Voice AI,是通用大模型之外的另一条故事线。

当所有人都在盯着通用大模型时,Voice AI 这条相对安静的赛道里,也开始出现一些值得注意的新模型。
键盘正在失去它的「统治地位」。
过去两年,OpenAI 推出了 Realtime API,Google 做出了 Gemini Live,国内的大模型公司也几乎都开始布局 Voice AI。越来越多的人开始相信,当 Agent 真正进入工作流之后,语音会成为比键盘更自然的上下文入口。
如果 Agent 想真正进入工作流,它首先要学会听懂这些声音。而这背后对应的第一层能力,就是 ASR(自动语音识别)。
衡量 ASR 水平,业内最常引用的是 Hugging Face 的 Open ASR Leaderboard,核心指标是词错误率(WER),数字越低,识别越准。长期以来,这个榜单基本是大厂和明星实验室的主场,训练数据、算力、工程积累,每一项都有比较大的门槛,很少有小团队敢在这个维度上正面竞争。
最近,一家名为 Hojo 的创业团队公开披露了一组语音识别测试结果,似乎有成为「黑马」的趋势。
根据官方公布的数据,Hojo-ASR-V1 在多个公开英文语音识别数据集上取得了不错的成绩。其中,LibriSpeech Clean 上词错误率(WER)只有 1.74%,在更接近真实场景的 GigaSpeech、VoxPopuli 等数据集上,也都压缩进了 8% 以内。他们没有提交榜单,但如果把数据放进 Open ASR Leaderboard 对比,会是一个非常前列的数据。
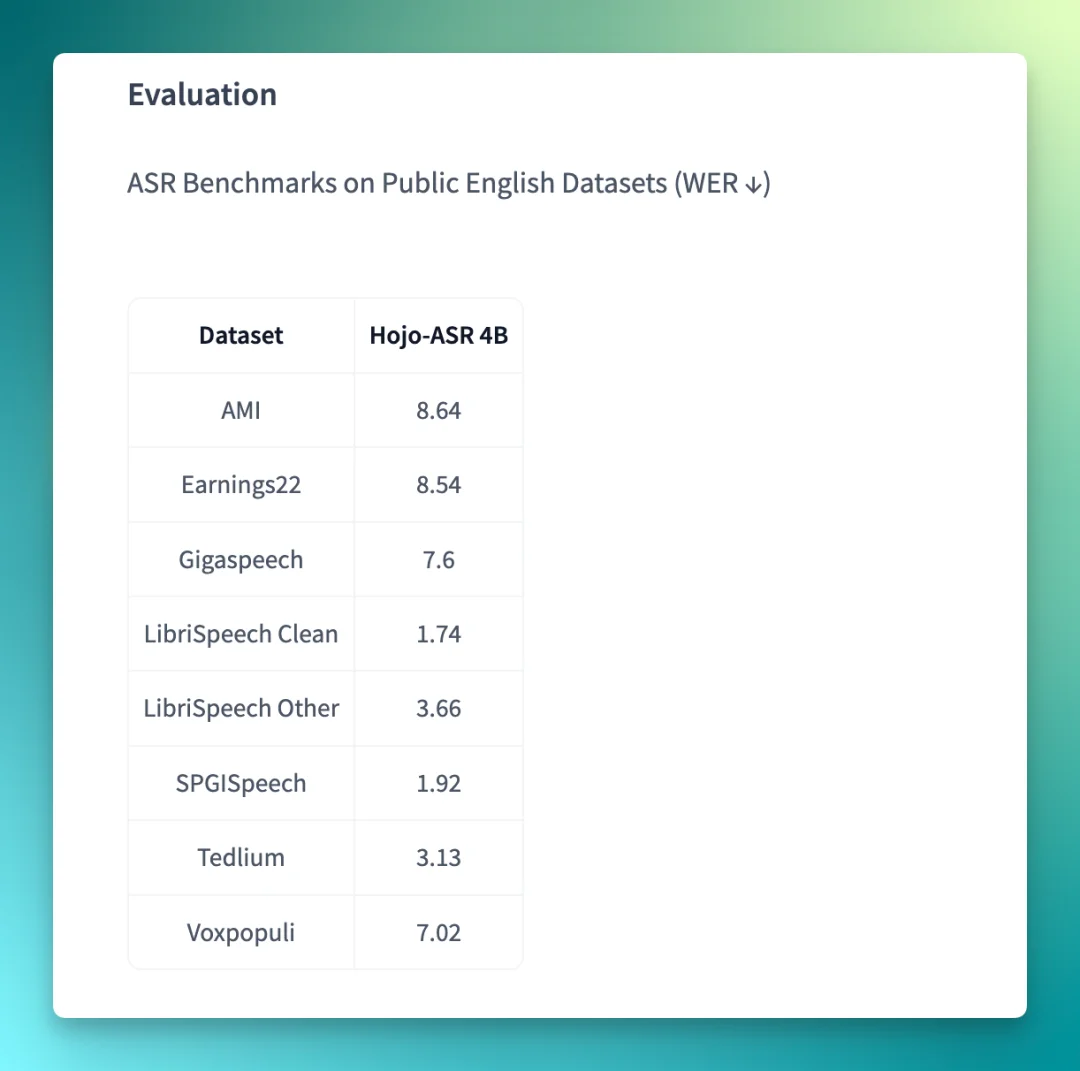
总的来看,这是一款在公开基准测试中展现出竞争力的 ASR 模型。而且它确实开源在了 GitHub 和 Hugging Face,Apache-2.0 许可证,二次使用没有太大限制。
🚥
于是,我们把 Hojo-ASR-V1 部署起来实际体验一遍,看看这家低调创业团队做出来的语音模型到底是什么水平,也顺着它聊聊 Agent 时代正在快速升温的一条新故事线:Voice AI。
Hojo-ASR 到底是什么,我们实测了一下
首先,Hojo-ASR-V1 开源到了 HuggingFace 和 GitHub :
Hugging Face 链接:
https://huggingface.co/HojoAI/Hojo-ASR-V1[1]
GitHub 链接:
https://github.com/HojoAI/Hojo-ASR[2]
先说清楚 Hojo-ASR-V1 是个什么模型,我们实际看过了它的代码和配置后,发现它的结构和传统的语音识别模型不太一样。
音频先用 Whisper 的特征提取器处理一遍,转成模型能用的声学特征,接着输入到 Qwen3-Omni 的音频编码器,中间用一个 Conformer 结构做适配和压缩;最后,被交给一个 Qwen3-4B 的语言模型,由它来写出最终的文字。
换句话说:
