某天,老板让你用 Agent 手搓个自动化流程的小工具,你袖子一撸,信心满满地开干。
结果,你让 Agent 把脚本里写错的一行路径改对,它怎么都改不进去。
你只能放弃挣扎,动手修改。
跑到后面,Agent 连你的需求也记不住了;抓取的信息还总是大半年前的旧闻,根本不能用。
我特意收集了三个比较有用的开源项目,分别针对编辑、记忆、信息获取这三处短板,让你的 Agent 快速变聪明。
项目一:oh-my-pi 治手抖
现在 Agent 改代码,绝大多数是同一套逻辑:先让 Agent 把要改的那段旧代码原样复述一遍,作为修改定位,再把它替换成新的。

也就是说,Agent 得把旧代码复述得分毫不差,才能开始修改。
文件要是中途被别的步骤动过,或者代码里好几处长得差不多,它就彻底懵了。
下面这个项目是一个 AI 编程 Agent,最近在 Coding Agent 圈子里相当能打,GitHub 上已经破万 star。
项目由好几个部分组成,其中最核心的部分是 hashline 构架。
前面说过,Agent 得把旧代码一字不差复述出来,才能修改代码。
hashline 换了个思路,干脆不让它复述了。
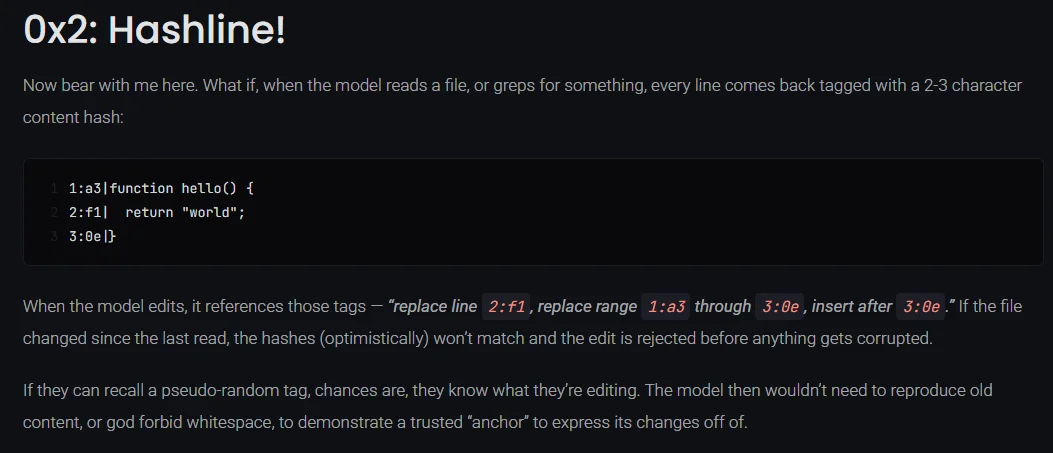
每生成一行代码,Agent 都会给这行挂上一个哈希锚点,相当于这行代码独一无二的指纹。
往后要改这行代码,Agent 直接报锚点就行,用不着再把旧代码整段搬一遍。
修改时,omp 会拿这个锚点跟当前文件再比对一次。对得上,就修改。
要是对不上,那就说明这行在它修改之前,就被别的步骤改过了。omp 不会在一个已经变样的地方硬打补丁,而是直接拒掉这次编辑。相当于每次改动前都自带一道版本校验,从机制上杜绝了改错位、改串行。

