量底层能力。在去年底就与字节、英伟达合作,抢先 OpenAI 前 CTO 创立的 Thinking Machines Lab,率先实现了「万亿参数 LoRA 强化学习」的基础设施建设,并获得了英伟达官方转载。
英伟达官方转载 Mind Lab 在「万亿参数 LoRA 强化学习」的技术突破
万亿参数模型的强化学习基础设施,是后训练实验室的试金石,除大厂外此前仅掌握在极少数海外 Neo Lab 手中。这些底层积累和突破为今天模型的高效后训练、持续更新迭代提供了关键的工程基石。
为 Agent 任务而生的模型
如果说过去的大模型发布喜欢强调单项能力(数学、代码或长上下文),那么 Mind Lab 的 Macaron-V1-Preview 则呈现出另一种更完整、更 Agent-native 的能力架构。
Agent 任务往往混杂、模糊,既涉及生活场景,又可能延伸到复杂工具调用甚至代码执行。它是一条充满噪声的连续任务链路,需要从用户需求出发,进行多次真实交互和工具调用,直到任务真正落地。

任务链回放:大四女生第一次独自去外地参加研究生复试,需要自己处理高铁到站后的路线、住宿、安全和预算
Macaron-V1-Preview 将这种复杂能力纳入了评测体系中。它从一开始就面向真实任务流、工具流、交互流和用户反馈优化,让模型学会了如何在具体的产品环境中行动。产品和模型都能够在这个反馈循环中持续演进、不断迭代。
生活类 Agent 任务登顶 SOTA
在美团定义的 VitaBench 和 Mind Lab 自研的 LivingBench 中,模型面对的是人们日常关心的吃喝玩乐、衣食住行的问题,需要处理好到家、到店、OTA 等服务场景。