Hojo-ASR-V1 是一个「编码器 + 适配器 + 大语言模型」的组合。
用大语言模型来做 ASR 解码的思路,并不是 Hojo 一家独有。这正是当下 OpenASR 榜单顶部的主流方向。目前榜单上排名很靠前的几个模型,比如英伟达的 Canary-Qwen-2.5B、IBM 的 Granite-Speech-3.3-8B、微软的 Phi-4-Multimodal 都是把语言模型的能力接进语音识别里,平均 WER 降低到了 5.6% 到 5.9% 这个区间。
把语言模型放进来的好处在于,识别不光是「听到什么音、写下什么字」,模型还能借助语义去判断。遇到噪声、口语化的表达、中英文混着说、或者某个领域的专业词,一个懂语义的模型更容易判断出说话人想表达什么。
下面是实测部分,我们把模型部署到了本地,前后跑了好多轮。
实测案例,分为两层:
【1】Hojo-ASR-V1 模型的 ASR 能力。
【2】Hojo-TTS。
ASR
ASR 的全称是 Automatic Speech Recognition,也就是自动语音识别。
它负责把声音转换成文字,是整个 Voice AI 链路里的第一步。无论是手机语音输入法、会议纪要、实时字幕,还是今天越来越火的 AI Agent,背后都离不开 ASR。
我之前一直是 Wispr Flow、Typeless 这类 AI 语音输入工具的用户。
这类产品体验不错,但网络状态不稳定时偶尔会有延迟,对中文场景的适配也还有提升空间。后来我逐渐转向本地部署方案,其中用得最多的是 OpenAI 开源的 Whisper。
这次 Hojo-ASR-V1 发布后,为了实际体验下,我把原来的 Whisper 替换成了 Hojo-ASR-V1。
整体体验下来,识别速度和准确率都不错,作为日常语音输入已经足够流畅。当然,代价是需要一定的本地硬件资源,对内存有一定要求。
整个方案并不复杂,本质上就是用 Hojo-ASR-V1 作为底层识别引擎,再通过系统级权限接管语音输入。完成配置后,它可以在浏览器、ChatGPT、Claude、Notion 等几乎所有文本输入场景中工作。
测试时,我直接口述了一段关于「十字路口」的介绍,包括栏目定位、内容方向以及名称由来等内容。整个过程没有提前整理文本,也没有刻意放慢语速:

我个人觉得有意思的是,这类工作流还可以继续扩展。识别完成后,可以再接入 DeepSeek、GPT 或其他模型,对文本进行润色、格式整理、错别字修正和结构优化。
大概整体的流程是这样的:
声音输入 → ASR 转写 → 大模型优化 → 直接进入工作流。
对于经常写作、开会或者与 Agent 协作的人来说,这种体验比传统输入法更舒服些。
除了 Hojo-ASR-V1,我们也注意到 Hojo 在 TTS 方向同样有所投入。我们这次体验了它的 TTS 语音合成模型,另外,团队还开源了一个更轻量的版本 Hojo-TTS-Light。这些共同构成了 Hojo 面向 Agent 工作流的回答。
