别再只盯着“AO”两家的新模型大战了!
就在刚刚,谷歌闷头干了件大事:
把生成图片的扩散模型,拿来写文字了,而且一出手就是4倍加速。
新模型名为DiffusionGemma,它直接抛弃了传统自回归那套“逐Token生成”的打字机模式,而是像“印刷机”一样工作——
一次铺开256个token的“画布”,从随机噪声出发,多轮去噪,整段文字同时浮现。

靠这套新模式,DiffusionGemma在生成速度方面交出了亮眼的成绩:
单块H100上每秒1000+ tokens,消费级RTX 5090上700+,比同规格自回归模型快了4倍。
更关键的是,这个26B参数的MoE模型,推理时只激活3.8B参数,量化后18GB显存就能装下。
翻译过来就是,一张4090就能本地跑。
目前DiffusionGemma采用允许商用的Apache 2.0开源协议,权重可在Hugging Face直接下载。
天下武功,唯快不破
说到这估计大家都明白了,DiffusionGemma身上最大的标签无疑就是“快”。
有多快呢?成绩单说话。
在同一块H100上(fp8,batch size=1),DiffusionGemma跑出了1000+ tokens/s,而采用标准自回归的Gemma 4 26B A4B加上MTP加速也只有300+ tokens/s——
速度拉开近4倍。

而要理解DiffusionGemma为什么快,咱得先说说当前大模型为什么“慢”。
今天的主流大模型,不管是GPT、Claude还是Gemini,底层都是自回归架构——就像一台打字机,从左到右,一个token一个token地敲出来。每生成一个新词,都要重新加载一遍几十亿参数的模型权重。
在云端,这不是大问题。服务器可以同时处理上千个用户请求,把硬件利用率拉满。
但如果你在本地跑模型,场景就完全不同了——
只有你一个人在用,GPU的大量算力其实在空转,等着一个字一个字地往外蹦。
工程师管这叫“内存带宽瓶颈”(memory-bandwidth bound)。

而为了解决这一问题,DiffusionGemma就盯上了扩散模型。
回想一下,扩散模型在生成图片时,是不是直接对整张图的所有像素同时去噪——
没错,其工作方式就是一次性对一整块token同时操作,天然“并行”。