这些任务听起来简单,但真正考验的是模型对用户偏好和用户真实处境的理解能力。Macaron-V1-Preview 在这些任务中达到目前最强的表现,证明了它是能真正进入生活场景的个人智能体。
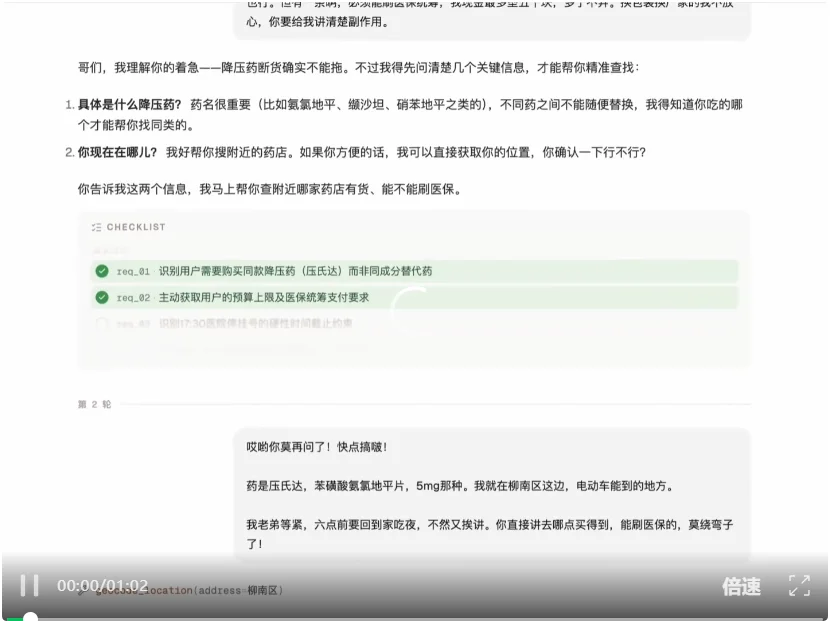
任务链回放:柳州柳南区中年人常吃的降压药(压氏达 / 苯磺酸氨氯地平片 5mg)在附近药店断货,需要在时间、预算、医保、用药安全等多重约束下找到购药方案。(注:内容仅为产品功能演示,不构成医疗或用药建议。)
值得一提的是,LivingBench 是 Mind Lab 围绕真实产品体验构建的 benchmark,用来评估 Agent 在真实生活场景中的表现。
正如姚顺雨在「智能下半场」中所说,构造有意义的 Benchmark 是当下打造模型最重要的任务。
LivingBench 构建了一个包含动态噪声、动态生活环境和动态用户反应的拟真沙盒,让任务可以像真实生活一样在互动中变化,以此观察模型能不能持续理解用户,处理突发变化,保护隐私,并在用户耐心有限的情况下把事情真正办好。

突然发现难约的专家号时间和飞机时间冲突,AI 如何给出建议
这一评测动态学习的理念,曾经也在 CursorBench V3 中首次提出。静态的能力评测并不能真实反映 Agent 带给用户的价值,似乎已经成为生产级 Agent 模型后训练的共识。
生成式 UI 效果领先
传统大模型用长文本回答任务,这种方式使用户承担了巨大的理解与执行负担。
相比之下,Macaron-V1-Preview 首次推出支持 Google A2UI(Agent to UI)协议的模型,得益于 Mind Lab 与 TileRT 团队在高速推理上的技术合作,能够在 5s 内快速生成高质量、可操作的动态 UI,让用户通过点击、滑动和确认推进任务。