Voice AI 的另一块拼图:TTS
我们体验 TTS 模型能力的路径是其官网:
hojoai.com
多语言语音合成-轻快女性
先测的是多语言语音合成,这算是 TTS 模型一个比较常用的功能。
最近世界杯快开打了,我就让其用一个轻快点的女声,念了一段介绍世界杯日本队球员的解说稿:
这段大概 30 秒的中文听下来挺顺的,咬字和一些细节都处理得还行,AI 感不太明显。女声的声调、轻快的口吻,都能听出来。其实我们平时判断一个声音自不自然,一般就听它的咬字,还有每个词收尾时的声调,这段基本和一开始设定的风格是能对齐的。
测下来 Hojo 支持的语言不少,日语、法语、粤语都行。
下面还是同一段日本队的介绍稿,换成日语来念,效果也还可以,听着确实有点像 NHK 的播报,挺有既视感:
多语言语音合成-磁性稳重男性
这个 TTS 模型也能换不同的角色音色,男声听下来也还行。
下面这段还是介绍 2026 年世界杯的稿子,我把音色设成了磁性、稳重的男声。
这段听下来,和我提示词里设的基本一致。
多音色语音合成-有声书
TTS 模型能用的音色比较多。这回我让它用有声书的音色念一段。这段文字是火影忍者的一段主题介绍,用有声书的男声来合成的。
听下来挺自然的。念到「少年」这类词的时候,尾音处理得让前后衔接很顺畅。还有像「与」这种我们平时说话会用的连词,它停顿也卡得比较准,这也是整段听着顺的一个原因。
多音色语音合成-耳语
测的时候还有个音色想单独说一下,就是耳语。
下面这段我用女性耳语的音色,念了一段《沉默的羔羊》的电影介绍:
这段你能听清在说什么,同时它还把人凑到耳边说话时很轻的气流、细微的呼吸声和轻音都模拟出来了。听下来, TTS 模型的耳语不是单纯把音量调小,语气、节奏和情绪也都还不错。这种音色拿来做悬疑解说、故事旁白、ASMR 都比较合适。
除了标准播报音色之外,我还测试了一些辨识度更高的角色音色。
康辉
最近是高考季,电视、广播还有短视频上,能听到不少祝福语和新闻播报。央视主播的声音在中文播报里算是比较有代表性的,发音标准、吐字清楚。
所以这回我挑了一段康辉的音频当参考,下面这段就是康辉的原音频。
文件复制音色-康辉
我把这段原音频发给 TTS 模型,让它照着里面的音色复刻,念一段大概 40 秒、祝高考学子顺利的稿子。
效果上, TTS 模型把原来声线的特点保留得还不错,尤其是康辉的语气、停顿和播报节奏。第一句一出来,就能听出来跟康辉本人挺像。像念到「不负青春,奔赴未来」这类话的时候,熟悉的新闻播报腔和大型活动的主持感,都能听出来。
哪吒
音色复刻算是 TTS 模型比较有代表性的能力。我拿它复刻了几个 IP 角色的声音,先是《哪吒之魔童降世》里的哪吒。
听下来挺接近哪吒不羁、慵懒的感觉,停顿也差不多是这个状态。
小猪佩奇
卡通角色的音色, TTS 模型复刻得也还行。卡通角色的声音跟真人、电影角色不太一样,处理起来也有点区别。
下面这段就是我用 TTS 模型合成的小猪佩奇:
麦克阿瑟