光说原理你可能没体感,直接上实测数据。开发者曾把 omp 接入 16 个模型、180 个任务,测试结果如下:
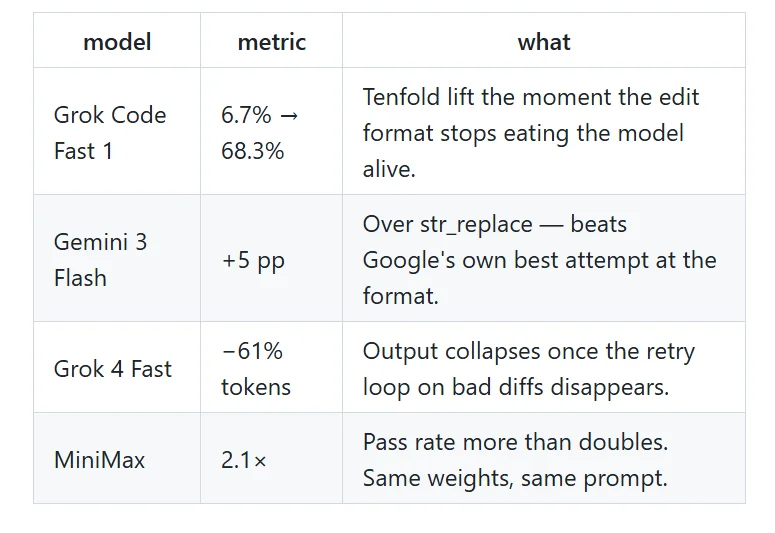
最夸张的是 Grok Code Fast 1,改代码成功率从 6.7% 直接干到 68.3%,接近十倍。
这里面有个特别反直觉的点,越笨、越弱的模型,装上它之后收益反而越大。
它也非常省钱,因为模型不用再为了复述旧代码白白烧一大把 token。
顺带提一句这个项目的身世:omp 的前身是 Mario Zechner 的极简终端 Agent「Pi」的一个 Fork,之前火出圈的个人 AI 助理 OpenClaw,底层用的也是 Pi。
项目链接:
https://github.com/can1357/oh-my-pi
项目二:TencentDB Agent Memory 治健忘
接着,我们来治 Agent 的健忘。
Agent 能记住多少,取决于一个叫上下文窗口的东西。它能一次性塞进去多少字是有上限的,你们聊得越久,这个窗口越满。
聊天达到上限后,它就会把最早那几句直接删掉。
你原先说的话,就这么在一轮轮地聊天中被挤没了。

现在主流的记忆解决方案,大多是一个套路,把对话切碎丢进向量库,要用的时候靠相似度去盲搜。
结果是,搜上来一堆看着相似、其实没用的对话,你真正想要的那条,反倒沉在了底下。
还有个更要命的点:跨会话的「记不住你是谁」,和单会话里的「被一堆废话撑爆」实则是两码事。
在真实任务里,单次会话工具日志的爆炸,可能比跨会话忘事还频繁。

Tencent DB Agent Memory 的聪明之处,就是它选择两个问题分开治。
先看「跨会话场景」,它的解法是分层。
这套解法,仿照了人类的记忆系统。
你不会把每天每句话都原样背下来,而是慢慢把零碎的经历,沉淀成对一个人、一件事的稳定印象。