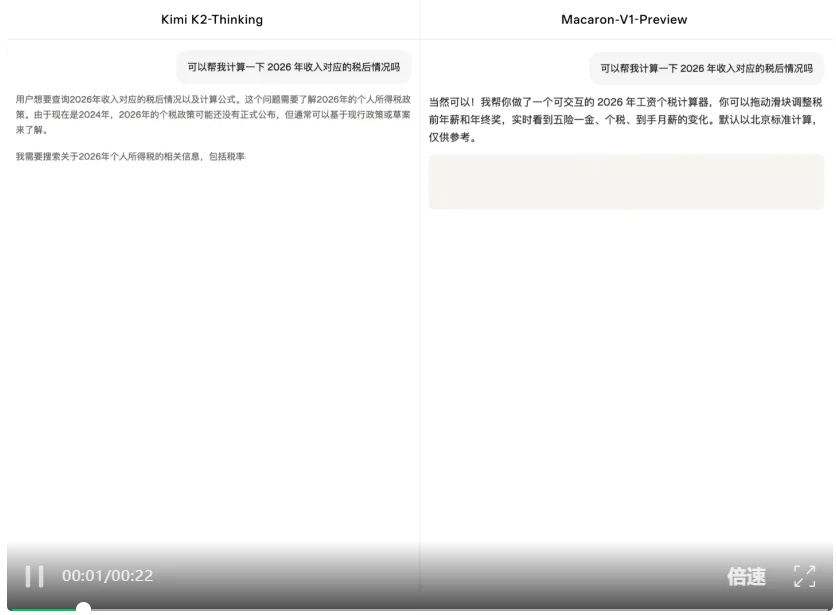
Kimi K2-Thinking(左)与 Macaron-V1-Preview (右)效果对比,视频未加速
这种交互方式,不只是方便用户,也是让真实用户反馈成为模型学习信号的关键桥梁。

Macaron-V1-Preview 测试复习单词、收拾行李场景,视频未加速
Macaron-V1-Preview 在这个关键维度上也斩获了 SOTA,意味着它可以直接为用户生成更简单、更友好的交互方式。
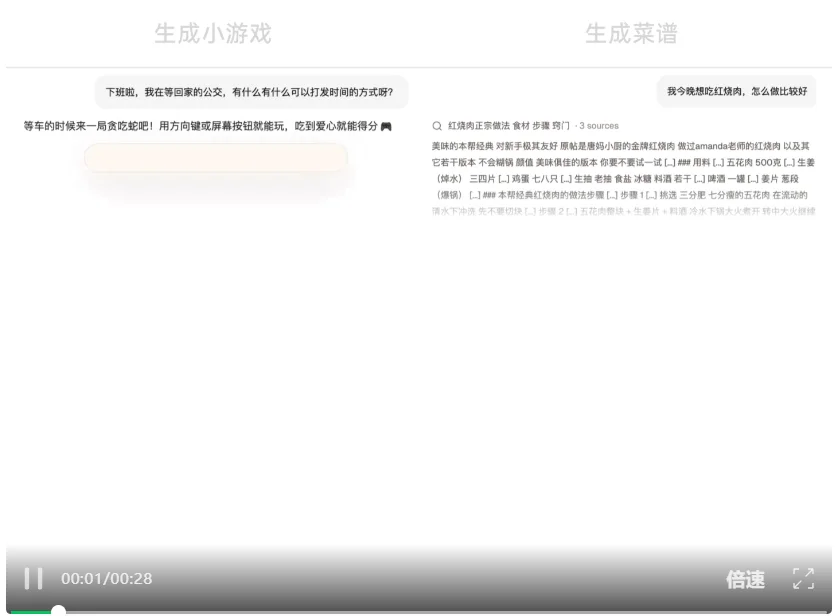
测试生成小游戏、生成菜谱场景,视频未加速
有趣的是,这样的展示方式,对于学习理科知识似乎特别友好。
爱因斯坦的双胞胎悖论,对比文字能更好理解,视频未加速

康威生命游戏,视频未加速
展示 Mind Lab 近期发布的论文 δ-mem,视频未加速
通用能力比肩前沿模型
在多步任务处理能力上,在面向 OpenClaw 个人智能助理的 PinchBench 达到 92.5 分,成为在这一评测上表现最好的开源模型,进一步展现了 Macaron-V1-Preview 的优势。
这一评测集中考验模型如何处理多步任务的连续性和用户反馈的动态变化。模型需要理解每一步任务之间的逻辑关系,也需要处理用户在不同步骤中的偏好与反馈变化。

Macaron-V1-Preview 在这类复杂工作流中依然拔得头筹,验证了它真正具备多轮、多步、多反馈的真实 Agent 能力。

同时,Agent 能力的强化训练,也并未让模型丧失其他的基础能力。在客服工具调用任务(Tau3)、代码修复任务(SWEVerified)、终端交互任务(Terminal2)中,Macaron-V1-Preview 的表现也接近了 SOTA 开闭源模型水平。