甚至,我还专门录了一段抖音上很火的「麦克阿瑟」解说语音,让他念了一遍:
「十字路口」是国内一档聚焦 AI 浪潮的科技自媒体,核心形态是播客,同时延伸出视频、公众号文字版和线下社群活动。「十字路口」是乔布斯对苹果公司的一个比喻,形容它站在科技与人文的十字路口,伟大的产品往往诞生在这里。关注 AI 给各行各业带来的变革与机会,寻找、访谈和凝聚 AI 时代的「积极行动者」,和他们一起探索和拥抱新的可能性。
Hojo 这个团队是谁
回到 Hojo 团队本身,它并不是一家只做语音大模型的公司。Hojo 成立大约两年,在这次披露信息之前,外界对它的了解很少。因为,我们联系了其团队,获取了一些一手信息。

按照 Hojo 自己的定位,它更想做的是面向知识工作者的 Personal Agent OS。简单说,就是让 Agent 真正进入办公、沟通、创作、协作这些日常工作流,而 ASR 和 TTS 则是这套系统里的 2 块关键拼图。
这也是理解 Hojo 的关键。ASR 其实只是 Agent 听懂真实工作场景的第一层底座。只有先把会议、电话、语音备忘、多人讨论里的信息稳定地接受到位,后面的理解、规划、执行才有可能成立。
从团队背景看,Hojo 比较特殊的一点是,它的核心成员长期和「真实语音场景」打交道。团队成员多来自车载语音、智能座舱和语音交互相关团队,包括小鹏、蔚来 Nomi、商汤等。
具体点说的话,创始人赵恒艺此前曾在乐视、小鹏、蔚来和商汤等团队负责语音交互、智能座舱和 AgentOS 相关工作,做过车载语音、智能座舱、多语言交互、AI 自主操作应用和跨设备服务。
首席产品官李欧此前在商汤、蔚来等团队负责 AgentOS、智能座舱和数字产品规划,关注的是语音能力如何被组织成完整产品体验,而不是停留在单点模型能力上。COO 孙晓刚则有 Agent 解决方案、语音交互商业化和行业落地经验,参与过车载、餐饮、出行等场景中的语音交互方案。
把这些履历放在一起看,Hojo 团队的共同经验对于长期处理真实场景中的语音问题是有背景背书的。
这主要也是因为这些团队成员基本都聚焦于 ASR 比较现实的环境里,这些场景和实验室里的干净音频很不一样。车里有噪声,有方言,有多人说话,有临时打断,也有大量不完整、口语化的表达。用户不会按照标准 Prompt 说话,也不会等系统慢慢反应。做过这类场景的人,更容易理解语音模型真正难的地方,ASR 需要在复杂环境里稳定理解人的意图。
Hojo 的首席科学家苏丹的经历也放在这个脉络里更容易理解。他早年在百度参与语音识别相关研发,经历过深度学习把 ASR 推向商业化落地的阶段;后来在腾讯 AI Lab 负责语音相关方向,又赶上了大模型重新改写语音交互的阶段。
这条履历的价值所在是他本人连续经历了语音技术从识别准确率竞争,到真实场景落地,再到大模型时代语音交互重构的几次变化。对一家想做 Personal Agent OS 的公司来说,这种经验决定了它不会只把语音看成一个输入组件,放进真实工作流里重新设计才是关键。