它也把这个过程进行拆分,总共拆成四层,从下到上叫 L0 到 L3,每一层只干一件事。
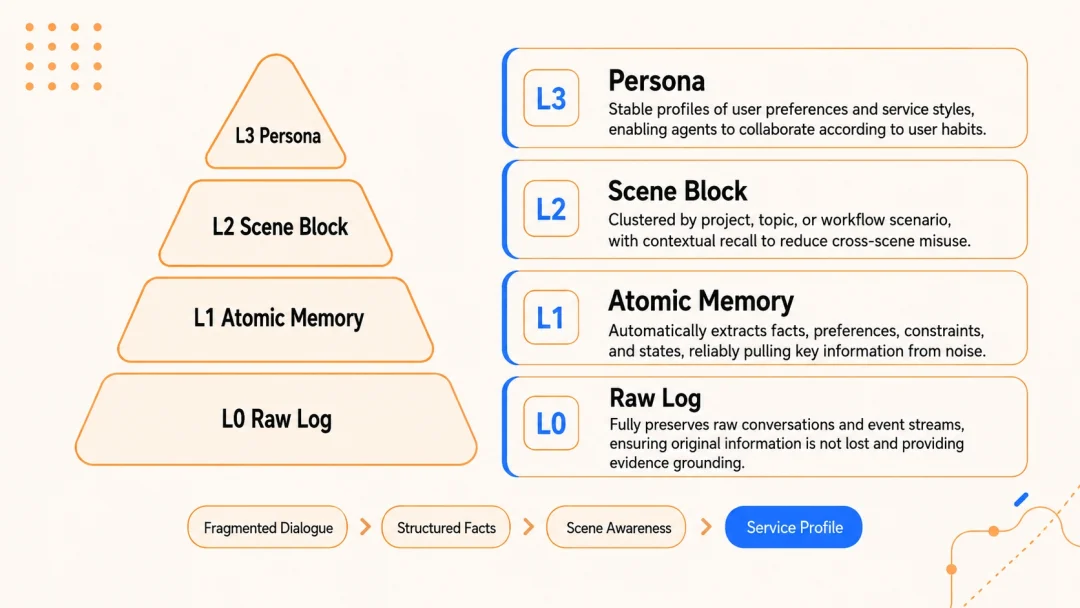
L0,把你说的每句对话保存下来,这是档案。
L1,从这些大白话里,把真正有用的事实、你的偏好、定下的规矩拎出来,单独记忆,这是要点。
L2,把这些零散的要点归归类,拢成一个个完整的场景和事件,这是脉络。
L3,沉淀成关于你这个人的稳定画像,这是结论。
这一路,越往上越精炼,噪音越少。
上层管方向,下层管证据,各司其职。
再看「单会话场景」,它的解法是上下文卸载加 Mermaid 画布。
它会把繁杂的工具日志卸载到磁盘文件里,上下文中只留一张轻飘飘的 Mermaid 任务画布。
这张画布,会把任务结构折叠成一张能导航的图 。
画布上每个节点都带编号,你想核对某个细节,只要按编号查找,磁盘上的原文分分钟就能调回来。
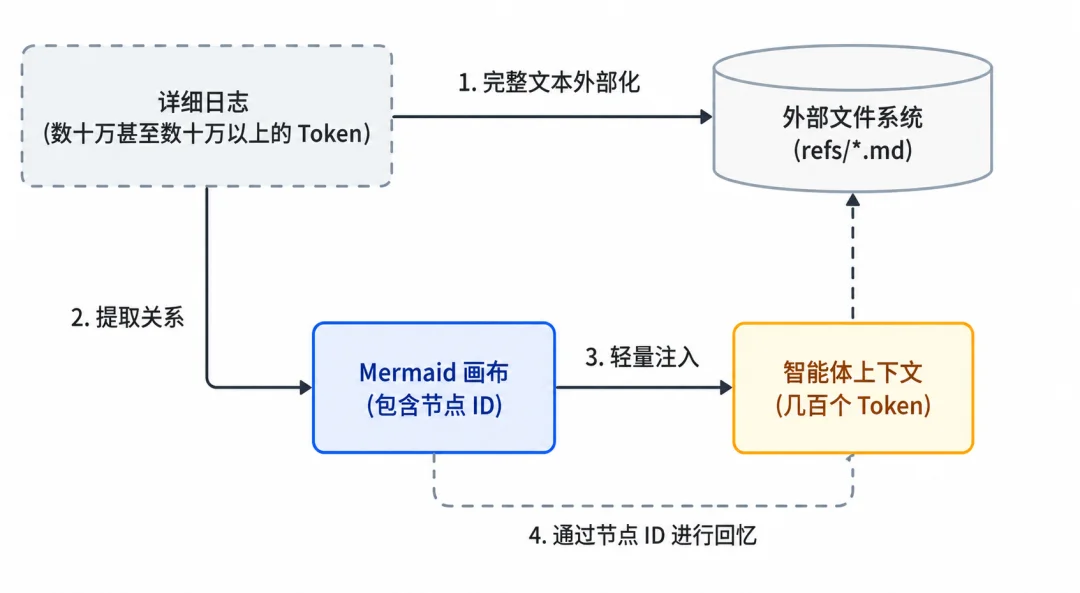
说实话,这项目里用的 SQLite、向量库、Mermaid、大模型抽取,单拎出来哪个都不新鲜。它真正的本事,是这套架构取舍:想明白了哪些信息该沉到底层当证据,哪些该浮到上层。
而且,它用的是异构存储,可以全链路溯源。底层的事实、日志进数据库,顶层的画像、场景是能直接打开看的 Markdown 文件 。
记忆在这里,不再是个黑盒。
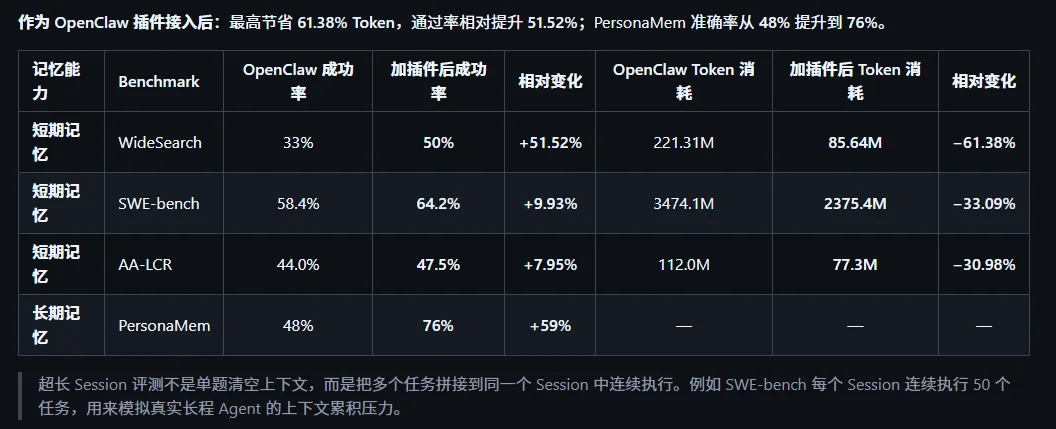
有开发者测试过,把它当成 OpenClaw 的插件接进去之后,最高省 61.38% 的 token,任务通过率相对提了 51.52%,在专测长期记忆的 PersonaMem 上,准确率从 48% 干到了 76%,相对提升近六成。
项目链接:
https://github.com/TencentCloud/TencentDB-Agent-Memory
项目三:last30days 治眼疾
如果你想让 Agent 搜最新网页,它一般会调用内置的网页搜索工具。
说白了就是接个搜索引擎,简单粗暴地把搜出来的头几条链接抓回来。
按照这种方式,给你的网页是被 SEO 排过序的,不一定是最新的。
真正在x、reddit社区的一手讨论贴,它基本碰不到。
这是开发者 mvanhorn 做的一个研究类 skill,GitHub 上有 25.5k star。
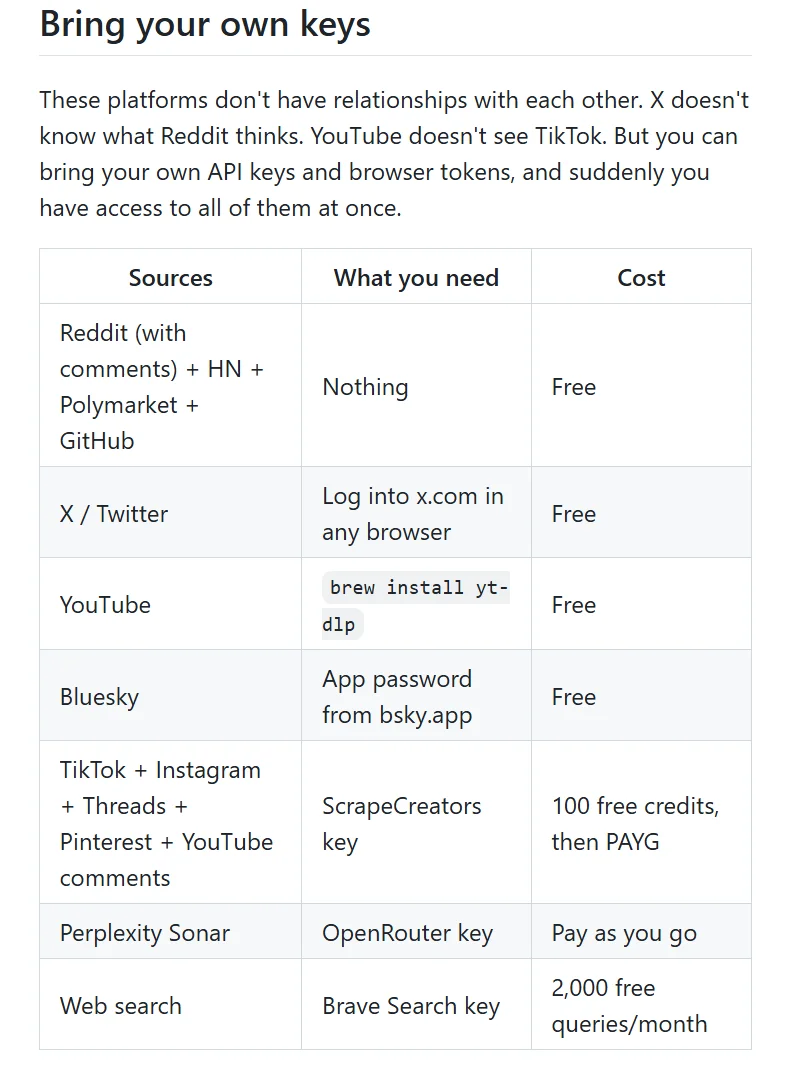
last30days 干的事,就是绕开搜索引擎,直接扎进这些地方:Reddit、X、YouTube、HN、Polymarket、GitHub,一把将信息全捞回来。
普通搜索聚合的是编辑筛过的内容,而它搜的是人。
它不按 SEO 排序,而是按真人实打实的反应给每条打分,谁的赞多、谁的投票高,哪条帖子就靠前。
而且,它还可以跨平台的相互印证。同一件事,要是在 Reddit 、HN 、X 上都有热度,它就把这条的权重往上提一大截。
不过,要把功能吃满,得同时配 OpenAI 和 社区平台两边的 key,才能开启双边的交叉验证。只配一个是单边模式,一个都没有就退回纯网页搜索,不会有真人互动打分。
内附各平台搜索信息的价格,和需要准备的工具:
项目链接:
https://github.com/mvanhorn/last30days-skill
文章来自于"JackCui",作者 "JackCui"。
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/