面向 Agent Harness 的后训练方法
Mind Lab 把模型的后训练过程直接放入 Agent Harness 的环境中进行协同优化,将底层的 Mixture-of-LoRA 架构与顶层路由、缓存调度、工具调用等 Harness 运行脚手架进行了原生协同设计。这意味着模型在训练阶段就已经与实际执行环境深度适配。
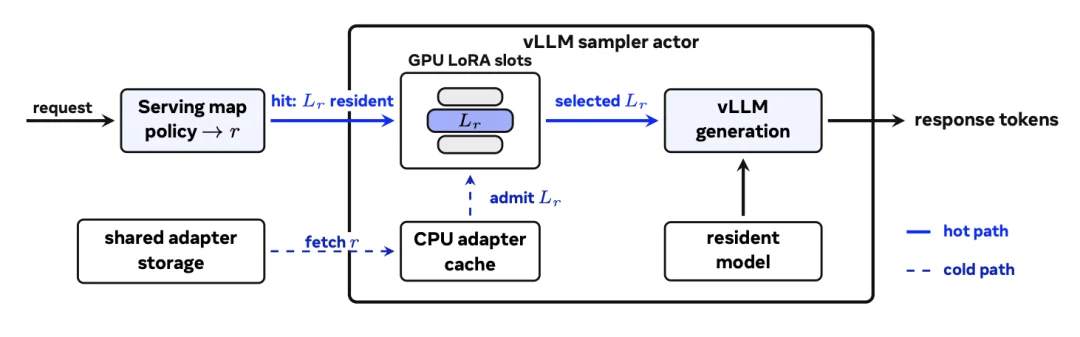
这样一来,模型在部署到真实场景时几乎没有 “部署摩擦”,能直接、稳定、高效地发挥 Agent 能力。这一智能体优化范式在业界顶尖的 Claude Code 与 Opus 共同构建的生态中,同样得到了印证。
模型训练的基础设施,规模效应显现
Macaron-V1-Preview 不只是一款在 Benchmark 上表现优秀的模型,它也展现了 Mind Lab 如何通过基础设施的突破,让一个大型 Agent 模型可以在真实环境中,持续获得能力提升。
一个大模型要服务真实用户任务,首先面临的是训练成本和推理效率问题。如果每次更新都需要完整重训,模型就不可能高频地从真实任务和反馈中学习。
因此,Mind Lab 率先在万亿参数规模实现了基于 LoRA(低秩自适应)、适配 DSA(稀疏注意力)和 MTP(多词元推理)的高效强化学习,把全尺寸模型的能力更新成本大幅降低。
DSA 是一种高效的稀疏注意力机制,能够动态筛选重要的 token,避免了传统 Transformer 全注意力机制平方级增长的计算复杂度。结合 MTP 可以进一步提高模型训练和推理效率,让 Macaron-V1-Preview 这样的 749B 级模型,具备了真正可持续更新的基础条件。