资本层面,Hojo 在产品还没有正式大规模面世的情况下,成立至今已经完成接近一亿元人民币的 4 轮融资,目前正在进行 Pre-A 轮。这类信息不能直接证明产品一定成功,但至少说明一级市场已经开始关注这家公司在 Voice AI 和 Agent OS 方向上的技术积累。
商业化方面,据 Hojo 介绍,它自研的「大模型 + Agentic OS」组合,已经为千万量级的 AI 声音设备提供底层语音能力。如果这个数字属实,说明它不是只停留在论文、Demo 或榜单上,而是已经进入了真实设备和真实用户场景。
从 Hojo 自己的规划看,ASR 只是第一步。它同时还在做 TTS,并计划在 6 月底推出全双工语音模型。真正想讲的故事,是围绕 Personal Agent OS 搭建一整套语音交互底座:让 Agent 能听见、能理解、能回应,并最终进入知识工作者的真实工作流。
这些规划能不能兑现,还需要后续产品来验证。但至少从这次 Hojo-ASR-V1 的表现看,它已经在 Voice AI 工作流的第一环上,交出了一份足够引人注意的结果。
那,Hojo-ASR 的这组披露数据为什么会吸引到关注?或者说 Hojo-ASR 处在一种怎样的背景之下?
Voice AI,是通用大模型之外的另一条故事线
当 Agent 开始进入真实工作流,它需要接收的上下文会越来越复杂:会议里的讨论、电话里的需求、现场环境里的声音、用户临时补充的一句话,甚至多人同时协作时不断变化的指令。
过去这些信息主要靠打字输入,但在很多工作场景里,真正发生的信息并不是写出来的,而是说出来的。
这也是为什么大厂这两年都在加码 Voice AI。OpenAI 推出 Realtime API,Google 做 Gemini Live,国内的科大讯飞、豆包、MiniMax、阶跃也都在语音方向投入。
这条赛道这两年的热度,可以用一笔笔热钱来衡量。根据 AssemblyAI 统计,2025 年语音类 AI 创业公司拿到的风险投资大约有 21 亿美元;从 2025 年 6 月到 2026 年 5 月这一年里,对话式 AI 领域公开披露的融资有 36 笔,合计约 25.8 亿美元。
一个词总结,就是非常热。
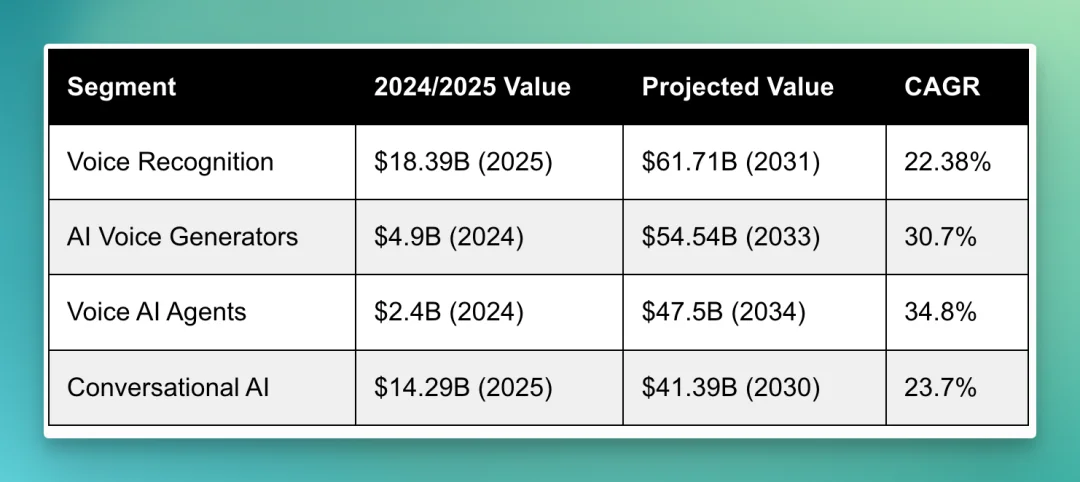
具体到公司,做语音合成的 ElevenLabs 在 D 轮拿了 5 亿美元,估值到了 110 亿美元;做电话客服语音的 PolyAI 拿了 8600 万美元的 D 轮;主打实时通话的 Retell AI,每个月要处理 4000 多万通 AI 电话,季度环比增长超过 300%。还有像 Cartesia 这样的团队,专门去把语音的延迟降到 100 毫秒以内,让对话听起来卡顿感更低。
大厂这边动作也非常多。OpenAI 推出了 Realtime API,把语音做成端到端的方案,声音进、声音出,中间不再分成「转文字、过模型、再合成」三段,一次走完全流程。