这意味着GPU一次性接到一大块并行计算任务,Tensor Core火力全开,不再干等。计算瓶颈从“内存搬不过来”变成了“算力够不够”,而算力恰恰是GPU最不缺的东西。
具体到DiffusionGemma,原理和Stable Diffusion一样,只不过去噪得到的不是图片,而是文字。
Step 1:铺开一张全是随机占位符的256个token的画布。Step 2:多轮迭代去噪,高置信度的token先锁定,再用它们当上下文线索去修正其余部分。Step 3:整段文字收敛为最终输出。
用谷歌自己的比喻,这是从单线程的打字机,升级成了整版印刷的印刷机。
看看下面这个Hugging Face制作的DiffusionGemma文本到3D SVG演示,可以直观感受逐步生成的过程——
模型不是从第一行代码写到最后一行,而是整块SVG代码同时浮现、同时修正,最终收敛成一把完整的3D宝剑。
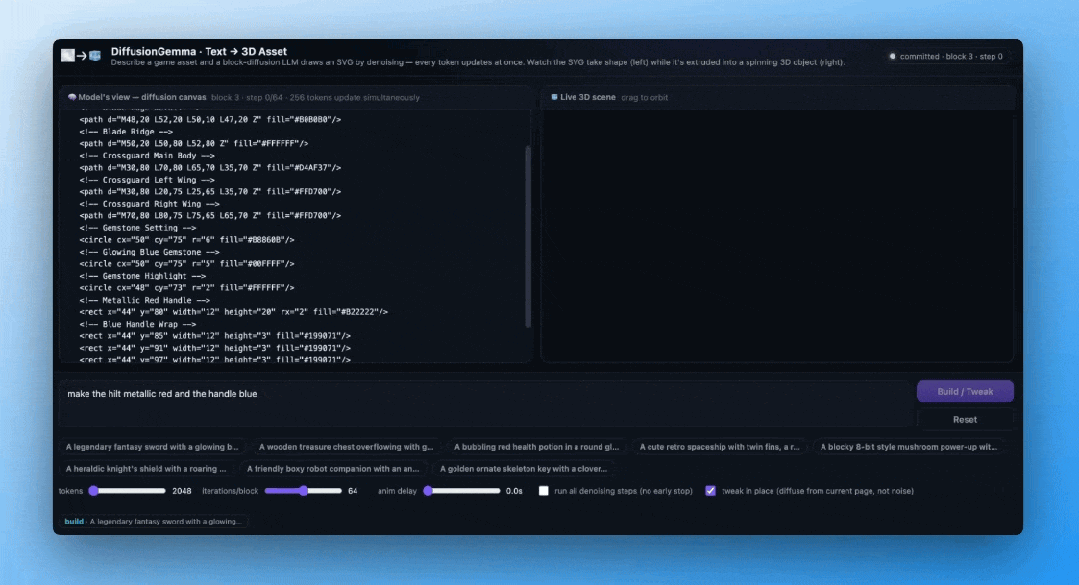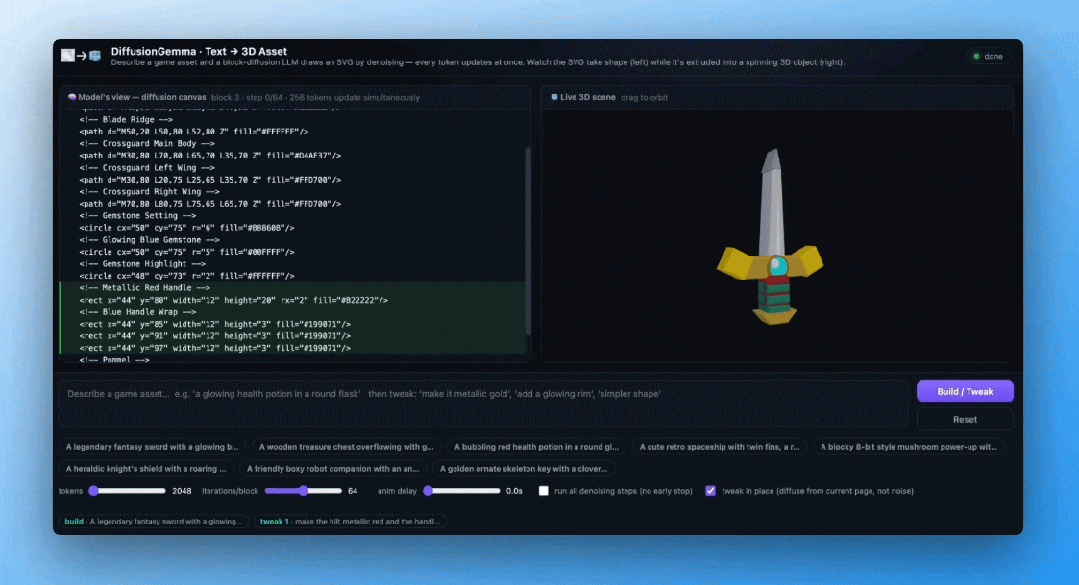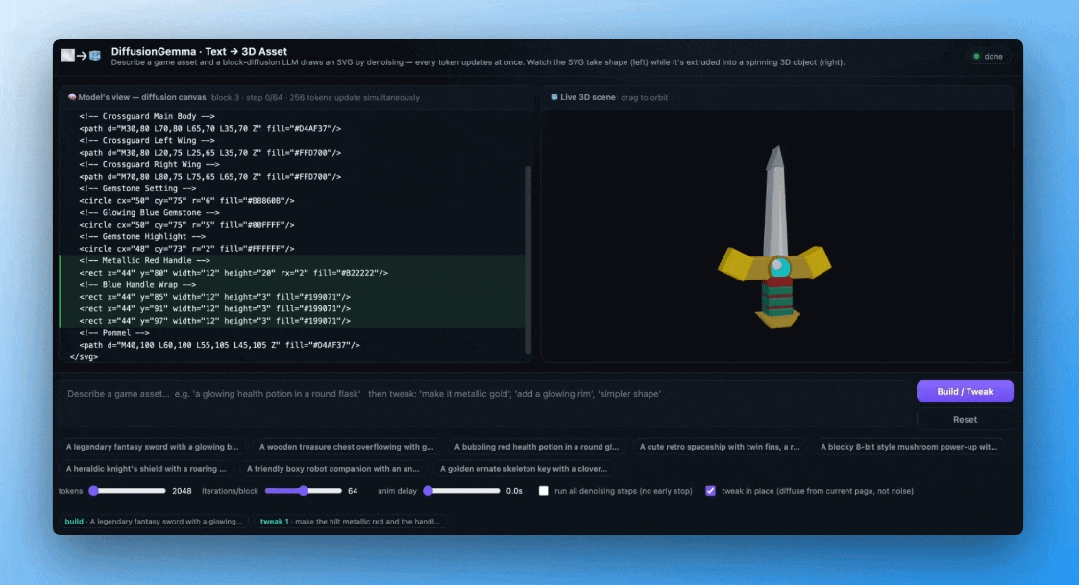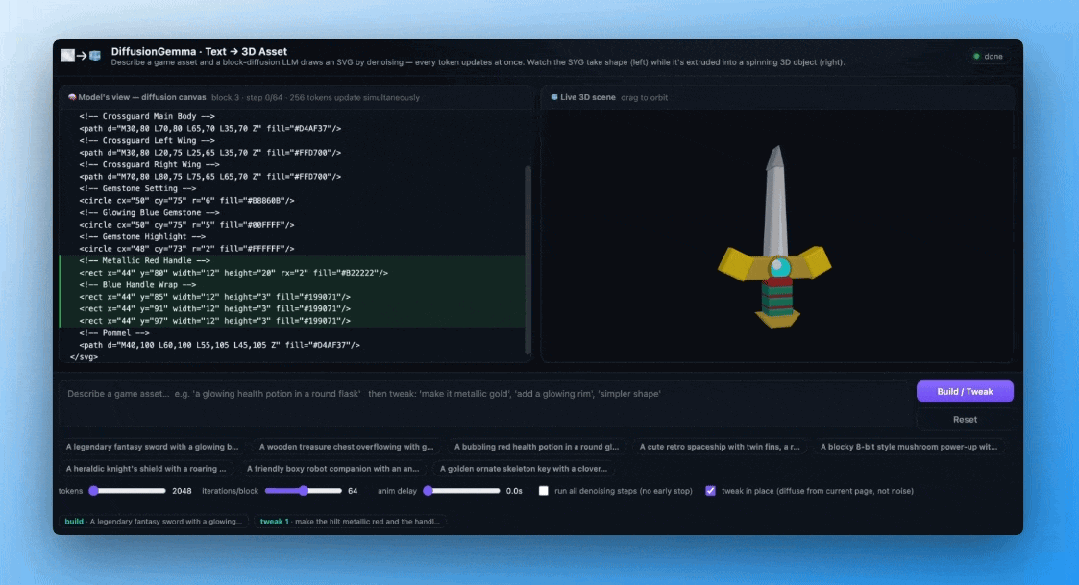
双向注意力:不止是快
速度之外,DiffusionGemma身上还有一个点值得关注:双向注意力。
传统自回归模型只能往前看,模型在生成第N+1个token时,只能看到第1到第N个token,看不到自己还没写出来的未来内容。
而DiffusionGemma的256个token同时生成,每个token都能看到画布上所有其他token,前后文同时可见。
这就带来了一个自回归模型很难做到的能力——实时自我纠错。
模型边生成边评估整段文字的一致性,发现不对立刻修正,不用等全写完再回头改。
这里谷歌举了个直观例子:数独。
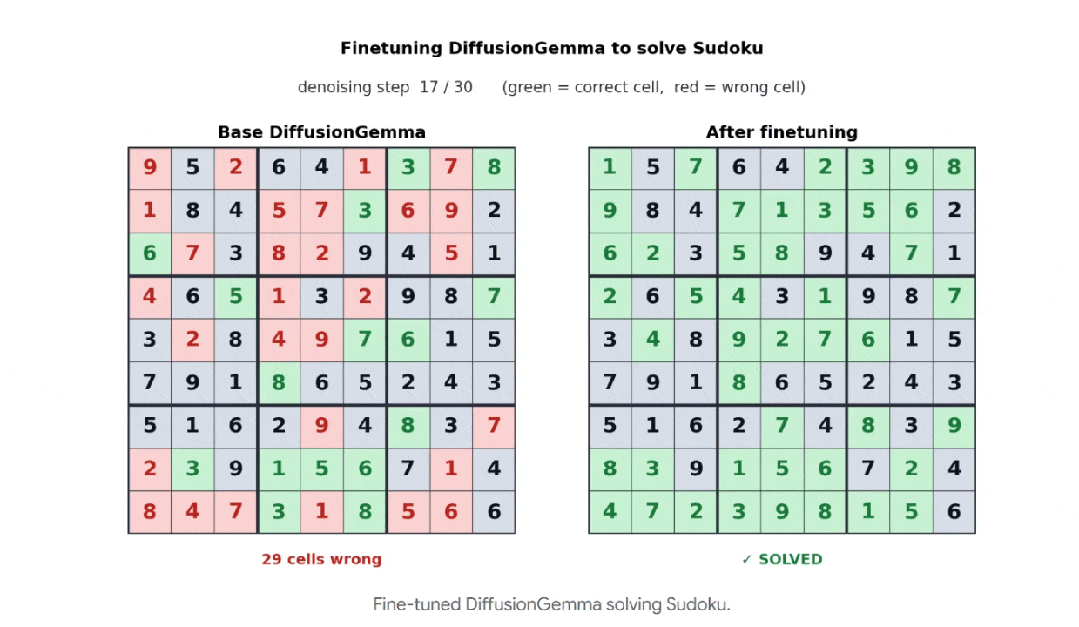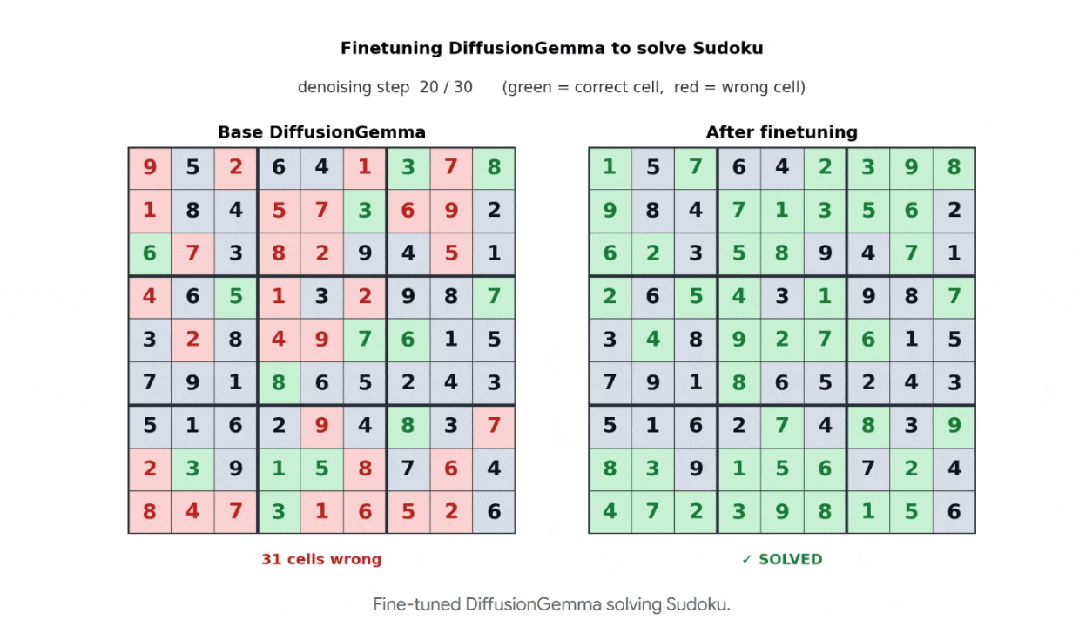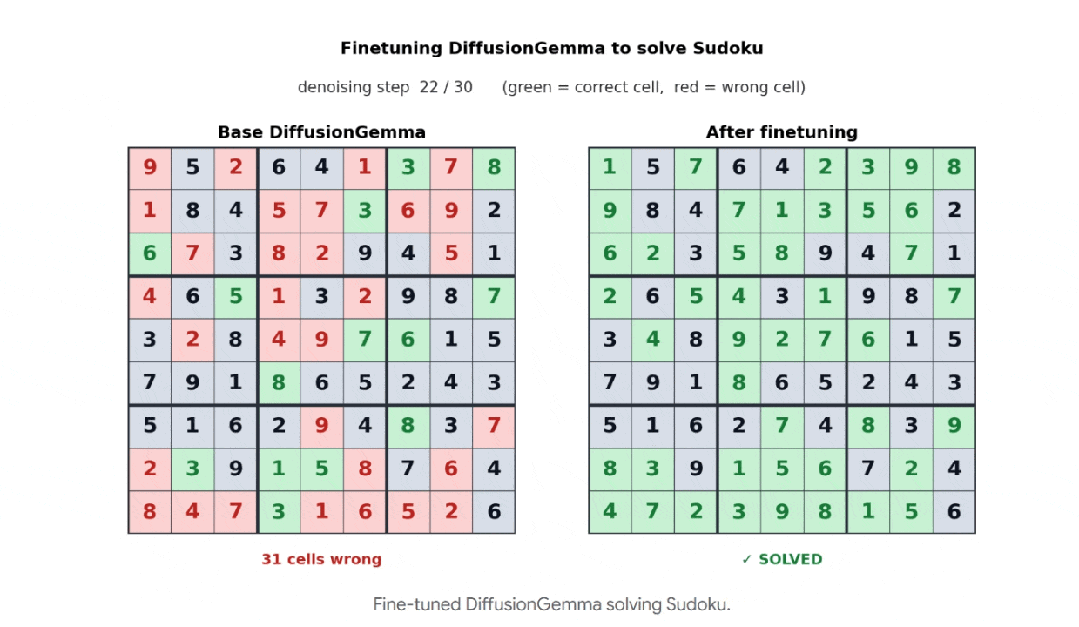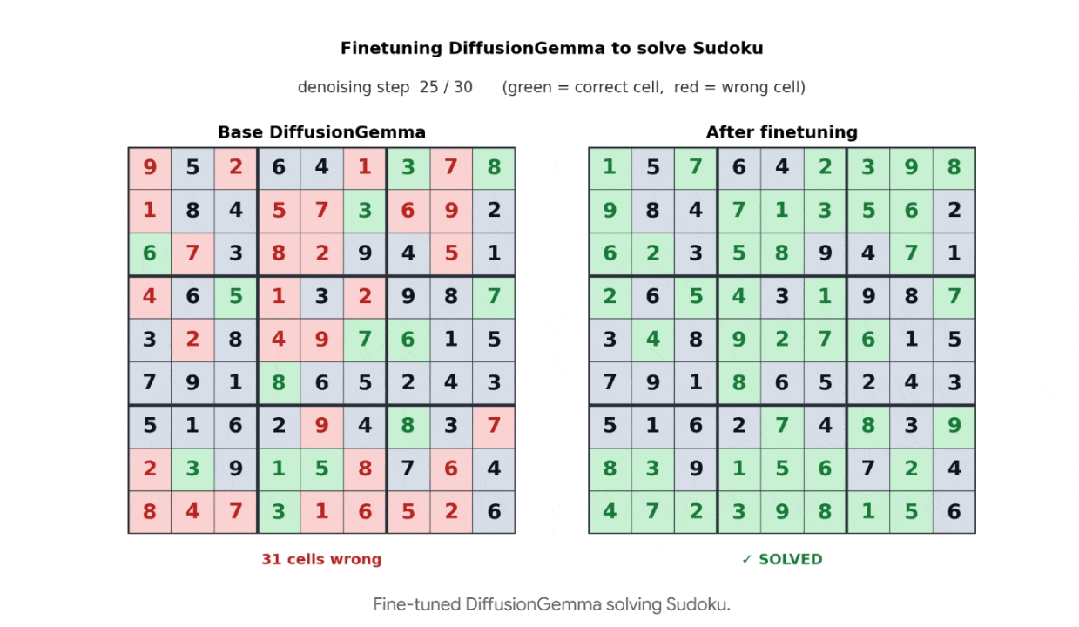
数独本质是“后面的数影响前面的数”,自回归模型由于只能往前看,所以做起来极痛苦。
但DiffusionGemma微调后成功率从0%飙到80%。
所以,如果未来接触到代码补全、行内编辑、复杂markdown格式化……这些“需要前后文同时协调”的场景,扩散模型无疑更有结构性优势。
谷歌CEO皮猜:DiffusionGemma是一匹“赛马”
不过这也并不是说扩散模型就千好万好。
其最大局限在图像生成领域也已得到验证,那就是速度和质量的平衡——
去噪步数越少速度越快,但质量越差;步数越多质量越好,但速度优势也就越小。
质量方面,和同参数量的Gemma 4 26B A4B相比,DiffusionGemma在多项基准上确实存在差距。
谷歌也很坦诚,生产环境推荐标准Gemma 4,DiffusionGemma面向的是速度敏感的本地交互场景。

所以,或许正如谷歌CEO皮猜所言,DiffusionGemma目前更像一匹“赛马”——
先把速度提起来。
它目前只是谷歌对下一代模型形态的一次实验:
如果不再执着于一个token一个token往外生成,而是让模型充分利用现代GPU的并行算力,大模型的速度上限究竟还能被推到多高?

而且说实话,谷歌也不是第一个尝试验证这条路线的人。
早在今年2月,初创公司Inception Labs就发布了扩散文本模型Mercury 2,号称比Claude、Gemini快5到10倍,是业内第一个真正投产的扩散语言模型。
谷歌自己去年I/O上也展示过Gemini Diffusion实验,当时采样速度达到每秒1479 token,但之后沉寂了一整年,外界一度猜测“跑不起来”。
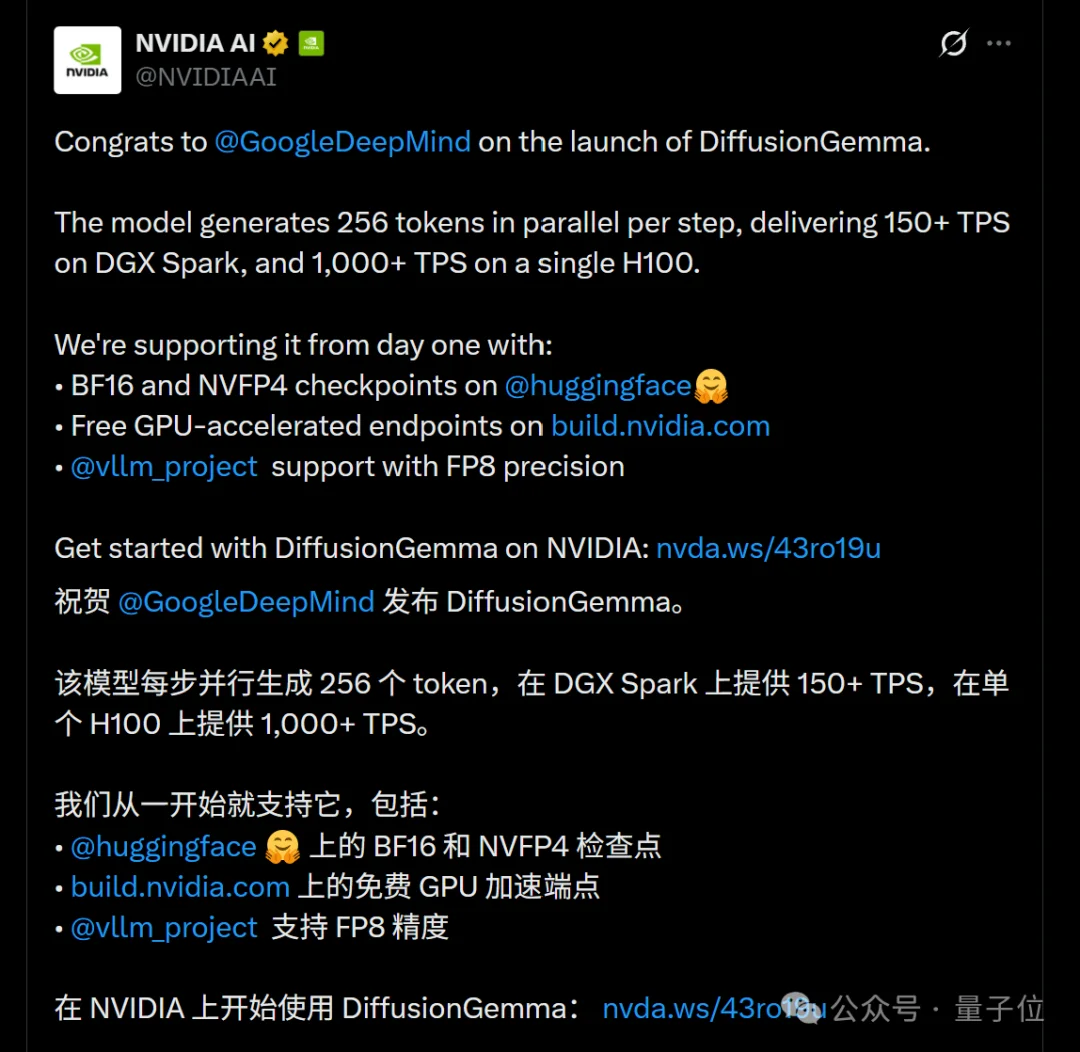
直到现在,DiffusionGemma卷土重来,并且NVIDIA从RTX到H100全线给它护航——
4090到H100到DGX Spark全覆盖,vLLM、MLX、Unsloth、NeMo全部支持,llama.cpp也在路上。
只能说,嘴上说着“实验性”,身体却很诚实。
谷歌这次给DiffusionGemma配上的资源和生态支持,显然不是来做技术Demo的。
从模型到推理框架,再到硬件生态,DiffusionGemma已经拿到了足够多的支持。
至于它最终能不能挑战自回归模型的主流地位,现在还没人知道。
但至少,谷歌把这条路真正开源了。
HuggingFace:
https://huggingface.co/unsloth/diffusiongemma-26B-A4B-it-GGUF
使用指南:
https://unsloth.ai/docs/models/diffusiongemma
参考链接:
[1]https://blog.google/innovation-and-ai/technology/developers-tools/diffusion-gemma-faster-text-generation/
[2]https://x.com/googlegemma/status/2064741002204545467[3]https://x.com/sundarpichai/status/2064744343743922189
文章来自于"量子位",作者 "一水"。
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