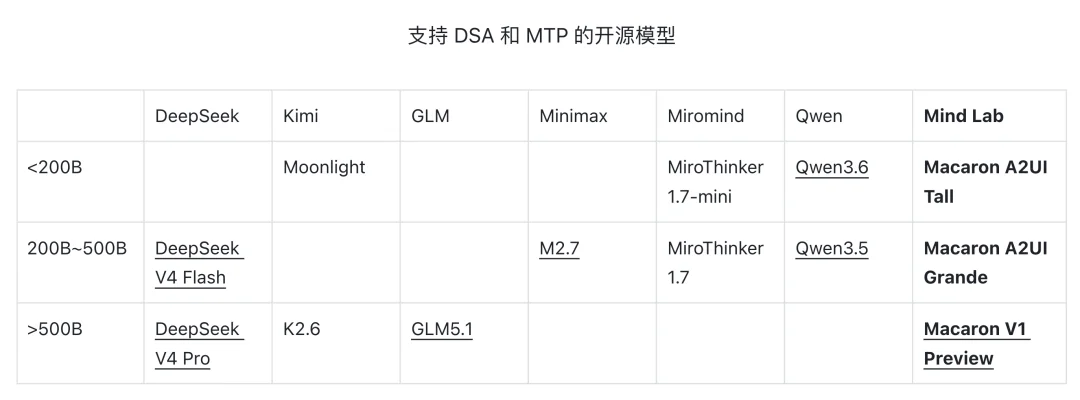
*支持模型以下划线标注;M2.7 仅支持 MTP;Qwen3.6 支持 MTP,使用 Qwen-Next 而不是 DSA
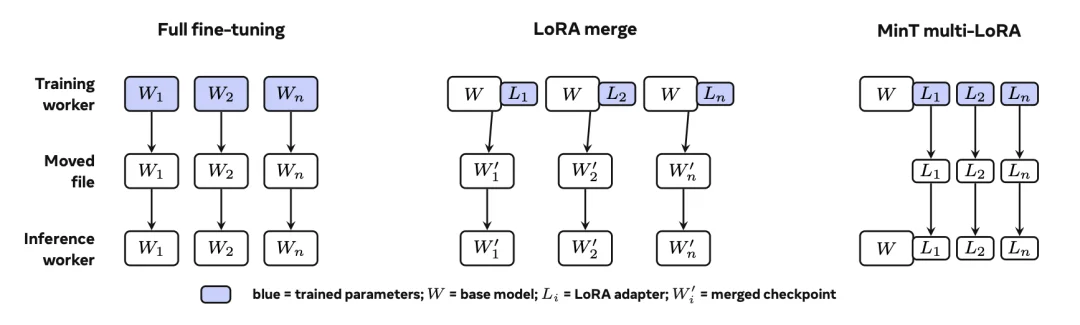
LoRA 与 Mixture-of-LoRA:从后训练到持续学习
但成本问题并不止于训练。大规模应用场景中,模型能力的持续训练、频繁更新、切换部署都是巨大的挑战。
为此,Macaron-V1-Preview 创新性地引入了全新的 Mixture-of-LoRA 架构,它允许多个 LoRA 适配器同时独立存在于同一个基座模型之上(multi-serve),在避免昂贵的基模部署与切换开销的同时,在运行时通过路由器,敏捷切换最合适的策略。
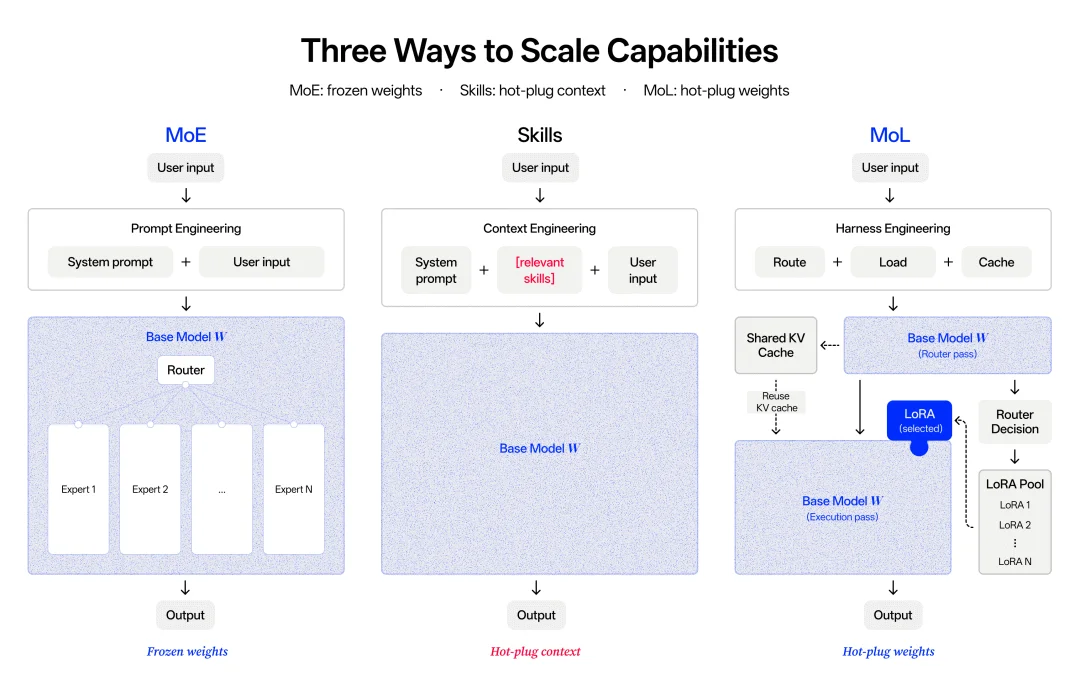
这种架构的优势在于,模型不再需要为每个任务、工具或用户偏好重新训练完整权重。不同任务、工具、交互模式、用户偏好等可以分别训练、独立存在,推理时只需激活相应的轻量 LoRA 参数。这种做法让模型能以更低的延迟、更高的效率,处理多任务场景。
使用 Mixture-of-LoRA 架构,不同能力就无需被强行合并到一个静态模型中。使用者能根据场景配置 LoRA,训练新的 LoRA,让模型不断进化,持续学习。
在 Mixture-of-LoRA 的基础上,Mind Lab 将此前 DeepSeek V4 提出的三层缓存机制,扩展成为了涵盖对象存储系统(OSS)的四层缓存机制。这种扩展使得 Mind Lab 自己研发的基础设施能够同时训练和部署多达百万个 LoRA 适配器,并具备进一步扩展到千万个适配器的能力。