Google 的 Gemini Live 是类似思路,能在你话说到一半时被打断,再接着回应,这两天也上新了 Gamma4 支持的 Voice AI :

可以看得出来,语音正在从一个「更自然的交互方式」,变成 Agent 获取上下文的入口。
放到最近流行的 Vibe Working 里,这个趋势会更明显。人不一定要把每一步需求都整理成完整 Prompt。可以边想、边说、边调整,让 Agent 在对话中接住意图、补全上下文、推进任务,这种可能才会更自然些。
在这条链路里,ASR 是第一层能力。它决定 Agent 能不能先听懂真实世界。听不准,后面的理解、规划、执行都会失真;听得准,语音才可能真正成为工作流的一部分。
总的来说:
当 Agent 开始进入日常生活,语音,也就是 Voice AI 很可能是它接触人的第一道入口。人和 AI 连接的方式有很多种,比如打字、点界面、写代码就去调 API,但最接近人与人日常对话的,还是开口说话。
这也是为什么越来越多人把语音称为 Agent 的 context entry,也就是上下文入口。如果说大模型负责理解世界,那么语音就是世界持续流入模型的通道。
而在这条通道里,ASR 扮演着感知层的角色。它决定 Agent 能否准确捕捉外部环境中的信息,能否把现实世界里的声音转化为模型可以理解和利用的上下文。
从这个角度看,ASR 的竞争点已经升维了:
争夺下一代 Agent 与真实世界连接的入口。
这也是 Hojo-ASR-V1 的披露数据更值得关注的原因。它背后反映的并不单单只是一个模型成绩的变化。
Voice AI 正在从辅助能力走向基础设施,成为 Agent 时代越来越重要的一层底座。
🚥
回到 Voice AI。当大部分厂商的注意力都集中在通用大模型上时,语音这条相对安静的赛道其实已经在快速演进。就在 ASR 这样一个长期由 OpenAI、微软、英伟达、IBM 等大厂主导的领域里,开始有创业团队交出颇具竞争力的成绩。
Hojo-ASR-V1 的出现,未必意味着格局已经改变,但至少说明 Voice AI 正在从边缘能力走向更重要的位置,并吸引越来越多的人重新关注这条赛道。
语音识别只是 Voice AI 的第一步,机器听准了之后,能不能理解、能不能用接近人的方式回应,才是更长、更有价值、更高潜的故事。
参考资料
[1]https://huggingface.co/HojoAI/Hojo-ASR-V1:https://huggingface.co/HojoAI/Hojo-ASR-V1
[2]https://github.com/HojoAI/Hojo-ASR:https://github.com/HojoAI/Hojo-ASR
文章来自于微信公众号 “十字路口Crossing”,作者 “十字路口Crossing”
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales

