FuseSearch:学习型自适应并行执行 —— 一个40亿参数的模型,凭什么在代码定位上干过了商用闭源大模型?答案只有四个字:搜得更聪明。
在AI编程狂飙突进的今天,一个尴尬的事实正在浮出水面:
你花在「让 AI 改代码」上的钱,超过一半其实烧在了「找代码」上。
研究表明,当前最先进的AI编程Agent,超过50%的计算资源消耗在代码搜索与定位环节——Agent翻来覆去地搜文件、读代码、定位函数,轮次消耗惊人,Token账单飞涨。
当所有人都在卷「模型多大、能写多长的代码」时,蚂蚁集团CodeFuse团队的一篇ACL 2026 Findings论文把目光转向了一个更底层的问题:能不能让搜索本身变得更聪明?
答案是可以。而且效果堪称惊艳——
FuseSearch-4B,一个仅40亿参数的开源模型,在SWE-bench Verified上达到84.7%文件级F1,匹配Claude Haiku 4.5的定位能力,同时速度快93.6%,Token消耗降低68.9%。
怎么做到的?一句话:让模型自己学会该并行多少。
代码定位
AI编程最烧钱的「卡脖子」环节
设想这样一个场景:你让AI帮你修一个Bug,它需要在一个几十万行代码的大型项目中,精准找到该改哪个文件、哪个函数。
这就是代码定位(Code Localization)——自动软件修复中最关键、也最昂贵的瓶颈。
现有方案分为两大流派,各有各的痛点:
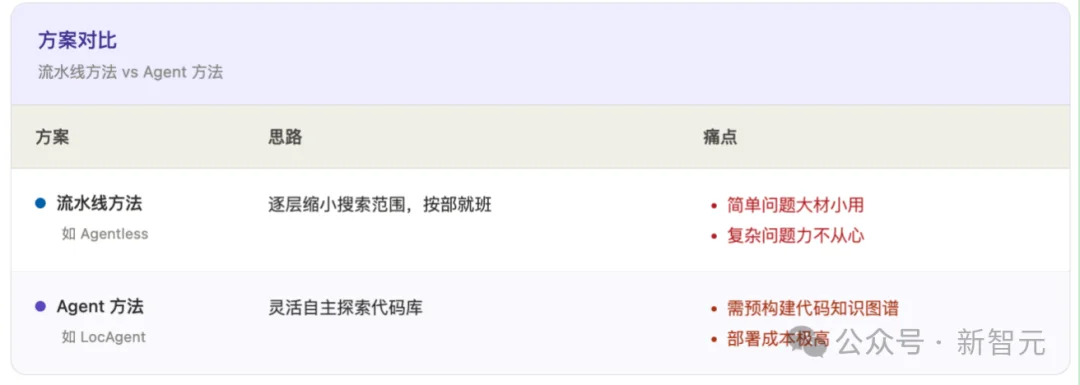
但这两派有一个共同的致命缺陷:一次只能做一件事。
每一轮交互只能调用一个工具,逐步缩小范围。就像你在图书馆找一本书,规定每次只能翻开一个书架看一眼——轮次用完了,信息还没收集够。
论文把这种现象称为信息匮乏(Information Starvation)。
并行 ≠ 万能解药
那解决方案似乎很简单——一次多调几个工具不就行了?