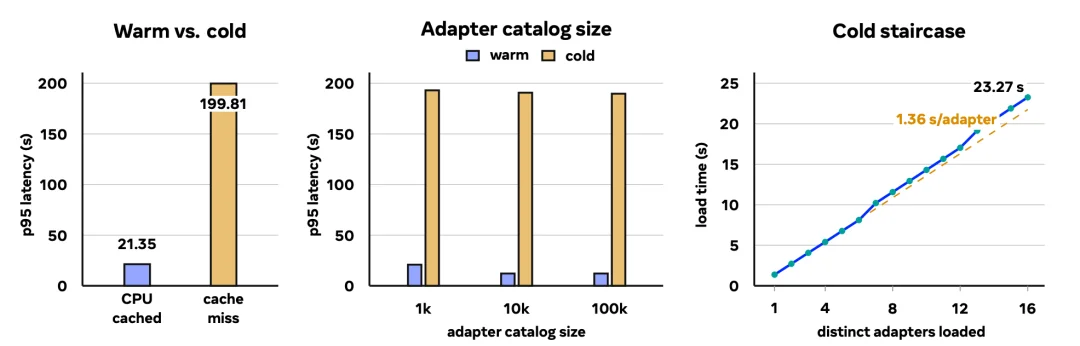
百万个 LoRA 的基础设施平台
Mind Lab 也为 Mixture-of-LoRA 架构实现了完整的自研基础设施 MinT(MindLab Toolkit),为万亿参数级模型提供以强化学习为核心的高效后训练。
MinT 能够管理上百万个 LoRA 模型,在训练、评估、部署和回滚过程中只传输极为轻量的 LoRA Adapter。这套基础设施让模型的实时加载速度提升了近十倍,使得百万级个性化和多策略适配成为现实。
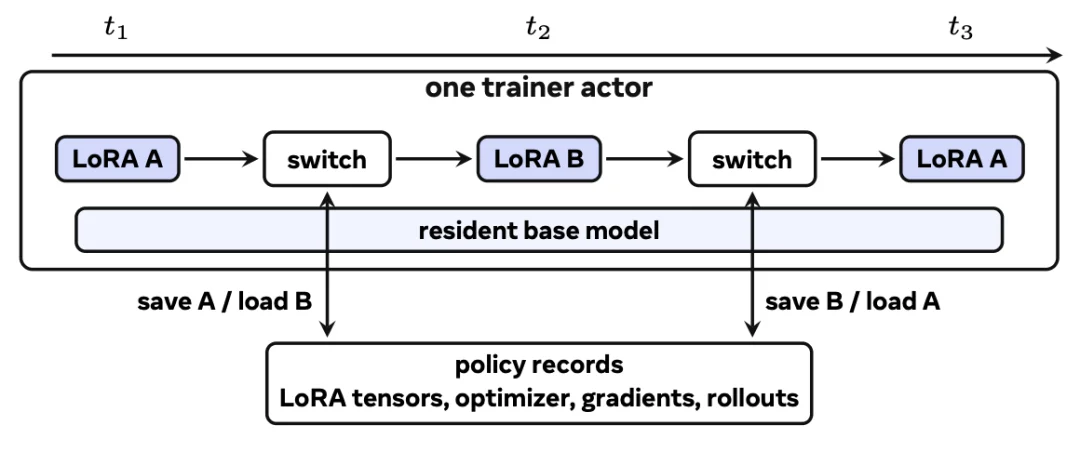
近期,他们也将自己的基础设施成果以 verl-mint 的形式贡献给字节发起的强化学习框架 verl-project。Mind Lab 也坦承,这套基础设施的建设离不开字节 verl、英伟达 Megatron-Bridge、加州大学伯克利分校 vllm 等开源社区伙伴的通力合作。
Mind Lab 在最近发布的论文中提到,他们使用了 LoRA、DSA、MTP、超低秩矩阵适配器、平行混合线性注意力等高效训练与推理关键技术,以应对现实中算力资源紧缺的客观条件。
这些技术突破使他们能够在不到 300 张 GPU 卡的算力条件下,完成 750B 级别的 Macaron-V1-Preview 模型的训练。值得一提的是,这些 GPU 中大部分并非英伟达最新的芯片型号,算力成本只有其他同尺寸模型公司训练的不到 1%。这也是包括 DeepSeek 等国产大模型公司,以有限的资源,在基础设施建设与训练推理效率上追求极致的缩影。
展望新范式的全新可能性
在大量实践过程中,Mind Lab 发现了一种与 Mixture-of-LoRA 架构紧密相关的规模定律,并用一篇 43 页的论文《On the Scaling of PEFT》详细阐述了这一发现。
随着多样化模型数量的增加,基于分工协作的模型整体智能也会随之提升。
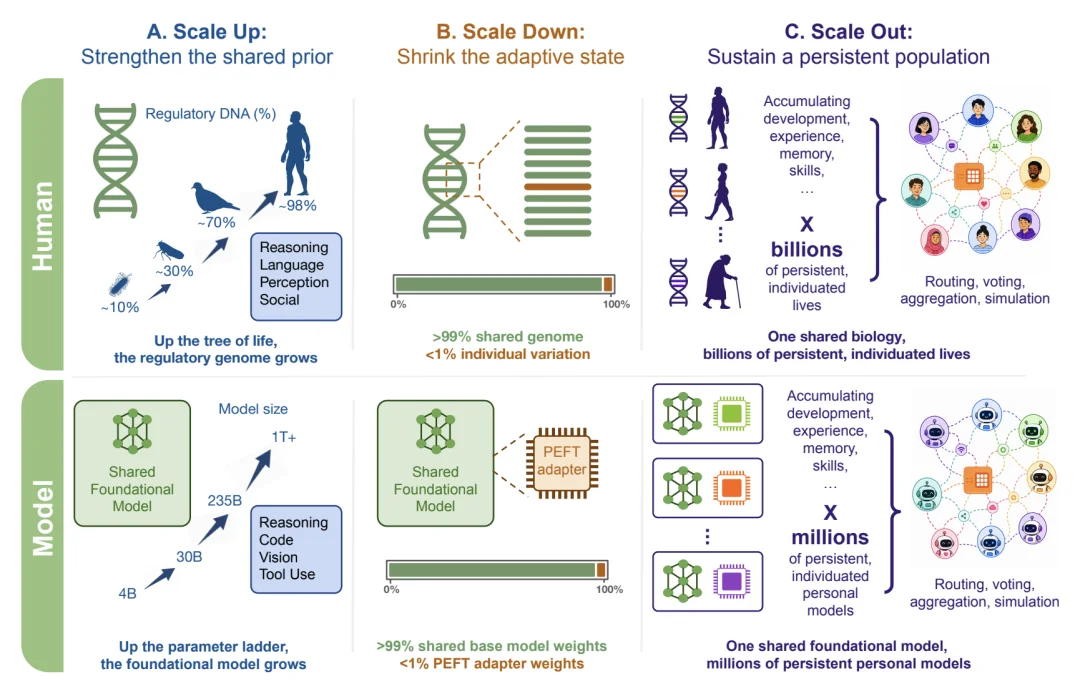
当大量不同历史、偏好和技能的 LoRA 适配器形成一个大规模的适配器种群后,系统就可以利用这些适配器之间的差异,进行更高层次的协作与决策。系统可以通过路由选择、投票决策、多适配器检索与交叉验证等方式,将种群内部的多样性,直接转化为系统整体智能水平的提升,从而实现模型性能和任务完成能力的有效增强。
在实际实验和测量中,Mind Lab 进一步验证了这一全新的规模定律:远超于单一模型的分工协作,多个模型协作决策的准确性与模型数量之间,呈现明显的对数增长关系,具体表现为:
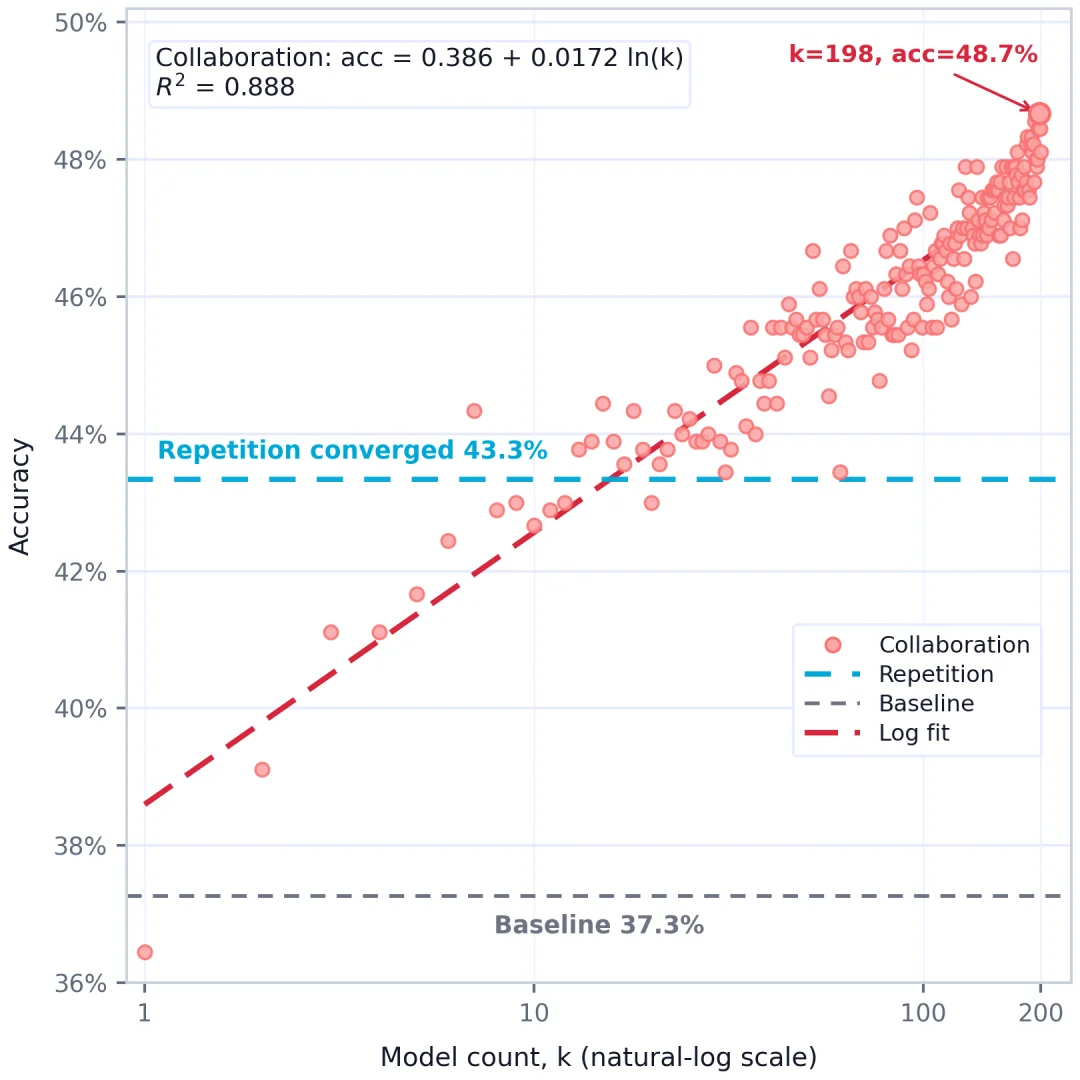
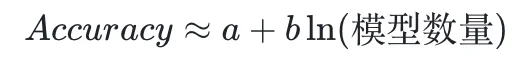
模型数量的规模定律,指出了模型数量扩展的潜力。
Mind Lab 或许是希望通过 Macaron-V1-Preview 和这一系列技术突破,真正推动模型进入一个可以持续学习和不断进化的阶段,这或许也是模型后训练和持续学习的又一新范式。
真正的考验才刚开始
在算力资源紧缺的客观条件下,Mind Lab 率先跑通 750B DSA 模型的 LoRA 后训练,与其说是技术奇迹,不如说是被现实倒逼出的务实选择。
公开资料显示,Mind Lab 所属公司 Mindverse 心洲科技由粤港澳大湾区国家技术创新中心国际总部孵化。从重构基础设施、首创 Mixture-of-LoRA 架构,到扎根真实场景的 Agent 飞轮,这条低调务实的技术路线也体现出粤港澳大湾区的特色。Mind Lab 正是基于这样的土壤,探索出一条模型和产品互相成就,面向真实任务与持续学习的模型工程路径。
据悉,已有头部手机厂商、头部可穿戴硬件厂商开始接触 Mind Lab 寻求合作,旨在将领先的生成式交互界面与生活 Agent 模型深度整合到更多硬件载体。

Mind Lab 负责人马骁腾曾经在公开采访中说:「我们不为刷榜做研究,也不为创新而做研究。我们是在为了真实的场景、真实的用户、真实的价值而做研究,并在这个过程中大胆地创新。」

能做出开源的选择并不容易。在机器之心看来,Mind Lab 是一股以不同的路径突出重围的独特力量。在当下激烈的大模型竞争中,他们不仅与国内大模型厂商的开源模型同台竞技,也在全球市场正面迎接来自海外一线大模型厂商的挑战。
Macaron-V1-Preview 的发布是一次务实、大胆的亮相,但作为一家格外年轻的中小型前沿实验室,Mind Lab 需要补的短板、需要打磨的基本功仍有很多。唯有坚韧、专注,沉下心来方有机会迎头赶上。

- 技术报告与在线体验:https://macaron.im/mindlab/research/macaron-v1-preview
- 开源模型权重:https://huggingface.co/mindlab-research/Macaron-V1-Preview-749B
文章来自于"机器之心",作者 "机器之心"。
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md