没那么容易。论文实验揭示了一个反直觉的发现:无脑并行反而更糟。
如果固定每轮调用8个工具(朴素的并行策略),会产生超过34.9%的冗余调用——重复搜索已经看过的代码区域,不仅浪费Token,还会引入噪声信号干扰判断。
核心矛盾就此浮出水面:
并行少了→信息不够用,定位精度下降。并行多了→大量冗余,浪费计算资源。
FuseSearch的核心洞察是:搜索效率和搜索质量并非对立关系。关键不在于并行多少,而在于——什么时候该多并行,什么时候该少并行。
FuseSearch
极简工具箱 + 自适应智能
FuseSearch的设计哲学出奇地优雅:不给模型定死规则,让它自己学会动态调整并行度。
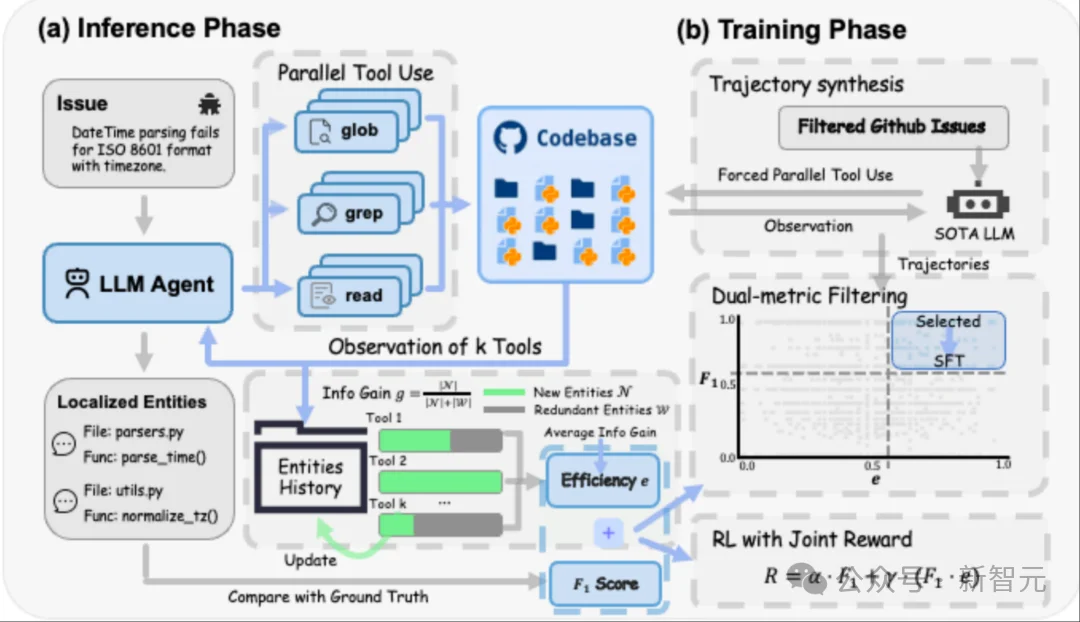
3.1 三把「瑞士军刀」
零成本部署
FuseSearch只用三个只读工具,极其克制:
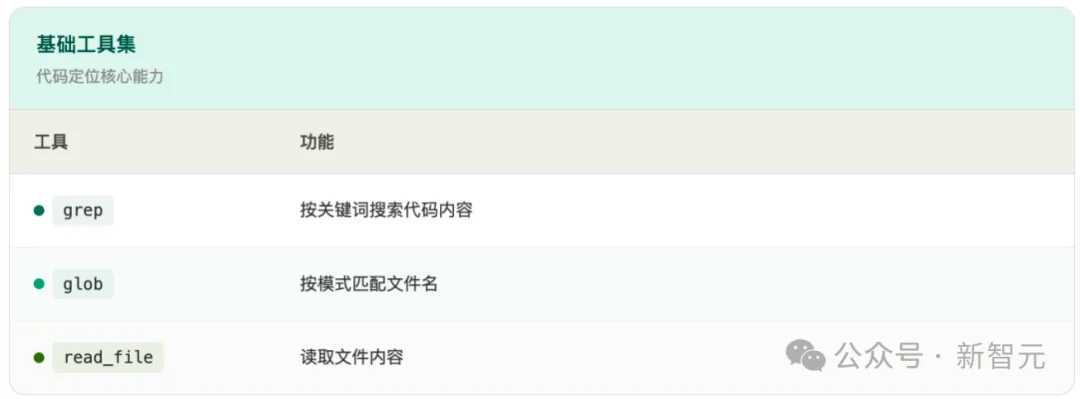
就这三个。不需要代码知识图谱,不需要语法解析器,不需要任何重型基础设施。零依赖,拿来就能用,可即时部署到任意代码仓库。语言无关,Python 仓库能用,Java仓库也能用。
工具虽少,能力完备——glob找文件、grep 搜内容、read_file读细节,三者组合可以遍历整个代码库。
关键创新
用「信息增益」量化搜索质量
论文首次提出工具效率(Tool Efficiency)指标,衡量每次工具调用的信息新颖性:
信息增益=新发现的代码实体数÷总返回的代码实体数
打个比方:你派了5个侦察兵去探路。如果5个人报告的都是同一条路,那4 个人就白跑了。工具效率衡量的,就是「每个侦察兵带回了多少独家情报」。
效率越高 → 每次搜索都在探索新区域。效率越低 → 在做重复劳动。
两阶段训练
先学会并行,再学会聪明地并行
FuseSearch的训练策略分两步走:
阶段一:监督微调(SFT)——建立并行能力
从233个高质量GitHub仓库中提取约21,000个issue-patch对,用强大的教师模型(Kimi-K2-Instruct)生成搜索轨迹。然后用双重标准严格筛选:
- 定位准确率 ≥ 0.8
- 工具效率 ≥ 0.5
从约24,000条候选轨迹中,精选出约 6,000 条「又准又不浪费」的高质量数据,教会小模型「每轮可以同时调 2-8 个工具」。
阶段二:强化学习(RL)——学会自适应
SFT之后,模型会并行了,但还不知道什么时候该多并行、什么时候该少并行。
RL阶段的奖励函数设计得极为精妙:
\text{奖励} = 0.8 *定位准确率 + 0.2 * (定位准确率*工具效率)
注意那个乘积项:
- 只有「找得准」且「搜得不浪费」同时满足,才能拿到额外奖励
- 如果定位完全错误(准确率=0),无论效率多高,奖励都是零——模型不能「高效地犯错」
这个设计迫使模型在搜索的每个阶段都做权衡:当前是广撒网收益大,还是精准验证收益大?
训练结果:一种「先撒网、再收网」的搜索策略
经过RL训练,模型自动学会了一种「老司机」式的自适应搜索模式:
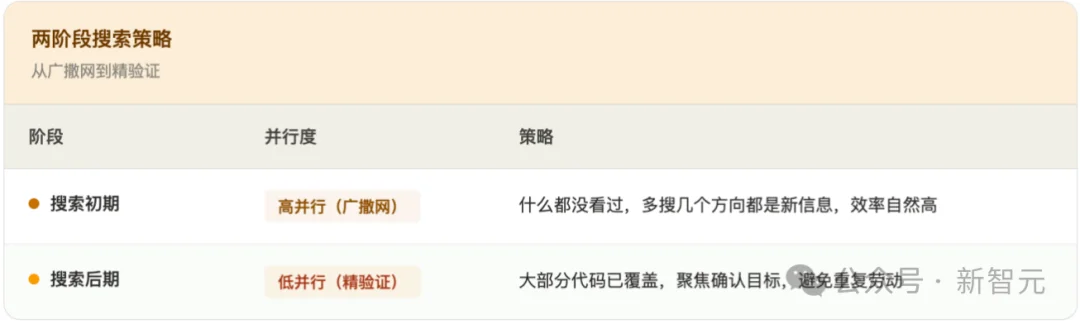
这种「先广度、后深度」的模式,完全是模型自己从奖励信号中学出来的,没有任何人工规则。
实验结果:小模型大翻身
5.1 核心数据(SWE-bench Verified,386 个实例)
在Qwen3-4B上对比之前的方法RepoSearcher,FuseSearch的提升堪称碾压:
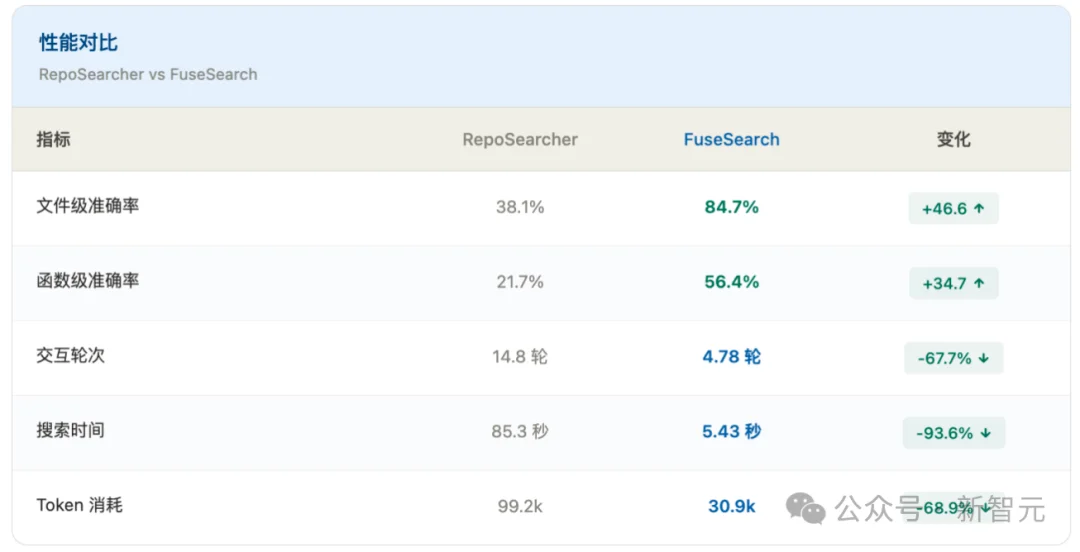
一句话总结:准确率翻倍,速度快16倍,Token省了近70%。
5.2 40亿参数 vs.商用闭源大模型
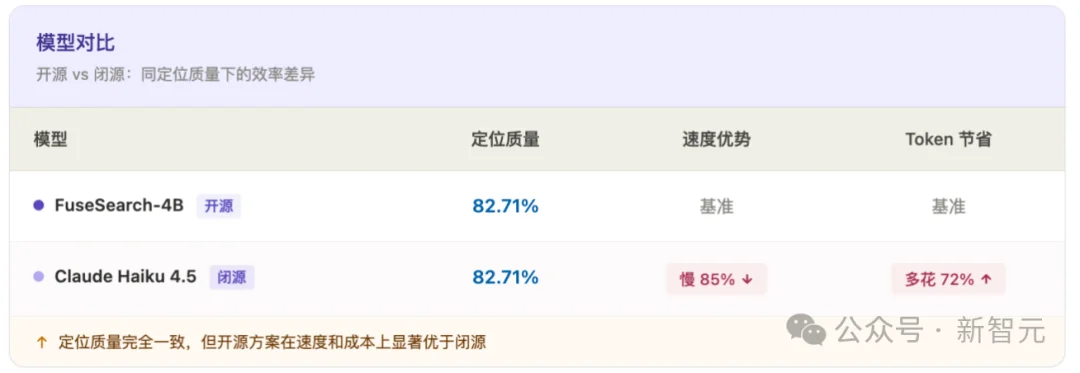
一个可以本地部署的4B开源小模型,定位能力与商用闭源大模型持平,同时更快、更省。
5.3 接入下游Agent:不掉精度,省一半成本
把FuseSearch-4B作为Kimi-K2-Instruct的「前置搜索引擎」:
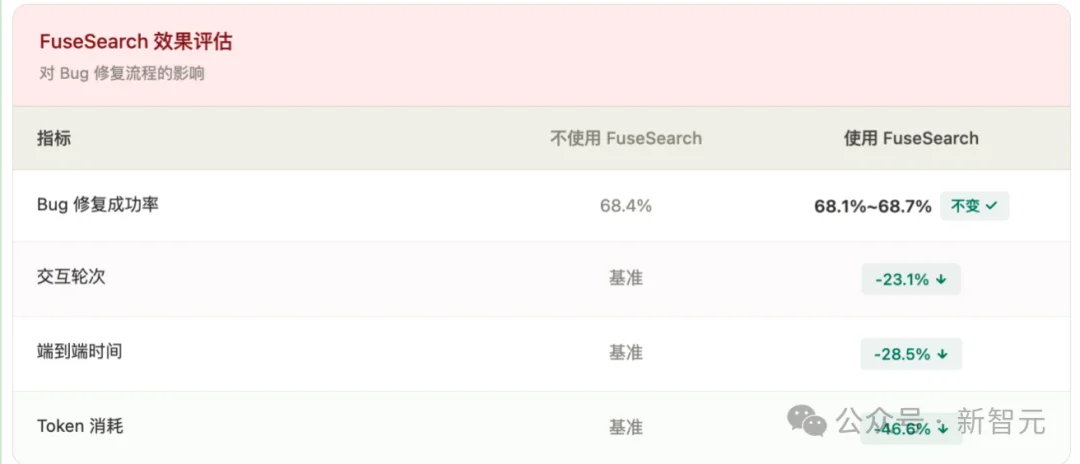
不影响修复效果,直接把成本砍掉近一半。
为什么这项工作值得关注?
FuseSearch带来了三个层面的贡献:
学术层面
首次将「搜索效率」变成一个可训练的目标。不是简单地让模型多搜或少搜,而是通过精巧的奖励函数设计,让模型自己学会「什么时候该搜多少」。这为 Agent 工具调用策略的优化提供了一个新范式。
工程层面
极简设计,零部署成本。 三个只读工具,语言无关,不依赖任何重型基础设施。论文作者已将代码开源,可即时部署到任意代码仓库。
产业层面
小模型逆袭大模型。40亿参数匹配Claude级别的定位表现,证明了「聪明的策略」比「堆参数」更重要。对于对延迟和成本敏感的工业级AI编程场景,这条路线极具落地价值。
论文信息
- 论文标题:FuseSearch: Learning Adaptive Parallel Execution for Efficient Code Localization
- 收录会议:ACL 2026 Findings
- 作者单位:蚂蚁集团(Ant Group)
- 论文链接:https://github.com/sxthunder/FuseSearch
文章来自于"新智元",作者 "新智元"。
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner

